AI PC的引擎 – 英特尔第 14 代处理器Meteor Lake架构分析

英特尔从2023年12月开始在笔记本电脑中发售首款 Meteor Lake 第 14 代 Core Ultra 芯片,开启新的“AI PC”时代。这款芯片采用了全新的架构,将CPU分为四块“瓷砖”(tiles):CPU Tile,SoC Tile,Graphics Tile和I/O Tile,从而降低功耗并提高产量。而图形性能翻倍和新的人工智能引擎有助于满足寻求新功能的消费者。
 Meteor Lake Tiles (图片来源:英特尔公开文档)
Meteor Lake Tiles (图片来源:英特尔公开文档)
传统上,英特尔 CPU 分为封装在一起的两个主要部分:CPU 和平台控制中心 (PCH)。直接媒体接口 (DMI) 总线将两者连接起来。在此方案中,很容易将其视为 CPU 和“其他一切”:I/O、内存等。英特尔在Meteor Lake上采用的tiles则解决了几个问题。首先,每块瓷砖都可以按照自己的路线图单独加工,并按照其所需的制造工艺进行制造。英特尔使用其Foveros 技术将它们连接并堆叠在一起。在 14 纳米制造工艺停滞多年后,英特尔的新计划是通过在四年内以前所未有的速度跨越五种新制造工艺技术,重新获得制造领先地位,并在Meteor Lake上采用了新的制程技术:Intel 4。英特尔的新模块还意味着其逻辑可以智能地相互分离,从而节省电力。每个块都通过提供大约 128GB/s 带宽的结构连接。除此以外,tiles还有一个巨大的次要好处:可制造性。英特尔的Intel 4工艺是第一个使用极紫外(EUV)光刻技术的技术,该技术解决了一个基本问题:英特尔从其光阻硅晶圆上雕刻出的晶体管小于蚀刻过程中使用的光的波长。EUV(需要设备内部的硬真空)被视为迈向 Intel 4 及更高版本的道路。英特尔甚至不自己生产所有的瓷砖。英特尔的 Meteor Lake GPU 模块由台积电采用 5nm N5 工艺制造;SOC模块由台积电采用6nm N6工艺制造,而CPU模块由英特尔采用Intel 4工艺制造。(英特尔没有透露其 I/O 模块的制造商是谁)
 英特尔制程路线图(图片来源:英特尔公开文档)
英特尔制程路线图(图片来源:英特尔公开文档)
接下来,我们详细地看一下Meteor Lake的这四个Tiles。
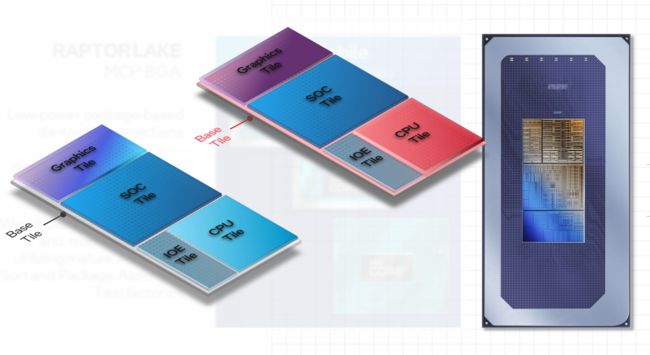 (图片来源:英特尔公开文档)
(图片来源:英特尔公开文档)
CPU Tile
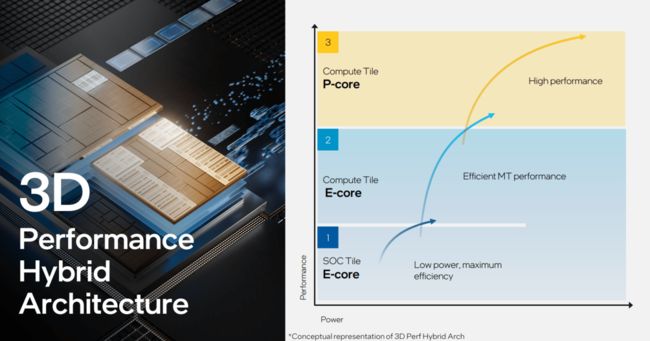
与第 13 代 Raptor Lake 一样,英特尔第 14 代 CPU 模块由两个主要部分组成:性能核心(P 核心)(现称为 Redwood Cove)和代号为Crestmont的新效率核心(E 核心)。我们不太了解 Raptor Lake 的 P 核和 E 核与 Meteor Lake 中的核之间有什么区别。然而,Redwood Cove 确实提供了更高的性能效率和带宽,并具有更大但未公开的二级缓存。
 全新的REDWOOD COVE P核心(图片来源:英特尔公开文档)
全新的REDWOOD COVE P核心(图片来源:英特尔公开文档)
英特尔也没有透露任何有关 Redwood Cove 性能改进的信息。不过,英特尔客户端系统和软件部门的研究员 表示,与 Raptor Lake 相比,Crestmont 的每时钟指令数的性能提升快了 4% 到 6%。(IPC 改进意味着,如果 Raptor Lake 和 Meteor Lake 以相同的速度运行,Meteor Lake 的 Crestmont E 核的运行速度将快 4% 到 6%。)
