存内计算路线再获加持,清华存内芯片登Science
2023年9月14日,清华大学吴华强及高滨共同通讯在Science在线发表题为“Edge learning using a fully integrated neuro-inspired memristor chip”的研究论文,论文显示,团队基于存内计算范式,研制出全系统集成、支持高效片上学习(机器学习能在硬件端直接完成)的存内计算芯片。
针对AI时代的新技术的方向,基于存储器运行计算的新型架构模式,进一步被验证。
一,存算一体:继CPU、GPU架构之后的算力架构“第三极”
清华最新芯片成果,登上Science!它集合了记忆、计算和学习能力,能在片上快速完成不同任务的模型训练。而能耗仅为先进工艺下ASIC的1/35,能效有望提升75倍,同时兼顾保护隐私。
存内计算(CIM)技术, 是存算一体技术的一个分支。它指的是在芯片设计过程中,不再区分存储单元和计算单元,将计算单元融合进存储单元,设计出存算一体单元,从而真正实现“存”与“算”的融合。存内计算是计算新范式的研究热点,其本质是利用不同存储介质的物理特性,对存储电路进行重新设计使其同时具备计算和存储能力,直接消除“存”与“算”的界限,使计算能效达到数量级提升的目标。存内计算最典型的场景是为 AI算法提供向量矩阵乘的算子加速,目前已在神经网络领域开展大量研究,如卷积神经网络(Convolutional Neural Network ,CNN)等。清华存内计算芯片主要为模拟存算,可基于物理定律(欧姆定律和基尔霍夫定律)在存算阵列上实现乘加计算。

图 1 存内计算概念图(TU DELFT-prophese)[1]
存内计算优势:
1)具有更大算力(1000TOPS 以上);
2)更低功耗(相比传统架构降低1000倍);
3)更高能效(超过 10-100TOPS/W)),超越传统 ASIC 算力芯片;
4)降本增效(可超过一个数量级)。
二,存内计算存储器件
论文中提到“可重构的忆阻器存算一体架构图”,我们都能明确从该文章中得知,清华大学所说的忆阻器是阻变存储器RRAM(Resistive Random Access Memory)。存算一体芯片采用的存算单元包含不同种器件,不同种器件适合的结构与实现效果有所不同,通常分为易失型存储器件(VM)与非易失型存储器件(NVM),清华大学采取的方案是NVM中的忆阻器。忆阻器是一种极具潜力的新型非易失型存储器件,其基本存储单元为金属-绝缘体-金属或者金属-绝缘体-半导体的三明治结构。如下图所示,上下为电极层,中间为绝缘的电阻转变层。通过在电极层施加电压/电流,电阻转变层的电阻值可以实现高阻态和低阻态的切换,每种组态对应1或者0,这样就可以存储器信息。且电阻转变层可以实现多级电阻状态,使其可存储多比特信息,这种电阻状态改变是非破坏性的的,即断电后也不会改变,这也是RRAM具有非易失性的原因。
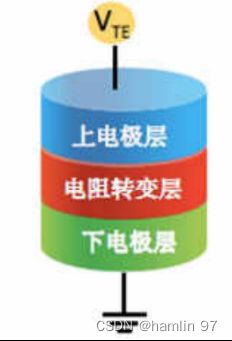
图 2 忆阻器结构示意图[2]
基于忆阻器的存内计算芯片具有制备简单、工艺成本低、时延低、支持多比特存储、兼容先进工艺、支持3D堆叠等诸多优点,被普遍认为拥有广阔的发展前景。当前业界主要利用忆阻器的模拟多比特特性进行模拟存内计算,可以达到较高的计算能效。然而,忆阻器目前在器件一致性和准确性等指标方面还有继续提高的空间。
存算一体采用不同介质的实现效果和关键点也不同,前沿研究更多偏向于技术成熟的易失型存储器件SRAM来探索和设计存算一体架构,但SRAM存在瓶颈,较大的单元面积会导致随着工艺发展,CMOS扩展难度会相应增大,芯片计算密度增长会逐渐放缓;相比之下非易失性存储器(NVM)在计算密度方面表现出更大的潜力,当今市场已有RRAM、PCM、MRAM、NOR Flash等非易失性存储器(NVM)落地应用,而其中NOR Flash存储介质在随机访问、易于集成、非易失性、读取速度、成本效益、灵活性和可靠性等方面具有显著优势。这使得它们在许多应用场景中,如嵌入式系统、微控制器、固件存储和实时操作系统等,成为理想的存储解决方案,目前已有知存科技等公司实现基于NOR Flash的存算一体AI推理芯片,可聚焦边缘计算领域。
如下表所示,我们列出了多种存内计算存储器件的相关信息。
表1 存内计算器件对比分析(中国移动研究院-存算一体白皮书)

三.清华忆阻器存算一体芯片研究介绍
前面我们已经讲述了存算一体的概念和存内计算存储器件,特别是对忆阻器这一新型存储器件有了较为专业的讲解,下面我们会重点介绍清华大学的忆阻器存算一体芯片研究成果。
1.忆阻器阵列
首先将从忆阻器阵列介绍出发,来描述忆阻器存内计算阵列如何实现在数据写入的同时完成计算。
忆阻器电路可以做成阵列结构,如下图3,与矩阵形状类似,利用其矩阵运算能力,可以广泛应用于AI推理场景中。在AI推理过程中,通过输入矢量与模型的参数(也即权重)矩阵完成乘加运算,便可以得到推理结果。

图 3 3 X 3交叉阵列的模拟型忆阻器
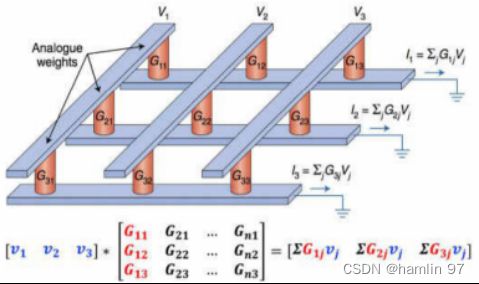
图 4 交叉阵列进行矩阵乘法运算示意图[4]
以矩阵乘加运算为例,如图4所示,将模型的输入数据设为矩阵[V],模型的参数设为矩阵[G],运算后的输出数据设为矩阵[I]。运算前,先将模型参数矩阵按行列位置存入忆阻器(即[G]),在输入端给定不同电压值来表示输入矢量(即[V]),根据欧姆定律(电流=电压/电阻),便可在输出端得到对应的电流矢量,再根据基尔霍夫定律将电流相加,即得到输出结果(即[I])。同时多个存算阵列并行,便可完成多个矩阵乘加计算。
由于整个运算过程无需再从存储器中反复读取大量模型参数,绕开了冯·诺依曼架构的瓶颈,能效比得到显著提升。除忆阻器外,其他存储介质也可通过不同的物理机制满足同样的并行计算需求。
2.清华忆阻器早期研究
清华大学钱鹤、吴华强研究团队对忆阻器存算一体芯片的研究登上《科学》(Science),而这样重大的研究成果并不是一蹴而就的,清华大学历经11年科研“长征”,才得到如此举世瞩目的科研成果,下面我们将简单介绍清华忆阻器的早期研究。
2009年,吴华强教授回到了其母校清华大学,此后一直从事新型阻变存储器的研究,并且承担了清华大学公共微纳加工平台的建设,一点一滴地将清华大学微纳加工平台建设起来。目前,清华公共微纳加工平台已经达到国际领先水平,为微电子研究工作提供了坚实的软硬件支撑。忆阻器作为一种极具发展潜力的新型存储器件,很快吸引了吴华强教授研究团队的目光。早在2012年,吴华强、钱鹤团队就开始研究用忆阻器来做存储,但是由于忆阻器的材料器件优化和集成工艺不成熟,外面也没有合适的代工厂,团队只能靠自己在实验室里摸索,在一次又一次失败的实验中探索提高器件的一致性和良率。
2014年后,清华大学与中科院微电子所、北京大学等单位合作,制备工艺慢慢提升,优化忆阻器的器件工艺,制备出高性能忆阻器阵列——在2023年提出的最新成果中已应用。具体的设计要点在于材料的选择,忆阻器性能好坏,很大程度上取决于材料的选择与组合,团队在选择材料时,会考虑所选材料未来是否适合产业化、材料的物理参数是否易调控等因素。本着这些原则,团队在常用于忆阻器的二氧化铪材料上,添加了一层界面调控层。这个界面调控层是一种金属氧化层材料,它的氧成分占比,可以根据加工工艺的不同来精确控制。通过这种方法,可以比较有效的控制二氧化铪忆阻层中的微观变化,以及内部的温度和电场,使得器件具有非常优异的电学特性,而且可以在工厂里大规模生产,推动了高性能忆阻器阵列的诞生。

图 5 多个忆阻器阵列芯片协同工作示意图
2017年5月,团队在《自然通讯》(Nature Communications)在线发表了题为 “运用电子突触进行人脸分类”(“Face Classification using Electronic Synapses”)的研究成果,将氧化物忆阻器的集成规模提高了一个数量级,首次实现了基于1024个氧化物忆阻器阵列的类脑计算,忆阻器阵列如下图6所示,这标志着清华大学在忆阻器方面的研究已经取得成果突破[5]。

