微服务、MQ、Redis面试题
一、微服务篇
1.SpringCloud常见组件有哪些?
(考察对SpringCloud的组件基本了解)
SpringCloud包含的组件很多,有很多功能是重复的。其中最常用组件包括:
注册中心组件:Eureka、Nacos等
负载均衡组件:Ribbon
远程调用组件:OpenFeign
网关组件:Zuul、Gateway
服务保护组件:Hystrix、Sentinel
服务配置管理组件:SpringCloudConfig、Nacos
(相互调用用到的组件OpenFeign ,进行管理用到的组件注册中心,涉及负载均衡组件Ribbon,服务要做配置管理用到配置中心的组件,对外提供服务的时候要有一个微服务网关作为入口)
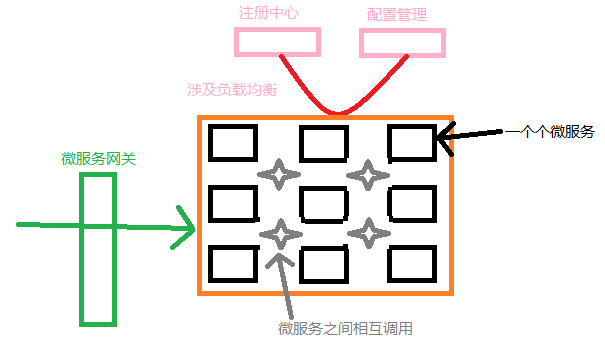
2.Nacos的服务注册表结构是怎样的?
(Nacos的服务注册表结构在后面的位置解释)
(考察对Nacos数据分级结构的了解,以及Nacos源码的掌握情况)
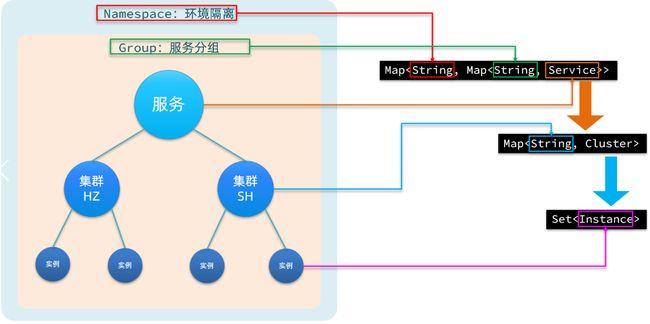
Nacos采用了数据的分级存储模型,最外层是Namespace,用来隔离环境。然后是Group,用来对服务分组。接下来就是服务(Service)了,一个服务包含多个实例,但是可能处于不同机房,因此Service下有多个集群(Cluster),Cluster下是不同的实例(Instance)。
对应到Java代码中,Nacos采用了一个多层的Map来表示。结构为Map
3.Nacos如何支撑数十万服务注册压力?
(考察对Nacos源码的掌握情况 ServiceManager)
Nacos内部接收到注册的请求时,不会立即写数据,而是将服务注册的任务放入一个阻塞队列就立即响应给客户端。然后利用线程池读取阻塞队列中的任务,异步来完成实例更新,从而提高并发写能力。
4. Nacos如何避免并发读写冲突问题?
(考察对Nacos源码的掌握情况)
Nacos在更新实例列表时,会采用CopyOnWrite技术,首先将旧的实例列表拷贝一份,然后更新拷贝的实例列表,再用更新后的实例列表来覆盖旧的实例列表。
这样在更新的过程中,就不会对读实例列表的请求产生影响,也不会出现脏读问题了。
5. Nacos与Eureka的区别有哪些?
(考察对Nacos、Eureka的底层实现的掌握情况)
Nacos与Eureka有相同点,也有不同之处,可以从以下几点来描述:
接口方式:Nacos与Eureka都对外暴露了Rest风格的API接口,用来实现服务注册、发现等功能
实例类型:Nacos的实例有永久和临时实例之分;而Eureka只支持临时实例
健康检测:Nacos对临时实例采用心跳模式检测,对永久实例采用主动请求来检测;Eureka只支持心跳模式
服务发现:Nacos支持定时拉取和订阅推送两种模式;Eureka只支持定时拉取模式
( 定时拉取:客户端,微服务端有定时服务,隔一段时间拉取一次
订阅推送:【服务变更的那一刻立即推送】用udp套接字和微服务建立连接,Nocos服务端,每当进行服务变更,就会推送广播给所有的监听这个服务的微服务,微服务接收到这个通知之后,就可以把接收到的这些服务信息缓存到本地缓存列表中,以后再有拉取服务的时候就从缓存里读
Eureka只支持定时拉取模式,30秒一次)
