webassembly003 TTS BARK.CPP-02-bark_tokenize_input(ctx, text);
bark_tokenize_input函数
- bark是没有语言控制选项的,但是官方的版本无法运行中文
- bark_tokenize_input会调用bert_tokenize函数,bark_tokenize_input函数对中文分词失效,也就是导致不支持中文的原因。
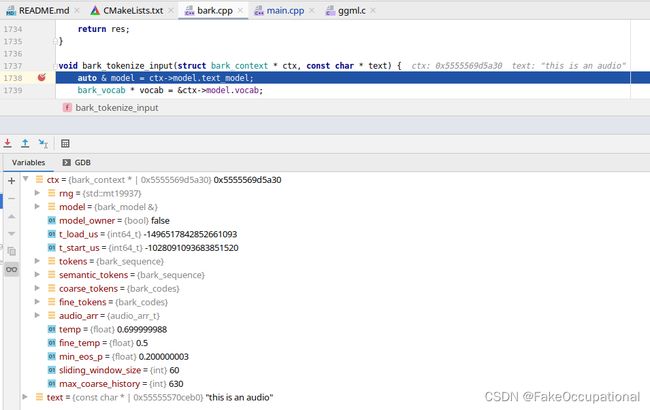
void bark_tokenize_input(struct bark_context * ctx, const char * text) {
auto & model = ctx->model.text_model;
bark_vocab * vocab = &ctx->model.vocab;
int32_t block_size = model.hparams.block_size;
int32_t max_ctx_size = std::min(block_size, 256);
int32_t n_tokens;
bark_sequence tokens(max_ctx_size);
bert_tokenize(vocab, text, tokens.data(), &n_tokens, max_ctx_size);
for (int i = 0; i < (int) tokens.size(); i++)
tokens[i] += TEXT_ENCODING_OFFSET;
if (n_tokens < max_ctx_size) {
for (int i = n_tokens; i < max_ctx_size; i++)
tokens[i] = TEXT_PAD_TOKEN;
} else if (n_tokens > max_ctx_size) {
fprintf(stderr, "%s: input sequence is too long (%d > 256), truncating sequence", __func__, n_tokens);
}
tokens.resize(max_ctx_size);
// semantic history
for (int i = 0; i < 256; i++)
tokens.push_back(SEMANTIC_PAD_TOKEN);
tokens.push_back(SEMANTIC_INFER_TOKEN);
assert(tokens.size() == 256 + 256 + 1);
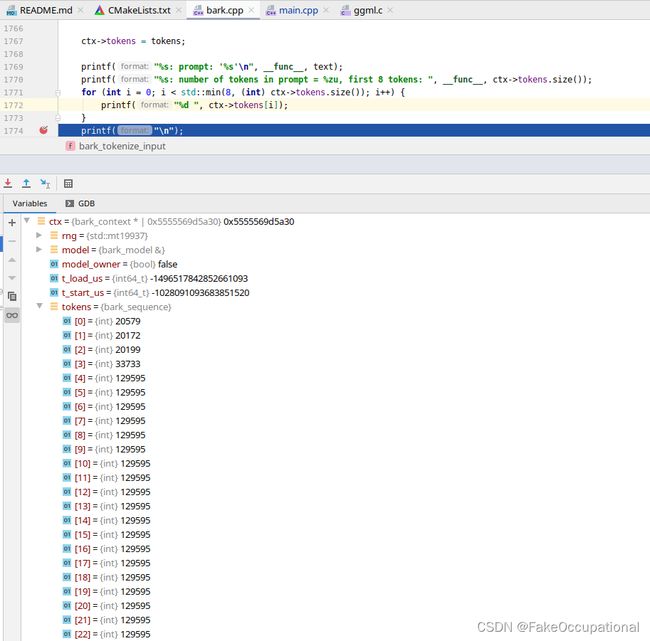
ctx->tokens = tokens;
printf("%s: prompt: '%s'\n", __func__, text);
printf("%s: number of tokens in prompt = %zu, first 8 tokens: ", __func__, ctx->tokens.size());
for (int i = 0; i < std::min(8, (int) ctx->tokens.size()); i++) {
printf("%d ", ctx->tokens[i]);
}
printf("\n");
}
单词表对象



- 对象创建自vocab.txt
上一步完成后还会进行wordpiece处理
// apply wordpiece
for (const auto &word : words) {
// 如果单词长度为0,跳过
if (word.size() == 0)
continue;
std::string prefix = ""; // 初始化前缀为空字符串
int i = 0; // 初始化索引 i 为0
int n = word.size(); // 获取单词长度
loop:
while (i < n) {
// 如果 tokens 数组中的元素达到了最大允许值,跳出循环
if (t >= n_max_tokens - 1)
break;
int j = n; // 初始化 j 为单词长度
while (j > i) {
// 尝试找到前缀加上从 i 到 j 的子串在 token_map 中的映射
auto it = token_map->find(prefix + word.substr(i, j - i));
if (it != token_map->end()) {
// 找到映射,将映射的值添加到 tokens 数组中
tokens[t++] = it->second;
i = j; // 更新索引 i
prefix = "##"; // 更新前缀为 "##"
goto loop; // 跳转到 loop 标签处
}
--j; // 递减 j
}
// 如果 j 等于 i,说明无法找到合适的子串
if (j == i) {
fprintf(stderr, "%s: unknown token '%s'\n", __func__, word.substr(i, 1).data());
prefix = "##"; // 更新前缀为 "##"
++i; // 更新索引 i
}
}
}
}
bert_tokenize函数
- bert_tokenize函数会将句子tockenlize到ctx中的tokens对象。
- 代码实现如下
void bert_tokenize(
const bark_vocab * vocab,
const char * text,
int32_t * tokens,
int32_t * n_tokens,
