搭建vmware虚拟化平台的基础配置,以及Hadoop平台的搭建
需要准备的东西:
vmware workstations
centos.iso
hadoop3.3.0
mobaxterm/xshell/pietty/winscp
jdk的tar包
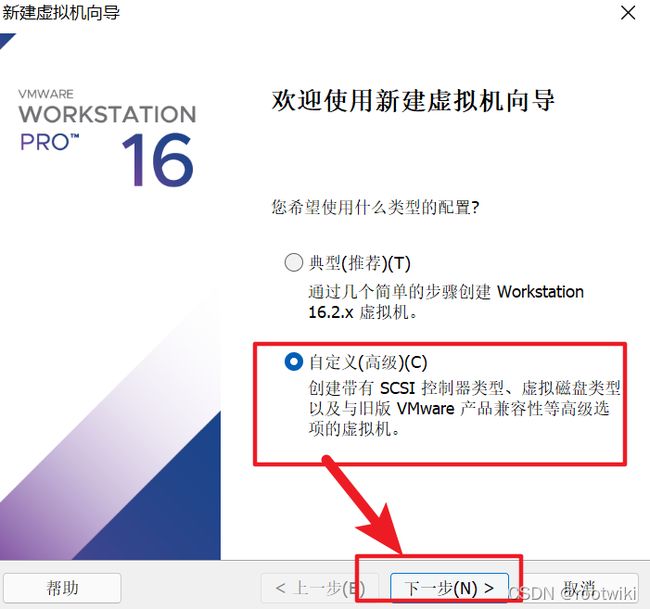
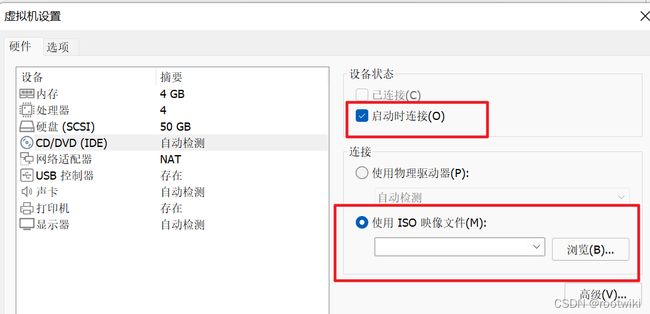
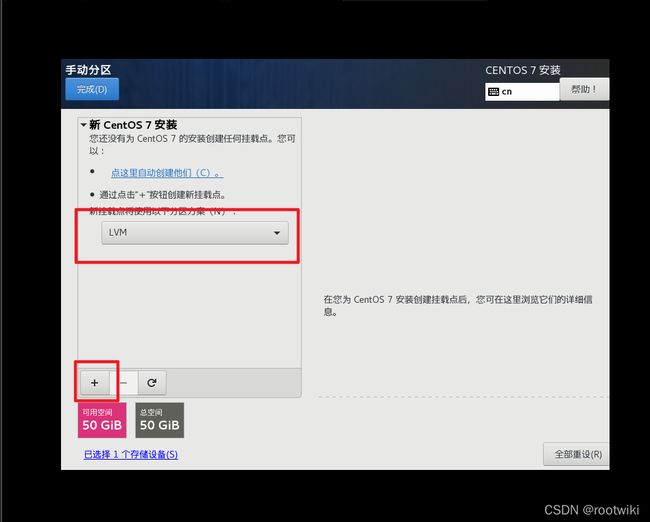
第一步 : 安装centos操作系统
第二步 : 克隆虚拟机(也可以在hadoop安装后再克隆)
我们这里需要选择完整克隆
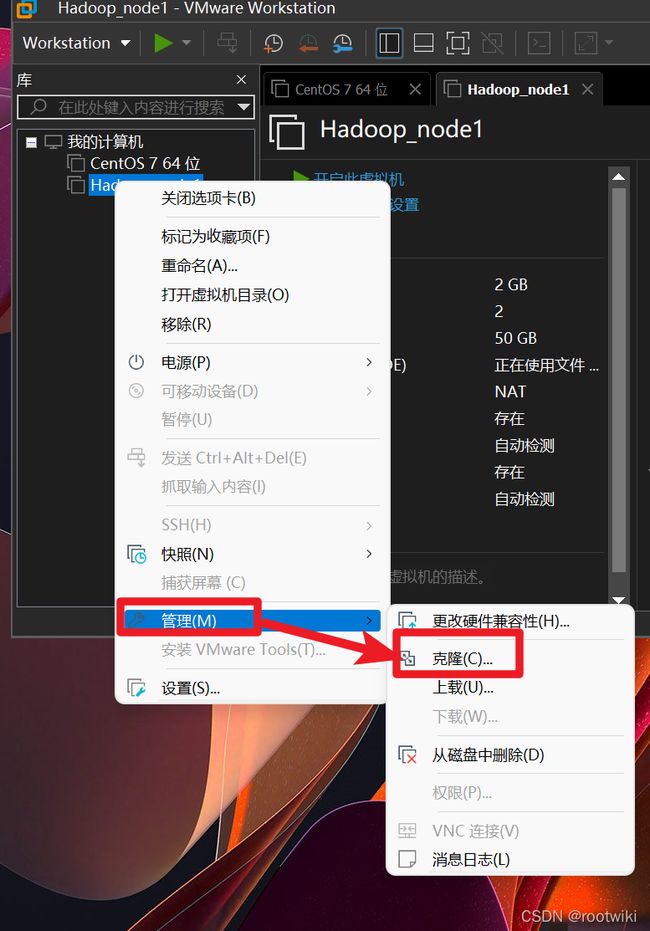

