C++类的继承——派生类详解
继承(类的复用)——派生类
1.单继承
格式 class <派生类名>: <继承方式> <基类名>
{
<成员说明表>
}
继承方式可以是public,private,protected
#include注意事项:
1).派生类除了拥有定义的成员外,还包含了基类的所有成员(基类的构造函数、析构函数和赋值操作符重载函数除外)。
2).定义派生类时一定要有基类的定义,否则编译程序无法确定派生类对象需占多大内存空间以及派生类中对基类成员的访问是否合法。
3).除非在派生类中显式指出,否则基类的友元不是派生类的友元;如果基类是另一个类的友元,除非在该类中显式指出,否则派生类不是该类的友元。
2.在派生类中访问基类成员——protected访问控制
<1>.protected访问限制
在C++中,派生类不能直接访问基类的私有成员,必须通过基类的非私有成员函数来访问基类的私有成员,例如:
#include实际上一个类可以用来创建对象(类的实例),也可以用来定义派生类,即一个类有两种不同的用户:
1.类的实例用户
void g()
{
A a;
a.f();
}
2.派生类
可以通过引进protected成员访问控制来缓解继承与数据封装的矛盾:在基类中声明为protected的成员可以被派生类使用,但不能被基类的实例用户使用。
这样,一个类就存在两个接口:(1).由public成员构成 ,它提供给实例用户使用 (2).另一个接口由类的public和protected成员构成,该接口提供给派生类使用。
#include<2>.基类和派生类同名成员访问规则
在派生类中访问基类成员除了要受到基类成员访问控制(private,protected之类)的限制以外,还要受到标识符作用域的限制。
对基类而言,派生类成员名的作用域嵌套在基类作用域中。
对于基类的一个成员,如果派生类中没有定义与其同名的成员,则该成员名在派生类中可见,否则该成员名在派生类中不直接可见(hidden),如果要使用,必须采用基类名受限方式。
#include名字相同,参数不同时,基类的同名函数在派生类中也是不直接可见的。这时也可以用基类受限方式来使用它:
#include也可以在派生类中使用using声明将基类中的某个函数名对派生类开放。例如:
#if PRO7==5
#include假如B还有一个派生类C
class C :public B
{
int m;
public:
void f(char s) { cout << "这是C类中的同名f函数,参数为char" << endl; }
using B::f;
//using B::A::f;
};
这时C的对象可以访问A、B、C的同名f函数:
C c1;
c1.f();//OK
c1.f(1);//OK
c1.f('x');//OK
3.派生类对基类成员的访问控制——继承方式
<1>.继承方式和成员类型对派生类成员的影响
在C++中,派生类拥有基类的所有成员。基类的成员对派生类用户具有的访问控制方式是由基类成员的访问控制和派生类的继承方式共同决定的。
| 在派生类中的访问控制↘ | 成员类型:public | 成员类型:protected | 成员类型:private |
|---|---|---|---|
| 继承方式:public | public | protected | 不可直接使用 |
| 继承方式:private | private | private | 不可直接使用 |
| 继承方式:protected | protected | protected | 不可直接使用 |
#include<2>.继承方式的调整
在任何继承方式中,除了基类的public成员,其他成员都可以在派生类中分别调整其访问控制,调整时采用下面的格式:
[public:|protected:|private:] <基类名>::<基类成员名>;
#include对基类一个成员函数名的访问控制的调整,将调整基类中所有的同名函数。但如果在派生类中定义了与基类同名的成员函数,则在派生类中不能再对基类中的同名函数进行访问控制调整。
在C++中,public继承方式有着特殊的意义:以public方式继承的派生类可看成基类的子类型(subtype):如果一个类型S是另一个类型T的子类型,则对用T表达的所有程序P,当用S替换程序P中的T时,程序P的功能不变。
子类型在程序设计中的作用体现在:
1.对类型T的操作也能作用于它的子类型数据S。
2.一个子类型S的数据也可以赋值或作为函数参数传递给类型T的变量。
#include注意,下面的操作是非法的:
a.g();//ERROR,派生类操作不能用于基类对象,a没有g这个成员函数
q=&a;//ERROR,派生类指针变量不能指向基类对象
//否则将导致可能通过q向对象a发送它不能处理的消息,如:q->g();
b=a;//ERROR,基类对象不能赋值给派生类对象
//否则将导致b有不确定的成员数据(对象a没有这些数据)
4.派生类对象的初始化和赋值操作
派生类对象的初始化由基类和派生类共同完成,即基类的数据成员由基类的构造函数初始化,派生类的数据成员由派生类的构造函数初始化。当创建派生类的对象时,派生类的构造函数在进入其函数体之前首先会调用基类的构造函数,然后再执行自己的函数体。默认情况下是调用基类的默认构造函数,如果要调用基类的非默认构造函数,则必须在派生类构造函数的成员初始化表中指出。
#include如果一个类既有基类又有成员对象类,则在创建该类对象时,该类的构造函数是先调用基类的构造函数,再调用成员对象类的构造函数,最后执行自己的函数体。
当该类对象消亡时,先调用和执行自己的析构函数,然后调用成员对象类的析构函数,最后调用基类的析构函数。
对于拷贝构造函数,派生类的隐式拷贝构造函数(由编译程序提供)将会调用基类的拷贝构造函数,而派生类自定义的拷贝构造函数在默认情况下则调用基类的默认构造函数,需要时可在派生类自定义构造函数的成员初始化表中显示地指出调用基类的拷贝构造函数。例如:
#include派生类不从基类继承赋值操作。如果派生类没有提供赋值操作重载,则系统会为它提供一个隐式的赋值操作符重载函数,其行为是:对基类成员调用基类的赋值操作符进行赋值,对派生类成员按逐个成员进行赋值。
对于派生类对象,如果系统提供的隐式赋值操作不能满足要求,则要求在派生类中重载赋值操作符“=”。在派生类的赋值操作符重载函数的实现中需要显式地调用基类的赋值操作符来实现基类成员的赋值,例如:
class A
{
......
};
class B:public A
{
......
public:
B & operator =(const B&b)
{
if(&b==this)return *this;//防止自身赋值
*(*A)this = b;//调用基类的赋值操作符对基类成员进行赋值
......
return *this;
}
};
在上面的赋值操作符重载函数中,为了能对基类的数据成员进行赋值,把this指针的类型强制转换成基类的指针,这样通过this指针就能得到基类的子对象,而对基类对象进行赋值操作就会调用基类的赋值操作符函数。
当然,上面对基类成员的赋值操作也可以写成:
this->A::operator =(b);
5.类之间的聚集关系
在面向对象程序设计中,继承不是代码复用的唯一方式,有些代码复用不宜用继承来实现。例如,在飞机类复用发动机类的功能时,由于飞机并不是一种发动机,因此就不宜用继承关系来描述飞机类和发动机类的关系。
类之间除了继承关系外,还存在一种部分与整体的关系(is-part-of),这种关系称为聚集。例如,发动机类与飞机类之间就属于一种部分与整体的关系,一个飞机类的对象包含了一个或多个发动机类的对象。
在聚集中,代码复用是通过在一个类中把另一个类说明成该类的成员对象来实现的。
【例】:利用一个线性表来实现一个队列类
solution 1:利用继承类实现
#includesolution 2:利用聚集来实现(部分功能)
class Queue
{
LinearList list;
public:
void en_queue(int i)
{
list.insert(i, list.GetNum());
return;
}
void de_queue()
{
list.remove(0);
return;
}
};
6.消息(成员函数调用)的动态绑定
C++将类看作类型,将以public方式继承的派生类看作基类的子类型,这样就使得在C++面向对象程序中存在下面三种状态。
1)对象类型的多态
派生类对象的类型既可以是派生类,也可以是基类,即一个对象可以属于多种类型。
2)对象标识的多态
基类的指针或引ta用可以指向或引用基类对象,也可以指向或引用派生类对象,即一个对象标识可以属于多种类型,它可以标识多种对象。在对象标识符定义时指定的类型称为它的静态类型,而在运行时实际标识的对象的类型称为它的动态类型。
3)消息的多态
一个可以发送到基类对象的消息,也可以发送到派生类对象,从而可能得到不同的解释。
上面2)和3)的多态性带来了下面的消息(成员函数调用)绑定问题:
#include对于上面的函数调用func1(b)和func2(&b),在func1和func2中的x.f()和p->f()调用的是A类中的f还是B类中的f?
