Seaborn:一个样式更好看的Python数据可视化库
简介
Seaborn 是一个基于 Matplotlib 的 Python 数据可视化库,它提供了更高级别的界面和更优雅的默认样式,使得用户能够更轻松地创建各种各样的统计图形。Seaborn 的全名是 “Statistical Data Visualization”,它的目标是使数据可视化更加简单、直观和有效。
Seaborn 的主要特点包括:
- 高度易用:Seaborn 提供了一组高级 API,使得用户可以轻松地创建各种统计图形,而无需关心底层的实现细节。
- 美观的默认样式:Seaborn 提供了一套美观的默认样式,使得生成的图形更具视觉吸引力。
- 紧密集成:Seaborn 与 Pandas 数据结构紧密集成,可以轻松地处理 Pandas 中的数据。
- 高度可定制:Seaborn 提供了丰富的选项,允许用户根据需要定制图形的外观和内容。
Seaborn可以生成哪些图?
Seaborn 是一个比 Matplotlib 集成度更高的绘图库,可以生成一些看起来更高大上的图。
访问 Seaborn 官网https://seaborn.pydata.org/examples/index.html可以查看 Seaborn 生成图表的示例,我截图放在下面。


Seaborn 可以生成的一些常见图形类型,可以参考 Seaborn 的官方文档和示例。官网教程https://seaborn.pydata.org/tutorial.html
以下是 Seaborn 可以生成的一些常见图形类型:
- 散点图(scatter plot):使用
sns.scatterplot()函数生成散点图,用于展示两个特征之间的关系。 - 柱状图(bar plot):使用
sns.barplot()函数生成柱状图,用于展示分类数据的频数或百分比。 - 箱线图(box plot):使用
sns.boxplot()函数生成箱线图,用于展示数据的分布情况,包括最小值、最大值、中位数、四分位数等。 - 热力图(heatmap):使用
sns.heatmap()函数生成热力图,用于展示数据的相关性或聚类情况。 - 直方图(histogram):使用
sns.histplot()函数生成直方图,用于展示数据的分布情况,包括频数或概率密度等。 - 小提琴图(violin plot):使用
sns.violinplot()函数生成小提琴图,用于展示数据的分布情况,包括最小值、最大值、中位数、四分位数等,以及数据的核密度估计。 - 核密度估计图(kernel density estimation plot):使用
sns.kdeplot()函数生成核密度估计图,用于展示数据的核密度估计。 - 成对图(pair plot):使用
sns.pairplot()函数生成成对图,用于展示多个特征之间的关系。 - 多元线性回归图(multiple linear regression plot):使用
sns.lmplot()函数生成多元线性回归图,用于展示多个特征之间的线性关系。 - 分类数据的关系图(relational plot):使用
sns.relplot()函数生成分类数据的关系图,用于展示分类数据之间的关系。
安装
pip install seaborn
官方数据集
Seaborn 提供了一些内置的数据集,通过这些数据集可以学习和演示 Seaborn 的各种功能,包括绘制直方图、箱线图、散点图、热力图等。官方的数据集可以去这个网址下载https://github.com/mwaskom/seaborn-data
以tips.csv数据集为例,这是一个关于餐厅消费的数据集,包含了 244 条记录,每条记录有以下字段:
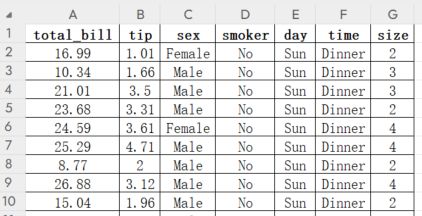
| 字段 | 含义 |
|---|---|
| total_bill | 消费总额(美元) |
| tip | 小费金额(美元) |
| sex | 顾客性别(男性或女性) |
| smoker | 顾客是否吸烟(是或否) |
| day | 消费日期(星期一至星期日) |
| time | 消费时间(午餐或晚餐) |
