三、ElasticSearch集群搭建实战
- 本篇ES集群搭建主要是在Linux VM上,未使用Docker方式, ES版本为7.10 ,选择7.10版本原因可以看往期文章介绍。
一、ElasticSearch集群搭建须知
JVM设置
Elasticsearch是基于Java运行的,es7.10可以使用jdk1.8 ~ jdk11之间的版本,更高版本还没测试过。ES运行期间很多计算都需要大量内存,所以内存这块需要提前根据机器规格进行适当配置,内存越大越好,单实例JVM堆内存官方建议最大设置到30G。
集群节点数
单个ES集群节点数据可以达到几百到上千,当单个集群满足不了业务时可以再搭新的ES集群。集群节点数以单数最好,可以避免脑裂,不过7.x及以上版本官方已经进行了优化,基本不会出现脑裂问题了。
ES启动用户
Linux下启动ES不能使用root用户, 需要单独建个系统用户来启动ES 。
二、ES集群部署架构
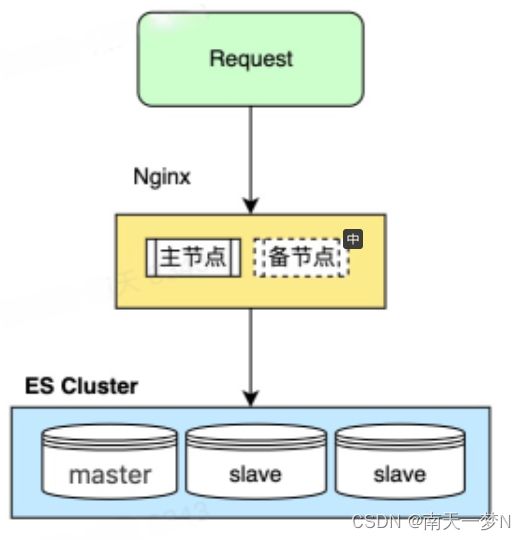
下面示例是以三个机器实例来搭建的ES集群
单集群示例
-
集群每个节点都可以设置为可参与master选举及是否是数据节点
多集群示例
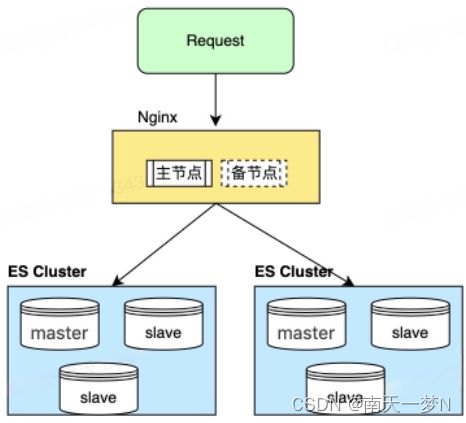
相较于单集群,多集群上层可以加一层负载均衡,统一管理及路由,方便业务使用。
集群访问规范建议
出于安全及后续维护综合考虑,ES集群对外提供访问地址最好是一个域名,这样能避免IP到处暴露,也避免IP较高频率变化而导致系统经常升级。
三、ES集群搭建实战
软件下载
es官方下载地址,es和kibana尽量下载同一版本
-
elasticsearch各版本下载地址
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
-
kibana (es的可视化管理工具)
Past Releases of Elastic Stack Software | Elastic

搭建步骤
以下搭建步骤均基于ES7.10版本,以该步骤在笔者公司内部测试环境、生产环境成功搭建过多次,并已稳定运行一年多。其它6.x、8.x版本搭建过程有些差异,请大家认准版本。
搭建过程中如果遇到问题也可以参考官方对应版本文档说明,以下是7.10官方文档。
Installing Elasticsearch | Elasticsearch Guide [7.10] | Elastic
搭建集群时先在一台实例上把ES搭建好后,再Copy到实例上进行配置修改。
1、堆内存设置 - jvm.options
启动前先设置ES占用的堆内存,es还是需要比较多的内存,可以根据机器规则来设置。如果机器只有4g内存可以设置2-3g,如果是8g的话可以设置为6g,16G的话可以设置到14G。剩余一部分留给系统。
-Xms6g
-Xmx6g如果在linux下启动出现以错时需要修改linux系统配置
max virtual memory areas vm.max_map_count [65530] is too low, increase to at
是因为系统虚拟内存默认最大映射数为65530,无法满足ES要求,需要调整为262144以上。
sudo vim /etc/sysctl.conf
#添加参数
vm.max_map_count = 262144
#重新加载配置
sysctl -p
2、先搭建ES单个节点
先找任一个节点修改elasticsearch.yml,并添加以下配置(此时不要添加集群和证书配置)
#数据和日志目录
path.data: /opt/data
path.logs: /opt/logs
#http访问端口,程序或kibana使用
http.port: 9200
#开启安全访问,集群搭建必选
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true3、启动ES
#启动命令,注意要使用非root账户
./bin/elasticsearch观察启动是否ok,若ok进行第三步
