python爬虫+虚拟机centos7+pyqt5+mapreduce实现微博舆情分析系统
记录一下自己做的一个简单的微博舆情分析系统,但是mapreduce实际就是单独的一个模块,不属于系统的一个部分,还有很多的不足之处,第一次学习这方面的知识做的。后续希望进行改进。
1. 需求分析
1.1 引言
随着互联网的快速发展,越来越多的人习惯于在网络上发表自己的观点。作为中国一大社交媒体平台,微博每天都会产生各类信息,其中的热搜更是会引导大众的视线和态度,有时甚至会达到难以控制的地步。由于活跃用户众多,舆情传播速度快,有些事件可能会被歪曲放大,严重时甚至危害国家和社会的稳定。因此,建立微博舆情分析系统十分必要。微博舆情分析系统可以帮助用户监测和分析微博平台上的舆情信息,提供实时的舆情监测、情感分析、关键词提取等功能,以帮助用户了解公众对特定话题的态度和观点,支持用户进行舆情管理和决策。
1.2 目标用户描述
该系统的目标用户包括高校、企业、政府机构、媒体等,他们希望通过该系统能够及时掌握公众对特定话题的舆情信息,以便进行舆情管理、危机处理、舆论引导等。
1.3 功能需求
(1)针对监测:系统能够通过关键词针对性监测微博平台上与特定话题相关的微博内容、评论、用户信息等。
(2)情感分析:系统能够对微博内容进行情感分析,判断微博作者和评论者的情感倾向,包括积极和消极。
(3)关键词提取:系统能够提取微博内容中的关键词,帮助用户更清晰的了解公众对特定话题的关注点。
(4)热点分析:系统能够分析微博内容的热点词汇,帮助用户了解公众对特定话题的关注度。
(5)数据可视化:系统能够将舆情数据进行可视化展示,通过完整的界面来操控,展示词云图和言论的情感,帮助用户直观地了解舆情信息。
2.设计框架
本系统功能设计可分为数据抓取、数据分析以及界面展示三种模块,其总体框架如下图1所示。其中,数据抓取模块通过网络爬虫实现,数据分析包括Mapreduce和snownlp技术,最后利用pyqt5控件制作界面。