然后稍作等待,在列表中会刷新虚拟计算机
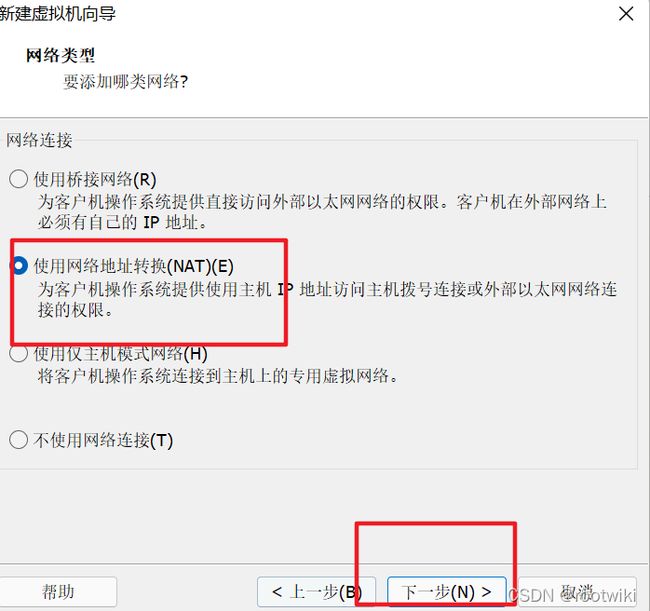
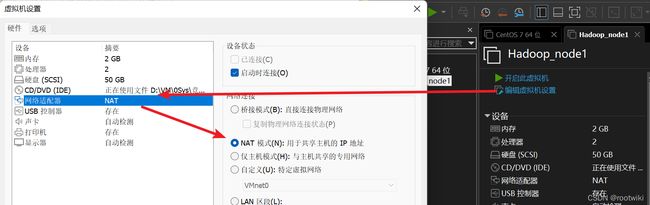
第三步 : 配置虚拟网络
3.1预备知识
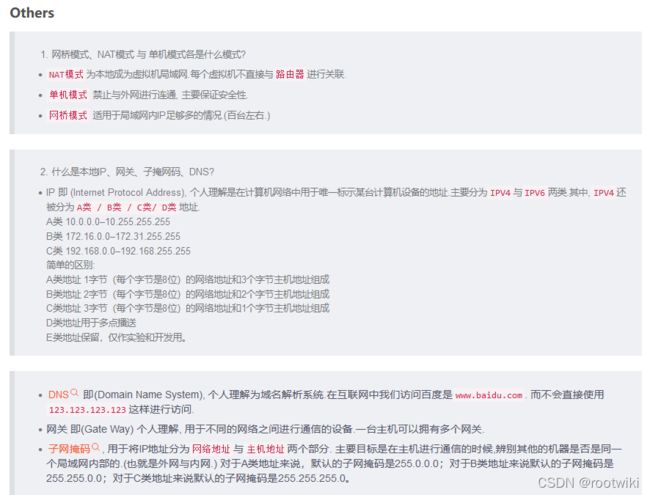
网络模式简介:
VMWare提供了3种工作模式, 它们是bridged(桥接) 模式、NAT(网络地址转换) 模
式和host-only(仅主机) 模式。
资料1:
在学习VMWare虚拟网络时, 建议选择host-only方式。原
因有两个:一是如果用的是笔记本电脑, 从A网络移到B网络环境发生变化后, 只有host-only
方式不受影响,其他方式必须重新设置虚拟交换机配置;二是可以将真实环境和虚拟环境隔
离开, 保证了虚拟环境的安全。下面将简单了解bridged(桥接) 模式和NAT(网络地址转换)
模式, 详细学习host-only(仅主机) 模式。
1.bridged
在这种模式下, VMWare虚拟出来的操作系统就像是局域网中的一台独立的主机, 它可
以访问网内任何一台机器。同时在桥接模式下,需要手工为虚拟系统配置IP地址、子网掩码,
