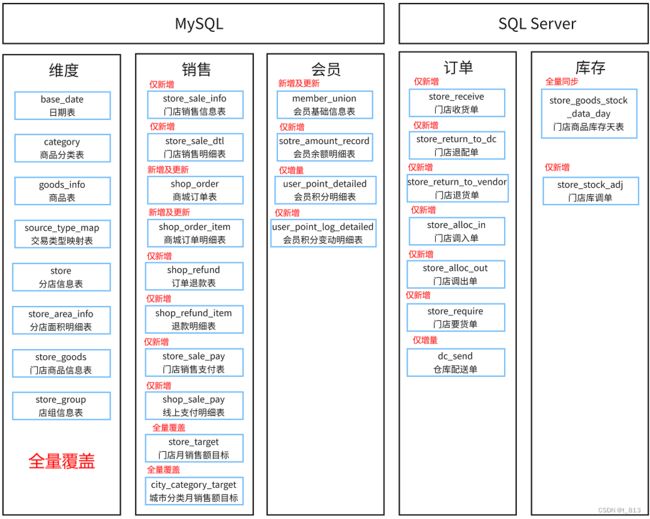
基于DataX完成数据导入-全量覆盖方案
建模设计: 建模需要考虑的问题
1- 数据的同步方式是什么?
全量覆盖同步:
在建表的时候, 不需要构建分区表, 每一次都是将之前的数据全部删除, 然后全部都重新导入一遍
适合于: 数据量比较少, 而且不需要维护历史变化行为
仅新增同步:
在建表的时候, 需要构建分区表, 分区字段是以更新的周期一致即可, 比如 更新的周期为天, 分区字段也应该为天, 每一次导入上一天的新增的数据
适合于: 数据量比较大, 而且不需要维护历史变化行为(并不代表表不存在变化, 只不过这个变化对分析没有影响)
新增及更新同步:
处理逻辑: 在建表的时候, 需要构建分区表, 分区字段是以更新的周期一致, 比如 更新的周期为天, 分区字段也应该为天,每一次导入上一天的新增及更新的数据
适合于: 数据量比较大, 而且需要后期维护历史变化
全量同步:
在建表的时候, 需要构建分区表, 分区字段以更新的周期一致即可, 比如 更新的周期为天, 分区字段也应该为天,每一次导入的时候, 都是将整个数据集全部导入到一个新的分区中, 后期定期删除老的历史数据(比如: 仅保留最近一周)
适合于: 数据量比较少, 而且还需要维护历史变化, 同时维度周期不需要特别长
注意: 此种同步方式相对较少
2- 表是否选择为内部表 还是 外部表?
判断的依据: 是否对数据有绝对的控制权, 如果没有 必须是外部表, 如果有 随意
外部表的使用场景:
1. 数据非常重要或者不易获得 (购买的数据)
2. 多个项目同时引用的数据文件一般做成外部表 例如 (日期表 , 公司组织架构表)
3- 表是否为分区表还是分桶表?
分区表: 分文件夹, 将数据划分到不同的文件夹中, 当查询数据的时候, 通过分区字段获取对应分区下的数据, 从而减少数据扫描量, 提高查询效率(一般存在更新及新增数据的表都会使用分区表 ,根据更新和新增周期进行分区)
分桶表: 分文件 将数据根据指定的字段划分为N多个文件 可以通过这种方式对数据进行采样操作 以及分桶表在后续进行join优化的时候也会涉及到(bucket Map Join | SMB Join)4- 表选择什么存储格式 和 压缩方案?
存储格式: 一般都是 ORC / Text File
压缩格式: 一般都会 SNAPPY / GZ / zlib(默认)
存储格式: 如果数据直接对接的普通文本文件的操作 只能使用textFile 否则大多数都是ORC
压缩格式: 读多写少 采用SNAPPY 写多读少 采用GZ 如果普通的文本文件对接, 一般不设置压缩
如果空间比较充足, 没有特殊要求, 建议统一采用SNAPPY5- 表中字段应该如何选择呢?
ODS层: 业务库有那些表, 表中有哪些字段, 对应在ODS层建那些表, 表中对应有相关的字段 额外根据同步方式, 选择是否添加分区字段
其他层次: 不同层次 需要单独分析, 目标: 把需求分析的结果能够完整的在表中存储起来即可
缓慢渐变维:
在我们进行数据同步的过程中, 既有更新,又有新增的数据表, 如果要进行数据历史变更行为的记录,就要使用到缓慢渐变维.
SCD1:不维护历史变更行为, 直接对过去数据进行覆盖即可
此种操作 仅适用于错误数据的处理

