Kafka源码分析10:副本状态机ReplicaStateMachine详解 (图解+秒懂+史上最全)
文章很长,建议收藏起来,慢慢读! Java 高并发 发烧友社群:疯狂创客圈 奉上以下珍贵的学习资源:
-
免费赠送 经典图书:《Java高并发核心编程(卷1)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Java高并发核心编程(卷2)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《SpringCloud Nginx高并发核心编程》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
推荐:入大厂 、做架构、大力提升Java 内功 的 精彩博文
| 入大厂 、做架构、大力提升Java 内功 必备的精彩博文 | 2021 秋招涨薪1W + 必备的精彩博文 |
|---|---|
| 1:Redis 分布式锁 (图解-秒懂-史上最全) | 2:Zookeeper 分布式锁 (图解-秒懂-史上最全) |
| 3: Redis与MySQL双写一致性如何保证? (面试必备) | 4: 面试必备:秒杀超卖 解决方案 (史上最全) |
| 5:面试必备之:Reactor模式 | 6: 10分钟看懂, Java NIO 底层原理 |
| 7:TCP/IP(图解+秒懂+史上最全) | 8:Feign原理 (图解) |
| 9:DNS图解(秒懂 + 史上最全 + 高薪必备) | 10:CDN图解(秒懂 + 史上最全 + 高薪必备) |
| 11: 分布式事务( 图解 + 史上最全 + 吐血推荐 ) | 12:seata AT模式实战(图解+秒懂+史上最全) |
| 13:seata 源码解读(图解+秒懂+史上最全) | 14:seata TCC模式实战(图解+秒懂+史上最全) |
| Java 面试题 30个专题 , 史上最全 , 面试必刷 | 阿里、京东、美团… 随意挑、横着走!!! |
|---|---|
| 1: JVM面试题(史上最强、持续更新、吐血推荐) | 2:Java基础面试题(史上最全、持续更新、吐血推荐 |
| 3:架构设计面试题 (史上最全、持续更新、吐血推荐) | 4:设计模式面试题 (史上最全、持续更新、吐血推荐) |
| 17、分布式事务面试题 (史上最全、持续更新、吐血推荐) | 一致性协议 (史上最全) |
| 29、多线程面试题(史上最全) | 30、HR面经,过五关斩六将后,小心阴沟翻船! |
| 9.网络协议面试题(史上最全、持续更新、吐血推荐) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
| SpringCloud 精彩博文 | |
|---|---|
| nacos 实战(史上最全) | sentinel (史上最全+入门教程) |
| SpringCloud gateway (史上最全) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
Kafka源码分析10:副本状态机ReplicaStateMachine
副本状态机ReplicaStateMachine管理着 Kafka 集群中所有副本和分区的状态转换,是非常核心的一个类。
接下来,带大家图解一下此核心类。
ReplicaStateMachine的功能
副本状态机ReplicaStateMachine的功能:
用于管理副本状态的转换。
副本状态机相关的类
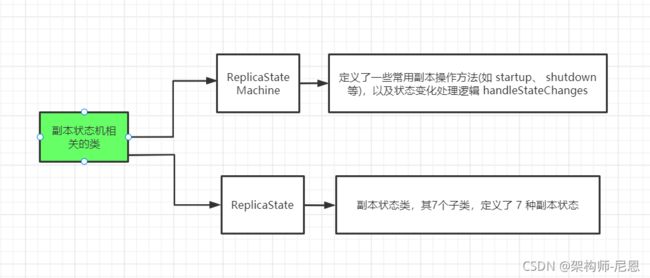
ReplicaStateMachine:
副本状态机抽象类,定义了一些常用方法(如 startup、 shutdown 等),以及状态机最重要的处理逻辑方法 handleStateChanges。
ReplicaState:
副本状态类,其7个子类,定义了 7 种副本状态。
ReplicaState
副本状态的接口定义。
ReplicaState 接口定义了每种状态的序号,以及合法的前 置状态。
// ReplicaState接口
sealed trait ReplicaState {
def state: Byte //每种状态的序号
def validPreviousStates: Set[ReplicaState] //合法的前置状态
}
ReplicaState的 7 种副本状态实现类
源码中的 ReplicaState 定义了 7 种副本状态,如下图:

- NewReplica:副本被创建之后所处的状态。
- OnlineReplica:副本正常提供服务时所处的状态。
- OfflineReplica:副本服务下线时所处的状态。
- ReplicaDeletionStarted:副本被删除时所处的状态。
- ReplicaDeletionSuccessful:副本被成功删除后所处的状态。
- ReplicaDeletionIneligible:开启副本删除,但副本暂时无法被删除时所处的状态。
- NonExistentReplica:副本从副本状态机被移除前所处的状态。
状态的有效前置集合
每一种状态,都定义了有效前置集合,以OnlineReplica状态为例。
// OnlineReplica状态
case object OnlineReplica extends ReplicaState {
