理解Spark中RDD(Resilient Distributed Dataset)
文章目录
- 1 RDD 基础
-
- 1.1 分区
- 1.2 不可变
- 1.3 并行执行
- 2 RDD 结构
-
- 2.1 SparkContext、SparkConf
- 2.2 Partitioner
- 2.3 Dependencies
- 2.4 Checkpoint(检查点)
- 2.5 Storage Level(存储级别)
- 2.6 Iterator(迭代函数)
- 3 依赖关系
- 4 RDD操作
-
- 4.1 转化操作
- 4.2 行动操作
- 4.3 惰性求值
- 4.4 持久化
- 5 Spark 程序工作流程
- 参考
1 RDD 基础
Spark对数据的核心抽象就是RDD(弹性分布式数据集)。RDD其实就是分布式的元素集合。
关于RDD的定义:RDD 表示已被分区、不可变的,并能够被并行操作的数据集合
下面是对定义的解释:
1.1 分区
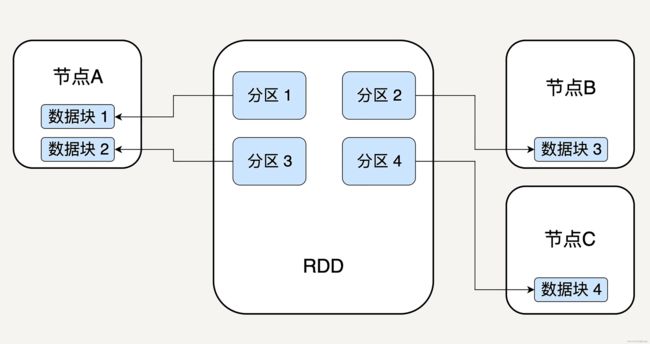
逻辑上,可以认为 RDD 是一个大的对象集合, 集合中的每个元素代表一个分区(Partition)。
在物理存储上,RDD中实际不存储实际的数据信息,而是每个分区指向一个存放在内存或者硬盘中的数据块(Block),而这些数据块是独立的,它们可以被存放在系统中的不同节点。
每个分区都包含在RDD中的Index以及指向的数据块信息,这样通过指定RddID+Index就能唯一指定数据块并进行处理了
1.2 不可变
不可变性代表每一个 RDD 都是只读的,它所包含的分区信息不可以被改变。既然已有的 RDD 不可以被改变,我们只可以对现有的 RDD 进行 转换(Transformation) 操作,得到新的 RDD 作为中间计算的结果。
1.3 并行执行
因为RDD数据块实际分布在不同节点上存储,所以就可以对数据并行执行
2 RDD 结构
RDD 结构简图如下所示
2.1 SparkContext、SparkConf
SparkContext 是所有 Spark 功能的入口,它代表了与 Spark 节点的连接,可以用来创建 RDD 对象以及在节点中的广播变量等。一个线程只有一个 SparkContext。SparkConf 则是一些参数配置信息。

2.2 Partitioner
Partitioner 决定了 RDD 的分区方式,目前有两种主流的分区方式:Hash partitioner 和 Range partitioner。Hash,顾名思义就是对数据的 Key 进行散列分区,Range 则是按照 Key 的排序进行均匀分区。此外还可以创建自定义的 Partitioner。
2.3 Dependencies
每个 RDD 里都会存储它的依赖关系,即它是通过哪个 RDD 经过哪个转换操作得到的。
2.4 Checkpoint(检查点)
在计算过程中,对于一些计算过程比较耗时的 RDD,我们可以将它缓存至硬盘或 HDFS 中,标记这个 RDD 有被检查点处理过,并且清空它的所有依赖关系。同时,给它新建一个依赖于 CheckpointRDD 的依赖关系,CheckpointRDD 可以用来从硬盘中读取 RDD 和生成新的分区信息。
这样,当某个子 RDD 需要错误恢复时,回溯至该 RDD,发现它被检查点记录过,就可以直接去硬盘中读取这个 RDD,而无需再向前回溯计算。
2.5 Storage Level(存储级别)
存储级别(Storage Level)是一个枚举类型,用来记录 RDD 持久化时的存储级别,常用的有以下几个:
- MEMORY_ONLY:只缓存在内存中,如果内存空间不够则不缓存多出来的部分。这是 RDD 存储级别的默认值。
- MEMORY_AND_DISK:缓存在内存中,如果空间不够则缓存在硬盘中。
- DISK_ONLY:只缓存在硬盘中。
- MEMORY_ONLY_2/MEMORY_AND_DISK_2 等:与上面的级别功能相同,只不过每个分区在集群中两个节点上建立副本。
2.6 Iterator(迭代函数)
迭代函数用来表示 RDD 怎样通过父 RDD 计算得到的。
它会首先判断缓存中是否有想要计算的 RDD,如果有就直接读取,如果没有,就查找想要计算的 RDD 是否被检查点处理过。如果有,就直接读取,如果没有,就调用计算函数向上递归,查找父 RDD 进行计算。
3 依赖关系
RDD 和它依赖的父RDD 的关系有两种不同的类型, 即窄依赖( narrowdependency) 和 宽依赖(wide dependency)
窄依赖就是父 RDD 的分区可以一一对应到子 RDD 的分区,宽依赖就是父 RDD 的每个分区可以被多个子 RDD 的分区使用。
即窄依赖的父RDD必须有一个对应的子RDD,也就是说父RDD的一个分区只能被子RDD一个分区使用,但是反过来子RDD的一个分区可以使用父RDD的多个分区。也就是说只有父RDD的分区被多个子RDD的分区利用的时候才是宽依赖,其他的情况就是窄依赖。
可以形象化记忆:
窄依赖:一子多父,一子一父
宽依赖:一父多子
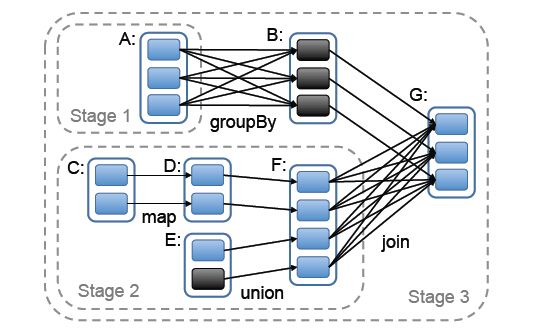
下图左边是窄依赖,右边是宽依赖

