【MySQL】常见函数和约束以及多表查询
目录
- 字符串函数
- 数值函数
- 日期函数
- 流程函数
- 约束
- 多表查询
-
- 连接查询
-
- 内连接
- 外连接
- 自连接
-
- 联合查询
- 子查询
字符串函数
| 函数 | 功能 |
|---|---|
| CONCAT(S1,S2,…Sn) | 字符串拼接,将S1, S2, … Sn 拼接成一个字符串 |
| LOWER(str) | 将字符串 str 全部转为小写 |
| UPPER(str) | 将字符串 str 全部转为大写 |
| LPAD(str, n, pad) | 左填充,用字符串 pad 对 str 的左边进行填充,达到 n 个字符串长度 |
| RPAD(str, n, pad) | 右填充,用字符串 pad 对 str 的右边进行填充,达到 n 个字符串长度 |
| TRIM(str) | 去掉字符串头部和尾部的空格 |
| SUBSTRING(str, start, len) | 返回从字符串 str 从 start 位置起的 len 个长度的字符串 |
例如:

例如:

例如:

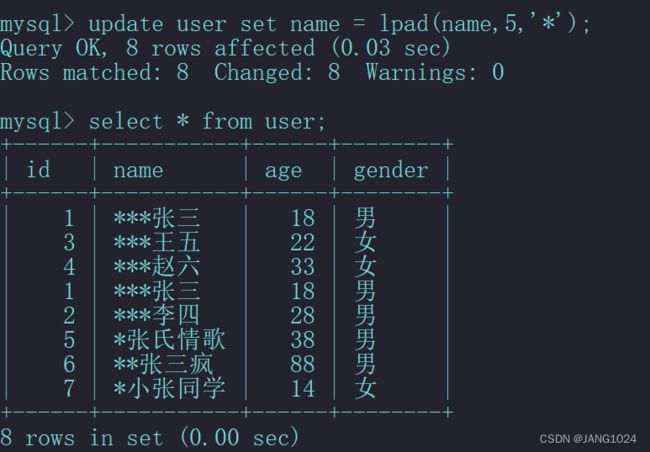
例如在 user 表中的 name 字段前面添加 * ,使得添加后长度变成5:
数值函数
常见数值函数如下:
| 函数 | 功能 |
|---|---|
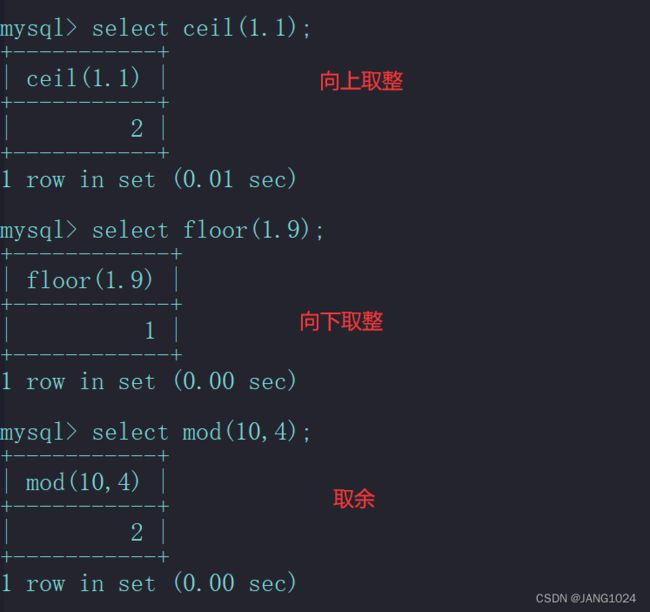
| CEIL(x) | 向上取整 |
| FLOOR(x) | 向下取整 |
| MOD(x, y) | 返回 x/y 的模 |
| RAND() | 返回 0~1 内的随机数 |
| ROUND(x, y) | 求参数 x 的四舍五入的值,保留 y 位小数 |
例如:
例如:

日期函数
| 函数 | 功能 |
|---|---|
| CURDATE() | 返回当前日期 |
| CURTIME() | 返回当前时间 |
| NOW() | 返回当前日期和时间 |
| YEAR(date) | 获取指定 date 的年份 |
| MONTH(date) | 获取指定 date 的月份 |
| DAY(date) | 获取指定 date 的日期 |
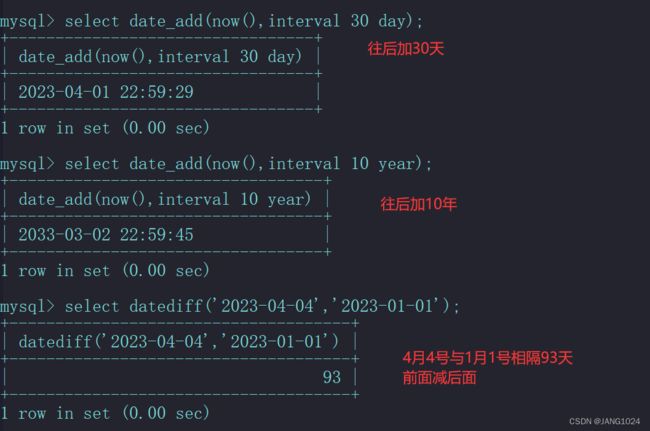
| DATE_ ADD(date, INTERVAL expr type) | 返回一个日期/时间值加上一个时间间隔 expr 后的时间值 |
| DATEDIFF(date1, date2) | 返回起始时间 date1 和结束时间 date2 之间的天数 |
例如:

例如:

例如:
流程函数
| 函数 | 功能 |
|---|---|
| IF(value, t, f) | 如果 value 为 true,则返回 t,否则返回 f |
| IFNULL(value1, value2) | 如果 value1 不为 null,返回 value1,否则返回 value2 |
| CASE WHEN [val1] THEN [res1] … ELSE [default] END | 如果 val1 为 true,返回 res1, … 否则返回 default 默认值 |
| CASE [expr] WHEN [val1] THEN [res1] … ELSE [default] END | 如果 expr 的值等于 val1,返回 res1, … 否则返回 default 默认值 |
例如:

例如,性别为男,就叫 ***先生,为女,就叫 ***女士:

约束
约束是作用于表中字段上的规则,用于限制存储在表中的数据,其目的是保证数据库中数据的正确性、有效性和完整性。
分类:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段的数据不能为 null | NOT NULL |
| 唯一约束 | 保证该字段的所有数据都是唯一、不重复的 | UNIQUE |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | PRIMARY KEY |
| 默认约束 | 保存数据时,如果未指定该字段的值,则采用默认值 | DEFAULT |
| 检查约束(8.0.16版本之后) | 保证字段值满足某一个条件 | CHECK |
| 外键约束 | 用来让两张表的数据之间建立连接,保证数据的一致性和完整性 | FOREIGN KEY |
假设我们现在需要设计一张有如下要求的表:
id 字段,主键,并且自动增长。也就是从 1 开始,每插入一条数据,id 加一 (primary key、auto_increment);
name 字段,不为空,并且唯一。插入内容时,名字不能为空也不能重复 (not null、unique);
age 字段,插入时,需要检查插入的年龄是否大于 0,并且小于等于 120 (check);
status 字段,如果没有指定值,状态默认为 1 (default);
gender 字段,暂无约束;
根据以上要求,我们建表的SQL语句如下:
create table user(
id int primary key auto_increment,
name varchar(10) not null unique,
age int check(age > 0 and age <= 120),
status char(1) default '1',
gender char(1)
);
注意:同个字段可以有多个约束,约束之间只用空格即可。
下面开始插入数据:
插入重复名字时:

插入年龄不在指定区间时:
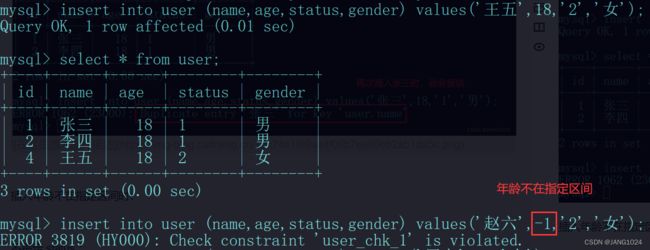
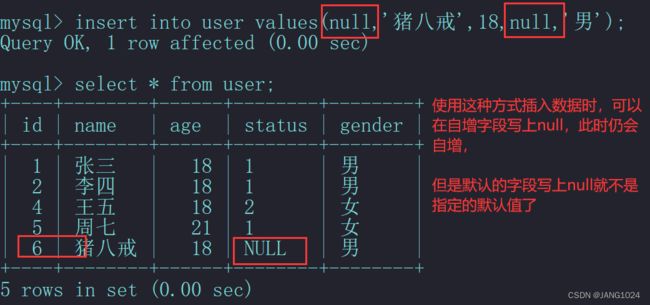
不指定 status :

外键:
外键用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性。
具有外键的表就是子表,外键所依赖的表就是父表。
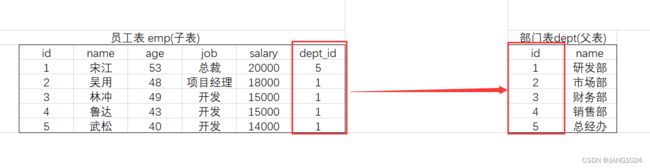
(员工表通过 dept_id 这个外键和部门表建立连接)
添加外键:
- 创建表同时添加:
CREATE TABLE 表名(
字段名 数据类型,
...
[CONSTRAINT] [外键名称] FOREIGN KEY(外键字段名) REFERENCES 主表(主表列名)
);
- 创建表之后,通过修改表结构添加:
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY(外键字段名) REFERENCES 主表(主表列名);
我们选择创建表的同时添加外键:
先建立父表 dept,因为子表在建立外键时需要父表:

建立子表 emp 同时创建外键:
create table emp(
id int auto_increment primary key,
name varchar(20) not null,
age int,
job varchar(20),
salary int,
dept_id int,
foreign key(dept_id) references dept(id)
);
insert into emp values
(1, '宋江',53,'总裁',20000, 5),
(2,'吴用',48,'项目经理',18000,1),
(3,'林冲',49,'开发',15000,1),
(4,'鲁达',43,'开发',15000,1),
(5,'武松',40,'开发',14000,1);
建立外键之后,我们就不能删除关联着父表的 id 了:

上图能删除 id 为 2 的记录,是因为子表中没有部门 id 为 2 的员工,但是有部门 id 为 1 的员工,所以不能删除。这就保证了数据的完整性和一致性。
删除外键:
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
当我们尝试删除外键时,会报一个错:

这是因为我上面创建外键时没有给外键约束取一个名称,所以 mysql 自动生成了一个名称,这个名称和收到约束的外键列名不一样,所以删除外键时,需要的是外键约束名,而不是表里的列名。
我们可以使用 show create table 表名; 来查看建表语句,里面包含了外键名称:

获取到外键名称后,我们就可以删除外键了:
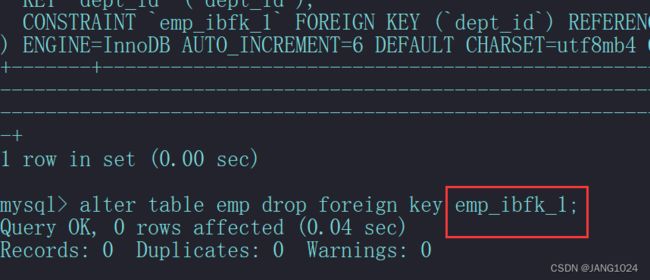
多表查询
多表关系: 在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,可分为三种:
- 一对多(多对一):
例如一个学生只属于一个班级,而一个班级可以有多个学生。 - 多对多:
例如一个学生可以选择多门课程,而一门课程也可以被多名学生选择。 - 一对一
例如一个学生只有一个学号。
多表查询: 多表查询就是从多张表中查询数据。
现在有 table1 和 table2 两张表:

我们需要进行多表查询,方法和查询一张表类似,只需在第一张表之后在加上另外一张表:
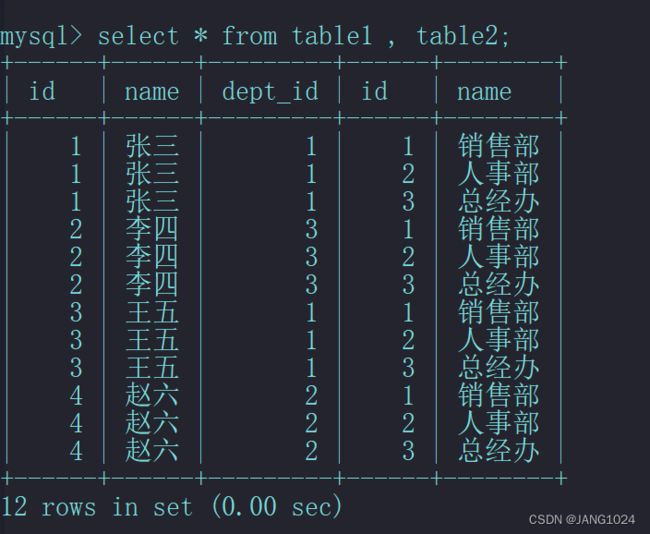
结果有 12 条数据,这是 table1 的 4 条数据和 table2 的 3 条数据进行了一一组合,也就是笛卡尔积。
笛卡尔积: 笛卡尔积是指在数学中,两个集合 A集合 和 B集合的所有组合情况。

所以在上面的查询结果才等于两个表的乘积,但是并不是每条数据都是有效的,只有 4 条数数据才是有效的,也就是 table1 的 dept_id 等于 table 的 id 的数据:
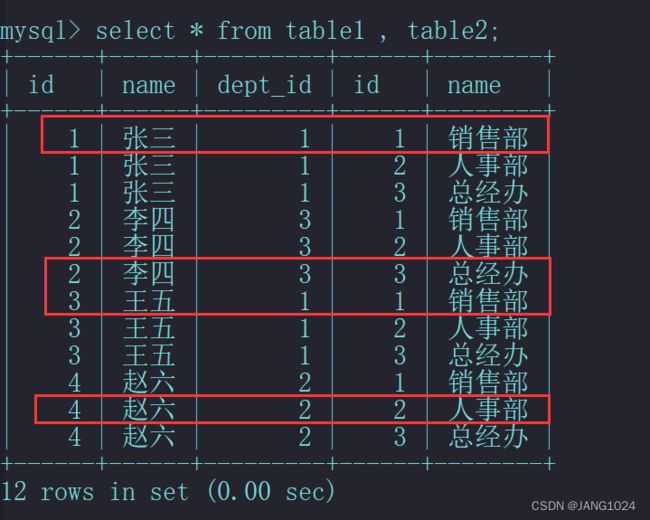
所以我们可以添加条件来过滤掉无效的数据:

连接查询
连接查询分为内连接和外连接。
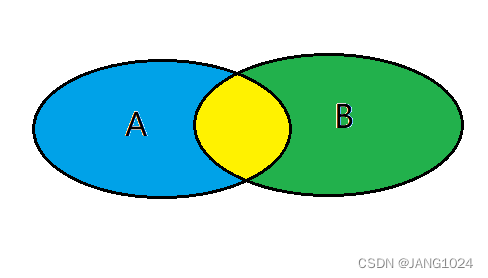
内连接
内连接查询的是两张表交集的部分(黄色区域):
内连接查询语法:
➢ 隐式内连接:
SELECT 字段列表 FROM 表1, 表2 WHERE 条件

➢ 显式内连接:
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件…;(inner 可以省略)

外连接
➢ 左外连接: 查询 表1(左表) 的所有数据包含 表1 和 表2 交集部分的数据。
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件… ;
➢ 右外连接: 查询 表2(右表) 的所有数据包含 表1 和 表2 交集部分的数据。
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件… ;
在演示外连接前,我们先插入一条数据:

此时使用内连接则会忽略 周七 这条数据的:

而我们使用左外连接查询:

右外连接查询:

自连接
自连接就是自己连接自己,可以是内连接查询,也可以是外连接查询。
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件… ;
我们先看这样一张表:

下面我们需要查询员工及其所属领导的名字:

查询语句:

查询所有员工及其领导的名字,无论有没有领导:

联合查询
对于 union 查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
SELECT 字段列表 FROM 表A …
UNION [ALL]
SELECT 字段列表 FROM 表B …;
注意: 对于联合查询的多张表的列数必须保持一致, 字段类型也需要保持一致。
union all 会将全部的数据直接合并在一起,union 会对合并之后的数据去重。
例如,将年龄65岁以下的员工,和 薪资 低于 16000的员工全部查询出来:
我们先查询满足部分条件的员工:

而使用联合查询则是把上面的两个查询结果给拼接起来:

子查询
SQL 语句中嵌套 SELECT 语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 );
子查询外部的语句可以是 INSERT / UPDATE / DELETE / SELECT 中的任何一个。
根据子查询结果不同,又可以分为:
-
标量子查询(子查询结果为单个值)
例如,查询 销售部 的多有员工:

例如查询刘唐之后入职的员工信息:

-
列子查询(子查询结果为一列)
常用操作符:IN、NOT IN、ANY、SOME、ALL
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
| ANY | 子查询返回列表中,有任意一个满足即可 |
| SOME | 与ANY等同,使用SOME的地方都可以使用ANY |
| ALL | 子查询返回列表的所有值都必须满足 |
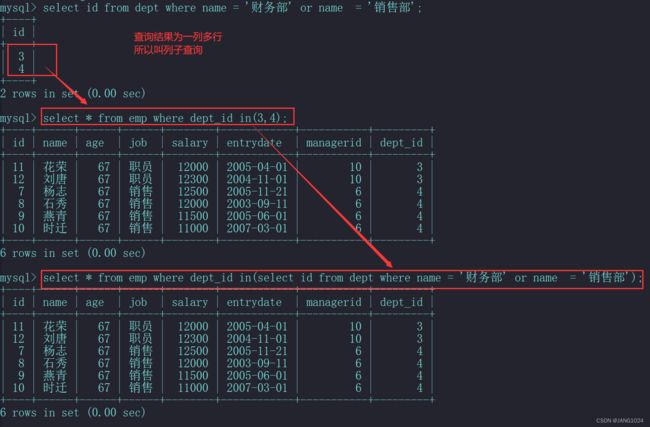
例如查询 财务部 和 销售部 的所有员工信息:
例如,查询比 销售部 所有人工资都高的员工信息:

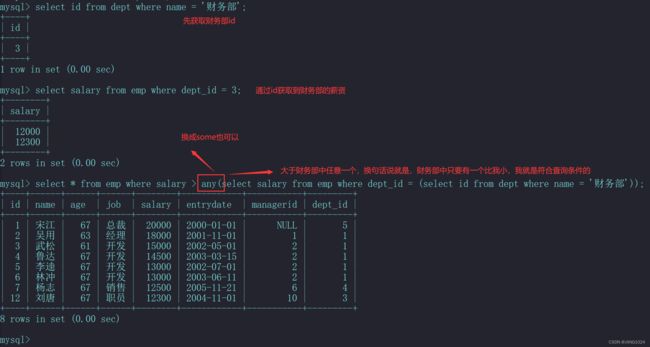
例如,查询比 财务部 任意一人工资都高的员工信息:
-
行子查询(子查询结果为一行,可以有多个字段)
常用操作符:=、<>、IN、NOT IN
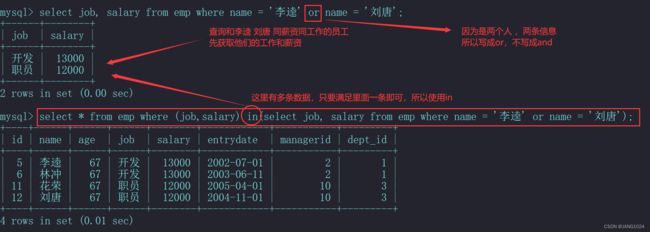
例如,查询与 ‘李逵’ 的薪资和领导都相同的员工信息:

-
表子查询(子查询结果为多行多列)
例如,查询和 李逵,刘唐 同工作同薪资的员工信息: