vtk教程第八章 高级数据表示
本章讨论数据表示中的高级主题。主题包括拓扑和几何关系和计算方法的单元格和数据集。
8.1坐标系
我们将研究三种不同的坐标系:全局坐标系、数据集坐标系和结构化坐标系。图8 - 1展示了全局坐标系和数据集坐标系之间的关系,并描绘了结构化坐标系。全球坐标系全球坐标系是一个笛卡尔的三维空间。每个点都表示为沿着x、y和z轴的值的三元组(x、y、z)。这与第三章中描述的系统是相同的(参见46页的“坐标系”)。
全局坐标系总是用于指定数据集的几何形状(即点坐标)和数据属性,如法线和向量。我们将使用“位置”一词来表示我们使用的是全局坐标。
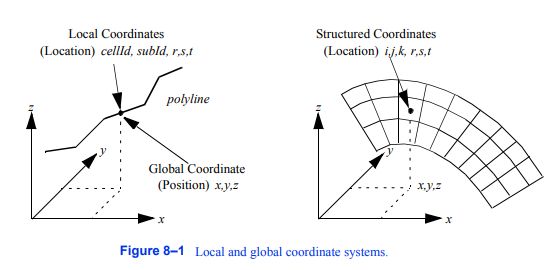
图8-1局部坐标系和全局坐标系。
数据集坐标系
数据集或局部坐标系统基于拓扑坐标和几何坐标的组合。拓扑坐标用于标识特定的单元格(或者可能是子单元格),几何坐标用于标识单元格内的特定位置。它们一起唯一地指定了数据集中的一个位置。这里我们将使用“位置”一词来指代本地或数据集坐标。拓扑坐标是一个“id”:一个唯一的非负整数,指向数据集点或单元格。对于复合单元格,我们使用额外的“子id”来指代组成复合单元格的特定主单元格。子id也是唯一且非负的。id和子id一起选择一个特定的主单元格。为了在主单元格中指定位置,我们使用几何坐标。这些几何坐标,或参数坐标,是“自然的”坐标或规范的特定拓扑和维度的单元。我们可以通过一个例子来最好地解释局部坐标。如果我们考虑图8 - 1所示的折线单元格类型,我们可以通过以下方式指定点的位置:1)折线单元格id, 2)主单元格(即线)子id和3)线的参数坐标。因为直线是一维的,所以自然坐标或参数坐标是基于一维参数r的。那么沿着直线的任何点都是由直线的两个端点和的线性组合给出的
其中参数坐标r被限制在(0,1)之间。在这个方程中,我们假设子id等于i。
参数坐标的数量对应于单元格的拓扑维度。三维单元格将由三个参数坐标(r, s, t)来表征。对于拓扑顺序小于3的单元格,我们将忽略最后一个(3 - n)参数坐标,其中n是单元格的拓扑顺序。为了方便和一致性,我们还将每个参数坐标限制在(0,1)之间。
每个单元格类型都有自己的参数坐标系。在本章后面,我们将详细描述参数坐标系。但首先我们要研究另一个坐标系,结构化坐标系。
结构化坐标系统
许多数据集类型是结构化的。这包括图像数据和结构化网格。由于其固有的结构,它们有自己的自然坐标系。这个坐标系统是基于我们在第5章中提到的i-j-k索引方案(参见第136页的“图像数据”)。
结构化坐标系统是描述结构化数据集组件的自然方式。通过固定一些指标,并允许其他指标在有限的范围内变化,我们可以指定点、线、面和体积。例如,通过固定i索引i = i0,并允许j和k索引在它们的最小值和最大值之间,我们指定了一个曲面。如果我们固定三个指标,我们指定一个点,如果我们固定两个指标,我们指定一条线,如果我们允许三个指标变化,我们指定一个体积(或子体积)。结构化坐标系通常用于指定感兴趣的区域(或ROI)。感兴趣的区域是我们想要可视化或操作的区域。
在数据集坐标系和结构化坐标系的点和单元格id之间有一个简单的关系。得到一个给定指标和维数的点id pid
用,,。(我们可以使用这个id为点数组或点属性数据建立索引。)这个方程隐含地假设了拓扑空间中点的顺序。
沿i轴的点变化最快,其次是j轴,然后是k轴。单元格id也存在类似的关系
在这里,我们已经考虑到每个拓扑轴上的细胞比点少一个。
8.2插值函数
计算机可视化处理离散数据。数据要么在有限数量的点上提供,要么通过在有限数量的点上采样连续数据来创建。但我们通常需要的信息不是这些离散点的位置。这可能用于在算法执行期间呈现数据或对数据进行子采样。我们需要使用插值函数将数据从已知点插值到某个中间点。
插值函数将单元格点上的值与单元格内部关联起来。因此,我们假设信息是在单元格点上定义的,并且我们必须从这些点开始进行插值。我们可以将结果表示为每个单元格点上数据值的加权平均值。
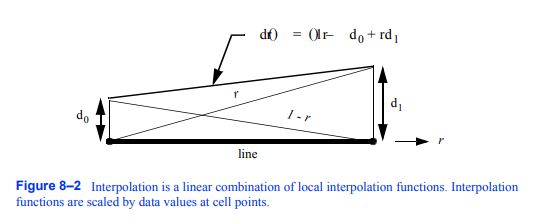
图8-2插值是局部插值函数的线性组合。插值函数按单元格点上的数据值进行缩放。
一般形式
为了将数据从单元格点pi插值到单元格内的点p,我们需要三个信息:
1. 每个单元格点的数据值,
2. 单元格内点p的参数坐标,和
3.包含插值函数的单元格类型。
给定这些信息,插值函数是单元格点上数据值的线性组合