stage的划分是Spark作业调度的关键一步,它基于DAG确定依赖关系,借此来划分stage,将依赖链断开,每个stage内部可以并行运行,整个作业按照stage顺序依次执行,最终完成整个Job。Spark利用依赖关系,调度器从DAG图末端出发,逆向遍历整个依赖关系链,在宽依赖关系处就会断开依赖链,划分stage。
4 RDD操作
RDD支持两种操作:转化操作(Transformation) 和 行动操作(Action),转换是用来把一个 RDD 转换成另一个 RDD,而行动则是通过计算返回一个结果。
两种操作返回值类型不同,转化操作返回的是 RDD, 而行动操作返回的是其它的数据类型。
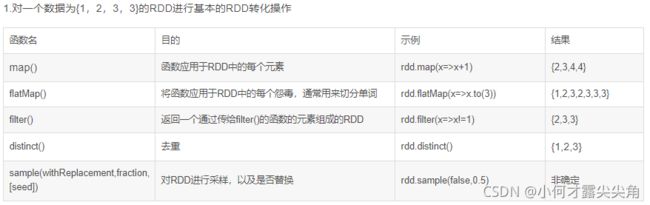
4.1 转化操作

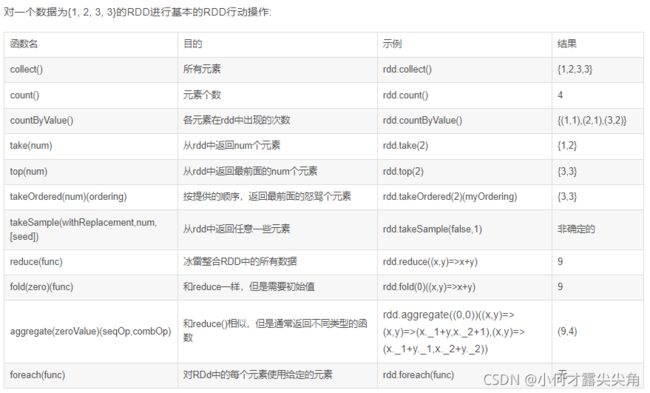
4.2 行动操作
4.3 惰性求值
RDD 的转化操作都是惰性求值的,也就意味着在调用行动操作之前Spark不会开始计算,而是只记录转化操作的依赖关系
4.4 持久化
RDD 是惰性求值的,当我们对 RDD 调用一个新的 action 操作时,整个 RDD 都会从头开始运算。因此,如果某个 RDD 会被反复重用的话,每次都从头计算非常低效,我们应该对多次使用的 RDD 进行一个持久化操作。
Spark 的 persist() 和 cache() 方法支持将 RDD 的数据缓存至内存或硬盘中,这样当下次对同一 RDD 进行 Action 操作时,可以直接读取 RDD 的结果,大幅提高了 Spark 的计算效率。
RDD持久化与RDD结构中 Checkpoint 区别:
Checkpoint 在 action之后执行,相当于事务完成后备份结果。既然结果有了,之前的计算过程,也就是RDD的依赖链,也就不需要了,所以不必保存。
但是cache和persist只是保存当前RDD,并不要求是在action之后调用。相当于事务的计算过程,还没有结果。既然没有结果,当需要恢复、重新计算时就要重放计算过程,自然之前的依赖链不能放弃,也需要保存下来。需要恢复时就要从最初的或最近的checkpoint开始重新计算。
5 Spark 程序工作流程
简单来说,每个 Spark 程序都会按如下方式工作:
(1) 读取数据创建 RDD
(2) 使用诸如 filter() 等转化操作函数对 RDD 进行转化,生成新的 RDD
(3) 利用 persist() 或 cache() 函数对需要重用的中间结果 RDD 持久化
(4) 使用行动操作触发一次并行计算,Spark 会对计算进行优化后再执行
(5) 使用 unpersist() 方法把持久化的 RDD 从缓存中移除
参考
RDD之间的依赖关系
弹性分布式数据集:Spark大厦的地基
Spark RDD常见的转化操作和行动操作
《Spark快速大数据分析》 Holden Karau