关于JVM常见的十道面试题
方法区、永久代和元空间有什么区别?
方法区、永久区和元空间是Java虚拟机用于存储类信息的区域,它们在不同的Java虚拟机版本有所不同:
- 方法区:方法去是一块用于存储类的结构信息、常量、静态变量、即时编译器编译后的代码等数据的内存区域。在早期的Java虚拟机版本中,方法区被永久实现为永久代。但是在Java 8及其以后版本中,方法去被移除,取而代之的是元空间
- 永久代:永久代是Java虚拟机中的一个特定的方法区,用于存储类的元数据新消息,如类名、方法名、字段名等。永久代的大小是固定的,并且在默认的情况下比较小。由于永久代的大小是有限的,当加载的类过多或者动态生成的类过多的时候,就容易出现永久代溢出的情况
- 元空间:元空间是Java 8及其以后版本中取代永久代的新方法区实现。元空间并不在虚拟机内存中,而是使用本地内存来存储类的元数据信息。元空间的大小可以根据需要进行调整,并且默认的情况下是不限制大小的。元空间的好处是可以避免永久代的溢出问题,并且可以更好的利用系统资源
所以说,方法区是一个规范层面的概念,而永久代是早期 HotSpot JVM(JVM的实现) 对方法区的具体实现方式,现已废弃;而元空间则是后来 HotSpot 为了改进内存管理,和解决永久代带来的内存溢出问题所采用的新的实现机制
为什么要使用元空间替代永久代?元空间有什么优点?
- 降低内存溢出:当使用永久代实现方法区时,永久代的最大容量受制于 PermSize 和 MaxPermSize 参数设置的大小,而这两个参数的大小又很难确定,因为在程序运行时需要加载多少类是很难估算的,如果这两个参数设置的过小就会频繁的触发FullGC 和导致 OOM(Out of Memory,内存溢出)。但是,当使用元空间替代了永久代之后,出现 00M 的几率就被大大降低了,因为元空间使用的是本地内存,这样元空间的大小就只和本地内存的大小有关了,从而大大降低了OOM 的问题
- 降低运维成本:因为元空间使用的是本地内存,这样就无需运维人员再去专门设置和调整元空间的大小了
常量池和字符串常量池有什么区别?字符串常量池是如何实现的?
常量池和自负床常量池都是Java中用于优化性能和内存使用的机制,但是它们的应用场景和存储内容有所不同:
常量池:是指存储在.class文件中的一组常量的集合,包括字符串常量、数字常量、类和接口的名称以及其他一些常量。常量池是Java中的一种优化机制,用于避免重复存储相同的常量值,从而减小类文件的大小
字符串常量池:也是常量池中的一种,专门用于存储字符串常量的
二者区别如下:
- JDK 1.8之后,字符串常量池存储在堆上,而常量池在元空间本地内存中
- 常量池包含很多的内容,如类、方法、字段你等常量都是存储在常量池中,而字符串常量池只是用于存储字符串常量对象
字符串常量池的实现
自负床常量池是由C++中的HashMap实现的,它的key是字符串的字面量,value是字符串对象的引用
什么叫做堆溢出?实际工作中哪些情况会导致堆溢出?
堆溢出通常是指堆内存中的对象过多,无法被垃圾回收导致的内存溢出出错。以下是常见的导致堆溢出的场景和原因:
- 内存泄露:最常见的情况就是内存泄漏,即对象被创建后不再被使用,但是没有被释放。这会导致之堆中的对象数量逐渐增加,直到堆溢出。例如ThreadLocal使用不当,使用完成之后未调用remove方法导致内存泄漏,以及忘记释放各种连接,也会导致内存泄漏,如数据库连接、网络连接和IO连接等
- 无限递归创建大量对象:无限递归调用一个方法可能会导致栈溢出,但是如果当调用中创建了大量对象并持续递归,也可能导致堆溢出
- 创建大量的大对象:创建大量大对象,尤其是数组或集合,可能导致堆溢出。如果没有足够的连续内存来存储大对象,堆溢出会发生
- 未合理设置堆大小:如果未合理设置 Java 虚拟机的堆大小参数(如 -Xmx 和 -Xms),可能导致堆溢出
- Excel 导入和导出:如果有大的 excel 要进行导入和导出的情况下,因为其操作都是在内存中拼接和组织数据的,如果 excel过大,很容易就会造成堆溢出
什么叫做栈溢出?导致栈溢出的原因是啥?
栈溢出是指在程序运行的时候,当栈空间中可用内存大小被超出所能容纳的大小的时候,导致发成异常或错误。以下是常见的导致栈溢出的场景和原因:
- 递归调用:在递归算法中,如果递归的深度过大,每次递归都会在栈上生成一个函数调用的帧,当栈空间内不足以容纳这些帧的时候,就会发生栈溢出
- 无限递归:在某些情况下,由于代码逻辑错误或循环调用,可能会导致无限递归的情况发生,从而导致栈溢出
- 大规模数据结构使用:当使用大规模的数据结构(如大数组、大集合等)时,如果栈空间不足以容纳这些数据,就会导致栈溢出。解决方法时尽量使用堆空间存储的答案规模数据结构,或者增加栈的大小
- 深度嵌套函数调用:当函数调用过于深度嵌套的时候,每次调用都会在栈中生成一个新的函数帧,如果嵌套层过多,就会导致栈溢出
说一下类加载机制?Loading和Class Loading有什么区别?
