基于PaddleDetection的锥桶检测并在Gazebo环境中实现部署
点击左上方蓝字关注我们

【飞桨开发者说】吴瀚,武汉理工大学本科在读,人工智能技术爱好者、飞桨开发者,希望能将AI技术更好地落地实践、服务生活。感兴趣的方向有:计算机视觉、迁移学习、推理部署。

项目简介

本项目基于飞桨开发套件PaddleDetection,实现在Gazebo环境中的锥桶检测,并使用Paddle Inference2.0实现在X86 Linux环境中的部署。
Gazebo是一款优秀的开源物理仿真环境,具备强大的物理引擎、高质量的图形渲染、方便的编程与图形接口。Gazebo的使用往往和ROS一起,这样开发仿真能力可以大大增强,为广大算法开发者在硬件实践前提供了完美的算法检验仿真环境。
项目开始前,咱们先介绍一下本项目使用到的两个工具:
PaddleDetection
PaddleDetection是飞桨的目标检测开发套件,模块化集成了主流的目标检测算法,并向用户提供了丰富且自由的接口实现数据增强、自定义网络模块、损失函数、训练配置等。同时,该套件也可以结合飞桨推理部署工具Paddle Inference和Paddle Lite实现在业务环境中的高性能部署。
Paddle Inference
Paddle Inference 是飞桨的原生推理库,提供高性能的推理推理引擎,使用范围包括服务器端、云端以及不能使用Paddle Lite的嵌入式设备。所谓原生推理库,即飞桨能实现的op,Paddle Inference不需要通过任何类型转换就可以实现,并且同时提供C、C++、Python的预测API,方便开发者在不同场景中进行使用。
项目方案
1.数据集制作
因为没有合适的仿真环境锥桶数据集,所以只能自己根据需求制作。自己做数据集的好处是针对性强、数据集质量高,缺点嘛,就是有点小辛苦。
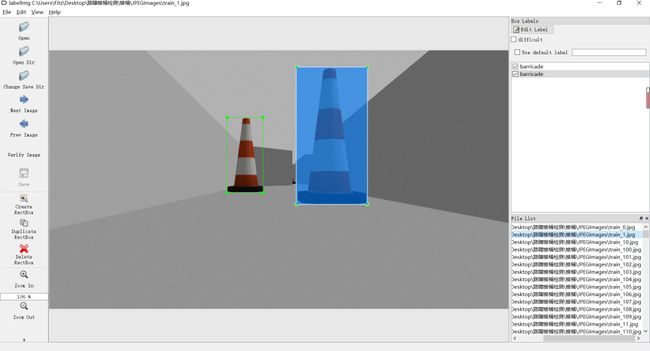
对于数据集的图片,首先在Gazebo环境中用手动方向键驱动仿真小车从各角度拍的锥桶视频,再从视频中抽帧得到图片,标注采用的工具是开源的标注工具LableImg,标记后自动生成xml文件,符合VOC数据集读取格式。考虑到应用部署时只需要检测锥桶这一类物品,种类单一,且仿真环境中背景简单变化小,所以训练数据不需要过多,最终从视频流中筛选出视角合适的520张数据作为数据集。该数据集已在AI Studio上公开,详情请戳链接:
https://aistudio.baidu.com/aistudio/datasetdetail/43886。
2.模型训练与导出
2.1 生成训练集与测试集
标记完的图片只有图片和对应的xml标注。这里,我按照9:1划分了训练集和测试集,并生成了对应的label_list.txt。请大家注意,生成的txt文件要符合PaddleDetection读取格式:图片路径/图片名 标签路径/标签名。
!mkdir barricade/ImageSets
train = open('barricade/ImageSets/train.txt', 'w')
test = open('barricade/ImageSets/test.txt', 'w')
label_list = open('barricade/label_list.txt', 'w')
xml_path = "./Annotations/"
img_path = "./JPEGImages/"
count = 0
for xml_name in os.listdir('barricade/Annotations'):
data =img_path + xml_name[:-4] + ".jpg " + xml_path + xml_name + "\n"
if(count%10==0):
test.write(data)
else:
train.write(data)
count += 1
label_list.write("barricade")
train.close()
test.close()
label_list.close()2.2 配置训练参数
前面已经介绍了PaddleDetection开发套件,使用这个套件最方便的点就是不需要自己搭建复杂的模型。这不仅可以快速进行迁移学习,训练中的参数也可以直接在yml环境文件中进行修改,简单方便易操作。具体步骤总结为:
点开PaddleDetection/configs目录,在其中挑选自己要用的模型;
点开挑选好的模型yml文件,进行配置的修改,其中主要注意三点:
数据集格式:PaddleDetecion支持读取的格式有VOC 、COCO、wider_face和fruit四种数据集。对于初学者,我建议使用原本yml设置好的数据集格式。
数据集读取目录:将dataset_dir改为数据集的根目录路径,同时将TrainReader和Testreder中数据集路径更改为2.1步中生成的对应txt文件。
训练策略:在yml文件中主要改的几个参数是:
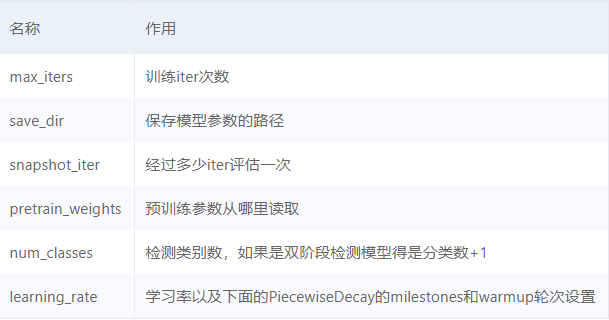
本次检测任务目标种类单一、环境简单、特征明显,但考虑到部署模型的时候还会运行其他ROS功能包,因此,我选择了轻量级的YOLOV3-MobilenetV1作为检测模型。对于使用YOLO的检测任务,我们也可以使用PaddleDetection提供的脚本,在自己的数据集上实现聚类得到最佳初始anchor大小,并在yml中进行修改:
!python PaddleDetection-release-2.0-rc/tools/anchor_cluster.py -c PaddleDetection-release-2.0-rc/configs/yolov3_mobilenet_v1_voc.yml -n 9 -s 416 -i 1666对应的yml配置如下:
architecture: YOLOv3
use_gpu: true
max_iters: 1024
