数仓工具使用-Datax
前置-解决中文乱码问题
解决方案-在mysql中执行
use hive;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;comment出现乱码的原因就是因为创建hive表时使用的编码集为
latin1不是utf8不支持中文不可以把hive的元数据库编码集直接改为utf8,因为修改后元数据将全部失效,但是我们可以将与comment相关的字段编码集进行修改.改为utf8.
注意: 修改编码集后创建的表comment才能变成中文,因为之前添加的数据已经按照
latin1编码集进行编码了.无法改变.
DataX介绍
DataX 是阿里推出的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
将DataX安装好之后, 仅需要配置Json的采集文件即可实现数据的同步

DataX几个组成部分:
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。Writer:Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。

经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:
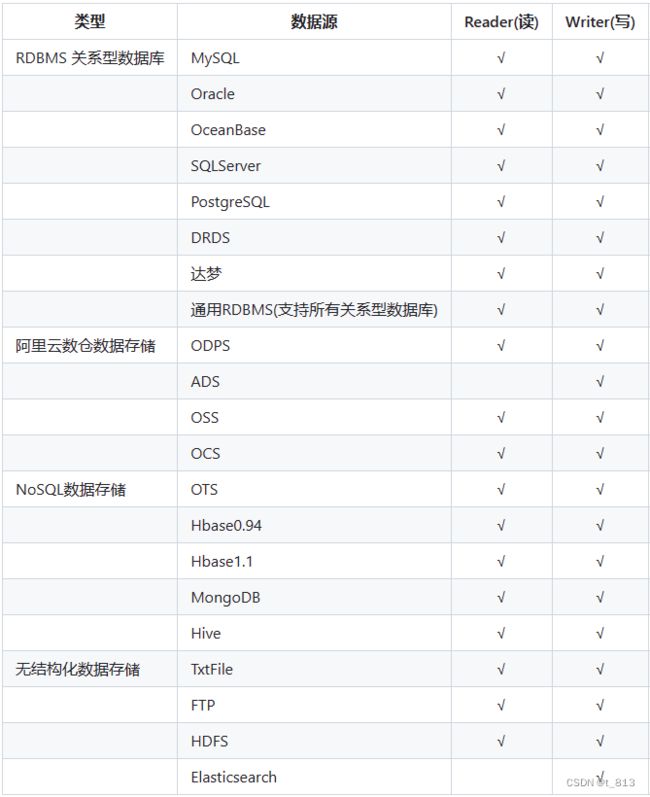
DataX的国内的开源的地址: Gitee 极速下载/alibaba datax?_from=gitee_search (码云)
DataX的GitHub的开源地址: https://github.com/alibaba/DataX
Datax中的插件使用json格式进行书写:
json格式中仅有以下几种数据类型
json格式中仅有以下几种数据类型
object数据类型: {键1: 值1, 键2: 值2....}
Array数据类型: [元素1, 元素2,......]
number数据类型: 1, 2, 11.2
string数据类型 : "name", "chuanzhi"
boolean数据类型: false , true
在json格式中不能使用'' 只能使用""
object数据类型的键,只能是字符串类型
一般情况下, json格式的最外层是一个大object{}
不能存在多余的, : 等符号
DataX使用
MySQL写入HDFS
1. 在mysql创建test数据库,在此数据库下创建student表,然后往表中插入数据。
drop database if exists test;
create database if not exists test character set utf8;
use test;
create table student(id int,name varchar(20),age int,createtime timestamp );
insert into `student` (`id`, `name`, `age`, `createtime`) values('1','zhangsan','18','2021-05-10 18:10:00');
insert into `student` (`id`, `name`, `age`, `createtime`) values('2','lisi','28','2021-05-10 19:10:00');
insert into `student` (`id`, `name`, `age`, `createtime`) values('3','wangwu','38','2021-05-10 20:10:00');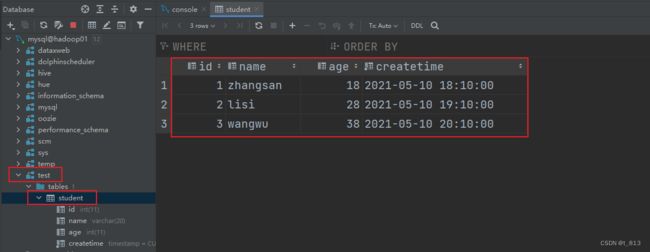
2.创建作业的配置文件(json),先执行脚本命令,查看配置的模板。 (可以直接查看官网的配置文档)
cd /export/server/datax
python bin/datax.py -r mysqlreader -w hdfswriter
显示模板:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
3.修改配置: 基于官网修改
cd /export/server/datax/job
vim mysql2hdfs.json{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"querySql": [
"select id,name,age,createtime from student where age <30;"
],
"jdbcUrl": [
"jdbc:mysql://hadoop01:3306/test"
]
}
]
}
},
"writer":{
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://hadoop01:8020",
"fileType": "text",
"path": "/test/datax/mysql2hdfs",
"fileName": "student.txt",
"column": [
{
"name": "id",
"type": "INT"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "age",
"type": "int"
},
{
"name": "createtime",
"type": "TIMESTAMP"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
"compress":"GZIP"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
4.启动HDFS, 创建目标路径: /test/datax/mysql2hdfs (可选的)
hdfs dfs -mkdir -p /test/datax/mysql2hdfs