val state: Byte = 2
val validPreviousStates: Set[ReplicaState] = Set(NewReplica, OnlineReplica, OfflineReplica, ReplicaDeletionIneligible)
}
OnlineReplica 的 validPreviousStates 集合里面包含 NewReplica、OnlineReplica、OfflineReplica 和 ReplicaDeletionIneligible。
这说明,Kafka 只允许副本从刚刚这 4 种状态变更到 OnlineReplica 状态。如果从 ReplicaDeletionStarted 状态跳转到 OnlineReplica 状态,就是非法的状态转换。
ReplicaStateMachine 副本状态机
ReplicaStateMachine 副本状态机 是 Kafka Broker 端源码中控制副本状态流转的实现类。
每个 Broker 都会创建这些实例,并不代表每个 Broker 都会启动副本状态机。
每个 Broker 启动时都会创建 ReplicaStateMachine 实例,但是,只有在 Controller 所在的 Broker 上,副本状态机才会被启动。
副本状态机一旦被启动,就意味着它要行使它最重要的职责了:管理副本状态的转换。
图解:副本状态的转换的设计与实现
三种基础的状态转换
当副本对象首次被创建出来后,它会被置于 NewReplica 状态。
经过初始化之后,当副本对象能够对外提供服务之后,状态机会将其调整为 OnlineReplica,并一直以该状态持
续工作。
如果副本所在的 Broker 关闭或者是因为其他原因不能正常工作了,副本需要从 OnlineReplica 变更为 OfflineReplica,表明副本已处于离线状态。

四种与副本删除相关的状态转换
一旦开启了如删除主题这样的操作,状态机会将副本状态跳转到 ReplicaDeletionStarted,以表明副本删除已然开启。
倘若删除成功,则置为 ReplicaDeletionSuccessful;
倘若不满足删除条件(如所在 Broker 处于下线状态),那就设置成 ReplicaDeletionIneligible,以便后面重试。
当副本对象被删除后,其状态会变更为 NonExistentReplica,副本状态机将移除该副本数据。

handleStateChange 状态转换入口方法
handleStateChange 方法的作用是处理状态的变更,是对外提供状态转换操作的入口方法。
该方法接收三个参数:
-
replicas 是一组副本对象,每个副本对象都封装了它们各自所属的主题、分区以及副本所在的 Broker ID 数据;
-
targetState 是这组副本对象要转换成的目标状态。
-
callbacks 为状态转换之后的回调。
其方法如下:
def handleStateChanges(replicas: Seq[PartitionAndReplica], targetState: ReplicaState,
callbacks: Callbacks = new Callbacks()): Unit = {
if (replicas.nonEmpty) {
try {
// raise error if the previous batch is not empty
//为了提高KafkaController Leader和集群其他broker的通信效率,实现批量发送请求的功能
// 检查上一批请求KafkaController请求,如果没有发送完成,就报错
controllerBrokerRequestBatch.newBatch()
// 将所有副本对象按照Broker进行分组,依次执行状态转换操作
replicas.groupBy(_.replica).map { case (replicaId, replicas) =>
val partitions = replicas.map(_.topicPartition)
doHandleStateChanges(replicaId, partitions, targetState, callbacks)
}
// 发送对应的Controller请求给Broker
controllerBrokerRequestBatch.sendRequestsToBrokers(controllerContext.epoch)
} catch {
case e: Throwable => error(s"Error while moving some replicas to $targetState state", e)
}
}
}
代码逻辑总体上分为两步:
-
第 1 步是调用 doHandleStateChanges 方法执行真正的副本状态转换;
-
第 2 步是给集群中的相应 Broker 批量发送请求。
在执行第 1 步的时候,它会将 replicas 按照 Broker ID 进行分组。
举个例子,如果我们使用 < 主题名,分区号,副本 Broker ID> 表示副本对象,假设 replicas 为集合:
< 主题名,分区号,副本 Broker ID>