类加载机制是Java虚拟机在运行Java程序的时候用来加载文件的过程。类加载机制包括以下几个步骤:
- 加载:将类的字节码文件加载到内存中,并创建一个对应的Class对象,用这个来表示类。加载阶段是通过类加载器来实现的
- 验证:确保加载的类文件符合Java虚拟机的规范不会造成安全问题
- 准备:为类的静态变量分配内存,并初始化为默认值
- 解析:解析阶段是JVM将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程。这个过程会涉及到三个概念:
- 符号引用:类文件中的一个抽象引用方式,它并不涉及具体的内存地址或者对象实例。符号引用包括三方面的信息:类和接口的全限定名、字段的名称和描述符、方法的名称和描述符。这些信息足以唯一的确定一个类、字段或者方法,但是类被加载到JVM之前,并没有实际的内存布局关联
- 直接引用:一种可以直接指向目标对象、类、字或者方法在JVM内存中的物理位置的引用方式。例如:指针、偏移量等。一但是有了直接引用,就可以直接访问目标实体,而无需经过其他的查找过程
- 替换过程:当JVM解析阶段需要对某个符号进行解析的时候,会根据类加载的结果生成对应的直接引用。比如,当一个类引用了另一个类的方法或者字段的时候,解析阶段会确保被引用的目标类已经被加载,并会计算出被饮用方法或字段在内存中的准确位置,然后用这个位置信息替换掉原来的符号引用
- 初始化:执行类初始化代码,包括静态变量的复制和静态代码块的执行。初始化阶段是类加载的最后一步
什么是双亲委派模型?为什么要用双亲委派模型?
双亲委派模型是Java类加载机制的一种设计模式,用于保证类加载的安全性和一致性。在双亲为欸配模型中,类加载器在尝试加载一个类时,会先将加载的请求派给其父类加载器,如果父类加载器无法加载该类(即父类加载器的搜索范围内找不到对应的类),则子类加载器才会尝试加载
自 JDK 1.2 以来,Java 一直保持着三层类加载器、双亲委派的类加载架构器,如下图所示:
- 启动类加载器:加载 JDK 中 lib 目录中 Java 的核心类库,即 $JAVA_HOME/lib 目录。
- 扩展类加载器:加载 lib/ext 目录下的类
- 应用程序类加载器:加载我们写的应用程序
- 自定义类加载器:根据自己的需求定制类加载器
双亲委派模型的主要目的就是确保Java类的安全性和一致性,具体的表现在以下几个方面:
- 防止重复加载:比如A类和B类都有一个父类C类,那么当A启动的时候就会将C类加载起来,那么在B类加载的时候就不需要进行重复加载C类
- 更安全:使用双亲委派模型也可以保证Java的核心API不会被串改,如果没有使用双亲委派模型,而是每个类加载自己的话就会出现一点问题,比如我们编写一个称为java.lang.Object类的话,那么程序运行的时候,系统就会出现多个不同的Object类,而有些Object类又是用户自己提供的因此安全性就不能得到保证
有哪些打破双亲委派模型的场景?为什么要打破双亲委派模型?
打破双亲委派模型的主要场景主要是以下两种:
- Java中自带的SPI机制
- Tomcat
