赢麻了……腾讯1面核心9问,小伙伴过了提42W offer
说在前面
在40岁老架构师尼恩的(50+)读者社群中,经常有小伙伴,需要面试腾讯、美团、京东、阿里、 百度、头条等大厂。
下面是一个小伙伴成功拿到通过了腾讯面试,并且最终拿到offer,一毕业就年薪42W,赢麻了。
现在把腾讯面试真题和参考答案收入咱们的宝典,大家看看,收个优质腾讯Offer需要学点啥?
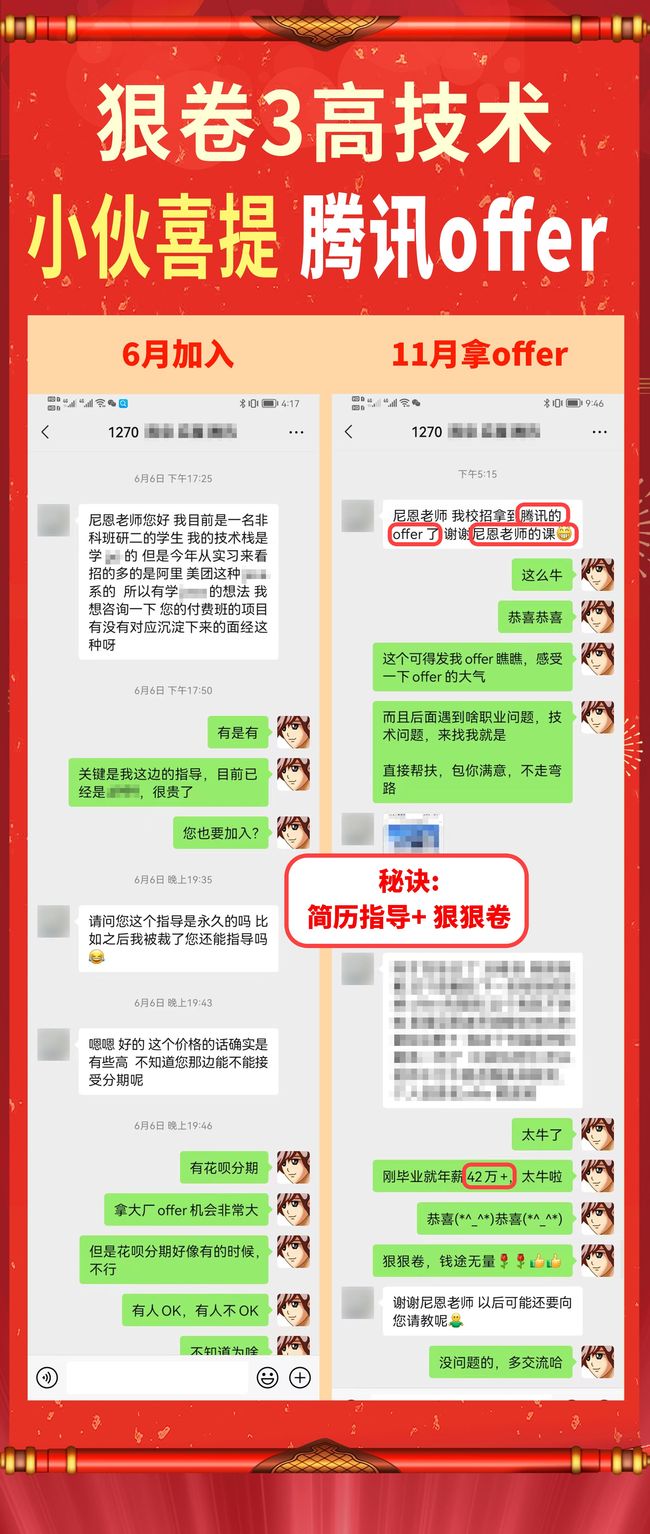
这里把题目以及小伙伴的吹牛逼的方式方法,经过整理和梳理之后,收入咱们的《尼恩Java面试宝典PDF》 V124版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发、吹牛水平。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到公众号【技术自由圈】获取
文章目录
-
- 说在前面
- 腾讯面试真题
-
- 1、说说TCP和UDP?
