MySQL索引原理以及SQL优化
案例
struct index_failure_t{
int id;
string name;
int cid;
int score;
string phonenumber;
}
Map; 熟悉C++的同学知道,上述案例中,我们map底层是一颗红黑树,一个节点存储了一对kv(键值对),k是int类型,v是结构体类型。我们把大量的数据记录到这颗红黑树中。
对应到sql中,语法变成了
CREATE TABLE ‘index_failure_t’(
‘id’ INT(11) NOT NULL AUTO_INCREAMENT,
‘name’ VARCHAR(255) DEFAULT NULL,
‘cid’ INT(11) DEFAULT NULL,
‘score’ SAMLLINT DEFAULT 0,
‘phonenumber’ VARCHAR(20),
PRIMARY KEY(‘id’),
)其中PRIMARY KEY(‘id’)相当于C++案例中的map指定KEY的步骤。存储结构也由红黑树变成了B+树。
如果在其中再添加 KEY ‘name_idx‘ (‘name’)语句,在C++中相当于再建立Map
细节上有所差异,业务上高度相似。红黑树是二叉平衡搜索树,B+树是多路平衡搜索树。
Sql中的索引简介
索引,在sql底层的B+树中,就是各个节点的key。通过索引,可以快速地锁定数据的位置。
主键索引
它是非空唯一索引,一个表只有一个主键索引;在 innodb 中,主键索引的 B+ 树包含表数据信息。如果没有执行主键索引,那么会自动把第一个非空唯一索引设为主键,如果没有非空唯一索引,那么自动生成一个主键索引rowid。
PRIMARY KEY(key1, key2)
唯一索引
不可以出现相同的值,可以有 NULL 值;
UNIQUE(key)
普通索引
允许出现相同的索引内容;
INDEX(key) OR KEY(key[,...])
组合索引
对表上的多个列进行索引
索引代价
代价:占用空间,DML语句变慢(因为底层维护的数据结构变多了)。
索引的使用场景

B+树和红黑树
B+树:多路平衡搜索树
红黑树:二叉平衡搜索树
多路:一个节点可以有多个子节点。
二叉:一个节点只能由2个子节点。
平衡:平衡根节点到各个叶子节点的高度,提供稳定是时间搜索复杂度。
搜索树:是有序的树结构。

B+树并不是一个节点存储一条数据,而是一个节点存储16kb数据,叶子节点存储数据库数据,非叶子节点存储地址数据。这样做的目的是让B+树尽量是矮胖结构,减少磁盘IO的次数,因为每走到一个节点都要把节点的数据内容加载到内存中,进行一次磁盘IO,磁盘IO的耗时是内存IO的百倍。

B树则非叶子节点也存储数据信息。
innodb 体系结构
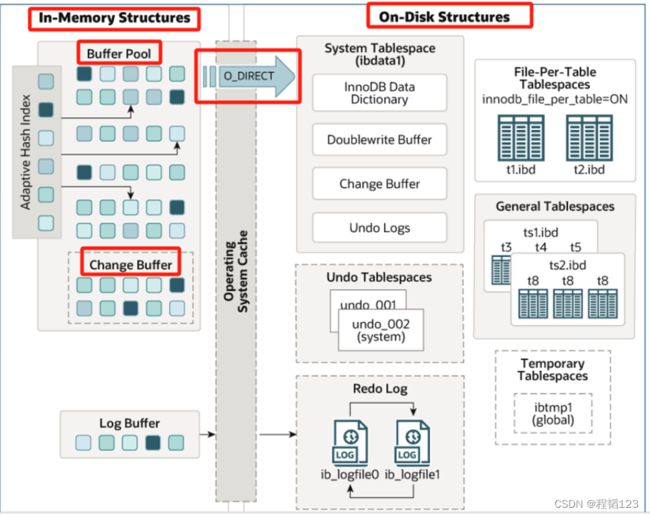
Buffer Pool主要用于缓存聚集索引和二级索引的B+树节点,也就是热门数据。
Change Buffer则专门用于缓存对聚集索引的修改操作。这些数据并不在 buffer pool 中,Change buffer 中的数据将会异步 merge 到 buffer pool 中。
Buffer Pool修改的数据会不经过内核的高速缓冲区,直接通过O_DIRECT刷入磁盘中。
SQL查询优化涉及原则及思路
EXPLAIN查询sql优化器方案
EXPLAIN是一个关键字,用于查询优化器解析和显示查询执行计划。
MySQL会解析查询,并返回一张执行计划表,该表描述了查询执行的步骤和顺序。执行计划表的列包括:
id:每个查询块(query block)的唯一标识符。
select_type:查询类型,例如SIMPLE(简单查询)、PRIMARY(主查询)等。
table:查询涉及的表名。
partitions:查询涉及的分区。
type:连接类型,例如ALL(全表扫描,尽量不要出现)、INDEX(索引扫描)、ref(索引值不好说、可能是非唯一索引)。
possible_keys:可能使用的索引。
key:实际使用的索引。
key_len:使用的索引的长度。
ref:连接条件,例如const(无需访问它表)。
rows:估计的返回行数。
filtered:过滤后的行百分比。
Extra:其他的附加信息。
覆盖索引
其实叫做索引覆盖更加合理,就是在辅助索引B+树里能找到全部所需数据,就不再进行回表查询了,可以减少查询耗时。这时候要求我们select语句尽量能包含辅助索引B+树的数据,而不是用select *。

