MFTCoder 重磅升级 v0.3.0 发布,支持 Mixtral 等更多模型,支持收敛均衡,支持 FSDP

1. MFTCoder 简介
CodeFuse在2023年9月开源了一种多任务微调框架——MFTCoder,它可以实现在多个任务上同时并行地进行微调。通过结合多种损失函数,我们有效地解决了多任务学习中常见的任务间数据量不平衡、难易不一和收敛速度不一致等挑战。大量实验结果显示,相较于单独对单个任务进行微调或者多任务混合为一后进行微调,我们的多任务微调方法表现更优。此外,MFTCoder具备高效训练特征,包括提供高效的数据Tokenization模式和支持PEFT微调,能有效提升微调训练速度并降低对资源的需求。MFTCoder是轻量的,简单清晰的,易于二次开发的,持续跟进Cutting-Edge技术的开源微调框架。
今天,我们对MFTCoder进行重磅升级,比如对Mixtral这个开源MoE的SOTA的多任务微调的支持;再比如我们提供了之前论文中提到的收敛均衡技术:Self-Paced Loss。
MFTCoder已适配支持了更多的主流开源LLMs,如Mixtral、Mistral、Deepseek、 Llama、CodeLlama、Qwen、CodeGeeX2、StarCoder、Baichuan2、ChatGLM2/3、GPT-Neox等。以Deepseek-coder-33b-base为底座,使用MFTCoder微调得到的CodeFuse-Deepseek-33B在HumaneEval测试中pass@1得分高达78.65%(greedy decoding)。
MFTCoder的详细介绍在我们之前的公众号文章中:干货!MFTCoder论文多任务微调技术详解
MFTCoder技术细节的论文已经放出到Arxiv:
https://arxiv.org/pdf/2311.02303.pdf;
新升级代码也已经开源到github:https://github.com/codefuse-ai/MFTCoder/tree/main/mftcoder_accelerate

2. v0.3.0新特性Hightlights
- 首先,新版本已经适配到最新的transformers v4.36.0, 它能带给我们更好的原生modeling,进而可以在很多开源模型比如llama等训练中有更多的Attention实现选择,比如 FlashAttention2,torch的SDPA和最基本的naive Attention(eager模式)。这样可以照顾到使用不同硬件的同学。对于最常用的FlashAttention2, 适配最新的v2.3.6,让MFTCoder可以有效利用最新的FlashAttention,比如sliding_window Attention, 进而支持类似Mixtral的全部特性。
- 然后,MFTCoder-accelerate框架在原有支持Accelerate+DeepSpeed的基础上,增加了对FSDP的支持,进而升级为Accelerate + DeepSpeed/FSDP模式,以便给开发者提供更多选择。DeepSpeed对LoRA/QLoRA更适合,而FSDP在全量参数训练方面具备更快的性能。
- 第三,我们也将MFTCoder支持的模型增加了Mistral, Mixtral-8x7b,Deepseek-coder, Chatglm3等新的主流开源模型。我们用新版MFTCoder训练的CodeFuse-Mixtral-8x7B, 是通用自然语言大模型经过多代码任务微调后代码能力领先的。而我们用MFTCoder训练的CodeFuse-DeepSeek-33B 更是可以在BigCode Leaderboard上以41.62%的胜率排在目前第一名。
- 最后,我们引入了Self-Paced Loss, 作为MFT多任务微调收敛均衡的新loss,它能为我们带来初步的收敛均衡,用过去窗口时间内验证损失来调整不同任务的权重,进而控制不同任务的收敛速度,以达到多个任务同时收敛的目的, 避免一些任务已经过拟合而另一些任务还未收敛。它的效果可以通过以下使用self-paced loss和原始MFT loss的收敛情况观察到。