其中d是内部单元位置(r,s,t)的数据值,di是第i个单元点的数据值,Wi是第i个单元点的权重。插值权值是参数坐标Wi = W(r,s,t)的函数。此外,由于我们希望当内点与单元格点重合时d = di,我们可以对权重施加额外的约束
我们还希望插值的数据值d不小于最小di,也不大于最大di。因此,权重也应满足

插值函数具有特征形状。它们在单元格点达到最大值Wi = 1,在所有其他点都为零。检查公式8-1,我们画出图8- 2,看到每个插值函数都有一个尖顶的“帽子”形状,插值是这些帽子函数的线性组合,按每个点的数据值缩放。
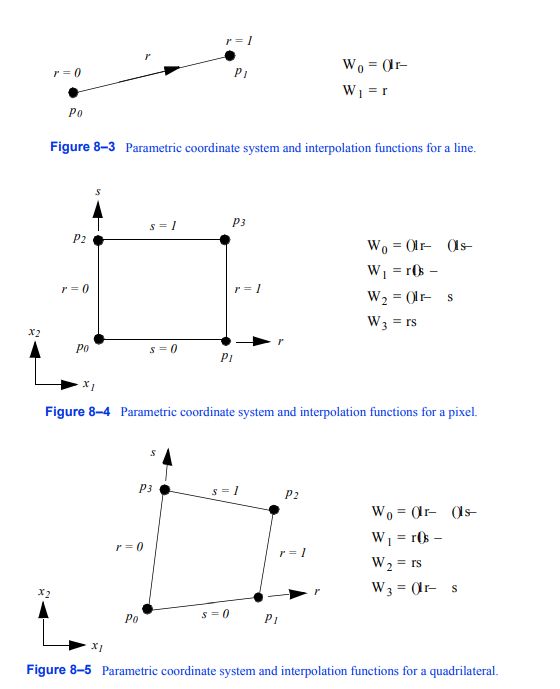
图8-3直线的参数坐标系和插值函数
图8-4像素的参数坐标系和插值函数。
图8-5四边形的参数坐标系和插值函数。
公式8-4是单元插值的一般形式。它用于将单元格点上定义的任何数据值内插到单元格内的任何其他点。我们只需为每种单元类型定义特定的插值函数Wi。
特殊的形式
每个单元格类型都有自己的插值函数。权重Wi是参数坐标r、s和t的函数。在本节中,我们将定义参数坐标系并进行插值
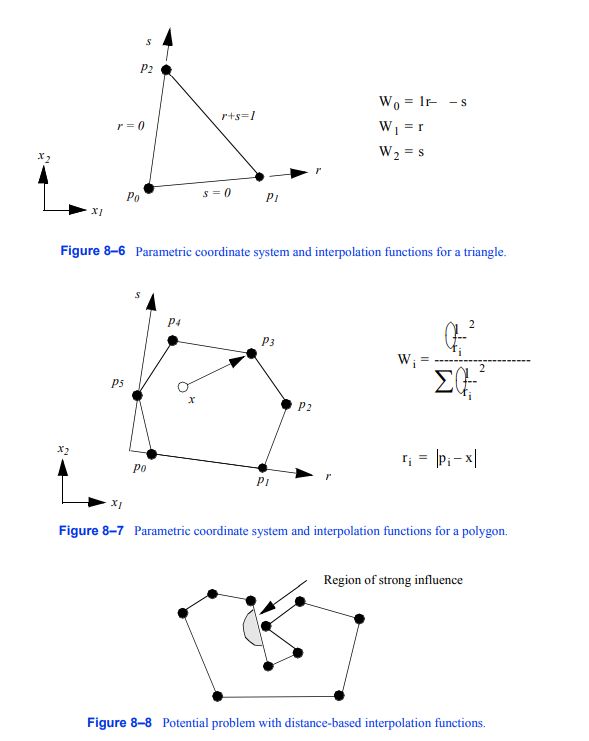
图8-6三角形的参数坐标系和插值函数
图8-7多边形的参数坐标系和插值函数。
图8-8基于距离的插值函数的潜在问题。
Tion功能为每个初级细胞类型。复合单元格使用它们组成的主单元格的插值函数和参数坐标。主单元格和复合单元格在坐标系规范上的唯一区别是,复合单元格使用额外的子id来指定特定的主单元格。
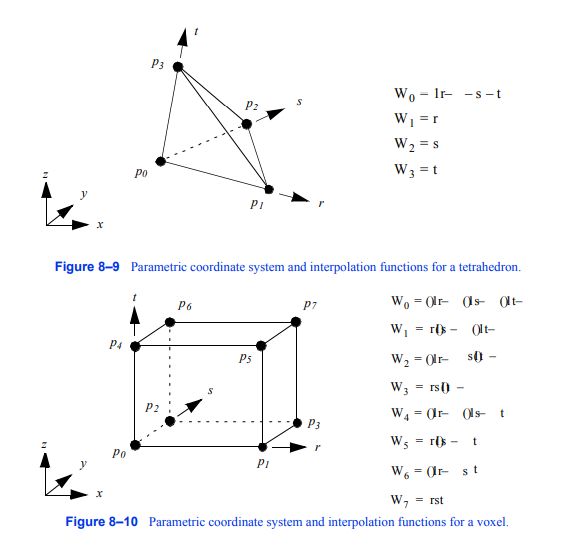
图8-9四面体的参数坐标系和插值函数。
图8-10体素的参数坐标系和插值函数。
顶点。顶点单元格不需要参数坐标或插值函数,因为它们是零维的。单权函数为W0 = 1。