上述问题存在两种可能的解决方案:
1)采用静态绑定。
在编译时,根据x.p的静态类型来决定f属于哪一个类。由于x和p的静态类型分别是A&和A*,所以在func1(a)和func2(&a)以及func1(b)和func2(&b)的调用中,f都是A::f。
2)采用动态绑定
在运行时,根据x和p的实际引用和指向的对象类型(动态类型)来确定f属于哪一个类。因此,在func1(a)和func2(&a)的调用中,f是A::f;而在func1(b)和func1(&b)的调用中,f是B::f。
而C++是一个注重程序效率的语言,由于采用动态绑定的程序效率有时不高,因此C++默认的绑定方式是静态绑定。对于上面的问题,C++默认采用解决方案1。
运行结果如下:
这是A中的f函数。
这是A中的f函数。
这是A中的f函数。
这是A中的f函数。
7.虚函数与消息的动态绑定
对于上面的问题,在大部分情况下我们需要的是解决方案2的动态绑定效果。为了能对上述func1和func2中的f调用进行绑定,必须在类A的定义中把f声明为虚函数(virtual function):
class A
{
int x, y;
public:
virtual void f() { cout << "这是A中的f函数。" << endl; }
};
这时运行结果如下:
这是A中的f函数。
这是A中的f函数。
这是B中的f函数。
这是B中的f函数。
一旦在基类中指定某成员函数为虚函数,那么,不管在派生类中是否给出virtual声明,派生类(以及派生类的派生类,以此类推)中与其相同型构的成员函数均为虚函数。
对虚函数有下面几点限制:
- 只有类的成员函数才可以是虚函数
- 静态成员函数不能是虚函数
- 构造函数不能是虚函数
- 析构函数可以(往往)是虚函数
为了能对虚函数的动态绑定有一个较全面的掌握,下面的程序给出了虚函数动态绑定的各种情况:
#include关于上面的程序,有两点需要注意:
-
只有通过引用或指针来访问对象类的虚函数时才能进行动态绑定,而通过引用或指针访问对象类的非虚成员函数或通过类名受限来访问虚函数则不采用动态绑定。
-
基类构造函数中对虚函数的调用不采用动态绑定。因为在创建派生类对象时,基类构造函数先于派生类构造函数执行,这样在基类构造函数进行时,派生类中的数据成员还未初始化,这时如果在基类函数中调用派生类的成员函数将会导致对派生类中未初始化的数据进行操作,从而会产生一些不确定的结果,因此,基类构造函数中对虚函数的调用采用静态绑定。
利用虚函数机制,我们可以通过基类的指针或引用来访问派生类中对基类重定义的成员函数。有时,我们需要通过基类的指针或引用来访问派生类中新定义的成员函数,这时,需要采用显示类型转换把基类指针或引用转换成派生类指针或引用。例如:
#include把基类指针或引用强制转换成派生类对象指针是不安全的。例如:如果上面的指针p指向的是A类对象,则下面的操作将导致不属于A类对象内存空间中的内容被修改。
A*p=new A;
((*B)p)->g();//通过B类的y修改了不属于A类对象内存空间中的值
在上面的转换中,把A类对象当作B类对象来使用,从而导致对不属于A类对象内存空间的值的修改。为了防止上面的从基类指针到派生类指针的转换所带来的不安全性问题,可以采用C++的另一种类型转换操作(dynamic_cast)来实现从基类指针到派生类指针的转换:
A* p = new A;
B* q;
q = dynamic_cast<B*>(p);
if (q != NULL)
q->g();
上面的dynamic_cast类型转换操作在进行类型转换时,根据p实际指向的对象类型来判断转换的合法性,如果合法则进行转换并返回转换后的对象地址,否则返回NULL。因此,上面的q将会得到NULL,从而不会调用B类的成员函数g。
8.纯虚函数和抽象类
纯虚函数(pure virtual function)是指只给出函数声明而没给出实现(包括在类定义的内部和外部)的虚成员函数,其格式为:在函数原型的后面加上符号“=0”。例如:
class A//抽象类
{
......
public:
virtual int f()=0;//纯虚函数
......
