OpenMIPS用verilog实现
一、前期准备
1. 编辑、编译、仿真工具
用vscode+iverilog+gtkwave组合实现verilog的编写、编译和波形查看,其配置过程见博主:Macbook M1使用vscode+iverilog+gtkwave实现Verilog代码的编译与运行-CSDN博客 文章浏览阅读1.6k次,点赞11次,收藏25次。最近在研究FPGA的开发,于是需要用到Verilog。但是手头上只有一台M1芯片的Macbook air,本文综合多篇教程,基于vscode+iverilog+GTKwave,带你从零开始在MacBook上搭建Verilog编写与仿真的平台。_gtkwavehttps://blog.csdn.net/qq_62561876/article/details/133901907
gtkwave工具的安装笔者费了一番功夫,最后是先安装MacPorts工具,然后用port命令行安装的方式得以安装成功。
MacPorts工具的安装可以参考:【macOS Sonoma】 MacPorts安装教程 - 哔哩哔哩
用port安装gtkwave
port install gtkwave笔者在输入这条命令行遇到了error:Error: Failed to configure gtk-osx-application-common-gtk2: gtk2 +quartz not installed.
在网上找到教程,输入下面两条命令行,然后再重新安装gtkwave。
sudo port -f deactivate active
sudo port -v -N install gimp +quartz查看verilog仿真模型的三条指令,其中openmips.vcd替换成实际生成的vcd名称
iverilog -o simulation.vvp *.v
vvp simulation.vvp
gtkwave openmips.vcd2. MIPS编译环境的建立
如果希望使用GNU工具链进行编译,可以按此节进行配置。
2.1 linux环境搭建
若电脑没有linux环境,可以在电脑上安装docker,在docker中创建ubuntu镜像。
docker的安装参考链接: Docker 简介和安装 - Docker 快速入门
在docker中拉取ubuntu镜像
docker pull ubuntu在docker中运行ubuntu
docker run -it --name myUbuntu -v /Users/lmx/Desktop/xcode:/home ubuntu /bin/bash查看容器是否运行
docker ps保存容器命令,其中这里最后一个参数是给这个容器命名
sudo docker commit -m="first commit" -a="fu" $id myubuntu:v1运行上面保存好的容器,-v用来实现主机和容器之间的文件挂载
docker run -it -v /Users/lmx/Desktop/xcode:/home/xcode myubuntu:v12.1 GNU工具链
as:GNU汇编器。通常也称为GAS(GNU Assembler)。用来对汇编程序进行编译产生目标文件。
ld:GNU链接器。链接as产生的目标文件,以及重定位数据产生可运行文件。
objcopy:用于将一种格式的目标文件复制成第二种格式。
objdump:用于列出关于二进制文件的各种信息。
readelf:类似于objdump,仅用于处理elf格式的文件。
二、OpenMips处理器蓝图
原始OpenMips处理器模块示意图如下所示,图取自于《自己动手写CPU》。
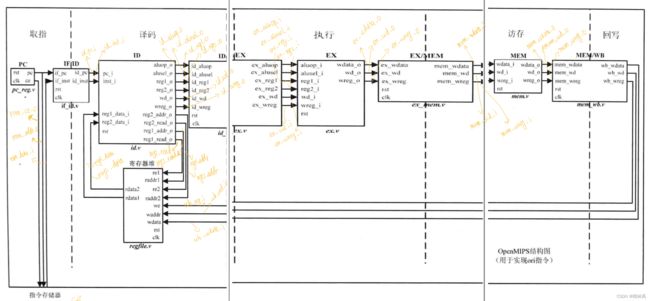
其中各模块的功能主要如下。
取指:取出指令存储器中的指令,PC值递增,准备取下一条指令。
译码:对指令进行译码,判断指令类型。从通用寄存器中取出源操作数。这里有两个源操作数寄存器,这两个源操作数寄存器都可以根据各自的使能信号选择读取通用寄存器的值还是使用立即数。
执行阶段:依据译码阶段送入的源操作数、操作码进行运算。
访存阶段:访存mem。
写回阶段:将运算结果保存到目的寄存器。
图中所有的IF/ID、ID/EX等衔接模块都是实现打拍功能,隔离开各组合模块,经过这些模块时间周期为一个cycle。其它模块为组合模块。
仿真波形图如下,195ns时rst置为0,在下一个clk上升沿,rom_ce使能信号有效,此时读取到第一条inst。经过if/id模块打一拍送到id模块进行译码,再经过id/ex模块打一拍送到ex中执行运算,再经过ex/mem模块打一拍送到mem模块进行访存,最后经过mem/wb模块打一拍将结果写回到通用寄存器。从指令读取出来到mem/wb模块的 wb_wreg信号拉高一共经历了4个cycle,wb_wreg拉高后将结果写入到通用寄存器为一拍,故而整个过程一共耗时5个时钟周期。