图1 系统设计总体框架图
接下来再分别对各模块进行介绍。首先是数据抓取模块,其框架图如下图2所示。大致流程为通过cookie和headers登入微博,然后通过关键词和时间来获取对应的URL,最后再解析该网页,通过正则表达式来获取各种页面信息。
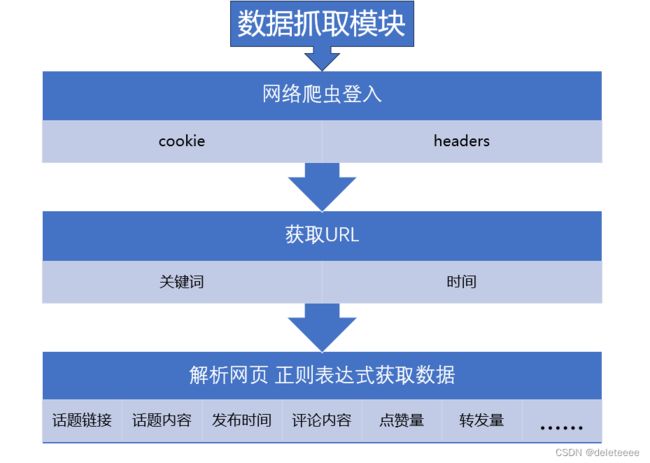
图2 数据抓取模块
第二个是数据分析模块也是本系统最为重要的一个部分,其框架图如下图3所示。本模块分成两个部分。第一部分对于上一步爬取到的数据文本先进行处理,包括分词、去停用词,然后将得到的规整文本上传至虚拟机配置好的Centos7系统的HDFS中,然后再存入到Hive数据库中,在hive中使用HiveQL语言调用mapreduce实现词频统计。第二部分是对数据进行分析,包括词云图生成和情感分析,词云图通过wordcloud自动生成,情感分析需要用到snownlp,考虑其原始模型不够适应微博情感判断,所以利用微博文本数据集对模型进行了重训练。
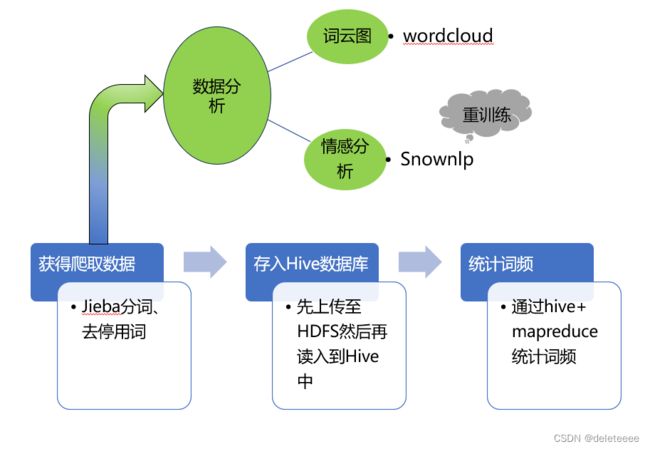
图3 数据分析模块
最后为界面显示模块,目的就是将上述功能集成于一个可视化界面内,方便于用户进行交互,其框架图如下图4所示。整体界面的设计是通过pyqt5这一工具来实现的,包括主题输入框、起止时间选择框、开始分析按钮、词云图显示框以及情感分析结果输出框。当用户完成主题和时间的输入后,点击开始按钮后将会调用主函数进行一系列的处理,最终将输出结果显示到界面上,此外在后台也能看到具体的爬虫过程。
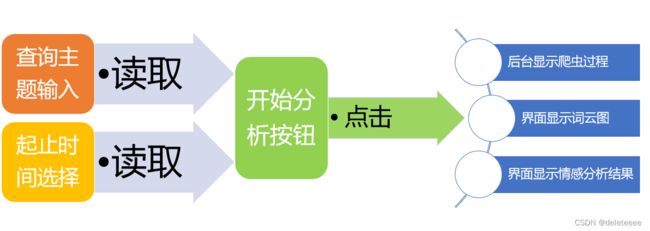
图4 界面显示模块
以上便是本系统所有的设计框架。
3.算法和技术介绍
3.1 数据抓取
本系统在数据抓取阶段采用的是爬虫技术,实际上就是根据微博网页上高级搜索包括的主题词和起止时间来产生并获取相应的URL,然后向网页发起请求获取响应对象,再利用响应对象中的源码字段,通过正则表达式提取出每篇微博位移的标识mid,其部分过程代码如下图5所示。后续读取具体微博页面信息都是基于这个mid的,不同字段比如用户ID、微博内容等都是在该页面上通过正则表达式提取的。

图5 mid值获取
3.2 词频统计
考虑到微博数据量大,因此词频统计采用MapReduce技术去实现,又由于直接使用MapReduce处理数据,实现查询逻辑开发难度较大,且输入数据分散,所以采用Hive处理数据更方便。接下来对它们分别进行介绍。
(1)MapReduce它是一种编程模型和软件框架,用于在分布式计算环境中处理大量数据。在MapReduce作业中,输入数据被分成较小的块,并分布到集群中的不同节点。然后,每个节点将映射操作应用于其分配的数据块,生成中间的键值对。这些中间结果随后被洗牌和排序,以便所有具有相同键的值被分组在一起。然后,归约操作应用于每个具有相同键的值组,生成最终的输出数据。归约操作的输出通常被写入文件或数据库以进行进一步的分析。
(2)Hive是一个基于Hadoop的数据仓库基础设施,它提供了类似于SQL的查询语言(HiveQL)来查询和分析大规模的结构化数据。它通过将HiveQL查询转换为一系列MapReduce作业来隐藏了底层的复杂性,可以灵活地处理数据。Hive使用类似于关系数据库的表结构来组织数据。用户可以通过HiveQL语句创建表,并将数据加载到表中。Hive支持各种数据格式,包括文本、CSV、JSON等。用户可以使用HiveQL查询语句来对表进行查询和分析,并将结果保存到新的表或文件中。
本系统在centos7系统内配置hadoop环境实现hive+mapreduce词频统计功能。
3.3 词云图和情感分析
(1)词云图:本系统使用的编程语言为python,关于词云图的生成,python有wordcloud库来自动生成,先利用jieba库对文本进行分词和去停用词,生成新的文本(以空格隔开每个词汇)后再输入到wordcloud中进行处理。
(2)SnowNLP:它是一个基于Python的中文自然语言处理(NLP)库。它使用机器学习的方法,通过训练语料库来进行中文文本情感分析、文本分类、关键词提取、文本摘要等任务。在本系统中可以将微博内容输入其中,得到一个0-1之间的值,该值越接近1表示内容越积极。但是原始SnowNLP情感分析模型是基于电商平台评论语料库的,对于本系统微博内容的情感判断难免不太准确,所以本系统在原始语料的基础上追加了几万条微博内容语料库进行重训练,增加后语料库部分内容如下图6,其中1代表积极情感。