6. Sentinel的限流与Gateway的限流有什么差别?
(考察对限流算法的掌握情况)
限流算法常见的有三种实现:滑动时间窗口、令牌桶算法、漏桶算法。Gateway则采用了基于Redis实现的令牌桶算法。
而Sentinel内部却比较复杂:
默认限流模式是基于滑动时间窗口算法
排队等待的限流模式则基于漏桶算法
而热点参数限流则是基于令牌桶算法
7. Sentinel的线程隔离与Hystix的线程隔离有什么差别?
(考察对线程隔离方案的掌握情况)
Hystix默认是基于线程池实现的线程隔离,每一个被隔离的业务都要创建一个独立的线程池,线程过多会带来额外的CPU开销,性能一般,但是隔离性更强。
Sentinel是基于信号量(计数器)实现的线程隔离,不用创建线程池,性能较好,但是隔离性一般。
(Nacos源码:参考 https://blog.csdn.net/weixin_48033615/article/details/127668580)
(Sentinel源码:参考 https://blog.csdn.net/weixin_48033615/article/details/127746740)
二、MQ篇
1.你们为什么选择了RabbitMQ而不是其它的MQ?

kafka是以吞吐量高而闻名,不过其数据稳定性一般,而且无法保证消息有序性。我们公司的日志收集也有使用,业务模块中则使用的RabbitMQ。
阿里巴巴的RocketMQ基于Kafka的原理,弥补了Kafka的缺点,继承了其高吞吐的优势,其客户端目前以Java为主。但是我们担心阿里巴巴开源产品的稳定性,所以就没有使用。
RabbitMQ基于面向并发的语言Erlang开发,吞吐量不如Kafka,但是对我们公司来讲够用了。而且消息可靠性较好,并且消息延迟极低,集群搭建比较方便。支持多种协议,并且有各种语言的客户端,比较灵活。Spring对RabbitMQ的支持也比较好,使用起来比较方便,比较符合我们公司的需求。
综合考虑我们公司的并发需求以及稳定性需求,我们选择了RabbitMQ。
2.RabbitMQ如何确保消息的不丢失?
RabbitMQ针对消息传递过程中可能发生问题的各个地方,给出了针对性的解决方案:
1)生产者发送消息时可能因为网络问题导致消息没有到达交换机:
RabbitMQ提供了publisher confirm机制
生产者发送消息后,可以编写ConfirmCallback函数
消息成功到达交换机后,RabbitMQ会调用ConfirmCallback通知消息的发送者,返回ACK
消息如果未到达交换机,RabbitMQ也会调用ConfirmCallback通知消息的发送者,返回NACK
消息超时未发送成功也会抛出异常
2)消息到达交换机后,如果未能到达队列,也会导致消息丢失:
RabbitMQ提供了publisher return机制
生产者可以定义ReturnCallback函数
消息到达交换机,未到达队列,RabbitMQ会调用ReturnCallback通知发送者,告知失败原因
3)消息到达队列后,MQ宕机也可能导致丢失消息:
RabbitMQ提供了持久化功能,集群的主从备份功能
消息持久化,RabbitMQ会将交换机、队列、消息持久化到磁盘,宕机重启可以恢复消息
镜像集群,仲裁队列,都可以提供主从备份功能,主节点宕机,从节点会自动切换为主,数据依然在
4)消息投递给消费者后,如果消费者处理不当,也可能导致消息丢失
SpringAMQP基于RabbitMQ提供了消费者确认机制、消费者重试机制,消费者失败处理策略:
消费者的确认机制:
消费者处理消息成功,未出现异常时,Spring返回ACK给RabbitMQ,消息才被移除
消费者处理消息失败,抛出异常,宕机,Spring返回NACK或者不返回结果,消息不被异常
消费者重试机制:
默认情况下,消费者处理失败时,消息会再次回到MQ队列,然后投递给其它消费者。Spring提供的消费者重试机制,则是在处理失败后不返回NACK,而是直接在消费者本地重试。多次重试都失败后,则按照消费者失败处理策略来处理消息。避免了消息频繁入队带来的额外压力。
消费者失败策略:
当消费者多次本地重试失败时,消息默认会丢弃。
Spring提供了Republish策略,在多次重试都失败,耗尽重试次数后,将消息重新投递给指定的异常交换机,并且会携带上异常栈信息,帮助定位问题。
3.RabbitMQ如何避免消息堆积?
消息堆积问题产生的原因往往是因为消息发送的速度超过了消费者消息处理的速度。因此解决方案无外乎以下三点:
提高消费者处理速度、增加更多消费者、增加队列消息存储上限