线。图8 - 3给出了直线的参数坐标系和插值函数。直线用单参数坐标r.
Pixel表示。图8 - 4显示了像素单元类型的参数坐标系和插值函数。像素用两个参数坐标(r,s)来描述。注意,像素边缘被限制平行于全局坐标轴。这些通常被称为双线性插值函数。
四边形。图8 - 5显示了一个四边形单元类型的参数坐标系和插值函数。四边形用两个参数坐标(r,s)来描述。
三角形。图8 - 6显示了三角形单元格类型的参数坐标系和插值函数。三角形用两个参数坐标(r,s)来表示。

图8-11六面体的参数坐标系和插值函数。
图8-12楔体参数坐标系及插补函数
多边形。图8 - 7显示了多边形单元类型的参数坐标系和插值函数。多边形用两个参数坐标(r,s)来表示。参数坐标系是通过创建一个沿多边形第一个边方向的矩形来定义的。矩形也必须与多边形结合。
多边形提出了一个特殊的问题,因为我们不知道有多少顶点定义多边形。因此,不可能以我们前面看到的函数的方式来创建一般的插值函数。相反,我们使用一个基于每个多边形顶点的加权距离平方的函数。
加权距离平方插值函数在实际应用中效果良好。然而,在某些罕见的情况下,在拓扑上远离多边形内部的点对多边形内部有不适当的影响(图8 - 8)。这些情况只发生在多边形是凹的并缠绕在自己身上的情况下。

图8-13金字塔的参数坐标系和插值函数。
图8-14五角形棱镜的参数坐标系和插值函数。

图8-15六棱柱的参数坐标系和插值函数
图8-16二次边的参数坐标系和插值函数。
四面体。图8 - 9显示了一个四面体单元类型的参数坐标系和插值函数。四面体用三个参数坐标(r,s,t)来描述。
体素。图8 - 10显示了体素单元类型的参数坐标系和插值函数。体素使用三个参数坐标(r,s,t)来描述。注意,体素边被限制平行于全局坐标轴。这些通常被称为三线性插值函数。

