如何使用 Rosetta Stone 工具统一 Tubi 内容管理系统
作为美国最受欢迎的免费电影电视流媒体服务,Tubi 致力于让人人都能免费观看来自全球的故事。2023 年 11 月,Tubi 的月活跃用户突破了 7400 万,这一成功的基石是优质的内容。
Tubi 内容库有着能满足不同观众群体观看需求的 200,000 部电影和电视剧集,是全球最大的内容库。同时,Tubi 内容库每天都有来自众多第三方来源的更新,其中包含大量丰富的元数据。
如此庞大的内容量为我们有效地管理和理解内容提出了挑战,我们所知最有效的方法是通过统一不同的 ID 空间、将每个元数据与相应的内容进行准确匹配。为了使这种统一变得自动化,我们建立了 Rosetta Stone 系统。
如果你对此类技术博客感兴趣,欢迎订阅 Tubi 技术博客!

Rosetta Stone 是一个灵活的 ID 映射系统
为了保持在行业中的良好势头,Tubi 必须对其过于庞大的内容目录进行恰当的管理和维护。Rosetta Stone 所提供的内容管理方法是通过构建自适应映射能力,使其能够在不同的元数据空间之间无缝过渡。
这一灵活的 ID 映射系统使以下应用成为了可能:
· 统一跟踪和理解
建立一个标准化的 ID 空间对于监控和连接所有内容来说是至关重要的。标准化的 ID 空间是构建 Rosetta Stone 平台领域的基础,同时还影响着平台领域的各个方面,包括内容处理、分析、推荐、合作伙伴支付和全平台运营。
· 处理未识别的信息
我们经常会遇到缺失可识别内容 ID 的内容。在这样的情况下,自动匹配系统尤为重要,特别是在早期的数据清理阶段。由负责人手动查找 ID 既耗时又低效,我们的目标是希望最大限度地减少此类时间的投入,这样员工便可以专注于更有影响力的工作上。
· 资源利用的系统化映射
通过借助元数据、文本描述、图像、评论、人气评级和性能指标等丰富的资源,ID 空间之间的系统化映射使我们能够增强原内容的元数据;这一综合性方法有助于我们更好地理解内容,并优化推荐。
大型语言模型(LLMs)提供了新视角
基于一定的研究与分析,Tubi 选择了利用基于 Embedding 相似性排名的方法来解决 ID 匹配的问题;之前我们也尝试过其他技术方法来解决这些问题,但结果并不理想。
如今,大型语言模型(LLMs)的飞快发展为我们提供了可以有效匹配内容的新方式,并且产生的结果也很好。
LLM 技术将文本映射到统一的语义空间中,增强了跨不同 ID 空间的模糊匹配能力。同时,在分类和识别相似内容风格方面,LLM 技术的表现也很出色,可以通过将不同来源的文本识别为同一内容,弥补缺失的元数据,以准确地定位内容。
作为一个以产品为核心的公司,Tubi 旨在利用 LLMs 构建一套先进的内容元数据 Embedding 空间,以满足不同团队、不同用例的需求。
Rosetta Stone 运行工作流
我们可以通过以下三步了解 Rosetta Stone 运行工作流:
第一,我们创建了一个包含所有相关的内容并且包含 groundtruth ID 的 Embedding 库,下方图片展示了这一问题的组合特性,也是我们在构建集合时需要尤其谨慎的原因。然而,容纳更多的组合可以提高基于相似度分数分析、在有限候选集中进行 ID 最佳匹配的准确性和包容性。
 Rosetta Stone 运行工作流
Rosetta Stone 运行工作流
第二,为了找到当前请求的匹配项 ID,我们根据可用数据创建一个和 Rosetta Stone Embedding DB 中同样 metadata 顺序的结构化字符串,字符用同一个 LLMs 生成对应的 Embedding。
第三,执行 K 近邻算法(KNN),从而在预先存储的 Embedding DB 中检索匹配的内容并按照相似度分数对其进行排序,相似度分数越高匹配正确性越高;并且,我们会一次返回多个匹配结果,以提高查询的召回率。
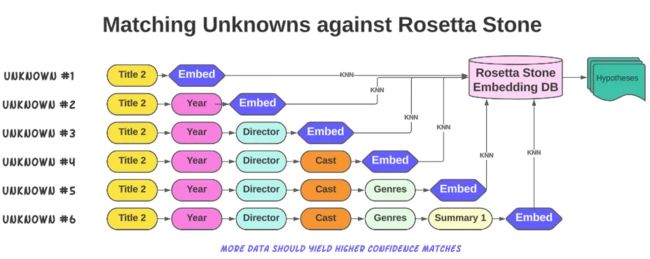 通过 Rosetta Stone 对未知元数据进行匹配
通过 Rosetta Stone 对未知元数据进行匹配
基于由 LLMs 支持的内容识别和匹配系统,我们利用一个对 Tubi 内容库具有非常广泛覆盖的第三方参考数据源(以下简称“参考数据”)作为标准 ID 空间,成功建立了统一的 ID 映射系统。我们还将生成的 ID 与多个内容丰富且广泛使用的第三方内容库的主键 ID 进行了匹配,得到的结果均具有比较高的准确性。
 多个内容空间中 ID 的映射
多个内容空间中 ID 的映射
如何利用 Rosetta Stone 优化 Tubi 内容管理系统
Rosetta Stone 工具在 Tubi 产生了立竿见影的重大影响。最显著的是纠正了内容库中错误的参考数据 ID,对外语片、电影别名等不准确度较高的特定内容尤为有效。
在 Tubi,有几支团队(以及一些后端应用程序)依赖于基于参考 ID 统计数据进行工作。因此,如果参考信息不正确,其在上层应用程序所产生的负面影响面将会扩大。通过纠正参考 ID,我们使内容库变得更加准确和稳健,也使其他团队在使用基于参考的后续统计数据时更有信心。
 利用 Rosetta Stone 匹配第三方数据库
利用 Rosetta Stone 匹配第三方数据库
Tubi 利用 Rosetta Stone 匹配第三方电影资源
Tubi 已完成多个第三方电影和电视节目商业数据库的整合,以补充缺失的信息并增强对内容的描述。虽然我们可以基于严格的匹配条件、将一些第三方结果与 Tubi 现有内容库进行匹配,但仍存在许多第三方结果由于信息不完整而无法匹配的情况;将这些结果直接丢弃无疑是一种资源的浪费。利用 Rosetta Stone,我们从最初无法匹配的第三方来源中检索到了大量结果,极大地补充了我们的内容库信息。
总结
Rosetta Stone 是一个强大的系统,用于管理复杂的内容元数据,我们利用这一系统进一步扩展并丰富内容库,同时为观众提供高度个性化的内容,创造愉悦的观看体验。
感谢
特别感谢 Yuanbo Chen 和 John Trenkle 在撰写本博客方面的巨大贡献,同时,衷心感谢 Tubi 产品团队和机器学习团队在推出 Rosetta Stone 系统方面的紧密合作与不懈努力。最后,感谢机器学习首席技术主管 Clair Dorman 和机器学习技术副总裁 Jaya Kawale 对本博客的审校。
我们正在招聘!
如果你对类似 Rosetta Stone 这样的高影响、大规模项目感兴趣,欢迎加入 Tubi,Tubi 中国团队正在招聘 大数据平台开发 Lead!
作者:Rudra Roy Choudhury,Yuanbo Chen,John Trenkle
译者:Yuanbo Chen
校对:Shengwu Yang
点击此处,查看往期技术博客!