关于MyBatis和JVM的最常见的十道面试题
ORM项目中类属性名和数据库字段名不一致会导致什么问题?它的解决方案有哪些?
在ORM项目中,如果类的属性名称和数据库字段名不一致会场导致插入、修改时设置的这个不一致字段为null,查询的时候即使数据库有数据,但是查询的结果也是为null。它的常见解决方法如下:
- 更改程序中属性名或数据库的字段名,使其一致
- 使用结果映射,使用
映射对应的字段 -
来进行查询结果的映射:
-
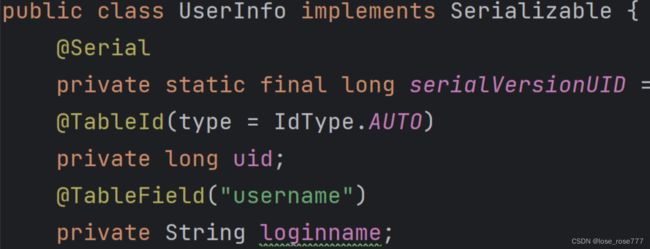
- 使用MyBatis Plus框架中的@TableFild注解映射二者的字段,如下图:
-
- 如果是查询操作 ,可以使用as重命名字段名,这样查询也就不会为null了
MyBatis中如何实现分页?它有几种实现分页的方式?
MyBatis中实现分页主要是一下两种实现方式:
- 物理分页:物理上是使用SQL擦哈寻语句,在数据库引擎层面实现的,如MySQL的LIMIT语法进行分页
- 逻辑分页:逻辑分页时在应用程序层面进行的分页,通常是先查询出所有符合条件的数据,然后在内存中对数据进行分页操作
物理分页
使用limit实现分页
物理分页是可以直接在XML中拼加SQL进行分页:
使用PageHelper插件实现分页
实现代码如下:
PageHelper.startPage(1,10);
//1 表示要查询的页码为第一页,10 表示每页显示的记录数为 10 条
Listlist=userMapper.selectIf(1); PageHelper实现原理分析
PageHelper底层是使用MyBatis的拦截器(Interceptor)机制,在MyBatis进行查询时,拦截并对SQL语句进行动态修改(添加limit等分页查询操作),之后查询数据库、并对查询结果进行包装,包装成分页对象(如包含数据列表、总记录数、总页数等信息的分页对象),最后再将这个分页对象返回给客户端
逻辑分页
MyBatis自带的RowBounds进行分页就是逻辑分页,它的一次性查询很多数据,然后在数据中在进行检索,实现代码如下:
RowBounds rowBounds = new RowBounds(offset, limit);
List users = sqlSession.selectList("getUserList", null, rowBounds);
其中 offset 为起始行偏移量,limit 是每页数据量,虽然设置了这两个值,但在使用 RowBounds 时,它会一次性查询多条数据,然后再在内存中进行 offset 和 limit 的筛选,最后在返回符合结果的数据
MyBaits二级缓存有几种淘汰策略?如何设置缓存淘汰策略?
- LRU-最近最少使用:移除最长时间不被使用的对象
- FIFO-先进先出:按照对象进入缓存的顺序来移除对象
- SOFT-软引用:基于垃圾回收器状态和软引用规则移除对象
- WEAK-弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象
默认的缓存淘汰策略时LRU
可以通过eviction属性来设置淘汰策略,如下:
MyBatisPlus如何实现分页功能?它的底层是如何实现的?