5.启动dataX
cd /export/server/datax/
python bin/datax.py job/mysql2hdfs.json
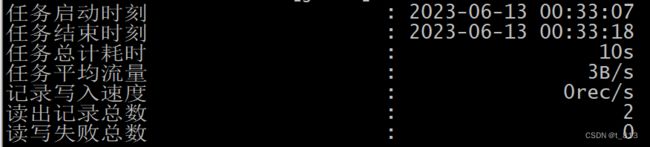
6.校验是否ok

解压, 查看内容即可:

MySQL写入HIVE
本质上, 没有hivewriter, 写入hive就是写入到hdfs中的指定目录中.
1.创建作业的配置文件
cd /export/server/datax/
vim job/mysql2hive.json
注意:写入hive时与写入hdfs的写入名称name都为hdfswriter。只是在写入hive时,为与hive表关联,在path参数后填写hive表在hdfs上的存储路径。以及保证存储格式和分隔符号与HIVE表保持一致
例:Hive上设置的数据仓库的存储路径为:/user/hive/warehouse/ ,已建立数据库:test,表:student;则对应的存储路径为:/user/hive/warehouse/test.db/student。
配置内容为:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"age",
"createtime"
],
"connection": [
{
"table": [
"student"
],
"jdbcUrl": [
"jdbc:mysql://hadoop01:3306/test"
]
}
]
}
},
"writer":{
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://hadoop01:8020",
"fileType": "text",
"path": "/user/hive/warehouse/test.db/student",
"fileName": "student.txt",
"column": [
{
"name": "id",
"type": "INT"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "age",
"type": "int"
},
{
"name": "createtime",
"type": "TIMESTAMP"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
"compress":"GZIP"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
2.在Hive中建库建表
create database IF NOT EXISTS test;
use test;
create table student(
id int,
name varchar(20),
age int,
createtime timestamp
)
row format delimited fields terminated by "\t" STORED AS TEXTFILE;如果crt中无法拖拽上传数据文件, 则手动安装插件
yum -y install lrzsz
3.执行DataX
cd /export/server/datax
python bin/datax.py job/mysql2hive.json

4.校验数据

DataX-Web工具
DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。
如何启动:
cd /export/server/datax-web-2.1.2
./bin/start-all.sh

登录主界面: http://hadoop01:9527/index.html
输入用户名 admin 密码 123456 就可以直接访问系统。

配置操作
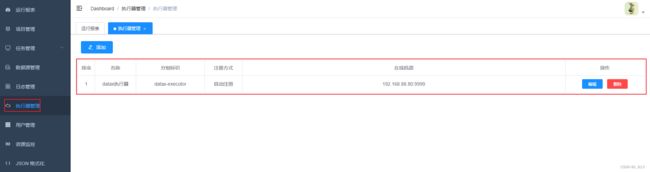
执行器配置: 点击执行器管理。
执行器列表中显示在线的执行器列表, 可通过"在线机器"查看对应执行器的集群机器
创建数据源: 创建数据源(源库和目标库)。首先点击数据源管理,点击添加
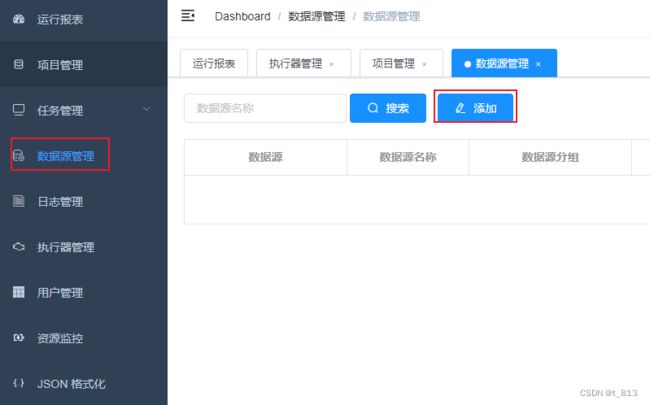
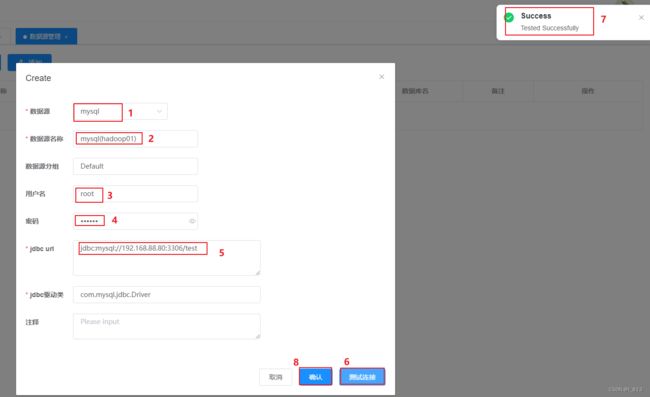
再次点击添加,添加目标数据库信息。如下:
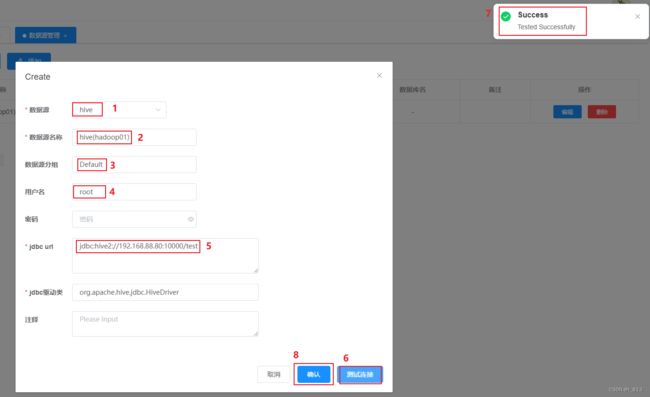
最终效果