新增且更新后

SCD2: 维护历史变化行为, 每天同步全量的数据, 不管是否有变化, 均全量维护到一个新的分区中
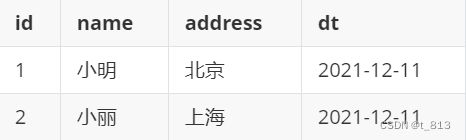
新增且更新后

SCD3:维护历史变更行为,处理方式在表中新增两个新的字段,一个是起始时间,一个是结束时间,当数据发生变更后,将之前的数据设置为过期,将新的变更后完整的数据添加到表中,重新记录其起始和结束时间,将这种方案称为拉链表
好处:可以维护更多的历史版本的数据, 处理起来也是比较简单的 (利于维护)
弊端:造成数据冗余存储 大量占用磁盘空间

新增且更新后
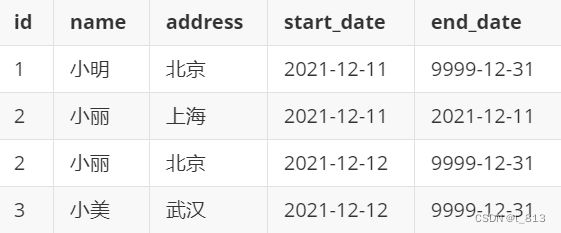
注意: 获取所有数据的最新状态, 使用 end_date = '9999-12-31'
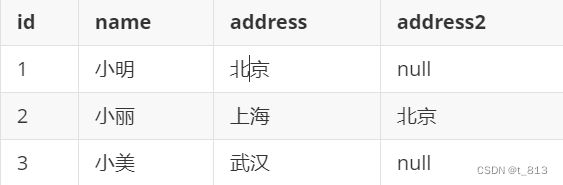
SCD4:维度历史变化,处理方式,当表中有字段发生变更后,新增一列,将变更后的数据存储到这一列中即可
好处:减少数据冗余存储
弊端:只能维护少量的历史版本, 而且维护不方便, 效率比较低

新增且更新后
Hive中构建原始业务表(ods层建表)
同步方式(通过查询表字段确定)
技巧: 如果表中没有时间维度字段, 则该表大概率为全量覆盖表.
如果表中仅有创建时间, 没有更新时间, 则该表一般为仅新增表
如果表中既有创建时间字段, 又有更新时间字段, 则该表一般为新增及更新表(但是此时要与业务部门确认, 因为新增及更新表,会占用大量的磁盘空间,所以有些表我们会酌情改为仅新增.)
内部表还是外部表
当前数据, 几乎都是从数据源数据库中提取出来的, 数据不是不可重复获得,且重要程度不是极高, 所以我们建议使用内部表.
分区表还是分桶表
技巧: 当前业务中, 所有的仅新增和 新增及更新表,都使用时间作为分区字段的分区表, 分区字段, 就是创建时间或者更新时间或者数据处理时间.
技巧: 开发中,我们一般不对于ods层的数据进行分桶. 因为这部分数据,一般是采用三范式进行建模的, 表的数据体量小,且每次我们仅分析一天的数据,累加到dw层中, 数据量小, 数据字段少, 没必要分桶. 而分桶表一般出现在dw层.
压缩和存储格式
技巧: 在hive开发中 一般情况下, 都会采用orc格式存储, 存储效率高, 读写速度快. 支持SNAPPY压缩格式, 压缩和解压效率也跟高
所以, 一般采用 snappy + orc格式进行压缩个存储格式的指定.
如果服务器的存储资源不是非常丰富, ods层会采用zlib 压缩格式, 或者gz压缩格式, 因为压缩比例高, 且ods层数据不会反复读写.(ods层数据读取一次,进行etl后就导入dw层, 此后将会反复在dw层进行数据处理,而不会读取ods层数据, 但是ods层数据体量较大,占用磁盘空间多,)
总结
我们开发中 在ods层会使用 : orc + zlib格式, 而其他分层则使用 orc + snappy格式
基于DataX完成数据导入
由于ODS层涉及到不同的同步方式导入方案, 每一种导入方式均有所差异性, 此处举例四种导出模式, 其余的表自行完成即可
初始准备工作
1- 在DataX-Web中新建项目: text
![]()
2- 创建任务模板: 在任务管理的Datax任务模板中添加任务模板(每日凌晨执行一次)