图8-17二次三角形的参数坐标系和插值函数。
图8-18二次四边形的参数坐标系和插值函数。在VTK中,参数坐标(r,s)运行于(0,1)之间,因此坐标系统转换为从(-1,1)开始的参数系统。注意并参考第i点的参数坐标。
六面体。图8 - 11显示了六面体单元类型的参数坐标系和插值函数。六面体用三个参数坐标(r,s,t)来描述。
楔。图8 - 12显示了楔形单元类型的参数坐标系和插值函数。楔形用三个参数坐标(r,s,t)来描述。金字塔。图8 - 13显示了金字塔细胞类型的参数坐标系和插值函数。金字塔用三个参数坐标(r,s,t)来描述。五角棱镜。图8 - 14显示了一个五边形棱柱单元类型的参数坐标系和插值函数。五角形棱镜用三个参数坐标(r,s,t)来描述。

图8-19二次四面体的参数坐标系和插值函数。在VTK中,参数坐标(r,s,t)运行于(0,1)之间,因此坐标系统转换为从(-1,1)开始的参数系统。
图8-20二次六面体的参数坐标系和插值函数。在VTK中,参数坐标(r,s,t)运行于(0,1)之间,因此坐标系统转换为从(-1,1)开始的参数系统。注意,并参考第i点的参数坐标。

六方柱。图8-21二次楔的参数坐标系和插值六角棱镜。图8 - 15显示了六边形棱镜单元类型的参数坐标系和插值函数。六边形棱镜用三个参数坐标(r,s,t)来描述。
二次边。图8 - 16显示了二次型边缘单元的参数坐标系和插值函数。二次边用单参数坐标r.
二次三角形来描述。图8 - 17显示了二次三角形单元格类型的参数坐标系和插值函数。二次三角形用两个参数坐标(r,s)来描述。
二次四边形。图8 - 18显示了二次四边形单元类型的参数坐标系和插值函数。二次四边形用两个参数坐标(r,s)来描述。请注意,由于插值函数最容易在区间(-1,1)中表示,因此坐标移位将执行到该范围内定义的坐标。同时,还介绍了符号和。这些是第i点的参数坐标。
函数

图8-22二次金字塔的参数坐标系和插值函数。在
VTK参数坐标(r,s,t)运行在(0,1)之间,因此坐标系移到
参数系统范围为(-1,1)。注意,并参考第i点的参数坐标。
二次四面体。图8 - 19显示了二次四面体单元类型的参数坐标系和插值函数。二次四面体用三个参数坐标(r,s,t)来描述。
二次六面体。图8 - 20显示了二次六面体单元类型的参数坐标系和插值函数。二次六面体用三个参数坐标(r,s,t)来描述。请注意,由于插值函数最容易在区间(-1,1)中表示,因此坐标移位将执行到该范围内定义的坐标。同时,还介绍了符号和。这些是第i点的参数坐标。
二次楔。图8 - 21显示了二次楔形单元类型的参数坐标系和插值函数。二次楔是使用三个参数描述的坐标(r、s、t)
二次金字塔。图8 - 22显示了二次金字塔单元类型的参数坐标系和插值函数。二次金字塔用三个参数坐标(r,s,t)来描述。请注意,由于插值函数最容易在区间(-1,1)中表示,因此坐标移位执行到该范围内定义的坐标系。另外,我们还介绍了符号,这些是第i点的参数坐标。(形状函数和导数的实现要感谢航空航天结构中心http://www.colorado.edu/engineering/CAS。)
8.3单元格镶嵌
正如第五章所简要介绍的,非线性单元常用于各种数值技术,如有限元法。虽然一些可视化系统直接支持非线性单元格,但通常只支持二次公式和偶尔的三次公式(例如,VTK支持二次单元格)。这只代表了目前在数值包中可用的公式的一个小子集,并忽略了无限潜在的细胞公式。为了解决这个重要的问题,可视化系统可以提供一个适配器框架(见图8 - 23),使用户能够将他们自己的仿真系统与可视化系统连接起来[Schroeder06]。这样的框架需要编写从可视化数据集和单元基类派生的适配器类(在图中它们被标记为GenericDataSet和GenericAdaptorCell)。这些适配器就像翻译器一样,将数据和方法调用转换成可视化系统和数值系统所期望的形式。像任何其他数据对象一样,这种适配器单元和数据集可以通过可视化算法直接处理。然而,处理这样的一般数据对象是一个困难的问题,因为迄今为止科学文献中描述的大多数可视化算法都采用了单元几何是线性的基本假设。消除这种假设可能需要在算法中引入显著的复杂性,甚至可能需要一种新的算法。例如,移动立方体等轮廓算法假设单元格为正交直线型六面体;如果没有这个假设,就需要在参数坐标系和全局坐标系之间进行复杂的转换,即使在高度弯曲的非线性单元中,也可以在没有广泛的拓扑和几何检查的情况下生成简并或自交等等值线。因此,适配器框架通常包括将非线性单元格镶嵌到熟悉的线性单元格的方法,然后可以很容易地用传统的可视化算法处理线性单元格。在下一节中,我们简要地描述了一种将高阶非线性单元格镶嵌生成线性单元格的简单方法。
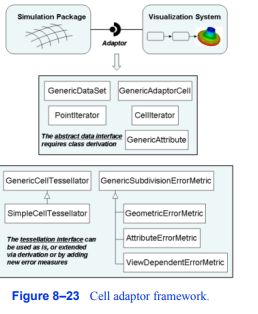
图8-23 Cell适配器框架
基本方法
基本方法是动态地对GenericDataSet的单元格进行镶嵌,然后对得到的线性镶嵌进行操作。在伪代码中,一个典型的算法是这样的:

重要的是不要一次对整个数据集进行细分,因为这可能会对内存资源产生过多的需求,而且许多算法只访问数据集单元格的一个子集。因此,上面的伪代码指的是一个选择标准,它取决于算法的性质。例如,等等值线算法可以检查单元格的标量值是否跨越当前等等值线值。
虽然有许多镶嵌算法是可能的,但那些基于边缘细分的算法特别简单。算法背后的思想很简单:每个单元格边e是
基于单元拓扑结构和需要细分的特定边,使用模板对单元进行细分。这个过程继续递归,直到所有边的误差指标都满足。该算法的一个优点是单元格可以独立地镶嵌。这是因为边缘细分是一个或多个误差测量的函数,只考虑沿边缘的信息,而不需要考虑单元格信息。因此,不需要跨单元边界通信,该算法非常适合并行处理和在遍历期间访问单元时的动态镶嵌。
单元格细分的一些模板如图8 - 24所示。请注意,在某些情况下,必须选择用于镶嵌的对角线(例如,图8 - 24 (b)中的虚线)。在2D中,这个选择可以任意做出,但是在3D中,这个选择必须与单元格的面部邻居一致。为了保持算法的简单性,包括避免细胞间通信,采用简单的领带打破规则来选择三维细胞表面的对角线。这些规则包括使用最短对角线(在全局坐标系中测量),或使用基于选择具有最小点id的对角线的拓扑决定器。(当几何距离测量不确定时,拓扑决定器是必要的。)
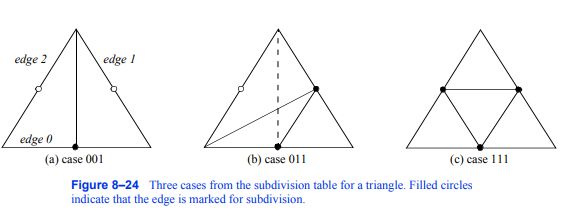
图8-24三角形细分表中的三种情况。填充的圆圈表示边缘被标记为细分。
人为失误控制措施
上述算法是自适应的,因为边缘分割是由局部网格属性和/或它与视图位置的关系控制的。由于目标是确保镶嵌的质量与可视化的特定要求相一致,我们期望与具有相同数量简式的固定细分相比,经过调整的镶嵌具有更好的质量,或者对于相同质量的镶嵌具有更少的简式。
我们的设计允许定义多种误差测量。如公式8- 7所示,误差度量由几个误差度量组成,每个度量相对于线性近似评估边缘的局部属性,并将度量与用户指定的阈值进行比较。如果任何测量值超过阈值,则对边缘进行细分。这些误差测量可能评估几何属性、对解属性的近似,或与当前视图相关的错误,以及其他可能性。基于几何或属性的误差测量是独立于视图的,网格只需要一个初始镶嵌。
下面几段描述了在实践中被发现有用的几种误差测量方法。由于tessellator被设计用于处理错误度量的列表,因此可以直接添加新的度量(通过从GenericSubdivisionErrorMetric类派生)和/或将其与现有的错误度量结合起来。
•基于对象的几何误差测量。如图8 - 25(左)所示,该误差测量值为从边缘中心点C到穿过单元格边缘顶点(A和B)的直线的垂直距离d。注意,d是在世界坐标中计算的,而C是在边缘的参数中心计算的。使用垂直距离而不是C和D之间的距离,因为如果C位于(AB)上,但与D不重合,则误差非零,导致许多无用的边缘细分。边0边2边1边(a) case 001边(b) case 011边(c) case 111图8-24三角形细分表中的三种情况填充的圆圈表示边缘被标记为细分。图8-25几何误差和属性误差定义高级数据表示
•基于对象的平面度误差测量。这个误差测量是弦(AC)和弦(CB)通过真实中点c的夹角。当夹角接近180°时,边缘变得平坦。阈值是边缘被视为平坦的角度。
•基于属性的错误测量。如图8 - 25(右)所示,该误差度量是某属性在边缘中点处线性插值值与该属性在边缘中点处实际值之间的距离。
•基于图像的几何误差测量。该误差测量是投影在图像空间中的直线(AB)与同样投影在图像空间中的中点C之间的距离,单位为像素。因为计算涉及到通过当前相机矩阵的投影,所以这个误差测量是依赖于视图的。因此,在远离相机的部分网格中,镶嵌可能是粗糙的。请注意,这种方法的缺点之一是,每次相机相对于网格重新定位时,都可能需要镶嵌。