 全新的CRESTMONT E-核心(图片来源:英特尔公开文档)
全新的CRESTMONT E-核心(图片来源:英特尔公开文档)
SOC Tile:低功耗的E-核心
Meteor Lake 的两个新的低功耗 E 核心包含在 SOC 模块中,就其功能阵列而言,SOC 模块是 Meteor Lake 中最复杂的。虽然 CPU 区块包含 CPU 核心,但 SOC 区块本质上是旧的 PCH,包含 Meteor Lake 的绝大多数辅助功能。在这里,您将找到低功耗 E 核、新的 NPU AI 引擎以及显示引擎、PCI Express 等。为什么要把低功耗E核放在SOC模块中?同样,这是英特尔低功耗计划的一部分:通过将低功耗 E 核心与 CPU 模块分离,这意味着只有 SOC 模块(或其特定部分)需要被唤醒进入活动电源状态。这样可以节省电量,延长笔记本电脑的电池寿命。
 低功耗的E-核心(图片来源:英特尔公开文档)
低功耗的E-核心(图片来源:英特尔公开文档)
低功耗E核呢是一个“新”E-core,是 Gracemont 架构的不同版本。E 核最初是为低功耗任务而设计的。新的低功耗 E 核是为高管们所说的后台“IT 任务”而设计的,但目前尚不清楚这些任务到底是什么。我们也不知道这些新内核的“功耗”有多低。这些“IT 任务”所涉及的一个相当例子是,英特尔使用低功耗 E 核来播放《钢铁之泪》,这是一个被广泛用来测量笔记本电脑电池寿命的开源视频文件。从历史上看,直到 2017 年左右,播放视频都需要整个 CPU 的注意力。从Lakefield 和 Alder Lake,英特尔开始将该任务分配给 E 核和 P 核。仅根据这项任务,笔记本电脑的电池寿命就有显着增加。
 (图片来源:英特尔公开文档)
(图片来源:英特尔公开文档)
在Meteor Lake中,大部分的IT后台工作都可以在低功耗E-核运行(图片来源:英特尔公开文档)
英特尔还大规模改变了 Thread Director,这是 Meteor Lake 中线程或工作负载在内核之间分流的机制。Windows 或 Linux 知道需要做什么并指示 CPU 接管。然后该工作将交给 Thread Director。在Core i9-13900K 上运行的Thread Director 2中,任务首先路由到性能核心,然后在需要时分流到 E 核心。
在 Meteor Lake 中,情况恰恰相反:线程首先分配给低功耗 E 核,然后分配给全功率 E 核,最后分配给 P 核。Thread Director 为任务分配不同的优先级,然后相应地分配任务。(任务的评级不是根据其表现,而是根据其他特征:“0”是“空闲”,“2”是“持续”,“3”是“突发”)。如果低功耗 E 核心完成任务并被释放,即使 P 核心可用,可用线程也会被推送给它。即使在 P 核空闲且英特尔线程控制器针对性能进行了优化(可能通过Windows 电源滑块)的情况下,任务也会首先分配给 低功耗E 核。
 Meteor Lake Thread Director改进(图片来源:英特尔公开文档)
Meteor Lake Thread Director改进(图片来源:英特尔公开文档)
尽管英特尔似乎能够将 Thread Director 作为一项政策进行调整优化,但我们不知道它是否会这样做。比如游戏优化笔记本电脑是否可以主要采用 P 核,并让 Thread Director 首先将线程路由到 P 核?英特尔技术人员评论可以根据游戏的需要调整 Thread Director。尚不完全清楚的是,例如,在低功耗 E 核上启动游戏线程,然后逐步进入 E 核,然后进入 P 核,是否会造成性能损失?
