基于腾讯云自然语言处理 NLP服务实现文本情感分析

文章目录
-
- 一、前言
- 二、NLP 服务简介
- 三、Python 调用腾讯云 NLP 服务 SDK 构建情感分析处理
-
- 3.1 开通腾讯云 NLP 服务
- 3.2 创建的腾讯云持久证书(如果已创建请跳过)
- 3.2 在腾讯云服务器中安装 Git 工具以及 Python 环境
- 3.3 安装 qcloudapi-sdk-python
- 3.4 部署腾讯云的自然语言处理 NLP 服务
- 四、文末个人总结
一、前言
最近有一个需求,就是分析各种评论内容,之后分析出来特定场景下其评论是否有效,比如我们CSDN最常见的互三,这些互三如何判断,是否很多人发的评论都是类似重复的,今天我们来使用腾讯云的 NPL 服务来做一个语义分析的实践。
本文是基于腾讯云产品:NLP 服务的技术实践,如果你需要更多了该服务,请点击官方链接:点击这里。
二、NLP 服务简介
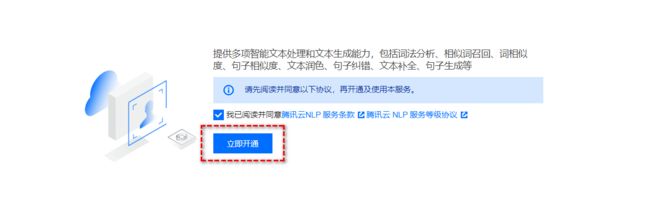
NLP 服务(Natural Language Process,NLP)深度整合了腾讯内部的 NLP 技术,提供多项智能文本处理和文本生成能力,包括词法分析、相似词召回、词相似度、句子相似度、文本润色、句子纠错、文本补全、句子生成等。满足各行业的文本智能需求。
上面介绍了 NPL 服务是什么以及主要的用途,下面介绍一下我们今天使用的腾讯云的 NLP 服务
腾讯云 NLP 服务综合了腾讯内部 NLP 技术,提供全面的智能文本处理和生成功能,包括词法分析、相似词召回、词相似度、句子相似度、文本润色、句子纠错、文本补全、句子生成等。这些功能适用于各行业,能够帮助用户更好理解文本、提高搜索和推荐准确性、评估词语相似度、快速发现文本中的重复或相似句子、优化文本表达、识别并纠正语法、拼写等错误,同时通过自动文本补全和关键句子生成提高创作效率。
三、Python 调用腾讯云 NLP 服务 SDK 构建情感分析处理
3.1 开通腾讯云 NLP 服务
这里我们直接访问限时福利 50000 次免费额度链接进行开通:官方链接点击这里
勾选协议后,点击立即开通按钮。
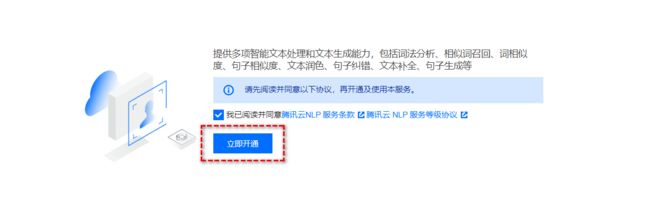
可以看到基础版是 50000 次免费,高级版是 1000 次免费。

3.2 创建的腾讯云持久证书(如果已创建请跳过)
登录腾讯云控制台 点击查看持久证书
链接:https://console.cloud.tencent.com/cam/capi
在提示的各种警告,直接点击蓝色按钮
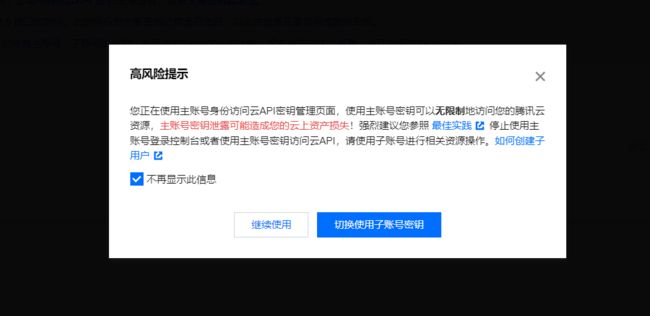
同样点击确定按钮。
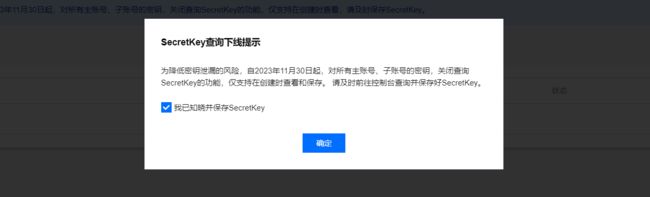
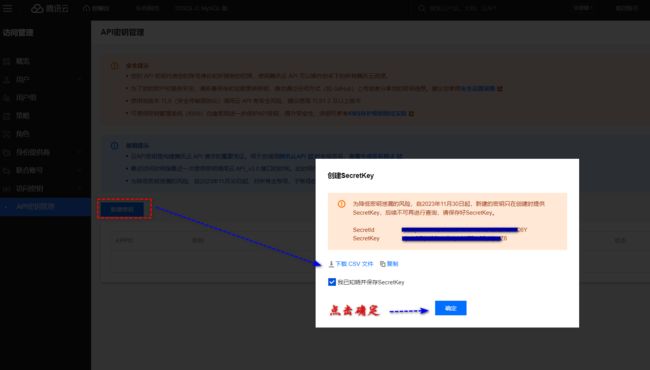
在 API 秘钥管理页面,点击新建秘钥按钮,之后勾选知晓警告后,点击确定按钮,进行创建秘钥。
3.2 在腾讯云服务器中安装 Git 工具以及 Python 环境
购买服务器过程自行略过,不是本文重点。
直接运行如下命令进行安装 Git 以及 Python。
yum install -y git python-pip

等待安装进度,之后出现 Completed 表示安装成功。
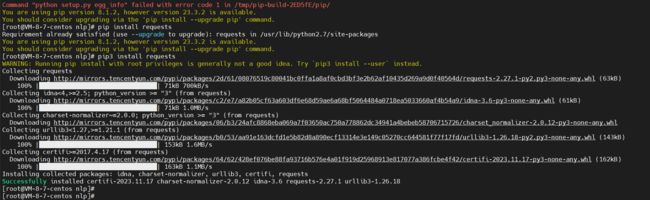
接着我们安装 Python 的 requests 依赖包
pip install requests
或者
pip3 install requests
这里直接使用的 pip3 进行安装的如下图所示
3.3 安装 qcloudapi-sdk-python
直接使用下面的命令进行克隆 qcloudapi-sdk-python
cd /data/nlp/
git clone https://github.com/QcloudApi/qcloudapi-sdk-python
执行过程如下:
[root@VM-8-7-centos ~]# cd /data/nlp/
[root@VM-8-7-centos nlp]#
[root@VM-8-7-centos nlp]# git clone https://github.com/QcloudApi/qcloudapi-sdk-python
Cloning into 'qcloudapi-sdk-python'...
remote: Enumerating objects: 813, done.
remote: Total 813 (delta 0), reused 0 (delta 0), pack-reused 813
Receiving objects: 100% (813/813), 122.81 KiB | 0 bytes/s, done.
Resolving deltas: 100% (476/476), done.
[root@VM-8-7-centos nlp]# ll
total 4
drwxr-xr-x 5 root root 4096 Jan 31 21:51 qcloudapi-sdk-python

3.4 部署腾讯云的自然语言处理 NLP 服务
在 /data/nlp/qcloudapi-sdk-python 下创建 wenzhi.py 文件,代码内容如下,将 SecretId 和 SecretKey 字段修改为 3.2 所创建的对应取值
Python 代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from QcloudApi.qcloudapi import QcloudApi
module = 'wenzhi'
'''
action 对应接口的接口名,请参考wiki文档上对应接口的接口名
'''
action = 'TextSentiment'
config = {
'secretId': '之前取得的 secretId',
'secretKey': '之前取得的 secretKey',
'Region': 'gz',
'method': 'POST'
}
'''
params 请求参数,请参考wiki文档上对应接口的说明
'''
params = {"content": "大A股挺住啊,加油!不能再跌了!"}
try:
service = QcloudApi(module, config)
# 生成请求的URL,不发起请求
print service.generateUrl(action, params)
# 调用接口,发起请求
print service.call(action, params)
except Exception, e:
print 'exception:', e
上述的代码调用的相关参照如下:

执行以下命令,就可以得到对 “大A股挺住啊,加油!不能再跌了!” 这句话的情感分析结果。
cd /data/qcloudapi-sdk-python
python wenzhi.py
得到类似如下的结果, 证明调用成功。
{"code":0,"message":"","codeDesc":"Success","positive":0.99481022357941,"negative":0.0051898001693189}
上面的各字段的含义如下:
positive 正面情感概率
negative 负面情感概率
code 0表示成功,非0表示失败
message 失败时候的错误信息,成功则无该字段
如果你想要更多相关接口和文档, 请访问 NLP服务 获取更多信息。
四、文末个人总结
和很多服务类似腾讯云的 NLP 服务同样有自己的 API 调用,并且部署调试过程也比较简单,如果有类似的需求,你可以直接参看上述的实例中进行操作。
以自身的经历及经验来讲,实际上腾讯云的 NLP服务可以在多个领域进行应用,比如:银行、保险、证券、政务等领域,经常有大量的文档需要投入人力进行整理、提炼和归档,可以使用腾讯云 NLP 的关键词提取和文本分类接口,快捷、高效地完成结构化抽取,有效辅助人工,降低人力参与成本。这无疑是非常符合当代企业的降本增效主题。希望本篇文章对你有所帮助。