创建项目: 点击项目管理,点击添加。创建测试项目


创建任务模板: 点击任务管理,点击DataX任务模板,点击添加


cron表达式是一个字符串,由6到7个字段组成,用空格分隔。其中前6个字段是必须的,最后一个是可选的。

【*】:每的意思。在不同的字段上,就代表每秒,每分,每小时等。
【-】:指定值的范围。比如[1-10],在秒字段里就是每分钟的第1到10秒,在分就是每小时的第1到10分钟,以此类推。
【,】:指定某几个值。比如[2,4,5],在秒字段里就是每分钟的第2,第4,第5秒,以此类推。
【/】:指定值的起始和增加幅度。比如[3/5],在秒字段就是每分钟的第3秒开始,每隔5秒生效一次,也就是第3秒、8秒、13秒,以此类推。
【?】:仅用于【日】和【周】字段。因为在指定某日和周几的时候,这两个值实际上是冲突的,所以需要用【?】标识不生效的字段。比如【0 1 * * * ?】就代表每年每月每日每小时的1分0秒触发任务。这里的周就没有效果了。
写入到Hive中
hive建表
在hive创建student2表
create database IF NOT EXISTS test;
use test;
create table student2(
id int,
name varchar(20),
age int,
createtime timestamp
)
row format delimited fields terminated by ","
STORED AS TEXTFILE;构建json脚本




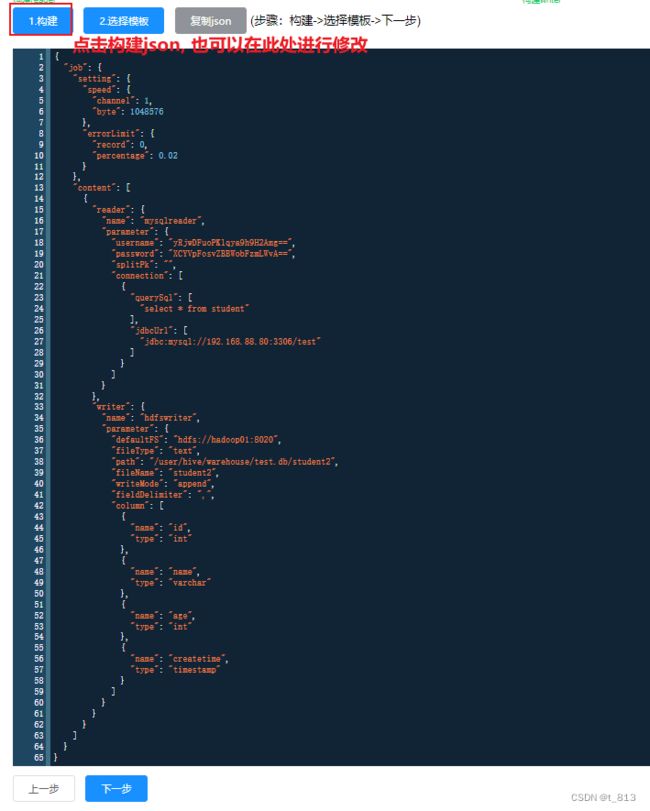

点击完成即可
点击任务管理, 执行任务

如果有问题, 可以点击编辑修改配置
 查看Hive表, 是否成功写入
查看Hive表, 是否成功写入