图 6 1024的忆阻器阵列图
2020年,团队又基于多阵列忆阻器,推出了全球首款基于忆阻器的卷积神经网络(CNN)存算一体芯片,能效高出图形处理器芯片(GPU)两个数量级,研究成果再次刊登在《自然》(nature)上,论文题目为“全硬件实现的忆阻器卷积神经网络”(Fully hardware-implemented memristor convolutional neural network)的研究论文,报道了基于忆阻器阵列芯片卷积网络的完整硬件实现。团队搭建了全硬件构成的完整存算一体系统,如下图7所示,在系统里集成了多个忆阻器阵列,并在该系统上高效运行了卷积神经网络算法,成功验证了图像识别功能,证明了存算一体架构全硬件实现的可行性,并且成功实现了以更小的功耗和更低的硬件成本完成复杂的计算[6]。同年,团队还在 ISSCC上发表了国际首款基于模拟型忆阻器的全系统集成存算一体芯片。

图 7 存算一体系统架构
2021年1月18日,团队又在《自然•通讯》(Nature Communications)上在线发表了题为“面向高效时序信号处理的动态忆阻器储备池计算系统”(Dynamic Memristor-based Reservoir Computing for High-Efficiency Temporal Signal Processing)的研究论文,利用忆阻器固有的动态特性和非线性构建了新型储备池计算系统,在语音识别和混沌信号预测任务上分别实现了极低的错词率和预测误差,结果优于已有的储备池计算系统,能够更高效、更低成本地处理复杂时序任务[7]。
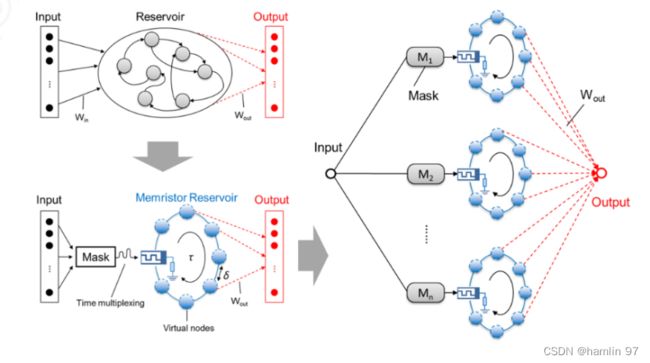
图 8 基于动态忆阻器的并行储备池计算系统示意图
2022年,清华大学集成电路学院钱鹤、吴华强教授课题组联合斯坦福大学、加州大学圣地亚哥分校(UCSD)、圣母大学等在《自然》(Nature)发表了题为“一种基于电阻式忆阻器的内存计算芯片”(A compute-in-memory chip based on resistive random-access memory)的研究论文,报道了一款基于忆阻器的存算一体芯片NeuRRAM。该芯片具有可重新配置的计算核心,可以兼容不同的模型结构,与之前最先进的忆阻器存算一体芯片相比,能效提升两倍,在多种人工智能任务中的推理准确率与四位量化权重的软件模型结果相当[8]。
从忆阻器器件发展不成熟到取得多个重大研究突破的今天,清华大学钱鹤、吴华强研究团队遇到的困难和挫折是不可估量的,他们所付出的努力才换来忆阻器存算一体芯片领域的重大突破,这些早期的研究成果为2023年清华忆阻器存算一体芯片刊登上《科学》(Science)打下基础。
3.清华忆阻器Science[9]
下面我们将简单介绍清华忆阻器Science论文的研究成果。
清华science忆阻器存算方案如下,片上部署两层神经网络,维度为784×100×10,用ReLU作为激活函数(给出的理由是ReLU常见)。以下是方程:
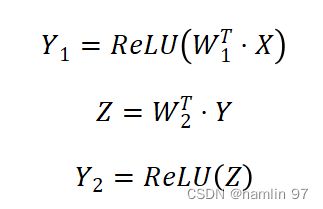
定义平方损失函数,损失函数方式如下:

其中E表示损失向量,T表示目标向量。
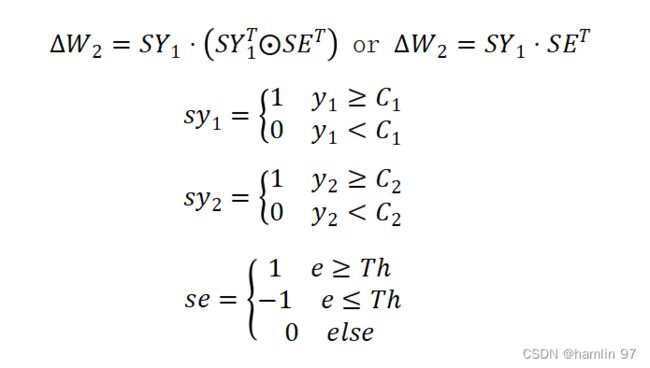
sx表示的是x的符号位,小写的e和y表示E和Y的元素
训练过程中,权重更新根据符号确定,并且权重更新大小是确定的,而不像传统神经网络那样受到步长和该点微分值的而双重影响。这都是为了让训练能够在片上进行而做出的妥协。根据测试,在一般神经网络中权重更新的最后阶段,调整步长非常接近0,如图9(C)所示,为了避免这种较小的se对权重更新的影响,stellar方法引入了阈值Th予以避免。

图 9 stellar更新方案性能展示
实际中的忆阻器电导更新曲线并非理想曲线,具有非线性和不对称性,如图9(A)所示,这是电导本身的特性,不可避免。根据文章中提供的信息,stellar由于引入了阈值Th,在实验测试中可以很好地应对忆阻器更新曲线地不对称性和非线性。在stellar方法与BP方法的对比中,stellar在端应用中均表现出优势,如图9(B)所示,通过引入阈值Th,对于训练准确度受到忆阻器更新曲线非线性和不对称性影响较小,并且准确度非常接近BP方法的基线。
作者也对BP方法引入了更新阈值Th并进行测试,结果如图9(E)所示,引入阈值Th后的影响很小。

图 10 不同训练方式下的性能对比
在stellar方法中,每次只更新2T2R中的一个忆阻器,相比于更新2T2R中的两个忆阻器,可以在达到类似效果的同时减少一半脉冲数,降低对忆阻器耐久性要求。如图10所示,stellar1表示在片上训练中更新2T2R中的一个忆阻器的情况,stellar2表示在片上训练中2T2R中的全部忆阻器的情况,BP w/ verify表示在训练环境下采用BP方法更新的情况。这里采用2T2R的原因在于,电导值和权重不是一一对应的关系,一个权重通过两个电导进行表示,表示方式如下:
对于正权重

对于负权重

清华这篇science所提出的stellar算法提供了一种实现片上训练的新思路,但其服务的模拟器件存算的精度和抗干扰能力较差,目前也只能进行两层神经网络的片上训练,在具体场景中的单独应用面临挑战。并且该方法为了通用性牺牲了神经网络的参数等数据。因此,在端侧具体场景的应用中,应该适时地选择存算范式,在高精度和抗干扰能力的需求下,数字存算可能更为适合。在某些场景下,数模混合运算也可以作为一种解决方案,充分利用两者的优势。例如知存科技推出的WTM2101SOC采用数模混合的存算一体技术,适合于可穿戴设备的智能语音和智慧健康服务。
从市场角度来看,存内计算还是一种比较超前的技术,还在找应用的阶段。目前仅有知存科技一家企业已经公开展开规模化落地以及商业化应用,布局AIoT智能语音、智能健康等低功耗方面的应用,未来将覆盖AI视觉芯片等领域。随着智能城市、智能生态等应用普及,长远地看,将会有更多公司加入存算一体赛道,存算产品的适用范围也可能会延伸至超大算力领域。
参考文献
[1] TU Delft-Prophesee_IMC
[2][4] 存算一体白皮书(2022年),中国移动通信有限公司研究院
[3] 20230414-方正证券-半导体行业专题报告:存算一体,继CPU、GPU架构之后的算力架构“第三极”
[5] Yao, P., Wu, H., Gao, B. et al. Face classification using electronic synapses. Nat Commun 8, 15199 (2017). https://doi.org/10.1038/ncomms15199
[6] Yao, P., Wu, H., Gao, B. et al. Fully hardware-implemented memristor convolutional neural network. Nature 577, 641–646 (2020). https://doi.org/10.1038/s41586-020-1942-4
[7] Zhong, Y., Tang, J., Li, X. et al. Dynamic memristor-based reservoir computing for high-efficiency temporal signal processing. Nat Commun 12, 408 (2021). https://doi.org/10.1038/s41467-020-20692-1
[8] Wan, W., Kubendran, R., Schaefer, C. et al. A compute-in-memory chip based on resistive random-access memory. Nature 608, 504–512 (2022). A compute-in-memory chip based on resistive random-access memory | Nature
[9] Wenbin Zhang et al. ,Edge learning using a fully integrated neuro-inspired memristor chip.Science381,1205-1211(2023).DOI:10.1126/science.ade3483