int32_t n_max_tokens) {
std::string str = text;
std::vector words;
int32_t t = 0;
auto * token_map = &vocab->token_to_id;
// split the text into words
{
str = strip_accents(text);
std::string pat = R"([[:punct:]]|[[:alpha:]]+|[[:digit:]]+)";
std::regex re(pat);
std::smatch m;
while (std::regex_search(str, m, re)) {
for (std::string x : m)
words.push_back(x);
str = m.suffix();
}
}
// apply wordpiece
for (const auto &word : words) {
if (word.size() == 0)
continue;
std::string prefix = "";
int i = 0;
int n = word.size();
loop:
while (i < n) {
if (t >= n_max_tokens - 1)
break;
int j = n;
while (j > i) {
auto it = token_map->find(prefix + word.substr(i, j - i));
if (it != token_map->end()) {
tokens[t++] = it->second;
i = j;
prefix = "##";
goto loop;
}
--j;
}
if (j == i) {
fprintf(stderr, "%s: unknown token '%s'\n", __func__, word.substr(i, 1).data());
prefix = "##";
++i;
}
}
}
*n_tokens = t;
}
将文本分割成单词
- 将文本分割成单词的部分使用了如下的正则表达式,其无法支持中文句子的分割,这也导致了无法正确推理运行。
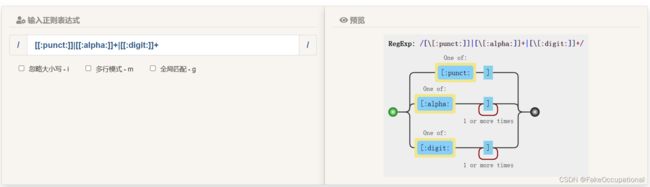
// split the text into words 将文本分割成单词
{
// 对文本进行去重音符处理
str = strip_accents(text);
// 定义正则表达式模式,匹配标点符号、字母和数字
std::string pat = R"([[:punct:]]|[[:alpha:]]+|[[:digit:]]+)";
// 创建正则表达式对象
std::regex re(pat);
std::smatch m;
// 使用正则表达式匹配文本中的单词
while (std::regex_search(str, m, re)) {
// 将匹配到的单词添加到单词列表
for (std::string x : m)
words.push_back(x);
// 更新文本,排除已匹配的部分
str = m.suffix();
}
}
简单修改与运行
// examples/main.cpp
struct bark_params {
int32_t n_threads = std::min(4, (int32_t) std::thread::hardware_concurrency());
// user prompt
std::string prompt = "你 好"; // "this is an audio";
//std::string prompt = "this is an audio"; // "this is an audio";
// paths
std::string model_path = "./bark.cpp/ggml_weights";
std::string dest_wav_path = "output.wav";
int32_t seed = 0;
};
// bark.cpp
// split the text into words
{
str = strip_accents(text);
// std::string pat = R"([[:punct:]]|[[:alpha:]]+|[[:digit:]]+)";
//
// std::regex re(pat);
// std::smatch m;
//
// while (std::regex_search(str, m, re)) {
// for (std::string x : m)
// words.push_back(x);
// str = m.suffix();
// }
// 用空格分割字符串
std::istringstream iss(str);
std::vector<std::string> words;
// 从输入流中读取每个分词并添加到 vector 中
do {
std::string word;
iss >> word;
words.push_back(word);
} while (iss);
// 输出分词结果
std::cout << "分词结果:" << std::endl;
for (const auto& word : words) {
std::cout << word << std::endl;
}
}
- ps:这样就能成功运行了,但是,不知道为什么中文推理用的内存比英文多,还有这个分不能通过手动空格实现(即使空格也无法运行,因为许多词没在词表中,还需要参考一下bert的分词过程。)