SPI机制:SPI是JDK内置的一种服务提供发现机制。例如,数据库驱动就是SPI的典型实现。在Java中,数据库驱动就是一个典型的SPI使用场景。不同的数据库厂商都提供了自己的数据库驱动实现,这些实现都是实现了同一个JDBC接口。JVM在运行时可以动态加载适合的数据库驱动,使得开发者可以在不修改代码的情况下切换不同的数据库
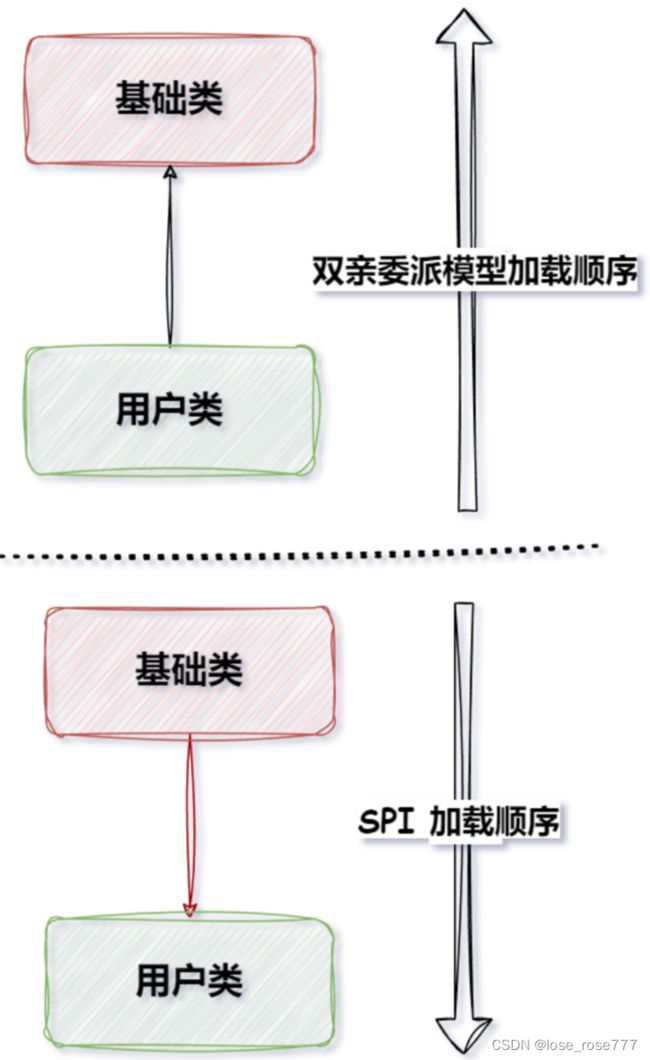
双亲委派模型是从下往上加载,而 SPI机制是从上往下加载
Tomcat:Tomcat 也要打破了双亲委派模型,因为一个外置 Tomcat 中要部署多个应用,多个 Web 应用程序在同一个omcat 实例中独立运行,而不会相互干扰或导致类冲突,所以 Tomcat 需要打破双亲委派模型来实现类隔离、热部署和解决类库版本冲突等问题
- 类隔离:应用服务器通常需要在同一JVM 中运行多个不同的 Web 应用程序,每个应用程序都可能依赖于不同版本的类库。为了保持这些应用程序的隔离性,Tomcat 需要使用自定义的类加载器来加载各个 Web 应用程序的类。这样可以确保每个 Web 应用程序都不会干扰其他应用程序的类加载
- 热部署和热加载:Tomcat 支持热部署和热加载,允许在应用程序运行时替换类文件而不需要重新启动整个应用服务器。为了实现这一功能,Tomcat 需要自己的类加载器,以便能够动态加载新的类定义
- 类库版本冲突:有时 Web 应用程序需要使用自己的类库版本,而不是应用服务器提供的全局类库版本。这可能会导致类库版本冲突,为了解决这个问题,Tomcat 可以使用自定义的类加载器来加载应用程序的类,而不受全局类库的影响
判断死亡对象的算法有哪些?
判断对象是否存活的常见算法主要有以下两种:
- 引用计数算法
- 可达性分析算法
引用计数算法
引用计数器的实现思路是,给对象增加一个引用计数器,没达昂有一个地方引用它时,计数器就+1;当引用失效的时,计数器就-1;任何时刻计数器为0的对象就是不能再被使用的,即对象已死
优点:实现简单,判定效率比较高
缺点:引用计数无法解决对象循环引用的问题
可达性分析算法
可达性分析算法是通过一系列为GC Roots的对象作为起点,从这些接电脑开始向下搜索搜索走过的路径称为引用链,达昂一个对象到GC Roots没有任何的引用链相连时(从GC Roots 到这个对象不可达)时,证明此对象是不可用的,也就是死亡对象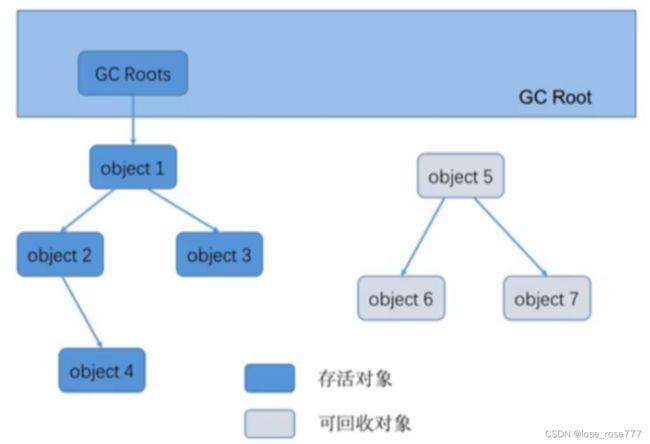
对象 Object5-0bject7 之间虽然彼此还有关联,但是它们到 GC Roots 是不可达的,因此它们会被判定为可回收对象
目前主流的Java虚拟机都是使用可达性分析算法来判断死亡对象的
什么对象可以作为GC Roots?为什么它们能作为GC Roots?
在Java中,可作为GC Roots的对象有以下几种:
- Java虚拟机栈(栈帧中的本地变量表)中引用的对象
- 本地方法栈中(Native方法)引用的对象
- 方法区中的类静态属性引用的对象
- 方法区中常量引用的对象
其中,Java 虚拟机栈和本地方法栈中的引用对象,是目前线程正在执行时用的对象,所以它们不能被回收,因此它们可以作为 GC Roots。而方法区中的静态属性和常量对象与类本身相关联,而类已经被加载到程序中了,所以类属于系统的一部分了,因此类所关联的静态属性和常量也就是系统的一部分了,所以它们可以作为 GC Roots