SOC 块也是英特尔所称的 NPU的所在地。2022年,英特尔CEO基辛格确认AI即将登陆Meteor Lake,开启“AI PC时代”,英特尔将出货“数百万”台此类人工智能电脑。顺便说一句,英特尔证实,该 NPU 将出现在所有版本的 Meteor Lake 上。
 SOC Tile架构(图片来源:英特尔公开文档)
SOC Tile架构(图片来源:英特尔公开文档)
英特尔实际上正在开发第三代人工智能:第一代是它于 2016 年从 Movidius 购买的,第二代将独立卡内置到三星 Galaxy Book3 Ultra等一些 PC 中,使这些 PC 能够通过 Windows Studio 进行背景模糊和噪声过滤效果。(虽然 Windows Studio Effects 使用 Movidius 技术,但 Zoom、Teams、Google Meet 和其他工具只需使用 PC 的 CPU 或 GPU。)
英特尔试图做的是将个人电脑定位为未来的人工智能应用,展示了一款 AI 艺术生成器Stable Diffusion ,还演示了音频编辑器 Audacity 的插件,该插件不仅将人声与伴奏乐器分开,而且后来使用文本提示改变了乐器风格。英特尔的目标似乎是齐头并进,加速 WinML、DirectML 等 AI API 及其自有的 OpenVINO 推理引擎。英特尔 SOC 设计总经理 Tim Olson 在一次单独的演讲中表示:“我们的目标是让人工智能平民化。”NPU 就是其中的一部分。英特尔的 NPU 包括一对神经计算引擎,每个引擎内部都有两个 VLIW Shade DSP,推理引擎每个周期最多可处理 8 条指令。即使对于习惯于解析每个芯片的核心数量、基本时钟和涡轮时钟的消费者来说,这也没有多大意义。英特尔试图传达的是,人工智能每个周期需要大量乘法累加 (MAC) 指令,而这些引擎每个可以执行 2,048 次 MAC 计算。
不过,英特尔的秘密武器不仅仅在于 AI NPU,还在于 CPU、GPU 和 NPU 如何相互帮助。以下面的例子为例。英特尔运行了 20 次Stable Diffusion迭代,尝试了各种组合:在 CPU 上执行所有计算、在 GPU 上执行所有计算、在 NPU 上执行所有计算以及三者的组合。在 NPU 上执行所有这些任务需要 20.7 秒,总功耗为 10 瓦,这是最有效的利用。但全部在 GPU和NPU 上执行需要 11.3 秒,消耗 30W。
 Stable Diffusion测试结果(图片来源:英特尔公开文档)
Stable Diffusion测试结果(图片来源:英特尔公开文档)
Graphics Tile
Meteor Lake的 XeLPG 图形模块结合了集成显卡和独立显卡两个市场的元素,更新了过去几年一直内置于 Core 处理器中的 Xe(或 XeLP)集成 GPU。从本质上讲,英特尔正在尽可能地从其独立的 Arc GPU 中汲取灵感,并将其放入集成的 Meteor Lake GPU 中,目标是实现早期 Xe 核心性能的两倍,以及每瓦性能的两倍。英特尔正在提高 XeLPG 的时钟速度,为其投入更多芯片,并提高其效率。英特尔将 Arc A770 的 8 个 Xe 核心以及 8 个光线追踪单元引入 Meteor Lake,这意味着光线追踪现在是基本集成 GPU 的一部分,而不仅仅是一个独立芯片。
 (图片来源:英特尔公开文档)
(图片来源:英特尔公开文档)
Meteor Lake 的 XeLPG 还支持 XeSS,这是英特尔对 Nvidia DLSS 的回应。英特尔的技术以较低的分辨率渲染帧,然后将其超级采样为高分辨率图像。这样可以节省能源并改善图像。Meteor Lake 引入了英特尔所谓的 Endurance Gaming,它将使用英特尔 Arc Control 应用程序进行电源管理。该应用程序直接与英特尔的移动驱动程序对话,调节性能并提高效率;在“常规游戏”模式下,Arc Control 可以为整个系统分配 28W,包括 CPU 和 GPU。在 Endurance Gaming 中,总功耗可以削减至 10W,只为 CPU 提供 1W 功耗。根据英特尔的测试, 《火箭联盟》这款游戏可以在不到1W的功率下以每秒30帧的速度运行。
I/O Tile
I/O Tile包含处理器 PCI-Express 接口的物理层接口,以及 Thunderbolt 和 USB4 等 PCIe 衍生接口。I/O Tile本质上是 SoC 块的扩展。英特尔认为需要单独的 I/O Tile,因为这将允许他们使用不同大小的 I/O Tile来满足不同的处理器型号。演示中的 I/O 模块采用顶级配置,拥有最多的 PCIe 通道、USB4 和 Thunderbolt 接口,英特尔打算在“Meteor Lake”中提供这些接口,不过一些低端 SKU 可能会配置较少的 PCIe 通道,并且缺少 Thunderbolt,使用物理上较小的 I/O Tile。不仅仅是 I/O Tile,还可能存在 P 核数量较少的计算块的变体,从而导致物理块更小。
 I/O Tile(图片来源:英特尔公开文档)
I/O Tile(图片来源:英特尔公开文档)
作者个人Blog(HY's Blog):https://blog.yanghong.dev