那么,在调用 doHandleStateChanges 方法前,代码会将 replicas 按照 Broker ID 进行分组,即变成:
Map(0 -> Set(, ))
Map(1 -> Set(, ))
待这些都做完之后,代码开始调用 doHandleStateChanges 方法,执行状态转换操作。
doHandleStateChanges 执行状态转换操作
这个方法看着很长,其实就是3步。

核心代码如下:
private def doHandleStateChanges(replicaId: Int, partitions: Seq[TopicPartition], targetState: ReplicaState,callbacks: Callbacks): Unit = {
//尝试获取副本在 Controller 端元数据缓存中的当前状态
val replicas = partitions.map(partition => PartitionAndReplica(partition, replicaId))
//如果没有保存某个副本对象的状态,代码会将其初始化为 NonExistentReplica 状态。
replicas.foreach(replica => replicaState.getOrElseUpdate(replica, NonExistentReplica))
//将副本对象集合划分成两部分:能够合法转换的副本对象集合,以及执行非法状态转换的副本对象集合。
val (validReplicas, invalidReplicas) = replicas.partition(replica => isValidTransition(replica, targetState))
//为执行非法状态转换的副本对象集合中的每个副本对象记录一条错误日志
invalidReplicas.foreach(replica => logInvalidTransition(replica, targetState))
//根据要转换成的目标状态 ,进入到不同的代码分支,处理能够执行合法转换的副本对象集合的副本的状态转换
targetState match {
case NewReplica =>
...
case OnlineReplica =>
...
//七大分支
}
第 1 步,尝试获取副本在 Controller 端元数据缓存中的当前状态。
如果没有保存某个副本对象的状态,代码会将其初始化为 NonExistentReplica 状态。
第 2 步,将副本对象集合划分成两部分:
-
能够合法转换的副本对象集合
-
不能合法转换的副本对象集合。
代码根据不同 ReplicaState 中定义的合法前置状态集合以及传入的目标状态(targetState),将副本对象集合划分成两部分:能够合法转换的副本对象集合,不能合法转换的副本对象集合。
doHandleStateChanges 方法会为不能合法转换的副本对象集合中的每个副本对象记录一条错误日志。
第 3 步,根据要转换成的目标状态 ,进入到不同的代码分支,处理能够执行合法转换的副本对象集合的副本的状态转换。
由于 Kafka 为副本定义了 7 类状态,因此,这里的代码分支总共有 7 路。
我挑选几路最常见的状态转换路径详细说明下,包括副本被创建时被转换到 NewReplica 状态,副本正常工作时被转换到 OnlineReplica 状态,副本停止服务后被转换到 OfflineReplica 状态。至于剩下的记录代码,你可以在课后自行学习下,它们的转换操作原理大致是相同的。
第 1 路:转换到 NewReplica 状态
首先看第 1 路,即状态转换的目标状态是 NewReplica 的场景。流程图如下:

核心代码如下:
case NewReplica =>
// 遍历所有能够执行转换的副本对象
validReplicas.foreach { replica =>
// 获取该副本对象的分区对象,即<主题名,分区号>数据
val partition = replica.topicPartition
// 尝试从元数据缓存中获取该分区当前信息
// 包括Leader是谁、ISR都有哪些副本等数据
controllerContext.partitionLeadershipInfo.get(partition) match {
// 如果成功拿到分区数据信息
case Some(leaderIsrAndControllerEpoch) =>
// 如果该副本是Leader副本
if (leaderIsrAndControllerEpoch.leaderAndIsr.leader == replicaId) {
val exception = new StateChangeFailedException(s"Replica $replicaId for partition $partition cannot be moved to NewReplica state as it is being requested to become leader")
// 记录错误日志。Leader副本不能被设置成NewReplica状态
logFailedStateChange(replica, replicaState(replica), OfflineReplica, exception)
} else {
// 否则,给该副本所在的Broker发送LeaderAndIsrRequest
// 向它同步该分区的数据, 之后给集群当前所有Broker发送
// UpdateMetadataRequest通知它们该分区数据发生变更
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(Seq(replicaId),
replica.topicPartition,
leaderIsrAndControllerEpoch,
controllerContext.partitionReplicaAssignment(replica.topicPartition),
isNew = true)
logSuccessfulTransition(replicaId, partition, replicaState(replica), NewReplica)
// 更新缓存中该副本对象的当前状态为NewReplica
replicaState.put(replica, NewReplica)
}
case None =>
logSuccessfulTransition(replicaId, partition, replicaState(replica), NewReplica)
// 更新缓存中该副本对象的当前状态为NewReplica
replicaState.put(replica, NewReplica)
}
}
这一路主要做的事情是,尝试从元数据缓存中,获取这些副本对象的分区信息数据,包括分区的 Leader 副本在哪个 Broker 上、ISR 中都有哪些副本,等等。
如果找不到对应的分区数据,就直接把副本状态更新为 NewReplica。否则,代码就需要给该副本所在的 Broker 发送请求,让它知道该分区的信息。同时,代码还要给集群所有运行中的 Broker 发送请求,让它们感知到新副本的加入。
第 2 路:转换到 OnlineReplica 状态
再看第2路,即状态转换的目标状态是 OnlineReplica的场景。OnlineReplica是副本对象正常工作时所处的状态。流程图如下:

核心代码如下:
case OnlineReplica =>
validReplicas.foreach { replica =>
// 获取副本所在分区
val partition = replica.topicPartition
// 获取副本当前状态
replicaState(replica) match {
// 如果当前状态是NewReplica
case NewReplica =>
// 从元数据缓存中拿到分区副本列表
val assignment = controllerContext.partitionReplicaAssignment(partition)
// 如果副本列表不包含当前副本
if (!assignment.contains(replicaId)) {
// 将该副本加入到副本列表中,并更新元数据缓存中该分区的副本列表
controllerContext.partitionReplicaAssignment.put(partition, assignment :+ replicaId)
}
// 如果当前状态是其他状态
case _ =>
// 尝试获取该分区当前信息数据
controllerContext.partitionLeadershipInfo.get(partition) match {
// 如果存在分区信息
// 向该副本对象所在Broker发送请求,令其同步该分区数据
case Some(leaderIsrAndControllerEpoch) =>
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(Seq(replicaId),
replica.topicPartition,
leaderIsrAndControllerEpoch,
controllerContext.partitionReplicaAssignment(partition), isNew = false)
case None =>
}
}
logSuccessfulTransition(replicaId, partition, replicaState(replica), OnlineReplica)
// 将该副本对象设置成OnlineReplica状态
replicaState.put(replica, OnlineReplica)
}
代码依然会对副本对象进行遍历,并依次执行下面的几个步骤。
第 1 步,获取元数据中该副本所属的分区对象,以及该副本的当前状态。
第 2 步,查看当前状态是否是 NewReplica。
-
如果是,则获取分区的副本列表,并判断该副本是否在当前的副本列表中,假如不在,就记录错误日志,并更新元数据中的副本列表;
-
如果状态不是 NewReplica,就说明,这是一个已存在的副本对象,那么,源码会获取对应分区的详细数据,然后向该副本对象所在的 Broker 发送 LeaderAndIsrRequest 请求,令其同步获知,并保存该分区数据。
第 3 步,将该副本对象状态变更为 OnlineReplica。至此,该副本处于正常工作状态。
第 3 路:转换到 OfflineReplica 状态
再看第3路,即状态转换的目标状态是OfflineReplica的场景。OfflineReplica表示副本服务下线时所处的状态。
