spark window源码探索
核心类:
1. WindowExec 物理执行逻辑入口,主要doExecute()和父类WindowExecBase
2. WindowFunctionFrame 窗框执行抽象,其子类对应sql语句的不同窗框
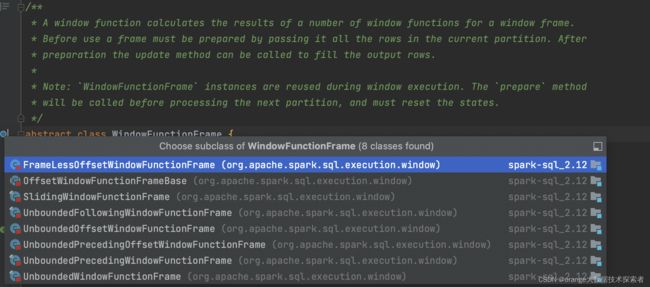
其中又抽象出BoundOrdering类, 用于判断一行是否在界限内(Bound), 分为RowBoundOrdering和RangeBoundOrdering
我们的UDAF在何时已什么顺序接受数据, 何时会被执行eval, 都取决于窗框内方法调用逻辑!
3. AggregateProcessor 负责调用一个frame下的各个窗口函数, 起着包装/代理的功能
AggregateProcessor中三个关键方法: initialize, update, evaluate, 里面都是去调用具体Function的对应方法
4. WindowExpression:窗口函数表达式,将一个表达式和一个窗口规范关联起来,用于在数据集的窗口上进行计算
代码流程
WindowExec这个类是物理执行逻辑入口,它有一个父类WindowExecBase
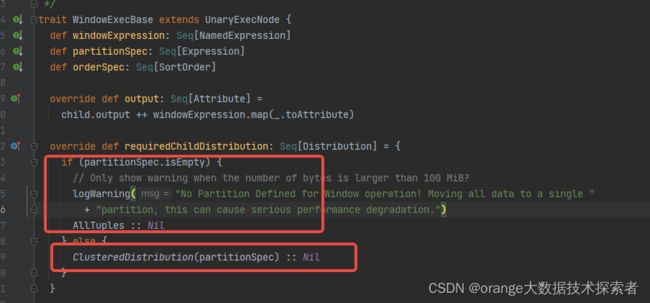
1. 在这里可以看到如果有partition关键字,就是hashpartition,没有partition by就会是singlepartition

2. 再看聚合的类 AggregateProcessor,明确说明了窗口函数只会使用Complete聚合模式,也就是说窗口操作,相同key的数据一定在同一分区,所以window函数的性能是比group要差的
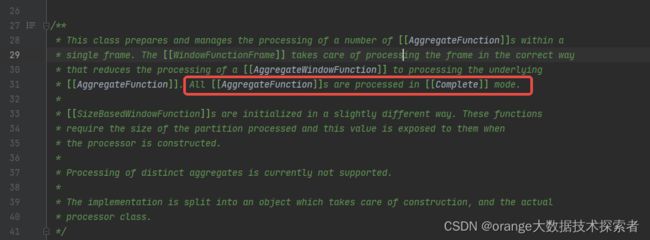
回到WindowExec,我们再来看doExecute()做了什么
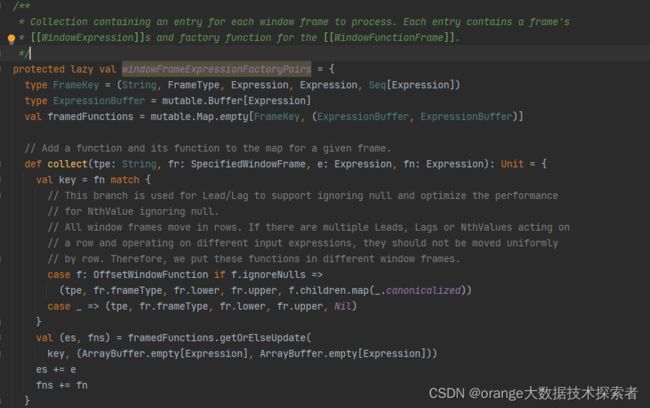
首先windowFrameExpressionFactoryPairs 主要是根据窗口表达式, 生成下面几个执行需要的核心类的对象

对RDD调用mapPartitions, 需要处理Iterator[InternalRow]并返回一个Iterator[InternalRow]
![]()
window执行过程中额外设置了buffer进行汇总,每个窗口中数据的缓存结构,有大小和条数限制,超出会移出到磁盘

fetchNextPartition做的事, 就是从子RDD的分区的Iterator[InternalRow]中, 每次读取同组的所有行(partition by列值相同的所有行). 它的执行逻辑, 依赖于RDD中的数据已经按照要求分区排序好了, 所以代码不复杂.
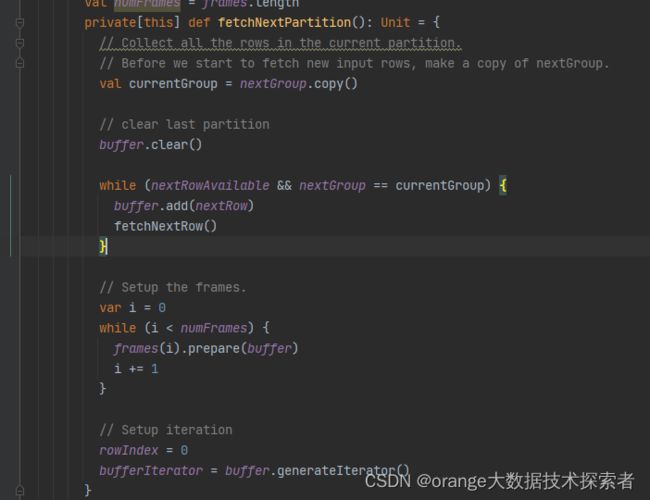
并经过一系列处理后join得到的window function result返回
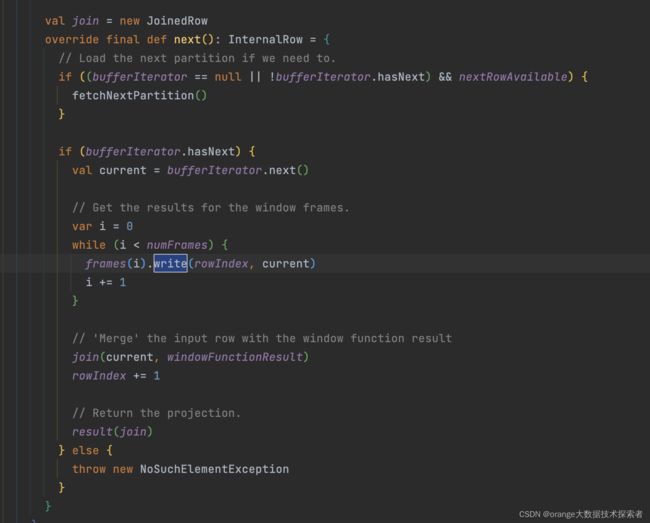
另外可以看到上诉两个代码其实都是在调用frame(WindowFunctionFrame)的两个方法:
- prepare(rows: ExternalAppendOnlyUnsafeRowArray): Prepare the frame for calculating the results for a partition. 在WindowExec的fetchNextPartition中被调用, 接收到同组的所有输入行.
- write(index: Int, current: InternalRow): Write the current results to the target row. 向target中写入当前行的计算结果. 一次一行.
而且多个窗口时explain可以看到多个窗口串行执行