而且还要和宿主机器处于同一网段,这样虚拟系统才能和宿主机器进行通信。
2.NAT
使用NAT模式, 就是让虚拟系统借助NAT功能, 通过宿主机器所在的网络来访问公网。
也就是说, 使用NAT模式可以实现在虚拟系统中安全的访问互联网。采用NAT模式最大的
优势就是虚拟系统接入互联网非常简单,不需要进行任何其他的配置,只需要宿主机器能访
问互联网即可。
3.host-only
在某些特殊的网络调试环境中, 要求将真实环境和虚拟环境隔离开, 这时可采用host-only
模式。在host-only模式中, 所有的虚拟系统是可以相互通信的, 但虚拟系统和真实的网络是
被隔离开的。
在host-only模式下, 虚拟系统的TCP/IP配置信息(如IP地址、网关地址、DNS服务
器等) , 都可以由VM net 1(host-only) 虚拟网络的DHCP服务器来动态分配。
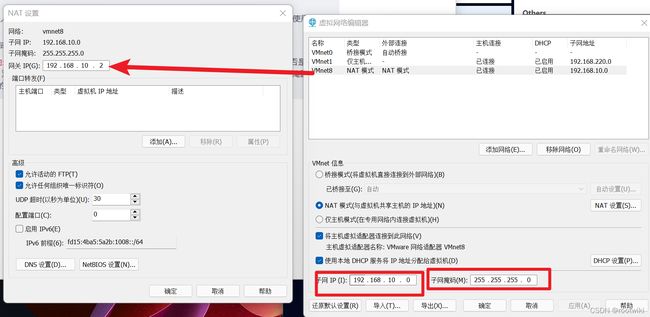
这里我们选择NAT模式,可以使用宿主机的网络
资料2:
3.2修改虚拟机配置:
vim /etc/sysconfig/network-scripts/ifcfg-**
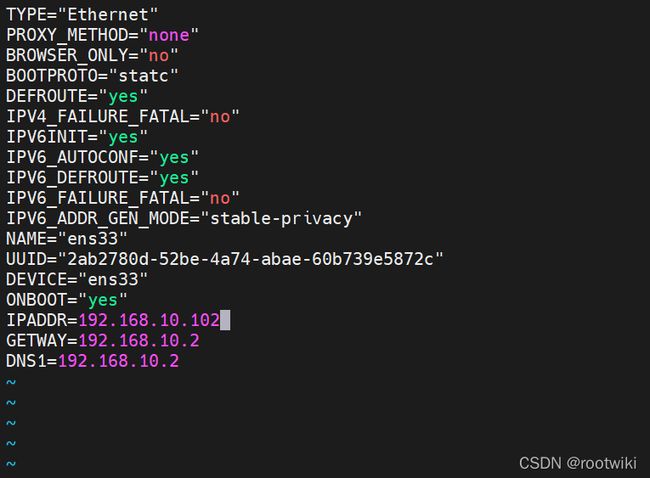