log_smooth_window: 20
save_dir: output
snapshot_iter: 80
metric: VOC
map_type: 11point
pretrain_weights: output/yolov3_mobilenet_v1_voc/best_model #http://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV1_pretrained.tar
weights: output/yolov3_mobilenet_v1_voc/model_final
num_classes: 1
use_fine_grained_loss: false
YOLOv3:
backbone: MobileNet
yolo_head: YOLOv3Head
MobileNet:
norm_type: sync_bn
norm_decay: 0.
conv_group_scale: 1
with_extra_blocks: false
YOLOv3Head:
anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
anchors: [[22, 79],[25, 84],[27, 108],[34, 124],[39, 133],[50, 172],[80, 257],[131, 303],[195, 353]]
norm_decay: 0.
yolo_loss: YOLOv3Loss
nms:
background_label: -1
keep_top_k: 100
nms_threshold: 0.45
nms_top_k: 1000
normalized: false
score_threshold: 0.01
YOLOv3Loss:
# batch_size here is only used for fine grained loss, not used
# for training batch_size setting, training batch_size setting
# is in configs/yolov3_reader.yml TrainReader.batch_size, batch
# size here should be set as same value as TrainReader.batch_size
batch_size: 8
ignore_thresh: 0.7
label_smooth: false
LearningRate:
base_lr: 0.001
schedulers:
- !PiecewiseDecay
gamma: 0.1
milestones:
- 400
- 700
- !LinearWarmup
start_factor: 0.
steps: 100
OptimizerBuilder:
optimizer:
momentum: 0.9
type: Momentum
regularizer:
factor: 0.0005
type: L2
_READER_: 'yolov3_reader.yml'
TrainReader:
dataset:
!VOCDataSet
dataset_dir: barricade
anno_path: ImageSets/train.txt
use_default_label: false
with_background: false
EvalReader:
inputs_def:
fields: ['image', 'im_size', 'im_id', 'gt_bbox', 'gt_class', 'is_difficult']
num_max_boxes: 50
dataset:
!VOCDataSet
dataset_dir: barricade
anno_path: ImageSets/test.txt
use_default_label: false
with_background: false
TestReader:
dataset:
!ImageFolder
anno_path: barricade/label_list.txt
use_default_label: false
with_background: false2.3训练与导出模型
配置好yml文件之后,我们就可以开始快乐炼丹了。在AI Studio中启动训练命令为:
!python PaddleDetection-release-2.0-rc/tools/train.py -c PaddleDetection-release-2.0-rc/configs/yolov3_mobilenet_v1_voc.yml --eval --use_vdl=True --vdl_log_dir=vdl训练过程中,PaddleDetection会将一些重要参数打印到LOG中,方便用户查看。我们也可以通过VisualDL对训练过程进行可视化。
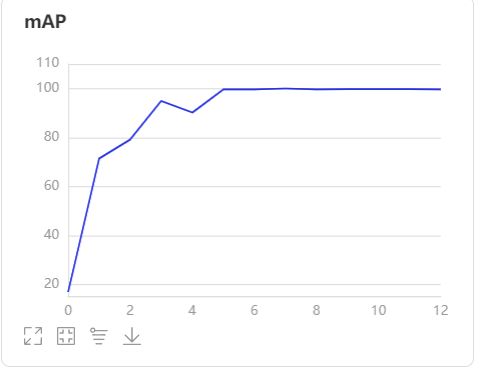
因为任务比较简单,训练几轮后指标都挺好的,测试集上mAP轻轻松松95+,所以我就直接导出了。PaddleDetection也提供导出模型脚本export_model.py:
!python PaddleDetection-release-2.0-rc/tools/export_model.py -c PaddleDetection-release-2.0-rc/configs/yolov3_mobilenet_v1_voc.yml \
--output_dir=inference_model \
-o weights=output/yolov3_mobilenet_v1_voc/best_model之后,设置的inference_model目录下就会生成相应的部署文件,一共有三个:model、params和infer_cfg.yml。有这三个文件,我们就可以开始部署了!