图6 增加后的语料库
接下来对于训练前后两个模型进行测试对比,下图7是初始模型分析结果,图8为训练后模型的分析结果。可以看出对于图中的两句已知消极的言论,训练后的模型明显分析的更加准确了。

图7 初始模型情感分析结果

图8 训练后模型分析结果
3.4 界面化技术
本系统采用的是桌面图形程序,利用PyQt5进行设计。PyQt5是一个用于创建图形用户界面(GUI)的Python模块,它是基于Qt框架的Python绑定库。Qt是一个跨平台的应用程序开发框架,可以用于开发桌面应用程序、移动应用程序和嵌入式系统等。PyQt5提供了丰富的GUI组件和工具,开发者可以使用它来创建功能强大的应用程序。它支持常见的GUI元素,如按钮、文本框、标签、列表框等,并且还支持自定义的GUI元素。PyQt5还提供了一些用于处理用户输入和事件处理的功能。开发者可以通过连接信号和槽来实现事件处理,以及使用事件过滤器来捕获和处理特定的事件。
4.结果展示
接下来将会展示本系统的各项功能,比如最近万圣节很火爆,那以万圣节为主题词,时间就设定最近一段时间,分析结果如下图9所示。结果包括两个显示框,左边的为情感分析框,对微博内容以及评论内容进行情感分析,右边为词云图,字体大小代表的就是该词汇出现频率。
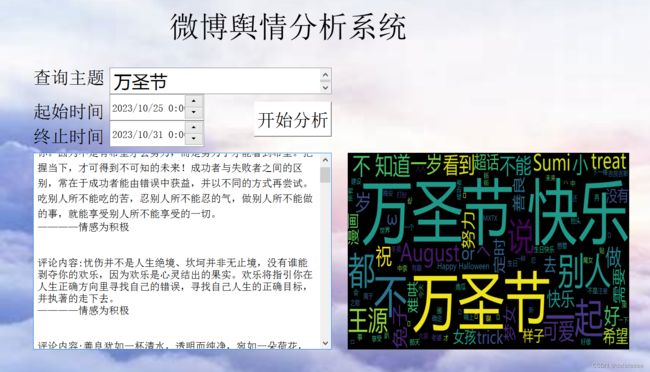
图9 万圣节主题分析结果
同时,后台也会显示爬虫程序过程,如下图10所示,可以看到相应的各种信息以及读写状态。
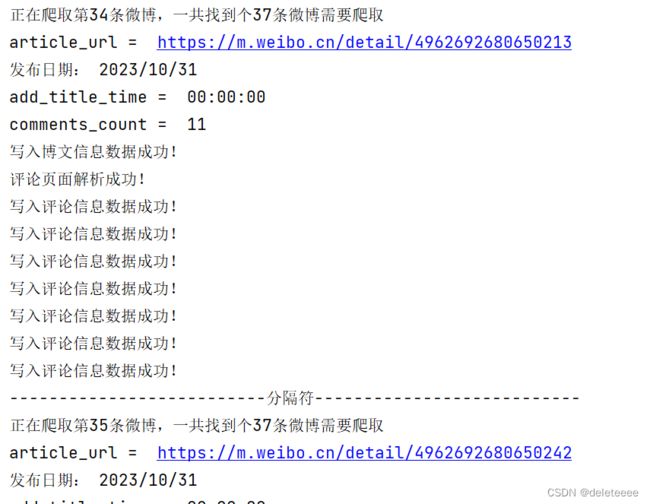
图10 爬虫过程
爬取的数据以及处理后的数据也会在本地有备份文件,下图11中所示的csv文件存储了爬虫得到的所有数据,包括话题链接、话题内容、博主ID等内容。
