代码随想录算法训练营第四十二天 | 01背包问题 二维、01背包问题一维、416.分割等和子集
文章目录
- 一、01背包问题 二维
- 二、01背包问题一维
- 三、416.分割等和子集
一、01背包问题 二维
01背包的基础定义不再赘述,详见卡哥的讲解:01背包理论基础(一),这里主要记录自己以前没注意的点和误区。
1、首先,dp数组的定义:dp[i][j]表示从下标为[0,i]的物品中取任意物品并放进容量为j的背包中的价值总和。(以前一直理解错)
注意,是“任意物品”而不是“所有物品”!想清楚这一点,在理解递推公式的时候才不会犯以前研一时候的错误。
2、递推公式的理解:
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
当前背包的状态取决于放不放物品i:放物品i是一个状态,不放物品i是另一个状态。
-
不放物品i时,背包容量仍为j,相当于在前i-1个物品中构建最大价值,dp[i][j]=dp[i-1][j];
-
当物品i放进去时,整个物品集被分为两部分:1到i-1和i。此时i是确定放入的,在j空间中占据wi的重量,剩下的j-wi空间留给物品1到i-1构建最大价值dp[i-1][j-wi],加上第i个物品的价值vi,就为dp[i][j]。
最后,要考量放进物品i到底划不划算,因此两者的最大值。
以前的误区:想当然的以为,诶?怎么会不放物品i反而会更划算呢,放了物品i价值肯定是多了的呀。
这就是没有搞清楚dp数组的定义。dp[i-1]并不是前i-1个都放进背包,而是在前i-1个物品中取任意个物品以达到最大价值。(前i-1个都放进背包,还有什么最大价值可言?以前就是个傻瓜)
所以,对dp数组更通俗的理解为:
dp[i - 1][j]:不取当前这个物品i,多取前面的(放入物品i不划算,占的多但价值少)
[j - weight[i]] + value[i]:取当前这个物品i,但是前面的空间少了,前面相应的价值也小了。
3、遍历顺序:二维dp数组先遍历物品和先遍历背包都可以,先遍历物品较好理解,代码如下。
// weight数组的大小 就是物品个数
for(int i = 1; i < weight.size(); i++) { // 遍历物品
for(int j = 0; j <= bagweight; j++) { // 遍历背包容量
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
感谢b站评论区用户:性感小甲虫画的图片,图中推导了整个01背包二维数组的递推过程。
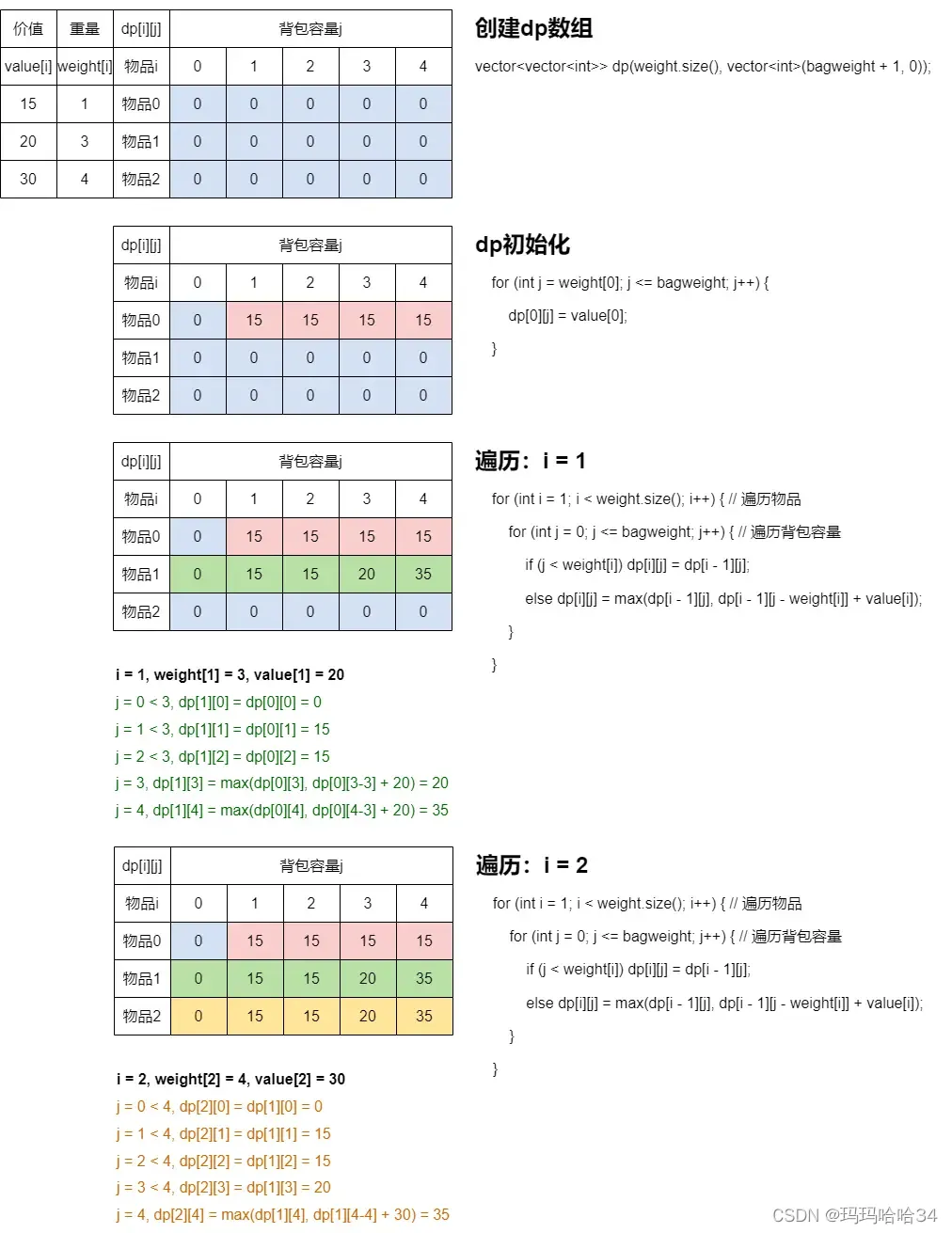
为什么先遍历背包后遍历物品也可以呢?因为dp[i][j]依赖于位于上方的dp[i-1][j]和位于左上方的dp[i-1][j-wi],不管是先背包还是先物品,本质上dp[i][j]都是由左上方(包括正上方)的数据推导出来的。虽然遍历顺序不同,但dp[i][j]所需要的数据一直都是位于左上角,不影响其的推导。
完整的C++测试代码:
void test_2_wei_bag_problem1() {
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int bagweight = 4;
