Kubernetes核心实战
kubernetes(一)概述与架构
kubernetes(二)创建集群
云原生实战 · 语雀
官网 Kubernetes 文档 | Kubernetes
B站课程:https://www.bilibili.com/video/BV13Q4y1C7hS/?p=41
1.Namespace
名称空间,用来对集群资源进行隔离划分。默认只隔离资源,不隔离网络

1.1 查看
kubectl get namespace
# 或者写简称ns
kubectl get ns
# kubectl get pods说明
kubectl get pods # 只获取默认名称空间(default)下的pod
kubectl get pods -A # 查看所有
kubectl get pods -n 具体的namespace # 查看指定名称空间下的pod
返回结果示例
[root@k8s-master ~]# kubectl get ns
NAME STATUS AGE
default Active 20d
kube-flannel Active 20d
kube-node-lease Active 20d
kube-public Active 20d
kube-system Active 20d
kubernetes-dashboard Active 7d1h
1.2 创建与删除
命令行方式
kubectl create ns hello
kubectl get ns
# 会把该名称空间下部署的所有资源连带删除
kubectl delete ns hello
YAML方式
hello.yaml
apiVersion: v1
kind: Namespace
metadata:
name: hello
执行命令
# 创建yaml文件,粘贴上面的内容创建名称空间
vim hello.yaml
kubectl apply -f hello.yaml
kubectl get ns
kubectl delete -f hello.yaml
2.Pod
运行中的一组容器,Pod是kubernetes中应用的最小单位
一个pod中可以有多个容器

2.1 创建删除
命令方式
kubectl run mynginx --image=nginx
kubectl delete pod 具体Pod名字
# -n可以指定多个命名空间,myapp和mynginx都是pod的名字
kubectl delete pod myapp mynginx -n default
yaml方式
pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: mynginx
name: mynginx
# namespace: default
spec:
containers:
- image: nginx
name: mynginx
执行命令
kubectl apply -f pod.yaml
kubectl delete -f pod.yaml
2.2 补充
# 查看default名称空间的Pod
kubectl get pod
# 描述
kubectl describe pod 具体Pod名字
# 查看Pod的运行日志
kubectl logs 具体Pod名字
# 查看Pod的运行日志 追踪
kubectl logs -f 具体Pod名字
# 每个Pod - k8s都会分配一个ip。【-owide】可以分开写成【-o wide】,是查看详细信息
# 集群中的任意一个机器以及任意的应用都能通过Pod分配的ip来访问这个Pod
kubectl get pod -owide
# 使用Pod的ip+pod里面运行容器的端口
curl 192.168.169.136
# 进入容器
kubectl exec -it mynginx -- /bin/bash
2.3 一个pod部署多个container
apiVersion: v1
kind: Pod
metadata:
labels:
run: myapp
name: myapp
spec:
containers:
- image: nginx
name: nginx
- image: tomcat:8.5.68
name: tomcat

3.Deployment
控制Pod,使Pod拥有多副本,自愈,扩缩容等能力
# 简单地只创建一个pod的话,pod被删了就不存在了
kubectl run mynginx --image=nginx
# 用deployment部署的pod有自愈能力,删了pod后deployment会再给启动pod,保证pod副本个数
kubectl create deployment mytomcat --image=tomcat:8.5.68
# 查看状态等信息(deployment可以简写为deploy)
kubectl get deployment
# 删除deployment
kubectl delete deploy mytomcat
3.1 多副本
多副本,使用命令行创建deployment的话,添加参数--replicas=3
# 创建一次部署,名字叫my-dep,image用什么镜像,replicas副本总共数量
kubectl create deployment my-dep --image=nginx --replicas=3
多副本,使用yaml创建deployment
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-dep
name: my-dep
spec:
replicas: 3
selector:
matchLabels:
app: my-dep
template:
metadata:
labels:
app: my-dep
spec:
containers:
- image: nginx
name: nginx
3.2 扩缩容

# 每隔 1 秒执行一次`kubelet get pod`命令
watch -n 1 kubelet get pod
# 把my-dep这个deployment由3个扩为5个,上面watch监控命令会变化
kubectl scale deploy/my-dep --replicas=5
# 缩容至2个
kubectl scale deploy/my-dep --replicas=2
扩缩容也可以这样做
kubectl get deploy
kubectl edit deployment my-dep
# 修改【replicas】的数值,保存后自动生效
3.3 自愈&故障转移
- 停机
- 删除Pod
- 容器崩溃
- ……
自愈能力
# 监控pod变化
watch -n 1 kubelet get pod
# 查看pod详细信息,包括pod在哪个node机器上
kubectl get pod -owide
# 在具体node机器上杀死某容器,观察watch命令的变化,可以看到自愈能力,又让该容器启动了
docker stop 容器id
故障转移
# 也是监控pod变化的命令,是k8s提供的,追加打印,可以看到变化过程
kubelet get pod -w
# 查看pod详细信息,包括pod在哪个node机器上
kubectl get pod -owide
# 将具体node机器强制关机,可以看到故障转移
3.4 滚动更新
启动新pod,成功了再删掉旧pod,实现平滑升级。不停服更新首先要保证新老版本应用都可以正常读写数据库。
# 让该deployment信息以yaml方式输出,可以看my-dep这个deployment用的什么镜像
kubectl get deploy my-dep -oyaml
# 监控pod变化
kubelet get pod -w
watch -n 1 kubelet get pod
# 滚动更新。yaml中spec.containers下的name是nginx,所以写【nginx=】
kubectl set image deployment/my-dep nginx=nginx:1.16.1 --record
# 查看名为my-dep的部署的状态。【rollout status】显示关于该部署更新的进度,例如更新是否成功,正在进行中,或者遇到了错误。
kubectl rollout status deployment/my-dep
3.5 版本回退
# 历史记录。可看版本的变更记录及其原因
kubectl rollout history deployment/my-dep
# 查看某个历史详情
kubectl rollout history deployment/my-dep --revision=2
# 回滚到上次
kubectl rollout undo deployment/my-dep
# 回滚到指定版本
kubectl rollout undo deployment/my-dep --to-revision=2
3.6 Deployment和其他工作负载
除了Deployment,k8s还有 StatefulSet 、DaemonSet 、Job 等 类型资源。我们都称为 工作负载。
实际工作场景中一般不会直接部署pod,而是使用工作负载控制pod,使其功能更强大。
无状态应用使用 Deployment 部署,有状态应用使用 StatefulSet 部署。
官网 - 工作负载资源 | Kubernetes

| 名称 | 部署类型 | 使用场景举例和特点 |
|---|---|---|
| Deployment | 无状态应用 | 比如微服务。提供多副本等功能。 |
| StatefulSet | 有状态应用 | 比如redis。提供稳定的存储、网络等功能。 |
| DaemonSet | 守护型应用 | 比如日志收集组件。在每个机器都运行一份。 |
| Job/CronJob | 定时任务 | 比如垃圾清理组件。可以在指定时间运行。 |
4.Service
将一组 Pods 公开为网络服务的抽象方法。
4.1 ClusterIP

使用命令方式
# 暴露的service只能在集群内访问,因为该命令末尾默认的是【--type=clusterIP】
kubectl expose deployment my-dep --port=8000 --target-port=80
# 集群内使用service的ip:port就可以负载均衡的访问
# 使用标签检索Pod
kubectl get pod -l app=my-dep
curl 10.96.8.0:8000
使用yaml方式
apiVersion: v1
kind: Service
metadata:
labels:
app: my-dep
name: my-dep
spec:
selector:
app: my-dep # 此处决定选中哪组pod。此处app的值是【kubectl get pod --show-lables】显示的app=my-dep
ports:
- port: 8000
protocol: TCP
targetPort: 80
# type: ClusterIP # 默认就是ClusterIp
4.2 NodePort
NodePort这种暴露方式集群外也可以访问。暴露的该服务在每一个节点都会开个端口,可使用每个节点的【公网ip:端口】访问。NodePort范围在 30000-32767 之间
命令方式
kubectl expose deployment my-dep --port=8000 --target-port=80 --type=NodePort
# 可看到PORTS列为【8000:30948/TCP】,30948为随机生成的端口
kubectl get svc
curl 10.96.91.238:8000
yaml方式
apiVersion: v1
kind: Service
metadata:
labels:
app: my-dep
name: my-dep
spec:
ports:
- port: 8000
protocol: TCP
targetPort: 80
selector:
app: my-dep
type: NodePort
4.3 补充弹幕讨论
回答一下为什么不用:最上面的HA和堡垒机做负载均衡,服务器层nginx做了服务器的负载均衡,业务代码层nacos做了微服务的发现和负载均衡,那k8s的地位是不是有点尴尬
必须是一组相同的服务,mysql主备虽然都是mysql,但一个主服务一个备服务,有状态服务,是不同组;某组业务微服务,无状态服务,才叫一组
5.Ingress
官网 - Welcome - Ingress-Nginx Controller
Ingress可以成为集群流量的唯一入口
Ingress底层就是拿Nginx来做的

5.1 安装
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.47.0/deploy/static/provider/baremetal/deploy.yaml
# 修改镜像
vi deploy.yaml
# 将image的值改为如下值:
registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/ingress-nginx-controller:v0.46.0
kubectl apply -f ingress.yaml
# 检查安装的结果
kubectl get pod,svc -n ingress-nginx
# 最后别忘记把svc暴露的端口要放行
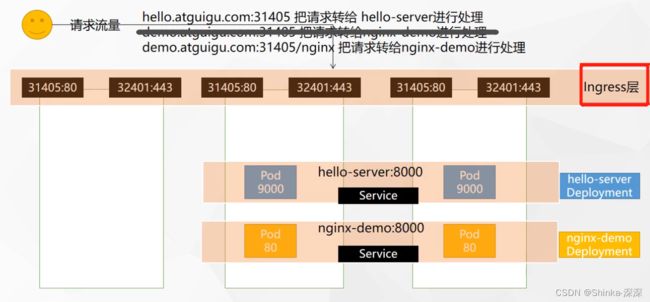
PORT列有显示开放的端口,之后所有的请求都应该发给31405(http)或32401(https),由网关统一处理

5.2 准备测试环境
【准备测试环境】阶段只做到【curl 10.96.58.176:8000】即可,
根据域名【hello.atguigu.com:31405】和【demo.atguigu.com:31405/nginx】经过Ingress层转发请求到达相应的服务,是下一步【域名访问】的内容。
执行命令
vim test.yaml
# 【kubectl apply -f test.yaml】执行后显示如下
# deployment.apps/hello-server created
# deployment.apps/nginx-demo created
# service/nginx-demo created
# service/hello-server created
kubectl apply -f test.yaml
kubectl get svc
curl 10.96.58.176:8000
test.yaml内容
kubectl apply -f test.yaml应用如下内容,产生几个部署(deployment)
nginx-demo这个service负载均衡网络,选中app为nginx-demo的2个pod,端口8000。hello-server同理
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-server
spec:
replicas: 2 # hello-server这个deploy有2个副本
selector:
matchLabels:
app: hello-server
template:
metadata:
labels:
app: hello-server
spec:
containers:
- name: hello-server
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/hello-server
ports:
- containerPort: 9000
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-demo
name: nginx-demo
spec:
replicas: 2 # nginx-demo这个deploy有2个副本
selector:
matchLabels:
app: nginx-demo
template:
metadata:
labels:
app: nginx-demo
spec:
containers:
- image: nginx
name: nginx
---
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx-demo
name: nginx-demo
spec:
selector:
app: nginx-demo
ports:
- port: 8000
protocol: TCP
targetPort: 80
---
apiVersion: v1
kind: Service
metadata:
labels:
app: hello-server
name: hello-server
spec:
selector:
app: hello-server
ports:
- port: 8000
protocol: TCP
targetPort: 9000
测试。访问hello-server会返回打印Hello World!

5.3 域名访问
vim ingress-rule.yaml
kubectl apply -f ingress-rule.yaml
# 查看ingress里的规则
kubectl get ingress
# 修改配置。ing是ingress简写,因为在default名称空间下,所以不用加-n参数指定
kubectl edit ing ingress-host-bar
yaml内容
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-host-bar # 不重复即可
spec:
ingressClassName: nginx
rules:
- host: "hello.atguigu.com"
http:
paths:
- pathType: Prefix # 前缀模式
path: "/" # hello.atguigu.com域名下的所有请求,前缀是/,即【hello.atguigu.com/】
backend:
service:
name: hello-server # backend是后台服务,转发给hello-server这个后台服务
port:
number: 8000
- host: "demo.atguigu.com"
http:
paths:
- pathType: Prefix
path: "/nginx" # 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
backend:
service:
name: nginx-demo # 此处以后使用java等微服务模块,要求path都带前缀/api的话,可以使用路径重写,去掉前缀nginx
port:
number: 8000
域名应该是申请购买,此处用添加域名映射的方式演示
对连接云服务器使用的物理主机修改hosts文件,添加master节点的域名映射
139.198.165.238 hello.atguigu.com
139.198.165.238 demo.atguigu.com
修改了host文件的主机的浏览器中访问hello.atguigu.com:31405和demo.atguigu.com:31405/nginx
5.4 路径重写
以后使用java等微服务模块,要求path都带前缀/api的话,可以使用路径重写,去掉前缀nginx,详见官网文档Ingress路径重写 - Annotations - Ingress-Nginx Controller

官网示例 - Rewrite - Ingress-Nginx Controller
$ echo '
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/use-regex: "true"
nginx.ingress.kubernetes.io/rewrite-target: /$2
name: rewrite
namespace: default
spec:
ingressClassName: nginx
rules:
- host: rewrite.bar.com
http:
paths:
- path: /something(/|$)(.*)
pathType: ImplementationSpecific
backend:
service:
name: http-svc
port:
number: 80
' | kubectl create -f -
以上官网示例的作用
In this ingress definition, any characters captured by
(.*)will be assigned to the placeholder$2, which is then used as a parameter in therewrite-targetannotation.在此入口定义中,捕获
(.*)的任何字符都将分配给占位符$2,然后将其用作rewrite-target注释中的参数。For example, the ingress definition above will result in the following rewrites:
例如,上面的入口定义将导致以下重写:
rewrite.bar.com/somethingrewrites torewrite.bar.com/rewrite.bar.com/something/rewrites torewrite.bar.com/rewrite.bar.com/something/newrewrites torewrite.bar.com/new
修改【域名访问】中的ingress-rule.yaml
加上了这句注解信息metadata.annotations.nginx.ingress.kubernetes.io/rewrite-target: /$2表示指定一个重写目标/$2,它将会替换发起HTTP请求时的URL。/$2 表示被提取的第二个正则表达式组。在本例中,由于只有一个正则表达式组,所以其实/$2表示正则表达式的结果。
将spec.rules.http.paths.path改为/something(/|$)(.*)。这行配置确定哪些HTTP请求会被应用重写规则。定义的URL前缀是/something,然后是两个可能的字符(/ 或者 结束字符),接下来是任意的字符序列(.*)。所以,这条规则将会应用到所有以/something开头的HTTP请求,无论它们是否有更多路径(譬如/something/more)
换句话说,如果有入站请求的URL path匹配了/something(/|$)(.*),重写后的请求path将会被Nginx服务器重定向到/$2,$2代表的是输入URL path的(/|$)(.*)部分。因此,这样的设定可以帮助我们处理特定模式的URL,并且可以根据这些URL path的内容进行动态地重写和路由。
vim ingress-rule.yaml
kubectl apply -f ingress-rule.yaml
# 查看ingress里的规则
kubectl get ingress
现在访问【demo.atguigu.com:31405/nginx】就相当于【demo.atguigu.com:31405/】
5.5 流量限制
官网 - Annotations - Ingress-Nginx Controller
nginx.ingress.kubernetes.io/limit-rps: number of requests accepted from a given IP each second. The burst limit is set to this limit multiplied by the burst multiplier, the default multiplier is 5. When clients exceed this limit, limit-req-status-code default: 503 is returned.
nginx.ingress.kubernetes.io/limit-rps:每秒从给定 IP 接受的请求数。突发限值设置为此限值乘以突发乘数,默认乘数为 5。当客户端超过此限制时,将返回 limit-req-status-code 默认值:503。
先对连接云服务器使用的物理主机修改hosts文件,添加域名映射139.198.165.238 haha.atguigu.com
yaml配置中,访问haha.atguigu.com会转发到nginx-demo服务,nginx.ingress.kubernetes.io/limit-rps: "1"让请求进行流量限制:每秒通过1个请求。
ingress-rule-2.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-limit-rate
annotations:
nginx.ingress.kubernetes.io/limit-rps: "1"
spec:
ingressClassName: nginx
rules:
- host: "haha.atguigu.com"
http:
paths:
- pathType: Exact # 精确模式,访问【haha.atguigu.com/】会匹配该规则转发到nginx-demo服务,访问【haha.atguigu.com/abc】不会匹配该规则
path: "/"
backend:
service:
name: nginx-demo
port:
number: 8000
执行命令
vim ingress-rule-2.yaml
kubectl apply -f ingress-rule-2.yaml
kubectl get ingress
等address分配好ip之后才算生效,再测试访问【haha.atguigu.com:31405】,疯狂刷新就偶尔能看到503,偶尔能成功返回Nginx页面。

5.6 总结-网络模型
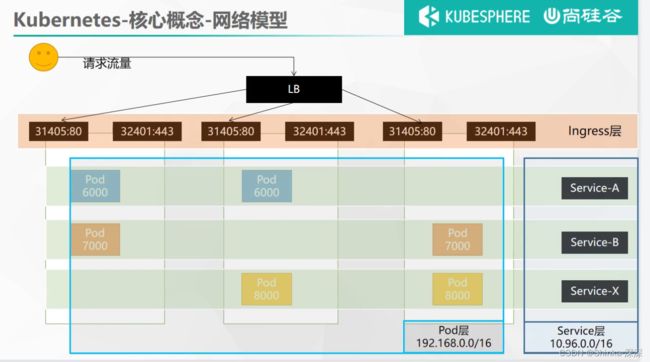
三台机器会部署很多Pod
相同颜色的就是一组Pod,这些Pod要想能提供访问,则将其抽象成一个Service。
Ingress前面可以做一层LB(Load Balance 负载均衡),这个前置负载均衡器可以购买或者自己搭建,由LB将请求流量分发到三台机器,就是相当于分发给具体机器的Ingress。
Ingress收到请求后,可以按照域名、路径等各种规则,将请求交给相应的Service。
Service负责了一组Pod,将请求交给其中一个Pod。
所以K8s中产生了三层网络:
-
所有的Pod。在安装搭建时
--pod-network-cidr=192.168.0.0/16配置了网络范围,Pod层的网络是互通的(所有Pod之间通过ip也能访问通)。 -
一组Pod的Service层网络。在安装搭建时
--service-cidr=10.96.0.0/16配置了网络范围,Service与Service之间也是互通的。Pod可以通过Service访问到别的组的Pod。 -
Ingress层。请求流量先到达Ingress层,再到达Service层,再到达Pod。
6.存储抽象
6.1 简介
单纯只使用Docker时,三台机器部署的各个Pod,可以将容器内部的路径与物理机的路径做数据卷映射
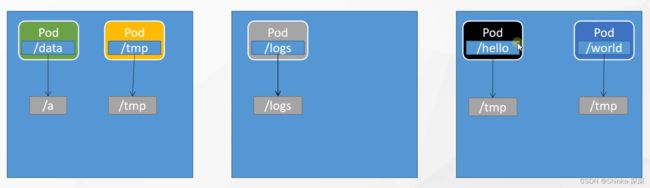
但使用了k8s这样会有问题,比如3号机器的一个Pod宕机,k8s判断它挂了,故障转移使得在2号机器启动了该Pod,那3号机器的物理机路径存储的数据不会转移2号机器上,因此2号机器新启动的Pod是没有历史数据的。
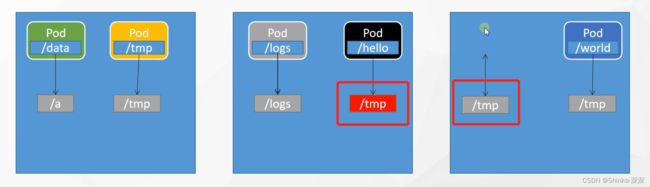
k8s可以把挂载统一管理起来,形成存储层。Pod想要挂载什么,找存储层获得分配的空间。故障转移在另外的机器启动了Pod,存储层也会找到该Pod之前存储的数据。
存储层可以使用的技术有很多,比如Clusterfs、NFS(网络文件系统)、CephFS等,用啥都行。

此处演示使用NFS。
NFS是一种基于TCP/IP传输的网络文件系统协议。通过使用NFS协议,客户机可以像访问本地目录一样访问远程服务器中的共享资源。
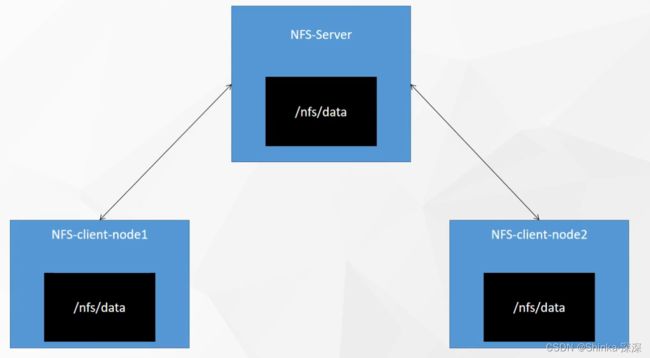
若在1号机器开了个目录/nfs/data有50G,所有的Pod挂载数据都在该目录下,同时在别的机器开个备份目录/bak/data(路径名自己配置,也可以配置同名的/nfs/data),与/nfs/data中的数据是一样的,三者之间同步。
比如2号机的Pod在/bak/data下写了数据,也会同步给/nfs/data及别的机器的/bak/data。
此时若2号机Pod挂了,在3号机重启该Pod时,从3号机的/bak/data中能读到该Pod的历史数据。

搭建NFS网络的文件系统,可随便指定一台机器(比如k8s的master节点)为NFS-Server
6.2 NFS环境准备
6.2.1 所有机器安装
yum install -y nfs-utils
6.2.2 nfs主节点
nfs主节点(此处选用k8s的master作为nfs的主节点)执行命令
# 在master节点暴露/nfs/data路径,*代表所有人都可以同步该目录,insecure非安全方式,rw读写
echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
mkdir -p /nfs/data/nginx-pv
# 启动rpc远程绑定,现在就启动且开机自启动
systemctl enable rpcbind --now
# 启动nfs服务,现在就启动且开机自启动
systemctl enable nfs-server --now
# 配置生效
exportfs -r
# 检查
exportfs
6.2.3 nfs从节点
nfs从节点执行以下命令。前面已经安装了nfs-utils工具类。
# 检查nfs服务哪些路径支持挂载,172.31.0.4换成master的私有ip地址(`ip a`命令eth0显示的)
showmount -e 172.31.0.4
# 在从节点上创建目录
mkdir -p /nfs/data
# 挂载nfs服务器上的共享目录到本机路径/nfs/data。172.31.0.4换成master的私有ip地址。
mount -t nfs 172.31.0.4:/nfs/data /nfs/data
# 写入一个测试文件
echo "hello nfs server" > /nfs/data/test.txt
6.2.4 原生方式数据挂载
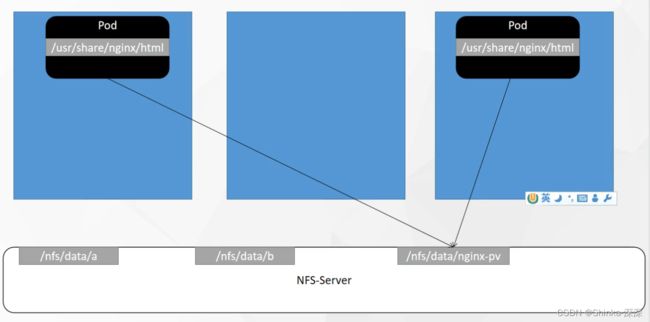
deploy.yaml文件内容。容器内部的/usr/share/nginx/html最终映射到nfs服务器的/nfs/data/nginx-pv
apiVersion: apps/v1
kind: Deployment # 这是一次Deployment部署
metadata:
labels:
app: nginx-pv-demo
name: nginx-pv-demo
spec:
replicas: 2 # 2个副本
selector:
matchLabels:
app: nginx-pv-demo
template:
metadata:
labels:
app: nginx-pv-demo
spec:
containers:
- image: nginx # 使用nginx镜像
name: nginx
volumeMounts: # 数据卷挂载
- name: html # 挂载到外面,名字叫html,这个名字随便起
mountPath: /usr/share/nginx/html # 该容器内部的/usr/share/nginx/html路径挂载到外面
volumes:
- name: html # 名字叫html,跟上面的name保持一致即可。具体挂载方式看下面几行
nfs: # 用nfs网络文件系统
server: 172.31.0.4 # 替换成nfs服务的主节点ip
path: /nfs/data/nginx-pv
执行命令,部署该nginx
vim deploy.yaml
kubectl apply -f deploy.yaml
# 发现创建了两个pod叫nginx-pv-demo,等它俩启动成功,数据就会挂载到/nfs/data/nginx-pv
kubectl get pod
# 查看描述能排查问题,或者从可视化界面里看。
kubectl describe pod pod名字
修改/nfs/data/nginx-pv路径的内容,效果就是两个Pod都改了。
# nfs服务的主节点
cd /nfs/data/nginx-pv
ls
echo 111222 > index.html
# 去nginx的两个容器里面查看
cd /usr/share/nginx/html
cat index.html
6.2.5 原生方式数据挂载存在的问题
以上方式会有问题
-
路径需手动创建。Pod都挂载到/nfs/data/nginx-pv,该路径需要自己手动创建。
-
内容不会自动清理。若删除Pod,/nfs/data/nginx-pv路径下的内容不会自动清理。
-
挂载目录无容量限制。以上示例nginx-pv-demo挂载了/nfs/data/nginx-pv路径,其他pod可能挂载别的路径比如/nfs/data/a、/nfs/data/b,而默认对它们能使用的空间没有限制,就有可能某Pod把磁盘全部占满导致别的Pod无法使用。
因此我们不使用原生方式数据挂载,接下来介绍其他挂载方案:
PV&PVC(适合挂载目录)
ConfigMap(适合挂载配置文件)
6.3 PV&PVC
6.3.1 简介
PV:持久卷(Persistent Volume),将应用需要持久化的数据保存到指定位置
PVC:持久卷申明(Persistent Volume Claim),申明需要使用的持久卷规格
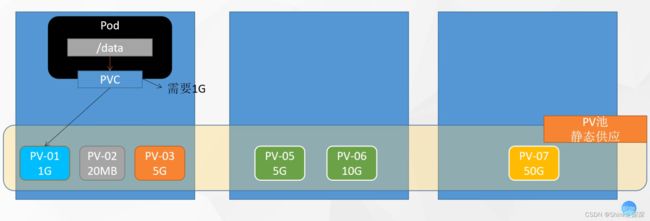
在3台机器准备一些存储空间PV-01至PV-07,叫做PV池,这种方式可以称为静态供应。
静态供应就是提前创建好,而不是根据申明动态创建空间大小。
Pod想要挂载数据,在Pod上提交一个PVC,然后使得Pod与具体的空间绑定。即使故障转移重启了Pod,根据PVC还能找到之前挂载数据的那块空间。
6.3.2 创建pv池
静态供应
# nfs主节点
mkdir -p /nfs/data/01
mkdir -p /nfs/data/02
mkdir -p /nfs/data/03
创建PV。以下pv.yaml声明了3块空间。
apiVersion: v1
kind: PersistentVolume # 持久化卷,即真正存数据的地方
metadata:
name: pv01-10m # 名字随便,但是字母要小写,否则kubectl apply时会报错
spec:
capacity:
storage: 10M # 容量最大10M
accessModes:
- ReadWriteMany # 可读可写 并且是多节点(多个机器一起读写操作)
storageClassName: nfs # Class的名字,随便起,但分割线(---)后面的两块storageClassName要一致
nfs:
path: /nfs/data/01
server: 172.31.0.4 # nfs服务主节点的ip
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv02-1gi
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/02
server: 172.31.0.4
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv03-3gi
spec:
capacity:
storage: 3Gi
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/03
server: 172.31.0.4
执行命令
cd ~
vim pv.yaml
kubectl apply -f pv.yaml
# 查看persistentvolume资源
kubectl get persistentvolume
6.3.3 PVC创建与绑定
创建PVC
vim pvc.yaml
kubectl apply -f pvc.yaml
kubectl get pv
pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim # 资源类型是PVC申明
metadata:
name: nginx-pvc # 名字自取,但后面创建pod所使用的pvc名字要与此处一致
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 200Mi
storageClassName: nfs # 跟前面创建PV时的storageClassName保持一致
演示删除pvc,再让pvc重新绑定pv的效果(不用操作)
pvc.yaml申请的200M自动绑定了pv02-1gi的PV,因为10M太小,3G太大,会自动选择合适的空间大小。

删除该pvc,所绑定的pv的状态变为释放。

该pvc重新申请,自动重新绑定到3G的PV上去了。pv02-1gi还在Released状态是还没完全清空。

创建Pod绑定PVC
dep02.yaml内容:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-deploy-pvc
name: nginx-deploy-pvc # Pod名字自取
spec:
replicas: 2 # 部署2个
selector:
matchLabels:
app: nginx-deploy-pvc
template:
metadata:
labels:
app: nginx-deploy-pvc
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: html # 这个是[挂载]的名字
mountPath: /usr/share/nginx/html
volumes:
- name: html
persistentVolumeClaim: # 这里不是写nfs了,而是写pvc
claimName: nginx-pvc # 这个名称跟前面pvc.yaml创建pvc时的名字一致
创建命令
vim dep02.yaml
kubectl apply -f dep02.yaml
# 有两个名字类似【nginx-deploy-pvc-xxx-xxx】的Pod,等它俩启动完成
kubectl get pod
# 可以查看到nginx-pvc这个pvc所绑定的卷是pv03-3gi
kubectl get pvc
# 同时查看多个资源用逗号分隔
kubectl get pvc,pv
Pod绑定了pvc(yaml文件中claimName指定的),pvc绑定了一块pv
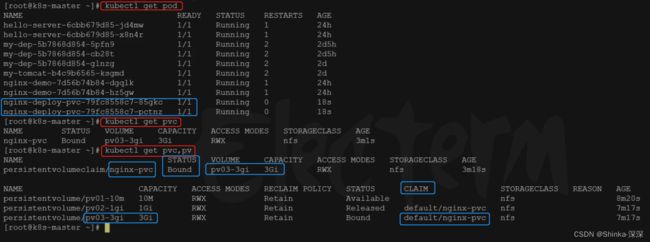
测试修改数据卷pv03-3gi,看这个nginx的pod的效果
cd /nfs/data/03/
echo 222222 > index.html
# 进入到nginx容器里面之后执行
cd /usr/share/nginx/html/
cat index.html
6.3.4 补充说明PV池动态供应
有个Pod想申请10M的空间,就给它自动创建好10M的空间并绑定,不是从实现创建好的静态的空间里挑选的。

6.4 ConfigMap
抽取应用配置,并且可以自动更新
想要挂载配置文件,遵循两步:先把准备要挂载的配置文件做成k8s推荐的ConfigMap,再在Pod的配置文件中引用该ConfigMap再启动。
【以下以redis作为例子演示】
6.4.1 把之前的配置文件创建为配置集
配置集是在k8s的ETCD(资料库)里面存着。将配置文件做成配置集,只要k8s正常,这个内容就存在
# 准备一个redis的配置文件。内容可以只写一句:appendonly yes
vim redis.config
# 创建配置集,redis保存到k8s的etcd。cm是configmap的简称,redis-conf是配置集名字
kubectl create cm redis-conf --from-file=redis.conf
# 查看,有redis-conf这个配置集
kubectl get cm
# 配置集有了以后,redis.config文件就可以删除了
rm -rf redis.conf
可以以yaml方式查看配置集kubectl get cm redis-conf -oyaml
精简后重点注意的配置集信息,主要是以下内容:
apiVersion: v1
data: # data是所有真正的数据,key:默认是文件名 value:配置文件的内容
# 配置数据是k:v的形式,key为redis.conf是因为前面执行命令时用的文件名是redis.conf。竖线|代表接下来是大文本
redis.conf: |
appendonly yes
kind: ConfigMap # 资源类型
metadata:
name: redis-conf # configmap资源的名字。前面命令指定的configmap的名字
namespace: default
6.4.2 创建Pod
启动pod,用到Redis配置文件时,用配置集里面的东西就可以
此处简单创建Pod,不创建Deployment部署了
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
command:
- redis-server # redis的启动命令
- "/redis-master/redis.conf" # 指的是redis容器内部的位置
ports:
- containerPort: 6379
volumeMounts: # 卷挂载
- mountPath: /data
name: data
- mountPath: /redis-master # 这个路径下本应该有个redis.conf文件,现在要挂载该/redis-master路径
name: config # [挂载]的名字自取
volumes:
- name: data
emptyDir: {} # /data随便挂载个空目录
- name: config # 与前面[挂载]的名字保持一致
configMap: # 以前这里写过nfs,现在是configMap,表明想用的配置文件/redis-master/redis.conf是从配置集里面取
name: redis-conf # 名字叫redis-conf的配置集,就是上一步创建的配置集
items: # 获取ConfigMap配置集下的data所有项的内容(见上一步`kubectl get cm redis-conf -oyaml`命令所显示的data内容)
- key: redis.conf # 取 配置集的data下的 [redis.conf]这个key的 所有内容
path: redis.conf # 将上面取的所有内容放到 容器内的该路径下。这个路径是前面写了【mountPath: /redis-master】,所以此处路径指容器内部的/redis-master/redis.conf
6.4.3 整个挂载关系图示

6.4.4 检查默认配置
kubectl exec -it redis -- redis-cli
127.0.0.1:6379> CONFIG GET appendonly
127.0.0.1:6379> CONFIG GET requirepass
6.4.5 修改ConfigMap
修改ConfigMap配置集的内容,Pod内的配置文件会跟着变。
但若没有热更新的话,Pod需要重启生效。
配置值未更改,因为需要重新启动 Pod 才能从关联的 ConfigMap 中获取更新的值。
原因:我们的Pod部署的中间件自己本身没有热更新能力
kubectl get cm
# 在【appendonly yes】下一行追加【requirepass 123456】,注意格式对齐
kubectl edit cm redis-conf
# 进入redis容器内部查看
cd /redis-master
cat redis.conf
另一种修改
apiVersion: v1
kind: ConfigMap
metadata:
name: example-redis-config
data:
redis-config: |
maxmemory 2mb
maxmemory-policy allkeys-lru
6.4.6 检查配置是否更新
kubectl exec -it redis -- redis-cli
127.0.0.1:6379> CONFIG GET maxmemory
127.0.0.1:6379> CONFIG GET maxmemory-policy
6.5 Secret
Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 将这些信息放在 secret 中比放在 Pod 的定义或者 容器镜像 中来说更加安全和灵活。
Secret跟ConfigMap工作原理差不多,但ConfigMap适用于保存配置文件。
Secret有个典型应用场景:Pod启动时拉取镜像,若从私有镜像仓库拉取,需要密码登录,密码写到Pod的yaml里不安全、容易泄露,可以让k8s使用Secret进行管理
执行命令
# leifengyang-docker是对这个Secret取的名字
kubectl create secret docker-registry leifengyang-docker \
--docker-username=leifengyang \
--docker-password=Lfy123456 \
--docker-email=534096094@qq.com
##命令格式
kubectl create secret docker-registry regcred \
--docker-server=<你的镜像仓库服务器> \
--docker-username=<你的用户名> \
--docker-password=<你的密码> \
--docker-email=<你的邮箱地址>
# 查看
kubectl get secret
# Secret里面存的dockerconfigjson其实是Base64编码的
kubectl get secret leifengyang-docker -oyaml
vim mypod.yaml
kubectl apply -f mypod.yaml
mypod.yaml
apiVersion: v1
kind: Pod
metadata:
name: private-nginx
spec:
containers:
- name: private-nginx
image: leifengyang/guignginx:v1.0
imagePullSecrets:
- name: leifengyang-docker # 使用刚才创建的Secret