HiveSQL题——array_contains函数
目录
一、原创文章被引用次数
0 问题描述
1 数据准备
2 数据分析
编辑
3 小结
二、学生退费人数
0 问题描述
1 数据准备
2 数据分析
3 小结
一、原创文章被引用次数
0 问题描述
求原创文章被引用的次数,注意本题不能用关联的形式求解。
1 数据准备
id表示文章id,oid引用的文章,当oid为0时表示当前文章为原创文章。
create table if not exists table18
(
id int comment '文章id',
oid int comment '引用的其他文章id'
) comment '文章信息表';
insert overwrite table table18 values
(1,0),
(2,0),
(3,1),
(4,1),
(5,2),
(6,0),
(7,3);2 数据分析
题目要求的是原创文章被引用的次数,其中原创文章为oid等于0的文章,即文章id为【1,2,6】被引用的次数。常见的思路是用关联方式求解,具体SQL如下图所示:
思路一:用左连接 left join
--思路一:用左连接 left join
select
t1.id,
count(t2.oid) as cnt
from (select * from table18 where oid = 0) t1
left join
(select * from table18 where oid <> 0) t2
on t1.id = t2.oid
group by t1.id
order by t1.id; 输出结果为: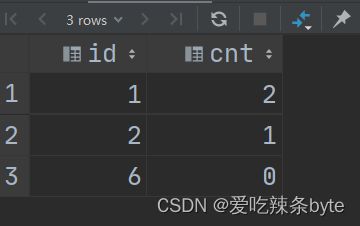
题意要求不能使用join等关联形式求解,其实该题本质是存在性计数问题。
思路二:借助array_contains(array,column) 函数
select
new_id,
sum(flag)as cnt
from (
select
id,
oid,
contains,
-- 第二步:利用array_contains()函数判断引用的oid是否在原创文章id集合中,ture则记为1,false则记为0
if(array_contains(contains, oid), 1, 0) flag,
-- 第三步:清洗数据,补充完整的原创文章
if(array_contains(contains, oid), oid, if(oid = 0, id, null)) new_id
from ( -- 第一步:构建原创文章id集合,作为辅助列
select
id,
oid,
collect_set(if(oid = 0, id, null)) over () contains
from table18
) tmp1
) tmp2
where new_id is not null
group by new_id;上述代码解析:通过array_contains(array,column) 函数进行存在性检测,如果array中包含column 则记为1,不存在记为0,关键公式: sum(if(array_contains(array,column),1,0))

上述代码解析:
第一步:构建原创文章id集合contains,j将contains作为辅助列。
select
id,
oid,
collect_set(if(oid = 0, id, null)) over () contains
from table18;第二步:利用array_contains()函数,判断非原创的oid是否在原创文章id集合中,存在则计数为1,否则计数为0。
select
id,
oid,
contains,
if(array_contains(contains, oid), 1, 0) as flag
from (
select
id,
oid,
collect_set(if(oid = 0, id, null)) over () contains
from table18
) tmp1;
第三步:清洗数据,对原创文章id补充完整
select
id,
oid,
contains,
if(array_contains(contains, oid), 1, 0) flag,
--清洗数据,对原创文章id补充完整
if(array_contains(contains, oid), oid, if(oid = 0, id, null)) new_id
from (
select
id,
oid,
collect_set(if(oid = 0, id, null)) over () contains
from table18
) tmp1;

ps: 此处需要对原创文章id补充完整,否则会丢失记录。具体是:通过array_contains(contains,oid)去判断,代码为 if(array_contains(contains, oid), oid, if(oid = 0, id, null)) as new_id --> 代表的意思是 :如果oid存在于原创文章id构建的集合中,就取得该oid,如果不存在,再判断oid是否为0,如果是0,则取得id,否则记为null。
第四步:将new_id 为null的数据滤掉,并对new_id分组,求出各原创文章被引用的次数sum(flag)as cnt
select
new_id,
sum(flag)as cnt
from (
select
id,
oid,
contains,
-- 第二步:利用array_contains()函数判断引用的oid是否在原创文章id集合中,ture则记为1,false则记为0
if(array_contains(contains, oid), 1, 0) flag,
-- 第三步:清洗数据,补充完整的原创文章id
if(array_contains(contains, oid), oid, if(oid = 0, id, null)) new_id
from ( -- 第一步:构建原创文章id集合,作为辅助列
select
id,
oid,
collect_set(if(oid = 0, id, null)) over () contains
from table18
) tmp1
) tmp2
-- 第四步:将为null的数值过滤掉,并对new_id分组,求出各原创文章被引用的次数sum(flag)as cnt
where new_id is not null
group by new_id;
3 小结
上述例子中利用array_contains(array,column)进行存在性检测,如果存在则记为1,不存在则记为0,核心计算公式为 sum(if(array_contains(array,value),1,0))
二、学生退费人数
0 问题描述
求截止当前月的学生退费总人数【退费人数:上月存在,这月不存在的学生个数】。
1 数据准备
create table if not exists test19( dt string comment '日期',
stu_id string comment '学生id');
insert overwrite table test19
values ('2020-01-02','1001'),
('2020-01-02','1002'),