配置要点:
GATEWAY=192.168.10.2
!!! GATEWAY 注意拼写!!!
重启一下网络:
service network restart
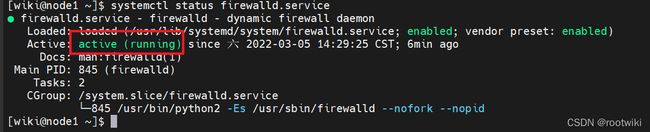
关闭防火墙:
systemctl status firewalld.service
systemctl stop firewalld.service
systemctl disable firewalld.service


然后同步一下服务器配置:
sync
第四步 : 单机搭建hadoop
4.1前置知识:
rpm 管理套件
-e 删除指定的套件
--nodeps 不验证套件档的相互关联性
给wiki用户分配sudoer用户组:
vim /etc/sudoers
wq!因为只读,需要强制保存

4.2环境变量的配置:
查看原装java的jdk :
rpm -qa | grep java
卸载原装的jdk:

rpm -e --nodeps java-1.8.0*
再一次查看
剩下这三个:

解压文件:
配置环境变量方法一(最普通常规):
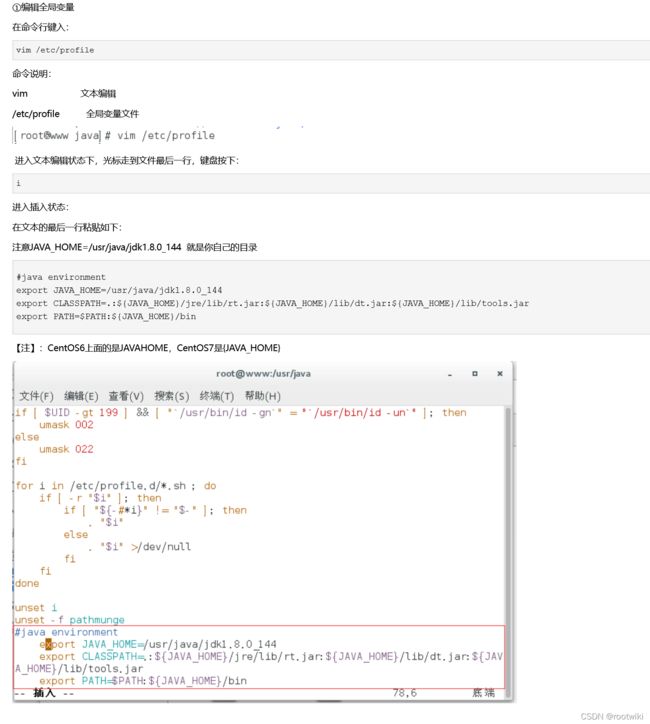
方法2(自己新建文件对hadoop的环境变量进行管理配置):
查看profile文件(/etc/profile)
打开profile.d文件夹
创建my_env.sh这个文件
区别:
1、两个文件都是设置环境变量文件的,/etc/profile是永久性的环境变量,是全局变量,/etc/profile.d/设置所有用户生效,同样是永久变量,是全局变量。
2、/etc/profile.d/比/etc/profile好维护,不想要什么变量直接删除/etc/profile.d/下对应的shell脚本即可,不用像/etc/profile需要改动此文件。
3、需要注意的是,/etc/profile和/etc/profile.d同样是登录(login)级别的变量,当用户重新登录shell时会触发。所以效果一致。
4、通常设置登录级别的变量,重新登录shell即可,或者source /etc/profile。
原来:
设置环境变量通常写在/etc/profile里面,现在看来真的很low,如果上百个应用,那么找得到和修改得到是不同的两码事!那么问题来了,升级后的做法是在/etc/profile.d/目录下新建以应用命令的shell文件即可,然后不需要的变量直接删除对于的shell文件。
现在:
同样的写法,只不过在/etc/profile.d/目录下新建对应的shell即可,比如新建java的:
vi /etc/profile.d/java.sh
export JAVA_HOME=/data/service/java
原理:
无论在Linux还是再Mac下,都可以用这个方式去实现,分析/etc/profile这个文件你会发现有这么一段shell,这个就是关键所在:
写入:
JAVA_HOME=/opt/module/jdk8
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export JAVA_HOME PATH CLASSPATH
或者:
JAVA_HOME=/opt/module/jdk8
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME PATH
export可以放在前面也可以集中
让刚才的修改生效
source /etc/profile
*如果需要新建文件夹(递归新建):
mkdir -p xxxx
4.3 hadoop安装
解压hadoop
tar -zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz -C /opt/module/
可以利用mv该文件夹名字:
mv hadoop-3.3.0/ hadoop3/
打开profile.d中的自己的环境sh文件:
添加下列命令:
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
测试:
hadoop version
知识储备:
Hadoop目录结构:

bin的结构(存放命令):
sbin集群的命令与其他命令(比如启动脚本):
etc放的是配置文件:

配置文件:重要的四大配置文件
lib(编译后的):

在
/opt/module/hadoop3/share/hadoop/mapreduce
路径下是些jar包(一些案例)
examples-3.3.0的案例(可以当下来)
服务器运行模式:
文档: Apache Hadoop 3.3.2 – Hadoop: Setting up a Single Node Cluster.