| size | 用餐人数(1 到 6 人) |
绘制柱状图
Seaborn 是基于 Matplotlib 进行的更上一层的封装,需要借助 matplotlib 中的 pyplot 进行展示图片,所有需要导 matplotlib.pyplot 包。
要使用 Seaborn 加载本地数据,可以使用 Pandas 库读取本地数据文件,然后将 Pandas DataFrame 对象传递给 Seaborn 进行可视化。
以下是一个使用 Seaborn 加载本地数据并绘制柱状图的例子:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取本地数据文件
tips = pd.read_csv('tips.csv')
# 绘制柱状图
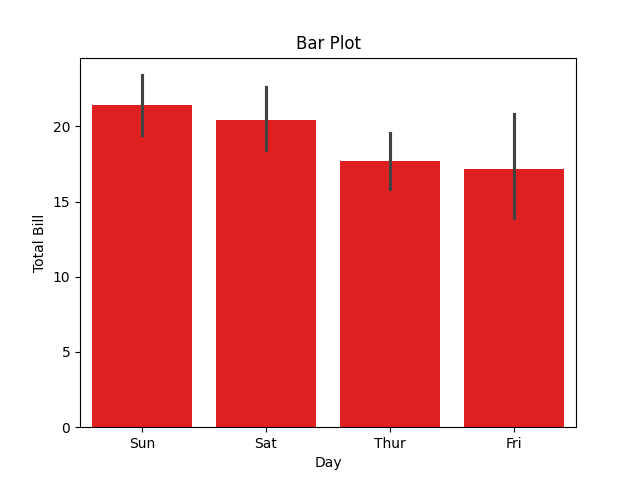
sns.barplot(x='day', y='total_bill', data=tips, color='red')
# 添加标题和标签
plt.title('Bar Plot')
plt.xlabel('Day')
plt.ylabel('Total Bill')
# 展示图表
plt.show()
在这个例子中,首先导入了 Pandas 库、Seaborn 库和 Matplotlib 库。然后使用 pd.read_csv() 函数读取了本地数据文件 tips.csv,并将读取到的数据存储在 Pandas DataFrame 对象 tips 中。接下来,使用 sns.barplot() 函数绘制了 tips 数据集中 x 和 y 两个特征之间的柱状图,并将柱状图的颜色设置为红色。最后,使用 plt.show() 函数显示了绘制出的柱状图。
生成的柱状图如下:
绘制散点图
继续以数据集 tips.csv 为例,使用 seaborn 库绘制一个散点图,展示 total_bill(总账单)与 tip(小费)之间的关系。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取本地数据文件
tips = pd.read_csv('tips.csv')
# 绘制散点图
sns.scatterplot(x='total_bill', y='tip', data=tips)
# 添加标题和标签
plt.title('Scatter Plot')
plt.xlabel('Total Bill')
plt.ylabel('Tip')
# 展示图表
plt.show()
代码执行流程如下:
- 导入所需的库:
pandas、seaborn和matplotlib.pyplot。 - 使用
pd.read_csv()函数读取本地数据文件tips.csv,并将数据存储在名为tips的 DataFrame 中。 - 使用
sns.scatterplot()函数绘制散点图,将total_bill作为 x 轴,将tip作为 y 轴,并使用tipsDataFrame 中的数据。 - 使用
plt.title()函数为散点图添加标题 “Scatter Plot”。 - 使用
plt.xlabel()和plt.ylabel()函数分别为 x 轴和 y 轴添加标签 “Total Bill” 和 “Tip”。 - 使用
plt.show()函数展示散点图。
库绘的散点图如下,展示 total_bill(总账单)与 tip(小费)之间的关系。

绘制成对图
penguins.csv是一个关于企鹅的数据集,包含了 344 条记录,每条记录有以下字段:
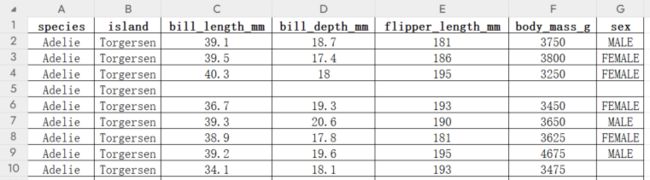
| 字段 | 含义 |
|---|---|
| species | 企鹅种类(Gentoo、Adelie 或 Chinstrap) |
| island | 企鹅生活的岛屿(Torgersen、Biscoe 或 Dream) |
| bill_length_mm | 企鹅嘴巴长度(毫米) |
| bill_depth_mm | 企鹅嘴巴深度(毫米) |
| flipper_length_mm | 企鹅翅膀长度(毫米) |
| body_mass_g | 企鹅体重(克) |