// 二维数组
vector<vector<int>> dp(weight.size(), vector<int>(bagweight + 1, 0));
// 初始化
for (int j = weight[0]; j <= bagweight; j++) {
dp[0][j] = value[0];
}
// weight数组的大小 就是物品个数
for(int i = 1; i < weight.size(); i++) { // 遍历物品
for(int j = 0; j <= bagweight; j++) { // 遍历背包容量
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
cout << dp[weight.size() - 1][bagweight] << endl;
}
int main() {
test_2_wei_bag_problem1();
}
二、01背包问题一维
一维的01背包实际上是由二维的01背包去除掉i这个维度得来的。
为什么可以去除i这个维度呢?因为从dp[i][j]的推导公式可以看出,它只依赖上一行的dp[i-1],因此可以将上一层dp[i-1]拷贝到当前dp[i]这一层上,不断更新dp[i][j]的值,就像滚动一样,因此也叫滚动数组。
详细的讲解见卡哥的代码随想录,这里主要记录自己开始难以理解的点。
一维dp数组的递推公式和遍历顺序:
for(int i = 0; i < weight.size(); i++) { // 遍历物品
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量,注意是>=weight[i],装不下的物品[i]的时候也没必要继续遍历了
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);// 递推公式
}
}
1、为什么遍历背包时要倒序遍历?
答:倒序遍历是为了保证物品i只会被放入一次背包。如果使用正序遍历,物品会被重复加入很多次。
卡哥举的例子:
物品0的重量weight[0] = 1,价值value[0] = 15
如果正序遍历
dp[1] = dp[1 - weight[0]] + value[0] = 15
dp[2] = dp[2 - weight[0]] + value[0] = 30
此时dp[2]就已经是30了,意味着物品0,被放入了两次,所以不能正序遍历。
为什么倒序遍历,就可以保证物品只放入一次呢?
倒序就是先算dp[2]
dp[2] = dp[2 - weight[0]] + value[0] = 15 (dp数组已经都初始化为0)
dp[1] = dp[1 - weight[0]] + value[0] = 15
所以从后往前循环,每次取得状态不会和之前取得状态重合,这样每种物品就只取一次了。
如例子中所说,计算dp[2]的时候叠加了dp[1]的数值,而dp[1]的情况也是将物品0放入了,相当于dp[2]放入了两个物品0,不满足01背包问题每个物体只能有一个的要求。
背包正序遍历的情况,对应的是完全背包问题,这是后续要学习的。
2、两个for循环的顺序为什么不能反过来(先背包后物品)?