运行官方案例(单词统计):
切换到目录:

新建目录:
mkdir wcinput
cd 进input目录
touch a.txt
写入一些东西
运行:wordcoun注意,是类名,不可乱写
hadoop jar /opt/module/hadoop3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount ./wcinput ./wcoutput
通过分析日志:
-
output不需要创建
启动了mapreduce:
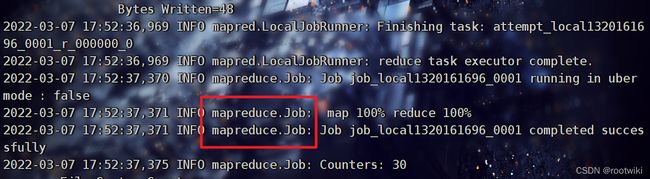
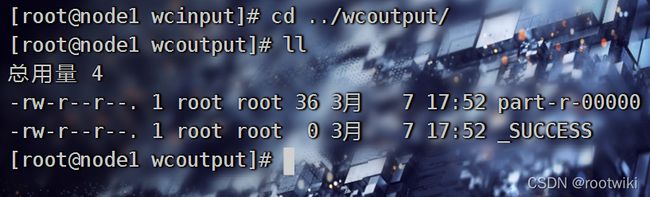


//此时完全没有用到hdfs和yarn的配置
4.4克隆虚拟机:
共三台:参照第二步即可
4.5修改虚拟机的网卡mac地址:
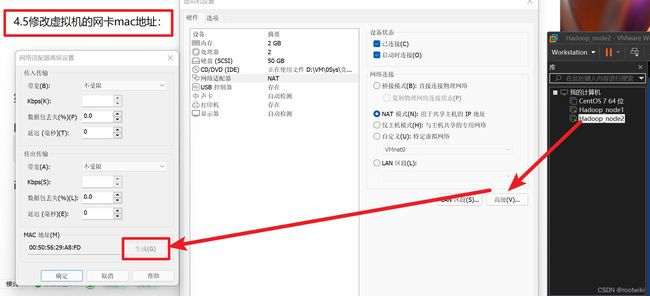
不然无法上网,网卡冲突了
然后修改主机名字和ip地址:
永久修改主机名如果要修改静态主机名,
vim /etc/hostname 文件
然后重启主机:
reboot
第五步:集群搭建:
5.1知识储备:
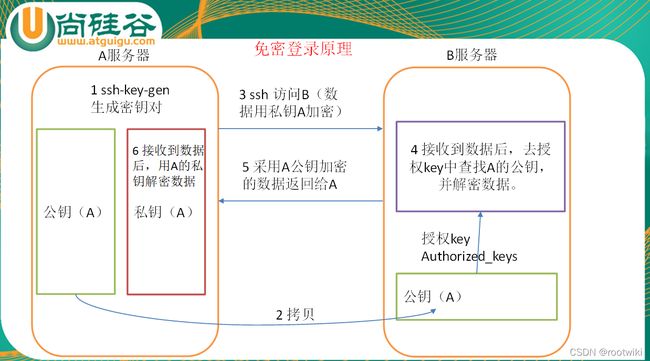
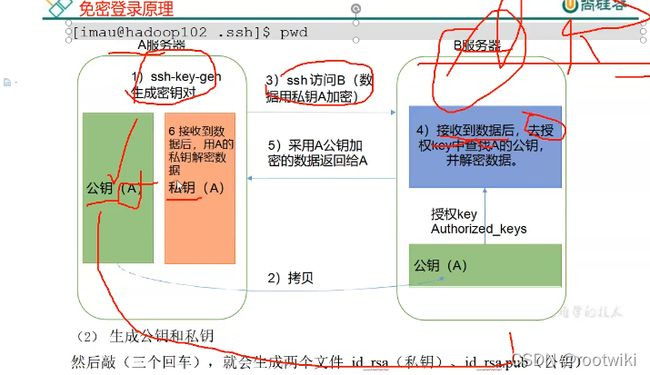
ssh免密码登录原理:
5.2在windwos下可以直接用名字访问虚拟主机:
hosts的配置映射文件:
C:\Windows\System32\drivers\etc\hosts
路径: C:\Windows\System32\drivers\etc
C:\Windows\System32\drivers\etc
ip地址后跟上名字:

192.168.10.102 node01
192.168.10.103 node02
192.168.10.104 node03
在linux下:查看:
cat /etc/hosts
路径是:
/etc/hosts 文件
5.3 SSH免密码登录实操:
打开远程root登录权限:
vim /etc/ssh/sshd_config
找到permit root即可
公钥私钥生成:
首先进入root用户或者当前用户的家目录:
找到.ssh文件夹

第一次登录才会生成
这是没有配免密登录的
进到.ssh目录下
生成私钥公钥(使用rsa算法)
ssh-keygen -t rsa
三次回车
然后ssh-copy-id Node2

输入密码或者没登录过就可以yes
然后顺序每个都互相配:
[root@node1 .ssh]# ssh-copy-id Node2
以此类推配好你的N台
然后可以快照
集群规划:

对于hdfs:
第一台namenode,另一台装snn
用配置文件规划:
路径在:
/opt/module/hadoop3/etc/hadoop

最好拿出来这些文件编辑:
1、下载到本地
2、快速下载到本地命令
3、可以用finalshell打开
编辑workers
写入三个节点名字,不要有空格,去掉localhost

第一次启动先格式化hdfs
hdfs namenode -format
集群启动:
start-all.sh
或者start-dfs.sh
加上start-yarn.sh
集群结束:
stop-all.sh
或者stop-dfs.sh
加上stop-yarn.sh
需要正确配置的文件:
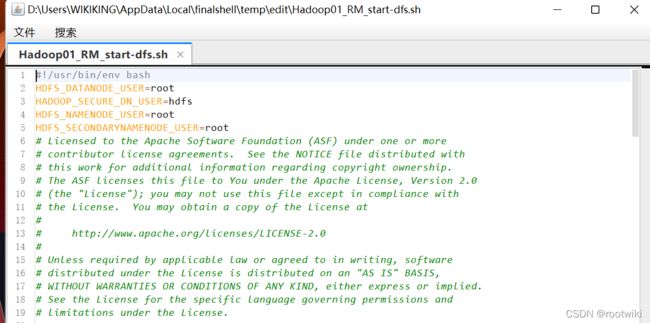
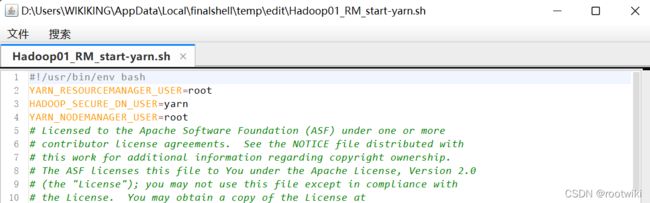
遇到的问题:
解决:是xml文档写错了
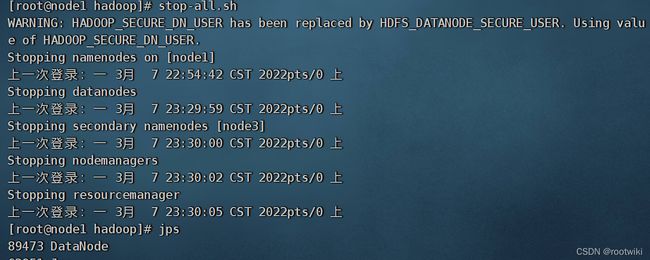
尚需解决的警告:
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
需要修改文件:
start-dfs.sh和stop-dfs.sh修改为:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
然后结束集群运行
群发文件start-dfs.sh和stop-dfs.sh
开启集群
hadoop jar /opt/module/hadoop3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output
附件:
hadoop集群搭建初步xml文件8个以及集群群发脚本2个-Hadoop文档类资源-CSDN下载
附注命令:
rz 上传
sz 下载
安装命令:
yum install -y lrzsz