4、设置安全账号信息(ES要启动状态)
-
执行以下命令,给各账号设置密码,整个集群只需要设置一次即可
-
bin/elasticsearch-setup-passwords interactive警告:设置账户密码切记要在单实例非集群模式时配置,不能添加任何集群的配置,否则会设置失败
-
似乎有8个账户都需要设置密码,方便期间密码全部设置成一样的即可,后续还可以再改。
5、添加ES集群配置信息
-
集群搭建需要开启安全验证,开启安全需要用到证书,证书生成参考【ES集群安全策略设置 X-pack】,生成后进行以下配置
-
elasticsearch.yml加入以下配置
-
以下配置是集群搭建的关键配置,配置错就会导致集群节点之间可能无法通信、节点不能加入集群等各种问题
#数据和日志存储路径
path.data: /opt/data
path.logs: /opt/logs
#数据备份和恢复使用,可以一到多个目录
path.repo: ["/opt/backup/es", "/opt/backup/es1"]
#http访问端口,程序或kibana使用
http.port: 9200
#集群名称
cluster.name: es001
#节点名,每个节点名不能重复
node.name: node1
#是否可以参与选举主节点
node.master: true
#是否是数据节点
node.data: true
#允许访问的ip,4个0的话则允许任何ip进行访问
network.host: 0.0.0.0
#es各节点通信端口
transport.tcp.port: 9300
#集群每个节点IP地址,搭建过程一个一个填写,比如搭建第一个节点时,只填写一个ip和节点信息
discovery.seed_hosts: ["xxx.xx.xx.xx:9300", "xx.xx.xx:9300", "xx.xx.xx:9300"]
#es7.x新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2", "node3"]
#配置是否压缩tcp传输时的数据,默认为false,不压缩
transport.tcp.compress: true
# 是否支持跨域,es-header插件使用
http.cors.enabled: true
# *表示支持所有域名跨域访问
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,X-Requested-With,Content-Type,Content-Length
#集群模式开启安全 https://www.elastic.co/guide/en/elasticsearch/reference/7.17/security-minimal-setup.html
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: certs/elastic-certificates.p12
#默认为1s,指定了节点互相ping的时间间隔。
discovery.zen.fd.ping_interval: 1s
#默认为30s,指定了节点发送ping信息后等待响应的时间,超过此时间则认为对方节点无响应。
discovery.zen.fd.ping_timeout: 30s
#ping失败后重试次数,超过此次数则认为对方节点已停止工作。
discovery.zen.fd.ping_retries: 3以上配置添加好后重启ES,验证是否能启动成功,如果启动不成功可根据ES日志进行排查解决,或者重新进行搭建。
是否启动成功可以使用以下方式进行验证
curl -XGET -u elastic:password localhost:9200/_cat/indices?v
curl -XGET -u elastic:password localhost:9200/_cat/health?v
在命令行行执行后看是否有数据返回,如果开启了安全验证,需要把上面的账号密码替换掉。
6、配置集群其它节点
第5步如果验证成功后,可以把该实例的整个ES程序及配置打包copy到其它节点上,然后再修改elasticsearch.yml配置,重点是把节点名称及节点IP配置信息修改好,改好后直接启动该节点ES。
注意启动时观察日志是否有异常信息。
7、集群验证
当启动第二个节点后最好先验证节点是否已经加到集群里了,如果未成功加入集群说明搭建方法出现了问题,此时需要先把问题解决掉再进行后续的集群搭建。
节点启动成功并不代表集群搭建就是成功后的,我们可以用以下两种方式来组合验证集群是否成功搭建:
-
1、使用系统命令查看集群节点数量
curl -XGET -u elastic:password http://127.0.0.1:9200/_cluster/health?pretty"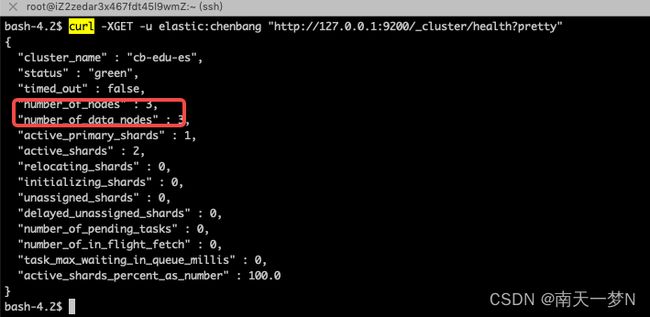
如果此时集群中有三个节点,执行以上操作后也返回了节点数量为3,则说明节点都已成功加入了集群。
-
2、创建一个索引看集群中每个节点索引数据是否一致
如果集群搭建成功,我们创建索引后ES集群会自动同步索引数据到所有的节点上,所以借助这点我们可以准确验证集群是否真正搭建成功。
步骤:
- 1)首先在任意节点执行一个索引创建命令
curl -XPUT -u elastic:password "http://127.0.0.1:9200/test-index"以上创建了一个名为『test-index』的索引
-
2) 查看其它节点索引是否一致
-
curl -XGET -u elastic:password "http://localhost:9200/_cat/indices?pretty"
分别在每个节点执行以上命令看所有节点是否返回一致,如果集群搭建正常,在任意一个节点创建索引后都会自动同步到其它节点,如果返回不一致则认为集群搭建的是有问题的。
如果以上验证成功后,其它节点重复5、6步即可。
四、集群配置优化
1、关闭索引自动创建
-
待es集群搭建完启动成功后,执行以下命令可以关闭索引自动创建功能,当然也可以不关闭,不关闭的话,在程序中调用ES Api保存数据时候如果索引不存在则会自动创建索引,线上环境可能会带来一些安全问题,所以尽量还是关闭由专门负责人统一来管理索引维护。
PUT _cluster/settings { "persistent": { "action.auto_create_index": "false" } }以上命令是在kibana中执行
注:如果后续装x-pak,可能需要修改 action.auto_create_index 值
2、修改es集群索引默认分片数
7.x版本默认是1分片1备份,集群场景下1分片会完全不能发挥集群性能,所以需要设置一下默认分片数量,具体设置多少可以根据节点数,比如按2n来设置,3个节点,分片数可以设置为6。
副本数1即可。
PUT _template/template_http_request_record
{
"index_patterns": [
"*"
],
"settings": {
"number_of_shards": 6,
"number_of_replicas": 1
}
}index_patterns = * 代表对所有索引生效
number_of_shards 是索引主分片数.
number_of_replicas 是备份数量.
-
ES集群模式数据分布原理
-
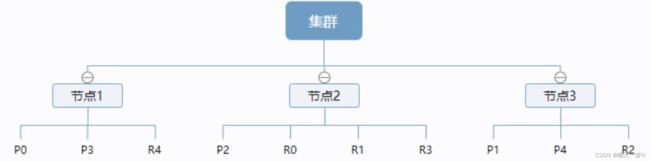
一个ES集群至少有一个节点,一个节点就是一个 elasricsearch 进程,每个节点可以有多个索引,如果创建索引时设置为5个分片,一个副本,那么索引数据将会均匀划分到 5 个分片上 (primary shard,又称主分片),每个分片有一个副本(replica shard,又称复制分片)。为了保证数据的稳定性es会把某个分片及副本存储在不同的实例上。
希望本文能帮助顺利完成ES集群搭建
往期文章
Elasticsearch入门必读指南:到底选择哪个ES版本更合适