('2020-02-02','1001'),
('2020-02-02','1002'),
('2020-02-02','1003'),
('2020-02-02','1004'),
('2020-03-02','1001'),
('2020-03-02','1002'),
('2020-04-02','1005'),
('2020-05-02','1006');
2 数据分析
完整的代码如下:
select month
,sum(lag_month_cnt) over(order by month)
from(
select month
,lag(next_month_cnt,1,0) over(order by month) as lag_month_cnt
from(
select distinct t0.month as month
,sum(if(!array_contains(t1.lead_stu_id_arr,t0.stu_id),1,0)) over(partition by t0.month) as next_month_cnt
from
(select
date_format(dt,'yyyy-MM') as month,
stu_id
from test19) t0
left join
(
select month,
lead(stu_id_arr,1) over(order by month) as lead_stu_id_arr
from(
select date_format(dt,'yyyy-MM') as month,
collect_list(stu_id) as stu_id_arr
from test19
group by date_format(dt,'yyyy-MM')
) tmp1
) t1
on t0.month = t1.month
) tmp2
) tmp3;第一步:聚合每个月的stu_id,合并利用collect_list()函数(不去重),具体sql如下:
select date_format(dt,'yyyy-MM') as month,
collect_list(stu_id) as stu_id_arr
from test19
group by date_format(dt,'yyyy-MM') 计算结果如下:
2020-01 [1001,1002]
2020-02 [1001,1002,1003,1004]
2020-03 [1001,1002]
2020-04 [1005]
2020-05 [1006]
第二步:按照月份排序,获取下一月合并之后的值,sql如下:
select month,
stu_id_arr,
lead(stu_id_arr,1) over(order by month) as lead_stu_id_arr
from(
select
date_format(dt,'yyyy-MM') as month,
collect_list(stu_id) as stu_id_arr
from test19
group by date_format(dt,'yyyy-MM')
) tmp1;计算结果如下:
2020-01 [1001,1002] [1001,1002,1003,1004]
2020-02 [1001,1002,1003,1004] [1001,1002]
2020-03 [1001,1002] [1005]
2020-04 [1005] [1006]
2020-05 [1006] NULL
ps:总体思路是利用数组差集函数求出差值集合后,再利用size()求出具体的个数,最后再sum集合即可。hive中的数组函数array_contains可以实现这个需求,该函数表示在数组中查询某个元素是否存在。在该题目中,借助此函数判断当月某个学生id是否在下月(数据集合 -->数组)中存在,如果存在就为0,不存在标记为1。
第三步:利用步骤2的结果与原表进行关联,获取当前学生id
select
t0.*,
t1.*
from (select
date_format(dt, 'yyyy-MM') as month,
stu_id
from test19) t0
left join ( select
month,
lead(stu_id_arr, 1) over (order by month) as lead_stu_id_arr
from ( select
date_format(dt, 'yyyy-MM') as month,
collect_list(stu_id) as stu_id_arr
from test19
group by date_format(dt, 'yyyy-MM')
) tmp1
) t1
on t0.month = t1.month;结果如下:
2020-01 1001 2020-01 [1001,1002,1003,1004]
2020-01 1002 2020-01 [1001,1002,1003,1004]
2020-02 1001 2020-02 [1001,1002]
2020-02 1002 2020-02 [1001,1002]
2020-02 1003 2020-02 [1001,1002]
2020-02 1004 2020-02 [1001,1002]
2020-03 1001 2020-03 [1005]
2020-03 1002 2020-03 [1005]
2020-04 1005 2020-04 [1006]
2020-05 1006 2020-05 NULL
第四步:利用array_contains()函数判断当月的stu_id是否在下个月array数组中,如果存在标记0,不存在标记1。具体sql如下:
select t0.month,
to.stu_id,
if(!array_contains(t1.lead_stu_id_arr,t0.stu_id),1,0) as flag
from
(select
date_format(dt,'yyyy-MM') as month,
stu_id
from test19) t0
left join
(
select month,
lead(stu_id_arr,1) over(order by month) as lead_stu_id_arr
from(
select date_format(dt,'yyyy-MM') as month,
collect_list(stu_id) as stu_id_arr
from test19
group by date_format(dt,'yyyy-MM')
) tmp1
) t1
on t0.month = t1.month
结果如下:
2020-01 1001 0
2020-01 1002 0
2020-02 1001 0
2020-02 1002 0
2020-02 1003 1
2020-02 1004 1
2020-03 1001 1
2020-03 1002 1
2020-04 1005 1
2020-05 1006 1
第五步:基于步骤四的结果,按照月份分组,对flag求和,得到下个月的学生退费人数
select distinct t0.month,