答:如果遍历背包放在上一层,那么每个dp[j]中只会放入一个物品,即背包中一直都是只放入一个物品。
这个点一开始很难理解,画了推导图以后才终于明白了。
还是以该数据为例:
背包最大容量为4,问背包能放进的最大价值是多少。
首先,01背包的以为数组背包的遍历顺序需要从后往前(为了避免重复装同一个物品),先遍历背包后遍历物品的代码如下:
for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
for(int i = 0; i < weight.size(); i++) { // 遍历物品
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);// 递推公式
}
}
dp[0] = 0,因为背包容量为0时所能装的最大价值为0。
dp数组其余的值初始化都为0,因为这样能让dp数组在递归公式的过程中取得最大的价值,而不是被初始值覆盖了。
对于背包容量j=4:
i=0,dp[4] = max(dp[4], dp[4 - 1] + 15) = max(0, 15) = 15
i=1,dp[4] = max(dp[4], dp[4 - 3] + 20) = max(15, 0 + 20) = 20
i=2,dp[4] = max(dp[4], dp[4 - 4] + 30) = max(20, 0 + 30) = 30
遍历完物品,最后得到的dp[4]为30,但正确的值是35。
从计算过程中可以看出:
第一次更新dp[4]的值,只放入了物品0。
第二次更新dp[4]的值,只放入了物品1。
第三次更新dp[4]的值,只放入了物品2。
同理,对于背包容量j=3:(j >= weight[i],物品2的重量为4,j不遍历)
i=0,dp[3] = max(dp[3], dp[3 - 1] + 15) = max(0, 15) = 15
i=1,dp[3] = max(dp[3], dp[3 - 3] + 20) = max(15, 0 + 20) = 20
也就是:
第一次更新dp[3]的值,只放入了物品0。
第二次更新dp[3]的值,只放入了物品1。
对于背包容量j=2:
i=0,dp[2] = max(dp[2], dp[2 - 1] + 15) = max(0, 15) = 15
即:
第一次更新dp[2]的值,只放入了物品0。
对于背包容量j=1:
i=0,dp[1] = max(dp[1], dp[1 - 1] + 15) = max(0, 15) = 15
即:
第一次更新dp[1]的值,只放入了物品0。
上面的推导已经显示了,最终得出的dp数组的每一个值,都是放入一个物品得出的结果。
(虽然从dp[3]开始和正确答案一样,但只是数据凑巧罢了)
出现这样结果的原因是什么呢?
因为对于固定的背包容量j,每一个物品i计算dp[j]的过程中,因为max()中的第二项dp[j - wi]一定是在dp[j]前面的,而dp[j]前面的都还是初始值0,因此递推公式是: dp[j] = max(dp[j], value[i]),也就是说,本质上是在求能遍历到的单个物品(能装下的单个物品)的历史最大值,最后dp数组的值也就为单个物品的价值。
再往深了看,是因为每次处理一件新物品时,没有利用到前面物品的信息。
对于背包容量j=4:
i=0,dp[4] = max(dp[4], dp[4 - 1] + 15) = max(0, 15) = 15
i=1,dp[4] = max(dp[4], dp[4 - 3] + 20) = max(15, 0 + 20) = 20
i=2,dp[4] = max(dp[4], dp[4 - 4] + 30) = max(20, 0 + 30) = 30
dp[4 - 1]、dp[4 - 3]、dp[4 - 4]也就是dp[3]、dp[1]、dp[0]这些都是尚未计算过的前面物品的信息。
而正确用到前面物品的信息应该是:先遍历物品后遍历背包,在遍历每一个物品时,都有一个对应的dp[4]、dp[3]、dp[2]…随着物品遍历的不断进行,dp[4]、dp[3]、dp[2]…不断和自身作比较进行更新,最后得到的结果才是正确的。
(画图比较麻烦,直接看草稿纸吧)

最后,感谢大嗑学家ZYX同学的博客:DAY45:动态规划(六)背包问题优化:一维DP解决01背包问题。对于许多难理解的地方他都做了很好的解答,图片也十分通俗易懂,感谢!
三、416.分割等和子集
题目链接:
想明白01背包一维数组的问题,这题就相当容易了。把数组和的一半看成背包的容量,如果从数组中能有子集把背包全都装满,就是true,否则false。数组中的数字既是重量,又是价值。
代码如下:
class Solution {
public:
bool canPartition(vector<int>& nums) {
int sum = 0;
vector<int> dp(10001,0); // 题中说总和不会大于20000,背包最大只需要其中一般,所以大小10001就可以了
for (int i = 0; i < nums.size(); i++) {
sum += nums[i];
}
if (sum % 2 == 1) return false;
int target = sum / 2;
for (int i = 0; i < nums.size(); i++) {
for (int j = target; j >= nums[i]; j--) {
dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
}
}
if (dp[target] == target) return true;
else return false;
}
};