-
- TCP:
- UDP:
- 2、说说TCP可靠机制?
- 3、说说Mysql引擎?
- 4、说说索引失效?
- 5、说说脏读,不可重复读,幻读?
- 6、Mysql事务隔离级别,怎么解决,MVCC+next-key lock可以解决幻读吗?
- 7、设计与实现一个 IM 系统?最好是分布式版本?
- 8、算法题:树的先中后序遍历
-
- 前序遍历
- 中序遍历
- 后序遍历
- 9、算法题:二进制加法
- 附录:100道常备的算法题
- 尼恩说在最后
- 尼恩技术圣经系列PDF
腾讯面试真题
1、说说TCP和UDP?
TCP:
- 面向连接:TCP 是一种连接导向的协议,它在通信开始前需建立连接,并在通信结束后释放连接。这确保了数据传输的可靠性,但也会增加一些额外开销。
- 可靠性:TCP 提供可靠的数据传输,确保数据包按顺序到达,并能重新发送丢失或损坏的数据包,以确保数据完整性。
- 流控制:TCP 支持流量控制机制,防止发送方发送过多数据,从而避免网络拥塞。这通过滑动窗口机制实现。
- 拥塞控制:TCP 具有内置的拥塞控制机制,可监测网络拥塞情况,并动态调整发送速率以防止拥塞。
- 有序性:TCP 确保数据包按顺序到达,对于需要数据有序性的应用至关重要。
- 连接开销:由于建立和维护连接的开销,TCP 的成本相对较高。这使其适用于需要可靠性的应用,如网页浏览、文件传输和电子邮件。
UDP:
- 无连接:UDP 是一种无连接的协议,无需建立连接,数据包可直接发送至目的地。这降低了通信开销,但也意味着它不提供连接的可靠性。
- 不可靠性:UDP 不提供数据包的可靠性,数据包可能会丢失、重复或乱序。它适用于对数据可靠性要求不高的应用,如音视频流媒体和在线游戏。
- 无流控制:UDP 不提供内置的流量控制机制,发送方可以以任意速率发送数据,不考虑接收方的处理能力。
- 无拥塞控制:UDP 没有内置的拥塞控制机制,不会主动监测网络拥塞情况,在拥塞网络中可能导致数据包丢失。
- 低开销:由于没有连接建立和维护的开销,UDP 具有较低的开销,适用于需要低延迟的应用,如实时音视频传输。
2、说说TCP可靠机制?
- 序列号和确认号:TCP 数据包中包含序列号和确认号。发送方使用序列号对数据包进行编号,接收方使用确认号来确认已成功接收数据。这确保了数据包的有序传输。
- 确认机制:接收方会定期发送确认(ACK)数据包,告知发送方已成功接收到的数据包。若发送方在一定时间内未收到确认,则会重新发送相应数据包。
- 超时重传:若发送方在一定时间内未收到确认,则会假定数据包丢失并进行超时重传。这确保了即使数据包在传输过程中丢失,最终仍能成功传输。
- 流控制:TCP 使用滑动窗口机制进行流控制。接收方通过通告窗口大小告知发送方还能接收多少数据。这有助于防止发送方发送过多数据,从而避免数据丢失和网络拥塞。
- 拥塞控制:TCP 内置拥塞控制机制,可监测网络拥塞情况。若发现网络拥塞,发送方会降低发送速率,以避免进一步加重拥塞。
- 有序性:TCP 确保数据包按顺序到达接收方,即使网络中可能出现乱序传输,TCP 会将数据包按正确顺序重新排列。
- 可靠的连接建立和终止:TCP 在连接建立和终止过程中采用多个握手与挥手步骤,确保连接可靠性。这包括三次握手和四次挥手过程。
3、说说Mysql引擎?