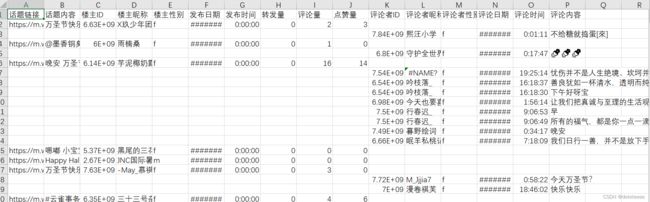
图11 爬虫结果
Jieba库分词结果也会被存入一个新的文件中,格式与图11相同,但对应的内容是分词结果,如下图12所示,话题内容那一列的文本都完成分词,词汇以空格相隔分开。
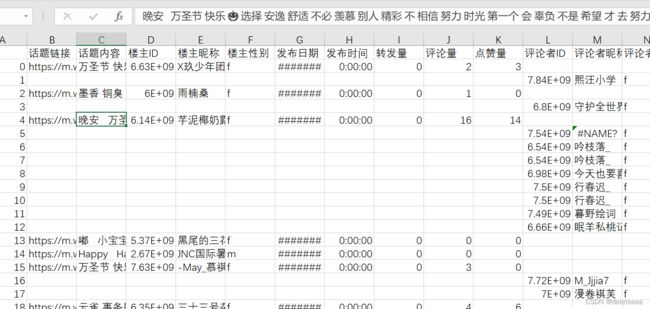
图12 分词结果
词频统计部分是在虚拟机上进行的,本地虚拟机配置的是centos7系统,整体界面如下图13所示。
图13 centos7系统界面
在该系统上配置好相应的环境后,将处理好的文本上传至HDFS分布式文件系统上去,查看结果如下图14。相应的txt文件已经成功上传,并且可以查看到其中的内容。
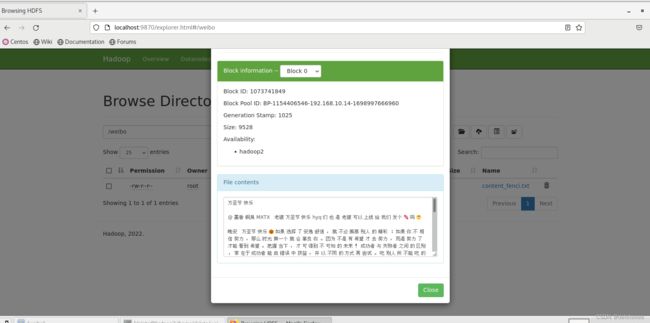
图14 文本上传结果显示
接下来在hive中使用HiveQL语言创建一张wordcount表存储上述txt文本,存储后用查询语言查看结果如下图15。

图15 查询wordcount表
该文本无法直接用来统计词频,还需根据词汇间的空格将各词汇纵向排列起来,输入相应HiveQL语言后结果如下图16所示,查看处理结果,结果如图17所示。
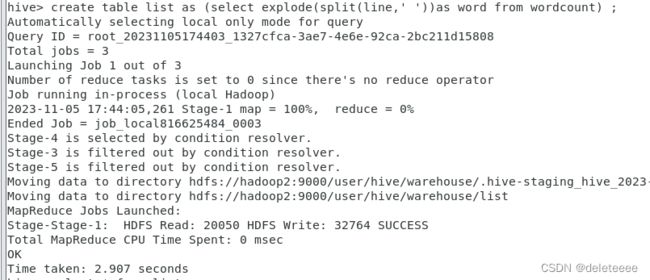
图16 文本处理

图17 文本处理结果
最后,使用select和count(*)调用mapreduce来实现词频统计,过程如下图18所示,然后再以升序排序查看词频统计结果如图19所示。

图18 mapreduce词频统计过程

图19 词频统计结果
以上便是本系统所有模块的结果展示。