案例:数据提取/数据获取/爬虫—工具篇—影刀
介绍
影刀
批量数据抓取


案例
官方案例1
3条命令实现批量数据抓取

命令含义

第一步:
提前用谷歌浏览器打开数据抓取的网址


第二步:数据提取

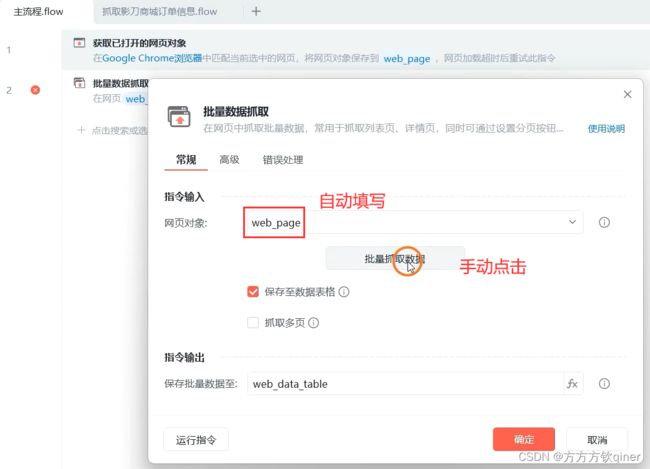
加分功能1:抓取多页,需获取元素



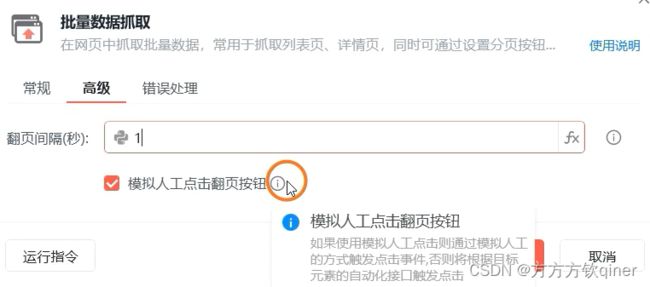
加分功能2:网页加载时间过长,可以调整“翻页间隔的时长”;网页有弹框类信息遮挡翻页按钮,可以取消模拟人工点击翻页按钮选项,通过底层代码去点击。
第三步:数据存到excel保留到本地
1、输出数据结果


2、保存的excel
第四步:自定义编辑数据
首先,点击“不是我想要”

然后,再捕获相似元素
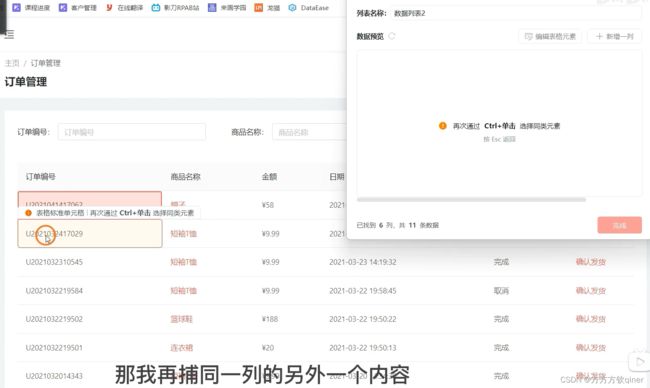
数据就会自动获取,接着,可“新增一列”,重复上述操作即可

注意,若出现如下报错,只需要重选相似元素捕获即可。

其次,可以通过鼠标自由调整列,点击三点,可以进行列表插入等操作。

其中,有“编辑列”,类似捕获元素时的元素编辑,是该列的元素属性。通过“校验元素”,可以验证捕获元素是否正常,有问题时需要进行元素编辑。


其中,还有“提取为链接列”,适用于有超链接的捕获


捕获后已经自动提取了超链接,如果没有提取
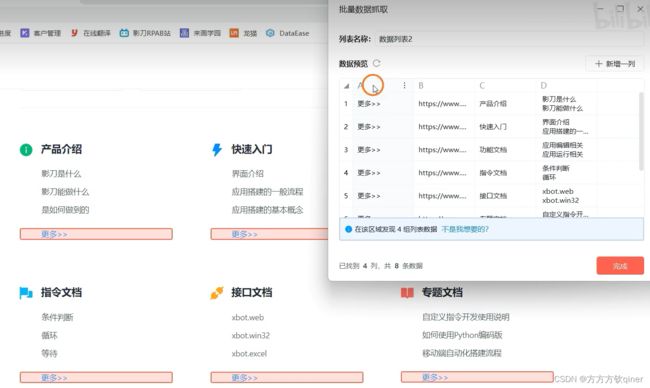
则,手动选择“提取为链接列”