3.部署流程
以上步骤中,我使用飞桨深度学习框架完成了模型的训练。但是,大家应该知道,训练过程中的反向传播有很多参数,而这些参数在实际使用正向推导时是没有用的。这也是上一步导出模型的意义,即把反向传播的一些参数全部去掉,只保留核心的正向推导参数,导出后剩下的参数都能对正向推导起到作用。
对于推理部署,飞桨提供了两种方法Paddle Lite和Paddle Inference。两种推理工具,我都使用过,个人感受如下:Paddle Lite主要针对移动端,而Paddle Inference是针对服务器端、云端和无法使用Paddle Lite的嵌入式设备,两者都能提供高性能推理引擎。这次我的部署环境是X86 Linux,所以就采用Paddle Inference2.0,并用Python API实现部署。
3.1 Paddle Inference2.0安装
部署环境是X86的Linux,可以直接参考官网步骤安装飞桨深度学习框架,并调用Paddle Inference进行推理。值得注意的是,本项目推理部署采用了Paddle Inference 2.0,请正确安装版本。
官网安装链接:
https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/2.0/install/pip/windows-pip.html
3.2 Paddle Inference推理步骤
部署推理,其实就是训练的前向传播部分。不同的是,训练时我们通过模型得到结果,而在推理时是通过一个推理引擎。但思路是一样的,具体为:
配置推理引擎的Config;
创建推理引擎Predictor;
读取图片+图片预处理;
将图片送入推理引擎进行正向推理;
得到预测结果;
对应代码实现为:
import cv2
import numpy as np
from paddle.inference import Config
from paddle.inference import create_predictor
def predicte(img,predictor):
input_names = predictor.get_input_names()
for i,name in enumerate(input_names):
#定义输入的tensor
input_tensor = predictor.get_input_handle(name)
#确定输入tensor的大小
input_tensor.reshape(img[i].shape)
#对应的数据读进去
input_tensor.copy_from_cpu(img[i].copy())
#开始预测
predictor.run()
#开始看结果
results =[]
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_handle(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
def preprocess(img , Size):
img = cv2.resize(img,(Size,Size),0,0)
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
img = img / 255.0
mean = np.array(mean)[np.newaxis, np.newaxis, :]
std = np.array(std)[np.newaxis, np.newaxis, :]
img -= mean
img /= std
img = img.astype("float32").transpose(2,0,1)
img = img[np.newaxis,::]
return img
if __name__ == '__main__':
#读入的摄像头信息根据大家自己ROS结点自己读入咯,这里我就直接用摄像头读取替代了,大家到时候这里自己更换进行
cap = cv2.VideoCapture(1)
config = Config()
config.set_model("inference_model/yolov3_mobilenet_v1_voc/__model__","inference_model/yolov3_mobilenet_v1_voc/__params__")
config.disable_gpu()
config.enable_mkldnn()
predictor = create_predictor(config)
im_size = 416
im_shape = np.array([416, 416]).reshape((1, 2)).astype(np.int32)
while(1):
success, img = cap.read()
if (success == False):
break
img = cv2.resize(img, (im_size,im_size),0, 0)
data = preprocess(img, im_size)
results = trash_detect(trash_detector, [data, im_shape])
for res in results[0]:
if (res[1]>0.5):
img = cv2.rectangle(img, (int(res[2]), int(res[3])), (int(res[4]), int(res[5])), (255, 0, 0), 2)
cv2.imshow("img", img)
cv2.waitKey(10)
cap.release()实际部署效果:

4.总结
首先,Gazebo环境中摄像头的ROS结点名因人而异,需要大家自己更改读入的视频数据。
其次,本项目使用飞桨框架2.0完整展示了数据集制作、模型选取、模型训练、模型导出以及模型部署的全流程实践,在Gazebo环境中成功使用飞桨框架实现了锥桶检测,为之后在Gazebo中实现深度学习的路径规划提供强力保证。
最后,本推文配合AI Studio项目食用更佳,详情请查看项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/1608121
如在使用过程中有问题,可加入官方QQ群进行交流:
PaddleDetection群:1136406895
飞桨推理部署交流群:959308808
如果您想详细了解更多相关内容,请参阅以下文档。
·飞桨官网地址·
https://www.paddlepaddle.org.cn/
·PaddleDetection项目地址·
GitHub:
https://github.com/PaddlePaddle/PaddleDetection
Gitee:
https://gitee.com/paddlepaddle/PaddleDetection
·Paddle Inference简介·
https://paddleinference.paddlepaddle.org.cn/product_introduction/inference_intro.html
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END