MyBatis-Plus 是 MyBatis 的增强工具,在 MyBatis 的基础上提供了更多方便的功能,包括分页功能。在 MyBatis-Plus 中,实现分页功能非常简单,主要使用 Page 类进行分页操作。
以下是使用 MyBatis-Plus 实现分页功能的基本步骤:
- 在 Mapper 接口中定义查询方法,并接收一个
Page类型的参数,用于分页
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
public interface UserMapper extends BaseMapper {
Page selectUserPage(Page page);
}
- 在 Mapper XML 文件中编写对应的 SQL 查询语句
- 在 Service 层调用 Mapper 中定义的查询方法,并传入一个
Page对象作为参数
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserMapper userMapper;
@Override
public Page selectUserPage(int pageNum, int pageSize) {
Page page = new Page<>(pageNum, pageSize);
return userMapper.selectUserPage(page);
}
}
这样就完成了分页功能的实现。MyBatis-Plus会自动将查询结果封装到Page对象中,其中包含了分页的相关信息,比如当前页码、每页大小、总记录数等
MyBatis-Plus底层是通过拦截器实现分页的,它会在执行SQL语句前进行拦截,并根据传入的分页参数自动生成对应的分页SQL语句,然后执行分页查询。最后将查询结果封装到Page对象中返回给调用方。这样,开发人员不需要手动编写分页的SQL语句,简化了开发流程
MyBatis中使用了哪些设计模式?举例说明一下
- 工厂模式:工厂模式是Java中最常见的设计模式之一。工厂模式就是它提供一个工厂,当有客户需要调用的时候,只调用这个工厂类就可以得到自己想要的结果,从而无需关注某类的具体实现过程。工厂模式在MyBatis中典型的代表就是SqlSessionFactory。SqlSession是MyBatis中的重要而Java接口,可以通过该接口来执行SQL语句,获取映射器示例和管理事务,而SqlSessionFactory正在用来产生SqlSession对象的,所以它在MyBatis中是比较核心的接口
- 建造者模式:建造者模式就是将一个复杂对象的构建与它的表示分离,使得的同样的构建过程可以创建不同的表示。也就是说建造者可以通过多个模块一步一步实现对象的构建,相同的构建过程可以创建不同产品。建造者模式在MyBatis中典型代表就是SqlSessionFactoryBuilder。普通的对象都是通过new关键字直接创建的,但是如果创建对象需要构造参数很多,且不能保证每个参数都是正确的或者不能一次性得到构建所需的所有参数,那么就需要将构建逻辑从对象本身抽离出来,让对象只关注功能,把构建交给构建类,这样就可以简化对象的构建,也可以达到分布构建对象的目的
- 单例模式:单例模式是Java中最简单的设计模式之一,此模式保证某个类在运行期间,只有一个实例对外提供服务,而这类被称为单例类。单例模式在MyBatis中典型的代表就是ErrorContext。ErrorContext是线程级别的单例,每一个线程有一个此对象的单例,用于记录该现成的执行环境的错误信息
- 代理模式:代理模式是指给某个对象提供一个代理对象,并由代理对象控制原对象的调用。代理模式在MyBatis中典型的代表就是MapperProxyFactory。MapperProxyFactory的newInstance()方法就是生成一个具体的代理类来实现某个功能
JVM是如何运行的?
JVM的执行流程如下:
- 程序再执行之前先要把Java代码转换成字节码(class文件),JVM首先需要把字节码通过一定的方式类加载器(ClassLoader)把文件加载到内存中运行时数据区(Runtime Data Area)
- 但是字节码文件是JVM的一套指令集规范,并不能直接交给底层操作系统去执行,因此需要特定的命令解析器,也就是JVM的执行引擎会将字节码翻译成底层系统指令再交由CPU去执行
- 在执行的过程中,也需要调用其他语言接口,如通过调用本地库接口(Native Interface)来实现整个程序的运行
所以整体来看,JVM主要是通过以下四个部分来执行Java程序的:
- 类加载器
- 运行时数据区
- 执行引擎
- 本地库接口
Java是编译性语言还是解释性语言?
编译型语言和解释性语言区别如下:
- 编译性语言:在程序执行之前,先经过编译器的处理,将源代码转换为目标及其可以执行的二进制机器码,然后直接执行。因此编译过程只需要进行一次,生成可执行文件可以重复运行
- 优点:执行效率高
- 缺点:编译时间长跨平台能力有限
- 解释性语言:不需要事先编译成机器码,而是在运行时由解释器江源带哦吗逐行解释执行
- 优点:跨平台性比较好,无需编译
- 缺点:执行效率低,不宜保护源代码
而Java语言既不属于编译性语言也而不属于解释性语言,又不完全属于解释性语言。Java是半编译语言,也叫编译-解释型语言,其执行过程包括编译和解释两个阶段:
- 编译阶段:Java源代码(.Java文件)通过Java编译器编译成字节码文件(.class文件)。字节码是一种中间语言,它具有平台无关性,可以在任何支持Java虚拟机(JVM)平台上运行
- 解释阶段:达昂程序运行时,Java虚拟机会加载字节码,并且对其进行解释或即使编译执行。现代JVM普遍采用JIT技术,会根据代码热点将频繁执行的字节码动态编译成本地机器指令以提高性能
为什么需要将 java 代码编译成字节码(.class)?
Java需要编译成字节码(.class文件)的原因主要是有以下几点:
- 跨平台执行:将Java代码编译成字节码,可以使不同平台下的Java虚拟机(JVM)识别,从而根据平台特性,从而生成不同平台的二进制机器码进行执行,这样就可以实现跨平台执行
- 代码检查:编译器在编译阶段会对代码进行类型检查,确保代码的类型安全性,让我们提前发现一些潜在的错误,例如类型不匹配、缺少方法等问题
- 动态加载和扩展:将Java代码编译成字节码可以动态扩展一些功能,例如Lombok插件的@Getter和@Setter方法就是编译器进行字节码生成的
- 高效执行:字节码是一种中间表示形式,相比于原始的源代码,可以提供更高效的执行和优化。JVM会通过即使编译等技术将字节码转换为机器码,以提高程序的执行速度
- 代码保护:编译后的字节码是一种经过转换的相信那个是,与原始的源代码相比,更难以直接理解。这可以提供一定程度的代码保护,使得源代码的逻辑和实现细节难以被逆向工程或恶意更改
说一下JVM的内存布局?
通常所说的JVM内存布局,通常是指JVM运行时数据区,也就是当字节码被类加载器加载后的执行区域。JVM运行时数据区主要分为以下几个部分:
- 程序计数器:当存储当前线程执行的字节码指令地址,在多线程环境之中,程序计数器用于实现线程切换,保证线程恢复执行时能后继续从正确的位置执行代码
- Java虚拟机栈:用于存储方法调用和局部变量(方法内部定义的变量),在方法调用和返回时,虚拟机栈用于保存方法的调用帧,包括方法的局部变量、操作数栈、方法返回地址等
- 本地方法栈:与薰妮基栈类似,本地方法找用于执行本地方法
- Java堆:JVM中的最大一块内存存储区域,用于存储对象实例,所有对象都在堆中分配内存
- 方法区:用于存储类的元数据信息,包括类的结构、字段、方法、静态变量、常量池等

Java虚拟机规范和Java虚拟机有什么关系
它们是一个JVM规范,以一个是针对规范的实现产品,具体来说:
- Java 虚拟机规范(JVM Specification)是 Sun Microsystems 公司(现为 Oracle 公司)制定的一套详细的文档,它定义了 Java 虚拟机的内部工作原理、结构、指令集、数据类型、内存区域、垃圾收集、类文件格式、加载和执行机制等具体规则,这些规则是 Java 平台实现兼容性和可移植性的基础
- Java 虚拟机(Java Virtual Machine,JVM)则是根据上述规范实现的具体软件系统,它是一个实际运行在物理硬件上的程序,负责装载并执行 Java 字节码。任何符合 Java 虚拟机规范的 JM 都可以正确解释和执行标准的 Java 字节码,从而确保 Java 代码的“一次编写,到处运行”的特性
因此,Java 虚拟机规范与 Java 虚拟机的关系可以理解为规范与实现的关系。规范描述了所有 Java 虚拟机应遵循的标准和约定,而各种不同的 Java 虚拟机则是按照该规范进行设计和实现的具体产品。例如,HotSpot JVM 就是由 Oracle 开发的一款广泛使用的 Java 虚拟机的默认实