3. MFTCoder提升Mixtral-8x7B混合专家模型的代码能力实践
CodeFuse-Mixtral-8x7B 模型地址:
https://modelscope.cn/models/codefuse-ai/CodeFuse-Mixtral-8x7B
https://huggingface.co/codefuse-ai/CodeFuse-Mixtral-8x7B
3.1. Mixtral-8x7B底座代码能力总览
Mixtral-8x7B 是由Mistral AI开源的自然语言大模型。它是以Mistral-7B为基础,将8个7B模型通过稀疏混合专家(SMoE)模式混合到一起训练的MoE模型。作为一个MoE模型, Mixtral-8x7B的每一层的Attention是8个expert共用的,而每个expert是一个单独的MLP模块, 通过一个gate进行路由,每次推理激活两个expert。因此Mixtral尽管有8x7B, 实际推理时相当于只用了12B的计算。缺点是Mixtral-8x7B对于显存的需求依然很大,相当于一个46B的模型。
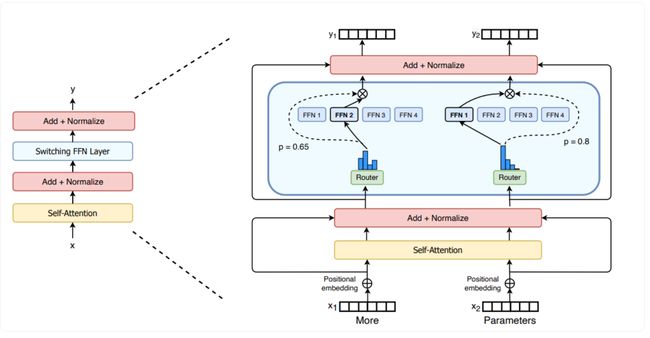
Sparse MoE: Switching transformer原理图
来源: https://huggingface.co/blog/moe
Mixtral-8x7B本身是一个通用自然语言大模型,并没有对代码进行针对性的加训,但它自身的代码能力在一众非代码大模型中是领先的,基本和CodeLLama-13B这个代码大模型性能相当,我们可以将它和一些主流通用自然语言大模型在HumanEval-X数据集中五种语言的Pass@1 评测结果对比如下(用Greedy解码统一测试):
| Model |
Python |
C++ |
Java |
JavaScript |
Go |
平均 |
| Mixtral-8x7B |
41.46% |
40.84% |
53.05% |
45.12% |
23.78% |
40.85% |
| Qwen-14B |
32.93% |
35.37% |
32.93% |
30.49% |
21.34% |
30.61% |
| Baichuan2-13B |
17.1% |
20.73% |
5.49% |
16.45% |
6.71% |
13.30% |
| CodeGeeX2-6B |
35.90% |
30.80% |
32.20% |
29.30% |
22.50% |
30.14% |
| StarCoder-15B |
33.57% |
30.22% |
30.79% |
31.55% |
17.62% |
28.75% |
| CodeLLama-13B |
43.29% |
41.46% |
38.41% |
34.76% |
29.27% |
37.44% |
Mixtral-8x7B的成功,为我们提供了关于MoE模型的很好地例子,证明了MoE模型是一个很好的趋势和方向。因此我们尝试对它进行多代码任务微调,看看它在微调后的代码能力提升如何。同时,Mixtral-8x7B也为代码大模型使用MoE提供了很多值得借鉴的地方,尤其是多任务代码大模型与MoE的思路有很多重合之处。
3.2. MFTCoder 多任务微调Mixtral-8x7B
借助MFTCoder(v0.3.0)的多任务微调能力,我们可以使用多个代码任务数据集对Mixtral-8x7B进行多任务微调(MFT)。在任务选择上,我们精选了3个核心代码任务数据,即代码补全(Code Completion),代码生成(Text2Code), 单测生成(Unittest Generation)一共60w条指令问答数据。该数据组合包含代码生成的三个基础任务,用基础任务微调对齐过的模型,在各类未训练过的代码任务上也有不错的泛化能力。
由于Mixtral-8x7B参数量比较大,尽管它是稀疏模型,实际计算仅仅类比12B模型,但是由于它依然需要46B模型所需要的显存,因此训练采用MFTCoder的多任务QLoRA微调模式,且代码任务属于相对复杂任务,我们对更多的模块进行微调,微调的模块我们采用和之前稍有区别的策略,只微调Attention,相应的配置如下:
{
"lora_rank": 96,
"lora_alpha": 32,
"lora_dropout": 0.05,
"targeting_modules": ["q_proj", "k_proj", "v_proj", "o_proj"]对以上数据进行了约5个Epoch的训练到收敛。训练过程loss情况如下图所示:
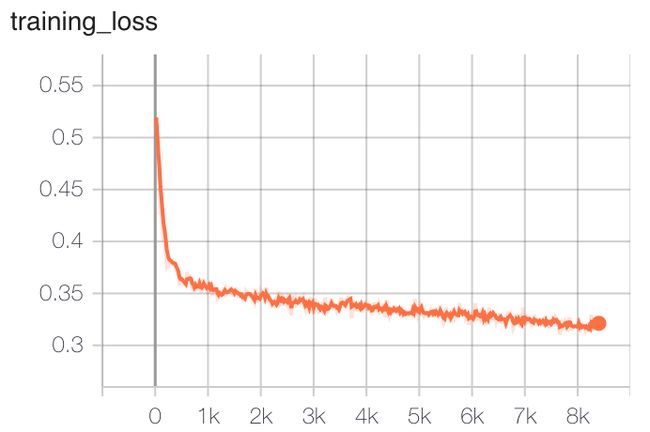

通过多任务微调,CodeFuse-Mixtral-8x7B的各方面代码能力均有比较大的提升。
3.3. CodeFuse-Mixtral-8x7B模型效果
对Mixtral-8x7B进行多代码任务微调后,CodeFuse-Mixtral-8x7B在HumanEval-X数据集中五种语言的Pass@1评测结果对比如下(用Greedy解码统一测试),我们同时用开源的通用自然语言大模型的Qwen-14B以及CodeFuse-Qwen-14B的代码能力做比较。
| Model |
Python |
C++ |
Java |
JavaScript |
Go |
平均 |
| CodeFuse-Mixtral-8x7B |
56.1% |
50.6% |
57.3% |
56.7% |
43.3% |
52.8% |
| Mixtral-8x7B |
41.5% |
40.8% |
53.1% |
45.1% |
23.8% |
40.9% |
| CodeFuse-Qwen-14B |
48.8% |
41.5% |
46.3% |
38.4% |
26.8% |
40.4% |
| Qwen-14B |
32.9% |
35.4% |
32.9% |
30.5% |
21.3% |
30.6% |
可以看出, CodeFuse-Mixtral-8x7B 在 Mixtral-8x7B的基础上,各语言代码能力(HumanEval-X)均有明显提高, 比Mixtral-8x7B平均pass@1提高12%, 达到40.9% -> 52.8%。这是目前开源的非代码大模型经过多任务代码微调后较为领先的。
4. 联系我们
MFTCoder最新版本v0.3.0已经开源,感兴趣的同学可以用版本tag或者持续跟踪main分支,本文中提到的模型和数据集也在陆续开源中,如果您喜欢我们的工作,欢迎试用、指正错误和贡献代码,可以的话请给我们的项目增加Star以支持我们。
- GitHub项目主页:https://github.com/codefuse-ai/MFTCoder
- HuggingFace主页:https://huggingface.co/codefuse-ai
- 魔搭社区主页:ModelScope 魔搭社区
- CodeFuse官网:https://codefuse.alipay.com