两个常见的:
- InnoDB:作为 MySQL 的默认存储引擎,InnoDB 支持事务处理和高度数据完整性。它提供行级锁定和外键约束,适用于注重数据一致性和事务处理的应用。
- MyISAM:MyISAM 是 MySQL 的另一种存储引擎,它支持全文本搜索和表级锁定。MyISAM 不支持事务处理,但适用于需要快速读取和写入的应用,如数据仓库和日志记录。
一些作为了解的:
- MEMORY:MEMORY 存储引擎将数据存储在内存中,因此读取速度非常快,但数据不会持久保存。适用于缓存和临时数据存储。
- NDB Cluster:NDB Cluster 存储引擎是 MySQL 的集群存储引擎,支持分布式数据库。适用于需要高可用性和负载均衡的应用。
- Archive:Archive 存储引擎用于高压缩率的数据存储,适用于归档数据和历史数据存储。
- TokuDB:TokuDB 存储引擎专注于大数据处理,支持高性能的数据插入和查询。适用于处理大量数据的应,如日志和分析应用。
- Federated:Federated 存储引擎允许在一个 MySQL 数据库中访问另一个远程 MySQL 数据库的表。适用于分布式数据访问。
- Blackhole:Blackhole 存储引擎实则不存储数据,仅将数据传递至其他存储引擎。可用于数据复制和数据分发。
- CSV:CSV 存储引擎用于读取和写入 CSV 文件格式的数据。适用于与其他应用程序交换数据。
- JSON:JSON 存储引擎支持 JSON 数据类型,用于存储和查询 JSON 数据。
4、说说索引失效?
索引失效是指在数据库查询中,数据库管理系统无法充分利用现有索引来加速查询,而需要进行全表扫描或全索引扫描的情况。这种情况可能导致查询性能下降。
索引失效的一些原因:
- 未使用索引列进行查询:如果查询条件不包含在索引列中,索引就无法加速查询。例如,如果有一个名为 “name” 的索引,但查询是基于 “age” 列的,那么索引就无法用于加速查询。
- 使用函数或操作符处理索引列:当在查询中对索引列使用函数或操作符时,索引可能会失效。例如,如果对 “name” 列进行了 UPPER() 函数操作,索引就无法使用。
- 使用不等号条件:某些不等号条件(如不等于、大于、小于等)可能导致索引使用受限。通常情况下,等于条件(=)更容易使用索引。
- 数据分布不均匀:若索引列的数据分布不均匀,即某些值出现次数很多,而其他值出现次数很少,索引的选择性较低,可能不会被选用加速查询。
- 索引列类型不匹配:若查询条件的数据类型与索引列的数据类型不匹配,索引可能会失效。例如,索引列是字符串类型,但查询条件使用了数字,索引可能无法使用。
- 索引顺序不匹配:针对复合索引,若查询条件的列顺序与索引的列顺序不匹配,索引可能无法加速查询。
- 表数据量太小:对于非常小的表,全表扫描通常比使用索引更高效,因此数据库管理系统可能会选择不使用索引。
5、说说脏读,不可重复读,幻读?
- 脏读(Dirty Read):脏读是指在一个事务读取另一个事务未提交的数据。当一个事务读取另一个事务的数据,而后者后来回滚,导致读取的数据实际上是无效的。这可能导致严重的数据不一致问题。
- 不可重复读(Non-Repeatable Read):不可重复读发生在一个事务内的两次查询之间,另一个事务修改了数据,使得第一次查询的结果与第二次查询的结果不一致。这是因为第一次查询返回的数据在第二次查询之前已经被修改。
- 幻读(Phantom Read):幻读是在一个事务内的两次查询之间,另一个事务插入了新的数据行,导致第一次查询的结果与第二次查询的结果不一致。尽管数据未被修改,但由于新数据的插入,第二次查询可能返回不同的结果。
这些问题与数据库的隔离级别相关。
SQL 标准定义了四种隔离级别:读未提交(Read Uncommitted)、读提交(Read Committed)、可重复读(Repeatable Read)、和串行化(Serializable)。不同的隔离级别会导致不同的数据一致性问题:
- 在读未提交隔离级别下,允许脏读、不可重复读和幻读。
- 在读提交隔离级别下,防止脏读,但允许不可重复读和幻读。
- 在可重复读隔离级别下,防止脏读和不可重复读,但允许幻读。
- 在串行化隔离级别下,防止脏读、不可重复读和幻读,但性能可能受到一定的影响。
6、Mysql事务隔离级别,怎么解决,MVCC+next-key lock可以解决幻读吗?
- MVCC(多版本并发控制):MVCC 是 MySQL 采用的一种机制,通过在数据库中保存不同版本的数据来解决并发读写问题。在 MVCC 中,每个事务启动时会获得一个事务 ID,读操作只能看到等于或小于该事务 ID 的数据版本,从而实现数据隔离。MVCC 主要应用于可重复读和读提交隔离级别,以解决不可重复读和幻读问题。然而,在可重复读隔离级别下,仍可能发生幻读。
- Next-Key Locks:Next-Key Locks 是 MySQL 中的锁机制,在索引上创建了锁,包括满足条件的记录以及下一个记录的锁。这可以防止其他事务在当前事务读取或修改记录时插入新的记录,从而避免幻读。Next-Key Locks 主要用于可重复读隔离级别,以解决幻读问题。
需要注意的是,MVCC 和 Next-Key Locks 能有效减轻幻读问题,但无法在所有情况下完全解决幻读。在某些特定情况下,如涉及范围查询,仍然可能发生幻读。
在这种情况下,应根据应用的需求和数据一致性的要求选择事务隔离级别,权衡性能和一致性。若对数据一致性要求较高,可以选择串行化隔离级别,但要注意性能可能受到影响。
7、设计与实现一个 IM 系统?最好是分布式版本?
尼恩提示: 这个是腾讯面试核心问题, 回答好这个题至关重要
这道题目的答案,内容非常多, 可以参考两个项目的方案去回答:
第一个项目:《腾讯太狠:10亿QPS的IM,如何实现?》
第二个项目:《1000Wqps生产级高并发IM,怎么架构?》
这两个项目的方案, 收录在《尼恩Java面试宝典》PDF集群的 专题04:《架构设计面试题(卷王专供+ 史上最全 + 2023面试必备)》 中。内容篇幅太大,在这里不做重复了。

8、算法题:树的先中后序遍历
前序遍历
前序遍历是一种深度优先遍历方式,它的访问顺序是先访问根节点,然后递归地访问左子树和右子树。
递归:
思路:
- 访问当前节点(根节点)。
- 递归遍历左子树。
- 递归遍历右子树。
示例代码:
#include 非递归:
思路:
- 创建一个栈,以及一个指向树根节点的指针。
- 将根节点入栈。
- 弹出栈顶节点,访问它。
- 如果该节点有右子节点,将右子节点入栈,再将左子节点入栈(这样确保左子节点在栈顶)。
- 重复步骤3和4,直到栈为空。
示例代码:
void preorderTraversal(TreeNode* root) {
std::stack<TreeNode*> s;
TreeNode* current = root;
while (current || !s.empty()) {
while (current) {
std::cout << current->val << " ";
if (current->right) {
s.push(current->right);
}
current = current->left;
}
if (!s.empty()) {
current = s.top();
s.pop();
}
}
}
中序遍历
中序遍历也是一种深度优先遍历方式,它的访问顺序是先遍历左子树,然后访问根节点,最后遍历右子树。
递归:
思路:
- 递归遍历左子树。
- 访问当前节点(根节点)。
- 递归遍历右子树。
示例代码:
#include 非递归:
思路:
- 创建一个栈,以及一个指向树根节点的指针。
- 从根节点开始,将所有左子节点入栈,直到达到最左边的叶子节点。
- 出栈一个节点,访问它。
- 如果该节点有右子节点,将右子节点设为当前节点,然后重复步骤2。
- 重复步骤3和4,直到栈为空且当前节点为空。
示例代码:
void inorderTraversal(TreeNode* root) {
std::stack<TreeNode*> s;
TreeNode* current = root;
while (current || !s.empty()) {
while (current) {
s.push(current);
current = current->left;
}
current = s.top();
s.pop();
std::cout << current->val << " ";
current = current->right;
}
}
后序遍历
后序遍历同样是一种深度优先遍历方式,它的访问顺序是先遍历左子树,然后遍历右子树,最后访问根节点。
递归:
思路:
- 递归遍历左子树。
- 递归遍历右子树。
- 访问当前节点(根节点)。
示例代码:
#include 非递归:
思路:
- 创建两个栈,一个用于节点的遍历,另一个用于保存遍历结果。
- 将根节点压入栈1。
- 从栈1弹出一个节点,然后将它压入栈2。
- 将当前节点的左子节点和右子节点分别压入栈1。
- 重复步骤3和4,直到栈1为空。
- 此时栈2中的元素就是后序遍历的顺序,将它们依次出栈并访问。
示例代码:
void postorderTraversal(TreeNode* root) {
std::stack<TreeNode*> s1, s2;
s1.push(root);
while (!s1.empty()) {
TreeNode* current = s1.top();
s1.pop();
s2.push(current);
if (current->left) {
s1.push(current->left);
}
if (current->right) {
s1.push(current->right);
}
}
while (!s2.empty()) {
std::cout << s2.top()->val << " ";
s2.pop();
}
}
9、算法题:二进制加法
描述:
给定两个 01 字符串 a 和 b ,请计算它们的和,并以二进制字符串的形式输出。
输入为 非空 字符串且只包含数字 1 和 0。
思路:
- 创建一个空字符串
result用于保存结果,以及两个变量carry(用于表示进位,初始化为0)和i(用于从字符串末尾向前遍历)。 - 从字符串
a和b的末尾开始,逐位取出字符并转换为整数,分别为numA和numB。如果字符串已经遍历完,则对应的数字设为0。 - 计算当前位的和,即
sum = numA + numB + carry。注意,carry初始为0,但在每次迭代后可能会变为1。 - 计算当前位的结果和进位:
currentResult = sum % 2和carry = sum / 2。 - 将
currentResult转换为字符并插入到result的前面。 - 将
i向前移动一位。 - 重复步骤2到步骤6,直到遍历完字符串
a和b。 - 如果最后一次迭代后
carry为1,表示有进位,将"1"插入到result的前面。 - 返回
result作为最终结果。
示例代码:
#include 附录:100道常备的算法题
大厂重视算法。
尼恩给大家备好了100道常背的算法题, 大家要一定要吃透,温故而知新, 常常看看, 不要忘了。

尼恩说在最后
在尼恩的(50+)读者社群中,很多、很多小伙伴需要进大厂、拿高薪。
尼恩团队,会持续结合一些大厂的面试真题,给大家梳理一下学习路径,看看大家需要学点啥?
前面用多篇文章,给大家介绍阿里、百度、字节、滴滴的真题:
《太细了:美团一面连环夺命20问,搞定就60W起》
《炸裂,靠“吹牛”过京东一面,月薪40k》
《太猛了,靠“吹牛”过顺丰一面,月薪30K》
《问懵了…美团一面索命44问,过了就60W+》
《炸裂了…京东一面索命40问,过了就50W+》
《问麻了…阿里一面索命27问,过了就60W+》
《百度狂问3小时,大厂offer到手,小伙真狠!》
《饿了么太狠:面个高级Java,抖这多硬活、狠活》
《字节狂问一小时,小伙offer到手,太狠了!》
《收个滴滴Offer:从小伙三面经历,看看需要学点啥?》
这些真题,都会收入到 史上最全、持续升级的 PDF电子书 《尼恩Java面试宝典》。
本文收录于 《尼恩Java面试宝典》。
基本上,把尼恩的 《尼恩Java面试宝典》吃透,大厂offer很容易拿到滴。另外,下一期的 大厂面经大家有啥需求,可以发消息给尼恩。
尼恩技术圣经系列PDF
- 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》
- 《Docker圣经:大白话说Docker底层原理,6W字实现Docker自由》
- 《K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由》
- 《SpringCloud Alibaba 学习圣经,10万字实现SpringCloud 自由》
- 《大数据HBase学习圣经:一本书实现HBase学习自由》
- 《大数据Flink学习圣经:一本书实现大数据Flink自由》
- 《响应式圣经:10W字,实现Spring响应式编程自由》
- 《Go学习圣经:Go语言实现高并发CRUD业务开发》
……完整版尼恩技术圣经PDF集群,请找尼恩领取
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