sum(if(!array_contains(t1.lead_stu_id_arr,t0.stu_id),1,0)) over(partition by t0.month) as next_month_cnt
from (select
date_format(dt,'yyyy-MM') as month,
stu_id
from test19) t0
left join
( select month,
lead(stu_id_arr,1) over(order by month) as lead_stu_id_arr
from( select
date_format(dt,'yyyy-MM') as month,
collect_list(stu_id) as stu_id_arr
from test19
group by date_format(dt,'yyyy-MM')
) tmp1
) t1
on t0.month = t1.month;计算结果如下:
2020-01 0
2020-02 2
2020-03 2
2020-04 1
第六步:计算截至当前月的退费人数
步骤五计算的是下一个月的学生退费人数,需要计算截止到当月的退费人数,因此需要借助sum()over聚合窗口函数。我们先将上个月的退费人数获取到当前行再进一步累加。sql代码如下:
select month,
lag(next_month_cnt,1,0) over(order by month) as lag_month_cnt
from(
select distinct t0.month as month,
sum(if(!array_contains(t1.lead_stu_id_arr,t0.stu_id),1,0)) over(partition by t0.month) as next_month_cnt
from
(select
date_format(dt,'yyyy-MM') as month,
stu_id
from test19) t0
left join
(
select month,
lead(stu_id_arr,1) over(order by month) as lead_stu_id_arr
from(
select date_format(dt,'yyyy-MM') as month,
collect_list(stu_id) as stu_id_arr
from test19
group by date_format(dt,'yyyy-MM')
) tmp1
) t1
on t0.month = t1.month
) tmp2;计算结果如下:
2020-01 0
2020-02 0
2020-03 2
2020-04 2
2020-05 1
最终计算截止当前月的退费人数,sql代码如下:
select month,
sum(lag_month_cnt) over(order by month)
from(
select month,
lag(next_month_cnt,1,0) over(order by month) as lag_month_cnt
from(
select distinct t0.month as month,
sum(if(!array_contains(t1.lead_stu_id_arr,t0.stu_id),1,0)) over(partition by t0.month) as next_month_cnt
from
(select
date_format(dt,'yyyy-MM') as month,
stu_id
from test19) t0
left join
(
select month,
lead(stu_id_arr,1) over(order by month) as lead_stu_id_arr
from(
select date_format(dt,'yyyy-MM') as month,
collect_list(stu_id) as stu_id_arr
from test19
group by date_format(dt,'yyyy-MM')
) tmp1
) t1
on t0.month = t1.month
) tmp2
) tmp3;计算结果为:
2020-01 0
2020-02 0
2020-03 2
2020-04 4
2020-05 5
3 小结
针对存在性问题,一般的求解思路是:1.利用collect_set()或者 collect_list()函数进行聚合,将数据集转换成数据组。2.再利用array_contains()等函数判断集合(数组)中是否存在某元素,针对结果打上标签。3.再根据标签进行之后的分组聚合计算等。
ps:以上文章参考:
https://blog.csdn.net/godlovedaniel/article/details/119388498?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167921970316800184142859%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=167921970316800184142859&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-119388498-null-null.142^v74^control_1,201^v4^add_ask,239^v2^insert_chatgpt&utm_term=%E5%AD%98%E5%9C%A8%E6%80%A7%E9%97%AE%E9%A2%98&spm=1018.2226.3001.4187文章浏览阅读741次。本文对存在性问题进行了探讨和研究,此类问题往往需要对不同的记录做对比分析,我们可以先将符合条件的数据域按照collect_set()或collect_list()函数进行聚合转换成数组,然后获取历史的数据域放入当前行,最后利用hive中数组的相关处理手段进行对比分析。常用的hive数组处理函数如expode()、size()、array()、array_contains()等函数,本题就借助于hive ,array_contains()函数进行存在性问题分析。_sql 求截止当前月退费总人数https://blog.csdn.net/godlovedaniel/article/details/119388498?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167921970316800184142859%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=167921970316800184142859&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-119388498-null-null.142%5Ev74%5Econtrol_1,201%5Ev4%5Eadd_ask,239%5Ev2%5Einsert_chatgpt&utm_term=%E5%AD%98%E5%9C%A8%E6%80%A7%E9%97%AE%E9%A2%98&spm=1018.2226.3001.4187