};
包含纯虚函数的类称为抽象类(abstract class)。由于抽象类包含纯虚函数,因此,抽象类不能用于创建对象。
A a;//ERROR,A是抽象类
抽象类的主要作用在于为派生类提供一个基本框架和一个公共的对外接口,派生类(或派生类的派生类等),应对抽象类基类的所有纯虚成员函数进行实现。
在C++中,对一个类的实例用户来讲,该类的接口就是指定义中声明为public的成员,编译程序能够保证实例用户只能访问这些成员,编译程序能够保证实例用户只能访问这些成员。但是,由于在C++中使用某个类创建对象时必须有该类的定义,因此,该类的非public成员是可见的,这样,有时就能以其他方式绕过类的访问控制而使用类的非public成员,例如:
//A.h
class A
{
int i, j;
public:
A();
A(int x, int y) { i = x; j = y; }
void f(int x);
};
//B.cpp
void func(A* p)
{
p->f(2);//OK
p->i = 1;//ERROR
p->j = 2;//ERROR
*((int*)p) = 1;//OK,访问p所指向的对象的成员i
*((int*)p + 1) = 2;//OK,访问p所指向的对象的成员j
}
上面的问题可以通过给类A提供一个抽象基类来解决,通过这个抽象基类把A的数据表示隐藏了:
//I_A.h
class I_A//A的抽象基类,作为A的对外接口
{
public:
virtual void f(int)=0;
}
//A.cpp
#include"I_A.h"
class A:public I_A
{
int i,j;
public:
A();
A(int x,int y);
void f(int x);
}
对类A的某些实例用户,不再提供原来的类A定义,而只提供其抽象基类I_A的定义(“文件I_A.h”),这样类A的这些实例用户就不知道类A中有什么数据成员了:
//B.cpp
#include"I_A.h"
void func(I_A *p)
{
p->f(2);//OK
......//这里不知道p所指向的对象有哪些数据成员,因此,无法访问它的数据成员
}
9.虚函数动态绑定的一种实现
对于每一个类,如果它有虚函数(包括从基类继承来的),则编译程序将会为其创建一个虚函数表(vtbl),表中记录了该类中所有虚函数的入口地址。当创建一个包含虚函数的类的对象时,在所创建对象的内存空间中有一个隐藏的指针(vptr)指向该对象所属类的虚函数表。例如,对于下面的两个类A和B:
#include对象a和b的内存空间布局如图所示。
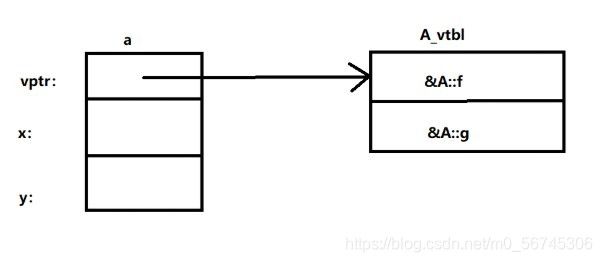
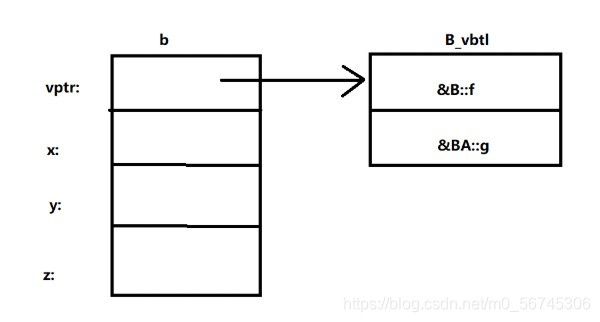
当通过基类的引用或指针来访问基类的非虚成员函数和直接通过对象来访问类的成员函数(包括虚函数)时,则不用虚函数表来进行动态绑定,而是采用静态绑定,例如:
A a;
B b;
A* p;
p->h();//编译成:A::h(p)
a.f();//编译成:A::f(&a)
a.g();//编译成:A::g(&a)
a.h();//编译成:A::h(&a)
b.f();//编译成:B::f(&b)
b.g();//编译成:A::g(&b)
b.h();//编译成:B::h(&b)
10.多继承
多继承是指一个类可以有两个或两个以上的直接基类。
当有一个类需要包括两个或两个以上类的成员时,可以考虑使用多继承。
class A
{
int m;
public:
void fa();
};
class B
{
int n;
public:
void fb();
};
class C :public A, public B
{
int r;
public:
void fc();
};
11.多继承派生类的定义
在定义多继承的派生类时,需要给出两个或两个以上的直接基类,其格式为:
class <派生类名>: <继承方式> <基类名1> <继承方式> <基类名2>
{ <成员说明表>
};
对于多继承,需要说明一下几点:
-
继承方式及访问控制的规定同单继承
-
派生类拥有所有基类的所有成员
-
基类的声明次序决定:
-
对基类的构造函数/析构函数的调用次序。
-
对基类数据成员的存储安排
-
可以把以public继承方式定义的多继承派生类对象的地址赋给任何一个基类的指针,这时将会自动进行地址调整。例如对于上面的例子:
C c;
B *pb = &c;//pb指向对象c内存中B::n的位置
12.命名冲突
在多继承中,当多个基类中包含同名的成员时,它们在派生类中就会出现命名冲突的问题。例如,对于下面的类C,由于它的两个基类中都有函数f,这样,在类C中访问函数f就会出现二义性:
#include在C++中,解决上面问题的办法是采用基类名首先访问:
class C :public A, public B
{
public:
void func()
{
A::f();//OK,调用A的f
B::f();//OK,调用B的f
}
};
C c;
c.A::f();
c.B::f();
13.重复继承——虚基类
在多继承中,如果直接基类有公共的基类,则会出现重复继承(repeated inheritance),这样,公共基类中的数据成员在多继承的派生类中就有多个拷贝。
class A
{
int x;
......