添加完成,点击下次触发时间下的查看,可以看到后续执行的时间。
全量覆盖方案
1- 添加数据源: 点击数据源管理,点击添加。
首先添加mysql的dim库。

接着添加hive的dim库。

任务构建。
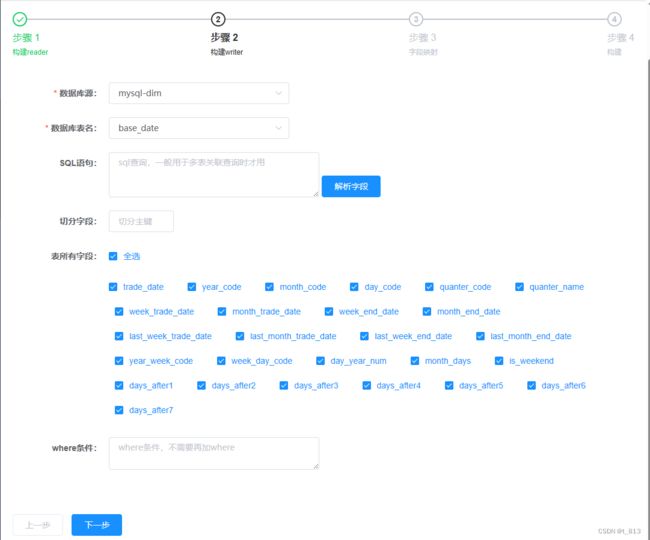
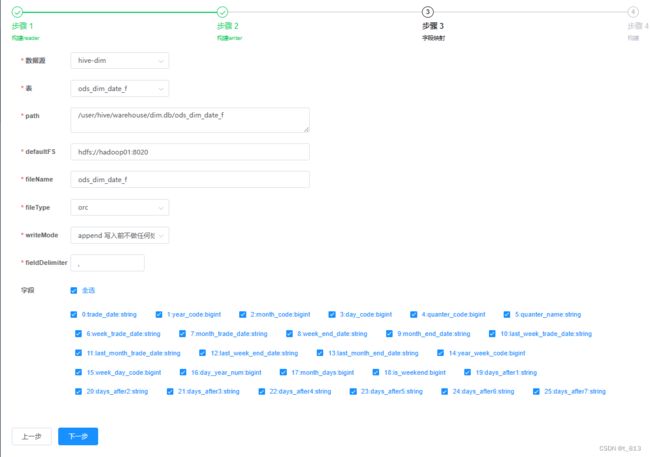
构建writer时,writeMode应该为truncate,即如果目录下有fileName前缀的文件,先删除后写入。但是这里选项中没有,可以先选append,在之后构建json的时候进行更改。

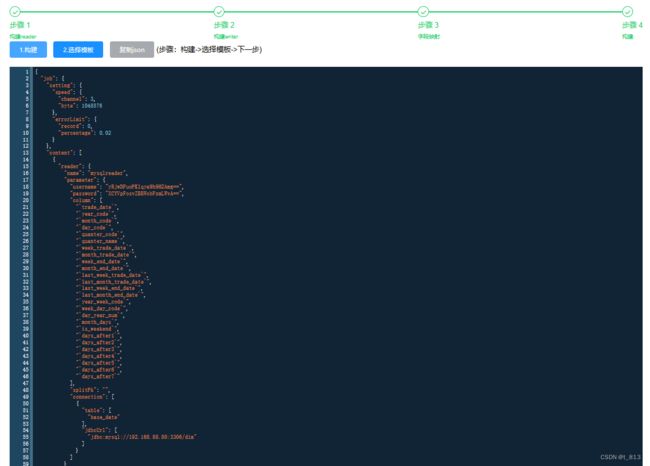
更改writeMode为truncate

![]()
执行任务
![]()
点击状态下的启动,到达下次触发时间后,会自动执行任务。
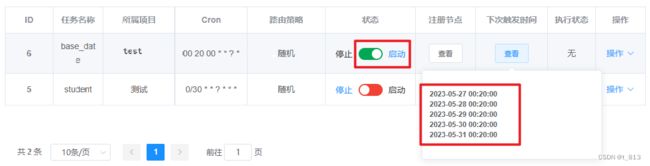
也可以点击操作下的执行一次,立即执行任务。 之后查看日志,可以看到执行成功。
![]()
查看Hive数据
查看HDFS

查看HIVE


经过核对,与mysql数据一致。 此时再次执行任务,执行成功后,发现hive表数据量没有变,说明同步方式是全量覆盖,即插入数据时先清空,后插入。