其中,还有还有“处理列数据”,需要学习“正则表达式”

案例2



import xbot
import xbot_visual
from . import package
from .package import variables as glv
import time
def main(args):
try:
web_page = xbot_visual.web.create(web_type="cef", value="https://uland.taobao.com/sem/tbsearch?refpid=mm_26632258_3504122_32538762&keyword=%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%94%B5%E8%84%91&clk1=08d140917a02706d0af264930b2a9309&upsId=08d140917a02706d0af264930b2a9309&spm=a2e0b.20350158.search.1&pid=mm_26632258_3504122_32538762&union_lens=recoveryid%3A201_33.54.87.175_4881315_1660392167968%3Bprepvid%3A201_33.54.87.175_4881315_1660392167968", wait_load_completed=True, load_timeout="20", stop_load_if_load_timeout="handleExcept", chrome_file_name=None, edge_file_name=None, ie_file_name=None, bro360_file_name=None, firefox_file_name=None, arguments=None, _block=("main", 1, "打开网页"))
for _xbot_retry_time in range(4):
try:
web_page2 = xbot_visual.web.get(web_type="cef", mode="url", value="https://uland.taobao.com/sem/tbsearch?refpid=mm_26632258_3504122_32538762&keyword=%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%94%B5%E8%84%91&clk1=08d140917a02706d0af264930b2a9309&upsId=08d140917a02706d0af264930b2a9309&spm=a2e0b.20350158.search.1&pid=mm_26632258_3504122_32538762&union_lens=recoveryid%3A201_33.54.87.175_4881315_1660392167968%3Bprepvid%3A201_33.54.87.175_4881315_1660392167968", use_wildcard=False, wait_load_completed=True, load_timeout="20", stop_load_if_load_timeout="handleExcept", open_page=False, url=None, _block=("main", 2, "获取已打开的网页对象"))
break
except Exception as e:
if _xbot_retry_time == 3:
raise e
else:
xbot_visual.programing.log(type='info', text=f'第2条指令: {e}')
time.sleep(3)
file_path = xbot_visual.programing.databook.export_data(folder_source="desktop", custom_folder_path="", file_name="影刀数据表格.xlsx", export_header=True, _block=("main", 3, "数据表格导出"))
web_data_table = xbot_visual.web.element.data_scraping(browser=web_page2, table_element=package.selector("数据列表3"), handle_pager=False, page_element=None, max_page="0", page_interval="1", simulate_click_page=True, save_to_datasheet=True, _block=("main", 4, "批量数据抓取"))
finally:
pass
第一步:安装库,遇到以下问题

进入https://pypi.org/project/x-bot/#files


将下载的包放在d盘,方便pip install下载
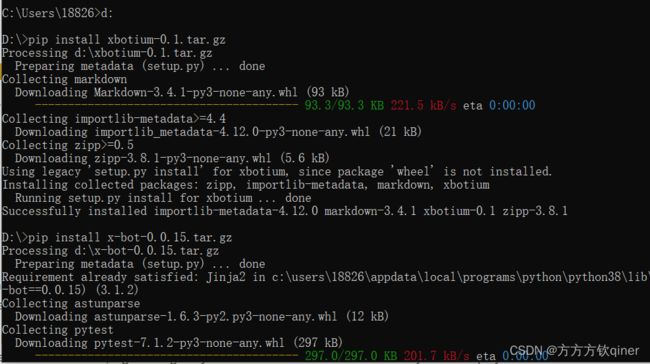
但是,没有找到xbot_visual

强化下载: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn xbot_visual

