代码随想录刷题笔记 DAY 18 | 找树左下角的值 No.513 | 路经总和 No.112 | 从中序与后序遍历序列构造二叉树 No.106
Day 18
01. 找树左下角的值(No. 513)
题目链接
代码随想录题解
1.1 题目
给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。
假设二叉树中至少有一个节点。
示例 1:
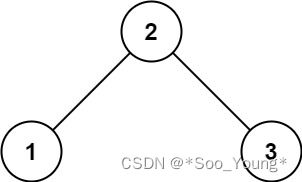
输入: root = [2,1,3]
输出: 1
示例 2:
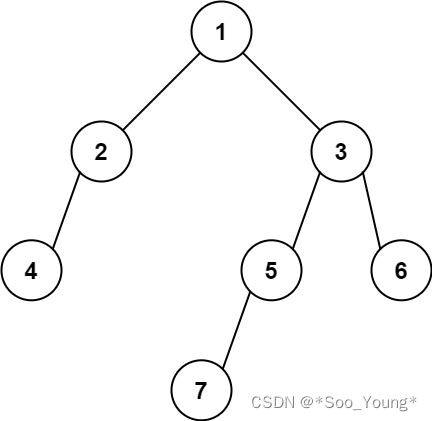
输入: [1,2,3,4,null,5,6,null,null,7]
输出: 7
提示:
- 二叉树的节点个数的范围是
[1,104] -231 <= Node.val <= 231 - 1
1.2 笔记
这道题递归实现很简单,但思路是比较难想到
根据这个题目中的 最底层 可以得到,无论是收集到的上一个节点多么靠左,如果有比它还深的节点,那这个节点更有可能是结果的节点。

比如上图中,无论 1 节点多么靠左,这道题的答案仍然是 6,这也就导致了 最左边的节点不一定是左节点,递归向左的方式就被否定了。
但如果是同层的,因为采用的遍历顺序是 左中右 的顺序,同层的最左边一定是被最先遍历到的,所以对于同层的只需要拿到第一个即可。
这里定义一个类来存放节点的 深度 和 数值
class Node {
int val;
int floor;
public Node(int val, int floor) {
this.val = val;
this.floor = floor;
}
}
1.3 代码
class Solution {
int floor = 0; // 记录当前节点的层数
Node tempNode = new Node(0, 0);
public int findBottomLeftValue(TreeNode root) {
tempNode = new Node(root.val, 1);
reverse(root);
return tempNode.val;
}
public void reverse(TreeNode node) {
if (node == null) {
return;
}
floor++;
// 说明本次遍历到的节点深度更深
if (floor > tempNode.floor) {
tempNode = new Node(node.val, floor);
}
reverse(node.left);
reverse(node.right);
floor--;
}
}
/**
记录可能是结果的节点的深度和值
*/
class Node {
int val;
int floor;
public Node(int val, int floor) {
this.val = val;
this.floor = floor;
}
}
02. 路经总和(No. 112)
题目链接
代码随想录题解
2.1 题目
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
叶子节点 是指没有子节点的节点。
示例 1:

输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
解释:等于目标和的根节点到叶节点路径如上图所示。
示例 2:
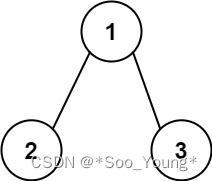
输入:root = [1,2,3], targetSum = 5
输出:false
解释:树中存在两条根节点到叶子节点的路径:
(1 --> 2): 和为 3
(1 --> 3): 和为 4
不存在 sum = 5 的根节点到叶子节点的路径。
示例 3:
输入:root = [], targetSum = 0
输出:false
解释:由于树是空的,所以不存在根节点到叶子节点的路径。
提示:
- 树中节点的数目在范围
[0, 5000]内 -1000 <= Node.val <= 1000-1000 <= targetSum <= 1000
2.2 笔记
是一道非常简单的递归题目,和递归计算深度思路完全相同,但是本题计算的是总和。
但这道题目有一个很大的坑就是在剪枝上,剪枝到最后发现最好的方式是不要加任何剪枝操作
看一下能想到的剪枝的想法
当前总和大于目标值:推翻,因为有可能存在负数当目标值大于 0 时选大于,小于 0 时选小于:推翻,因为节点中可能存在负数
所以本题是无法加入剪枝操作的,对这些边缘处理一定要考虑好。
剩下的就是简单的递归处理了。
为了递归代码尽量的简洁,我将 targetSum 单独的抽离出来作为一个全局变量。
这道题在回顾一下递归要考虑的三个部分
- 递归的出口:
node = null因为对空节点的任何操作都是没有意义的,还有就是叶子节点,在叶子节点直接收集信息然后可以返回,直接返回的话要进行后续位置进行的操作,这里再详细的解释一下,看下面代码中判断叶子节点并且返回的位置,这个位置处于递归的前序位置,但是currentSum -= node.val是处于后序位置的,也就是说后续位置的操作还没有执行就直接返回了;当然,也可以选择不return,递归到下一层发现是空节点返回后同样也会执行后序位置的代码。 - 递归的返回值:因为这里采用外置全局变量的方式,是不需要任何返回值的。
- 递归中要进行的操作:拿取当前路径下的总和、判断是否符合结果的要求,分别向左向右递归,离开节点时删除节点的
val。
2.3 代码
class Solution {
int currentSum = 0; // 记录总和
boolean flg = false;
int target;
public boolean hasPathSum(TreeNode root, int targetSum) {
target = targetSum;
reverse(root);
return flg;
}
public void reverse(TreeNode node) {
if (node == null) {
return;
}
currentSum += node.val;
// 判断是否为叶子节点
if (currentSum == target && node.right == null && node.left == null) {
flg = true;
return;
}
reverse(node.right);
reverse(node.left);
currentSum -= node.val;
}
}
03. 从中序与后序遍历序列构造二叉树(No. 106)
题目链接
代码随想录题解
1.1 题目
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:

输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1]
输出:[-1]
提示:
1 <= inorder.length <= 3000postorder.length == inorder.length-3000 <= inorder[i], postorder[i] <= 3000inorder和postorder都由 不同 的值组成postorder中每一个值都在inorder中inorder保证是树的中序遍历postorder保证是树的后序遍历
1.2 笔记
后序遍历的顺序是 左 右 中
中序遍历的顺序是 左 中 右
先来看一下为什么仅仅通过一个遍历得不到完整的二叉树,而需要两个遍历配合
这就导致了这两种遍历形成的数组是这样的:

后序的最后一个位置的节点一定是中心节点,但是这个节点的左子树和右子树是混合在左边的,再来看中序遍历,虽然它的左右子树是分开的,但是中心节点不得而知,所以需要两个遍历顺序配合来解题。
通过上面的规律,可以总结出一个大概的解题思路:
- 从后序拿到中心节点
- 在中序中找到中心节点
- 分割中序数组,可以得到左子树的所有节点和右子树的所有节点
- 通过分割完成的两个中序数组的长度来切割后序的数组
- 构造当前的节点,也就是后序的最后一个元素
- 以新的中序数组和新的后序数组再次执行上述的步骤,直到只剩下一个节点
这个思路就需要通过递归来完成
简单的画一个图

通过这样逐次的递归,会在后序数组和中序数组长度为 1 的时候就是递归结束的时候,这时候创建节点直接返回即可
再来看每次递归中要做的事情:
- 递归的出口,数组为
null也就是传入数据为空的时候直接返回空;当数组的长度为1的时候,比如上图的9节点,意味着遍历到叶子节点了,这时候也直接返回。 - 递归返回值:因为要构建二叉树,返回的内容是一个节点,使得返回的这个节点树称为上一个节点的子树。
- 每次递归要进行的内容:判断是否符合返回条件、执行上面的六个步骤、返回该节点
3.3 代码
class Solution {
public TreeNode buildTree(int[] inorder, int[] postorder) {
return reverse(inorder, postorder);
}
public TreeNode reverse(int[] inorder, int[] postorder) {
if (postorder.length == 0) {
return null;
}
if (postorder.length == 1) {
// 叶子节点
return new TreeNode(postorder[0]);
}
int target = postorder[postorder.length - 1]; // 拿到节点的值
int index = 0;
for (int i = 0; i < inorder.length; i++) {
if (inorder[i] == target) {
index = i; // 记录切割节点的值
break;
}
}
// 切割中序数组,copyOfRange 为左闭右开
int[] newInorderLeft = Arrays.copyOfRange(inorder, 0, index); // 左
int[] newInorderRight = Arrays.copyOfRange(inorder, index + 1, inorder.length); // 右
// 切割后序数组
int[] newPostorderLeft = Arrays.copyOfRange(postorder, 0, newInorderLeft.length);
int[] newPostorderRight = Arrays.copyOfRange(postorder, newInorderLeft.length, postorder.length-1);
TreeNode node = new TreeNode(target);
node.left = reverse(newInorderLeft, newPostorderLeft);
node.right = reverse(newInorderRight, newPostorderRight);
return node;
3.4 补充
上述的代码中不断的进行数组的切割,会导致时间复杂度很高,这里可以使用逻辑切割,也就是通过传入数组的 startIndex 和 endIndex 来限制数组的空间。
这时候递归的出口就变成了
startIndex == endIndex || startIndex > endIndex
后一个条件是为了处理空的情况,如果带入空值会让数组下标出现负数,可以调试试一下
还需要修改的是下面传入的内容,书写的时候可以把当前的数组写出来,比如起始位置不要写 0 而要写 startIndex,这样可以避免书写条件的时候出错
node.left = reverse(inorderStart, index-1, postorderStart, postorderStart+(index- inorderStart-1));
node.right = reverse(index+1, inorderEnd, postorderStart+(index-inorderStart), postorderEnd-1);
最终写出的条件是这样的,总体的思路和上面的代码相同
class Solution {
int[] globalInorder;
int[] globalPostOrder;
public TreeNode buildTree(int[] inorder, int[] postorder) {
globalInorder = inorder;
globalPostOrder = postorder;
return reverse(0, inorder.length-1, 0, postorder.length-1);
}
public TreeNode reverse(int inorderStart, int inorderEnd, int postorderStart, int postorderEnd) {
if (postorderStart > postorderEnd) {
return null;
}
if (postorderEnd == postorderStart) {
// 叶子节点
return new TreeNode(globalPostOrder[postorderStart]);
}
int target = globalPostOrder[postorderEnd]; // 拿到节点的值
int index = 0;
for (int i = inorderStart; i <= inorderEnd; i++) {
if (globalInorder[i] == target) {
index = i; // 记录切割节点的值,也就是此时的节点
break;
}
}
TreeNode node = new TreeNode(target);
node.left = reverse(inorderStart, index-1, postorderStart, postorderStart+(index-inorderStart-1));
node.right = reverse(index+1, inorderEnd, postorderStart+(index-inorderStart), postorderEnd-1);
return node;
}
}