最左匹配原则
最左匹配原则只适用于使用组合索引的情况,对于单列索引或者没有索引的情况,顺序并不重要。当查询语句中有多个条件,并且这些条件可以利用索引进行匹配时,最左匹配原则决定了如何使用索引进行匹配。我们可以通过利用最左匹配规则的思路,减少B+树的创建数量,也就是过度索引,比如一棵树虽然有组合索引,但是我们可以通过最左匹配规则只沿用其中一条索引也能起到相同的效果。同时组合索引的存在也能帮助我们复用索引减少回表次数。

索引下推

索引存储

索引失效
select ... where A and B 若 A 和 B 中有一个不包含索引,则索引失效;
索引字段参与运算,则索引失效;例如:from_unixtime(idx)= '2021-04-30'; 改成 idx = unix_timestamp("2021-04-30");
索引字段发生隐式转换,则索引失效;例如:将列隐式转换为某个类型,实际等价于在索引列上作用了隐式转换函数;
LIKE 模糊查询,通配符 % 开头,则索引失效;例如:select* from user where name like '%Mark';
在索引字段上使用 【NOT】【 <>】【 != 】索引失效;如果判断 id <> 0则修改为idx > 0 or idx < 0;
组合索引中,没使用第一列索引,索引失效;
Sql查询优化思路
查询频次较高且数据量大的表建立索引;
索引选择使用频次较高,过滤效果好的列或者组合;
使用短索引,能使得节点包含的信息多,较少磁盘 IO 操作;比如: smallint,tinyint;
对于组合索引,考虑最左侧匹配原则和覆盖索引;
尽量选择区分度高的列作为索引,该列的值相同的越少越好;
尽量扩展索引,在现有索引的基础上,添加复合索引;最多 6 个 索引;
不要 select *; 尽量只列出需要的列字段;方便使用覆盖索 引;
索引列,列尽量设置为非空;
可选:开启自适应 hash 索引或者调整 change buffer;
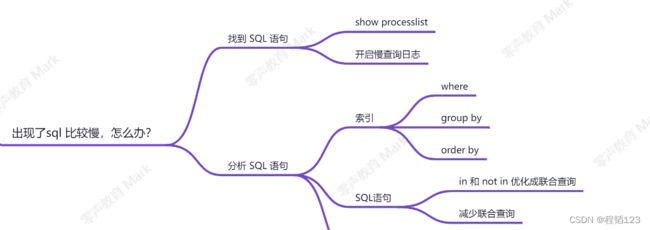
Sql查询优化方法
Show processlist:是一个用于查看当前正在运行的数据库连接和查询的 MySQL 命令。它会返回一个结果集,该结果集包含了当前活动的数据库连接的详细信息。通过查看 SHOW PROCESSLIST 的结果,你可以了解当前正在运行的查询、连接的用户、连接的状态以及查询执行的时间。这对于监视数据库的性能、识别慢查询或长时间运行的查询以及查找可能存在的连接问题都非常有用。
慢查询日志:慢查询是指执行时间较长的查询语句,可能会对数据库性能产生负面影响。通过开启慢日志,数据库会将执行时间超过设定阈值的查询语句记录到慢日志文件中,以便后续分析和优化。