};
class B :public A
{
......
};
class C :public A
{
......
};
class D :public B, public C
{
......
};
对于上面的类D,它拥有两个成员x,即B::x和C::x。
这时它们的关系如下图所示:

通常情况下,我们需要把这两个x合并为一个,这时,应把A定义为B和C的虚基类(virtual base class):
class B :virtual public A
{
......
};
class C :virtual public A
{
......
};
class D :public B, public C
{
......
};
将A定义为B和C的虚基类,它们的关系如下图所示:

这样定义之后,类D就只有一个成员x了。
对于虚基类,应注意以下几点:
- 虚基类的构造函数由最新派生类生出的类的构造函数调用。
- 虚基类的构造函数优先非虚基类的构造函数执行。
例如,对于下面的类A,B,C,D和E:
class A
{
int x;
public:
A(int i) { x = i; }
};
class B :virtual public A
{
int y;
public:
B(int i) :A(1) { y = i; }
};
class C :virtual public A
{
int z;
public:
C(int i) :A(2) { z = i; }
};
class D :public B, public C
{
int m;
public:
D(int i, int j, int k) :B(i), C(j), A(3) { m = k; }
};
class E :public D
{
int n;
public:
E(int i, int j, int k, int l) :D(i, j, k), A(4) { n = l; }
};
D d(1, 2, 3);//这里,D是最新派生出来的类,A的构造函数由D调用,d.x初始化为3
E e(1, 2, 3, 4);//这里,E是最新派生出来的类,A的构造函数由E调用,e.x初始化为4
当创建D类对象d时,所调用的构造函数以及它们的执行次序为:
A(3)、B(1)、C(2)、D(1,2,3)
当创建E类对象e时,所调用的构造函数以及它们的执行次序为:
A(4)、B(1)、C(2)、D(1,2,3)、E(1,1,3,4)
ges\image-20210718223209547.png" alt=“image-20210718223209547” style=“zoom:67%;” />
通常情况下,我们需要把这两个x合并为一个,这时,应把A定义为B和C的虚基类(virtual base class):
class B :virtual public A
{
......
};
class C :virtual public A
{
......
};
class D :public B, public C
{
......
};
将A定义为B和C的虚基类,它们的关系如下图所示:
[外链图片转存中…(img-rmIkRlNC-1626619414270)]
这样定义之后,类D就只有一个成员x了。
对于虚基类,应注意以下几点:
- 虚基类的构造函数由最新派生类生出的类的构造函数调用。
- 虚基类的构造函数优先非虚基类的构造函数执行。
例如,对于下面的类A,B,C,D和E:
class A
{
int x;
public:
A(int i) { x = i; }
};
class B :virtual public A
{
int y;
public:
B(int i) :A(1) { y = i; }
};
class C :virtual public A
{
int z;
public:
C(int i) :A(2) { z = i; }
};
class D :public B, public C
{
int m;
public:
D(int i, int j, int k) :B(i), C(j), A(3) { m = k; }
};
class E :public D
{
int n;
public:
E(int i, int j, int k, int l) :D(i, j, k), A(4) { n = l; }
};
D d(1, 2, 3);//这里,D是最新派生出来的类,A的构造函数由D调用,d.x初始化为3
E e(1, 2, 3, 4);//这里,E是最新派生出来的类,A的构造函数由E调用,e.x初始化为4
当创建D类对象d时,所调用的构造函数以及它们的执行次序为:
A(3)、B(1)、C(2)、D(1,2,3)
当创建E类对象e时,所调用的构造函数以及它们的执行次序为:
A(4)、B(1)、C(2)、D(1,2,3)、E(1,1,3,4)