如果副本所在的 Broker 关闭或者是因为其他原因不能正常工作了,副本需要从 OnlineReplica 变更为 OfflineReplica,表明副本已处于离线状态。
第 3 路流程图如下:
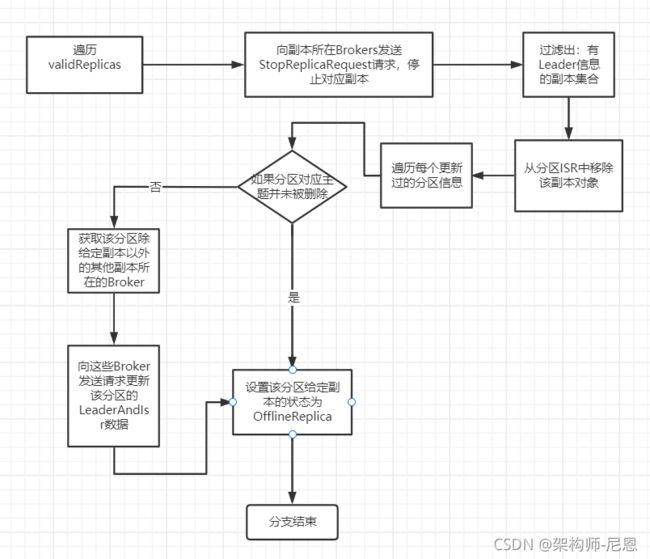
第 3 路流程的核心代码如下:
case OfflineReplica =>
validReplicas.foreach { replica =>
// 向副本所在Brokers发送StopReplicaRequest请求,停止对应副本
controllerBrokerRequestBatch.addStopReplicaRequestForBrokers(Seq(replicaId), replica.topicPartition,
deletePartition = false, (_, _) => ())
}
// 过滤出:有Leader信息的副本集合
val replicasToRemoveFromIsr = validReplicas.filter(replica => controllerContext.partitionLeadershipInfo.contains(replica.topicPartition))
// 从分区中移除该副本对象并更新ZooKeeper节点
val updatedLeaderIsrAndControllerEpochs = removeReplicasFromIsr(replicaId, replicasToRemoveFromIsr.map(_.topicPartition))
// 遍历每个更新过的分区信息
updatedLeaderIsrAndControllerEpochs.foreach { case (partition, leaderIsrAndControllerEpoch) =>
// 如果分区对应主题并未被删除
if (!topicDeletionManager.isPartitionToBeDeleted(partition)) {
// 获取该分区除给定副本以外的其他副本所在的Broker
val recipients = controllerContext.partitionReplicaAssignment(partition).filterNot(_ == replicaId)
// 向这些Broker发送请求更新该分区更新过的分区LeaderAndIsr数据
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(recipients,
partition,
leaderIsrAndControllerEpoch,
controllerContext.partitionReplicaAssignment(partition), isNew = false)
}
val replica = PartitionAndReplica(partition, replicaId)
logSuccessfulTransition(replicaId, partition, replicaState(replica), OfflineReplica)
// 设置该分区给定副本的状态为OfflineReplica
replicaState.put(replica, OfflineReplica)
}
首先,代码会给所有符合状态转换的副本所在的 Broker,发送 StopReplicaRequest 请求,显式地告诉这些 Broker 停掉其上的对应副本。
broker接收到 StopReplica 请求之后,通过Kafka 的副本管理器组件(ReplicaManager)负责处理这个逻辑。也就是说,StopReplicaRequest 被发送出去之后,这些 Broker 上对应的副本就停止工作了。
其次,代码根据分区是否保存了 Leader 信息,将副本集合划分成两个子集:有 Leader 副本集合和无 Leader 副本集合。有 Leader 信息副本集合并不仅仅包含 Leader,还有 ISR 和 controllerEpoch 等数据。
最后,迭代有 Leader信息副本集合,向这些副本所在的 Broker 发送 LeaderAndIsrRequest 请求,去更新停止副本操作之后的分区信息,再把这些分区状态设置为 OfflineReplica。
总之,把副本状态变更为 OfflineReplica 的主要逻辑,包含两个核心工作:
- 停止Broker 上对应副本
- 更新远端 Broker 元数据。

参考文献:
https://www.cnblogs.com/boanxin/p/13696136.html
https://www.cnblogs.com/start-from-zero/p/13430611.html
https://blog.csdn.net/lidazhou/article/details/95909496
https://www.jianshu.com/p/5bef1f9f74cd
http://www.louisvv.com/archives/2348.html
http://www.machengyu.net/tech/2019/09/22/kafka-version.html