| sex | 企鹅性别(雄性或雌性) |
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="ticks")
# 读取本地数据文件
df = pd.read_csv('penguins.csv')
# 绘制成对图
sns.pairplot(df, hue="species")
# 展示图表
plt.show()
这段代码使用 Seaborn 的 pairplot 函数绘制了一个成对图,用于展示penguins.csv 数据集中不同特征之间的关系。
首先,代码导入了 Pandas、Seaborn 和 Matplotlib 库,并使用 sns.set_theme() 函数设置了 Seaborn 的主题样式。然后,代码使用 pd.read_csv() 函数读取了本地数据文件 penguins.csv,并将读取到的数据存储在 Pandas DataFrame 对象 df 中。
接下来,代码使用 sns.pairplot() 函数绘制了一个成对图,其中 df 参数指定了要绘制的数据集,hue 参数指定了要使用的颜色分组,这里是 penguins.csv 数据集中的 species 特征。
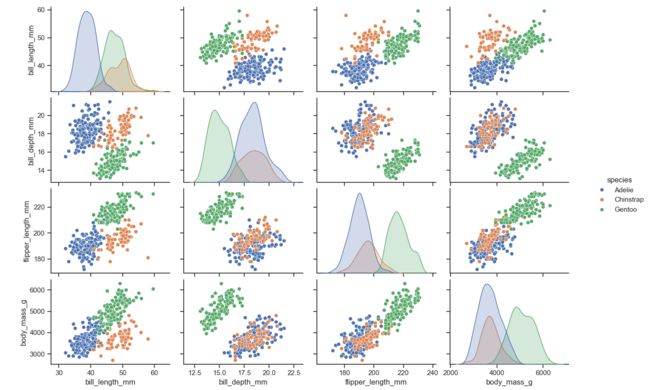
pairplot 函数会自动选择数据集中的所有特征,并绘制它们之间的成对关系。在每个子图中,x 轴和 y 轴分别表示两个特征,而颜色表示第三个特征,这里是 species。通过观察成对图,可以更好地理解penguins.csv 数据集中不同特征之间的关系。
绘制热力图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取本地数据文件
df = pd.read_csv('flights.csv')
# 按指定的月份顺序排序
month_order = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October',
'November', 'December']
df['month'] = pd.Categorical(df['month'], categories=month_order)
# 通过pivot函数进行数据透视
flights_pivot = df.pivot(index='month', columns='year', values='passengers')
# 绘制热力图
sns.heatmap(flights_pivot, cmap='YlGnBu', annot=True, fmt='d')
# 添加标题
plt.title('Heatmap')
# 展示图表
plt.show()
这段代码使用 Seaborn 的 heatmap 函数绘制了一个热力图。代码执行流程如下:
- 导入所需的库:
pandas、seaborn和matplotlib.pyplot。 - 使用
pd.read_csv()函数读取本地数据文件flights.csv,并将数据存储在名为df的 DataFrame 中。 - 定义一个名为
month_order的列表,其中包含按指定顺序排列的月份名称。 - 使用
pd.Categorical()函数将df中的month列转换为分类类型,并按照month_order中的顺序进行排序。 - 使用
df.pivot()函数对数据进行透视,将month列作为行索引,year列作为列索引,passengers列作为数据值,生成了一个新的 DataFrame 对象flights_pivot。 - 使用
sns.heatmap()函数绘制热力图,其中flights_pivot参数指定了要绘制的数据集,cmap参数指定了要使用的颜色映射,并在每个单元格中显示数值。 - 使用
plt.title()函数为热力图添加标题 “Heatmap”。 - 使用
plt.show()函数展示热力图。
生成的热力图如下:

通过观察热力图,可以更好地理解 Flights 数据集中,每个年份和月份的航班乘客数量的分布情况。
本文首发在“程序员coding”公众号,欢迎关注与我一起交流学习。