图8-25几何误差和属性误差定义
先进的科技技术
细心的读者会注意到,前面描述的细分方案可能无法捕获高阶基的所有特征。例如,想象一个跨越三角形的标量函数,其中函数的峰值出现在三角形的中心,并且通过边缘的变化为零。前面描述的边缘细分算法不会捕获峰值,因此等轮廓等算法将产生不准确的结果。线性等轮廓算法要求满足以下条件,以产生正确的拓扑结果。
•每条网格边缘与某一特定值的等等值线相交最多一次,
•没有等等值线与网格面相交而不与至少两条边相交,并且
•没有等等值线完全包含在单个元素中。
根据定义,这些条件与临界点直接相关,因为一个可微函数在开域中的极值必然是一个临界点。线性网格假定标量场的所有极值都出现在元素顶点上,但通常当使用高阶基时,情况并非如此,极值可以在单元格内部找到。
为了解决这个问题,必须对基底进行预三角剖分。预三角剖分必须识别细胞内部、表面或边缘的所有临界点,然后将这些点插入三角剖分。例如,可以先执行基于高阶单元格顶点的初始三角剖分,然后使用Delaunay三角剖分或等效方法插入三角剖分(参见345页的“三角剖分”)。预三角剖分之后,可以使用之前提出的基于边缘的标准算法。
8.4坐标变换
坐标变换是一种常见的可视化操作。这可能是从数据集坐标到全局坐标的转换,也可能是从全局坐标到数据集坐标的转换。
数据集到全局坐标
在数据集坐标和全局坐标之间转换非常简单。首先使用单元格id和子id标识主单元格。然后利用公式8-4中的插值函数,由参数坐标生成全局坐标。给定单元格点pi = pi(xi, yi, zi)全局坐标p就是
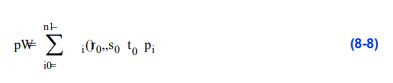
其中插值权值Wi在参数坐标处求值。
在这里提出的公式中,我们对数据和单元几何使用了相同的顺序插值函数。(我们所说的顺序是指插值多项式的多项式次。)这被称为等参数插值。可以对几何图形和数据使用不同的插值函数。超参数插值用于几何插值函数的阶数大于数据插值函数的阶数。当几何插值函数的顺序小于数据插值函数的顺序时,使用次参数插值。使用不同的插值函数是常用的数值分析技术,如有限元法。在可视化应用中,我们总是使用等参数插值。
全局到数据集坐标
与数据集到全局坐标相比,全局到数据集坐标的转换成本较高。这有两个原因。首先,我们必须确定包含全局点p的特定单元Ci。其次,我们必须求解公式8-4中p的参数坐标。
识别单元Ci意味着进行某种形式的搜索。一种简单但效率低的方法是访问数据集中的每个单元格,并确定p是否位于任何单元格中。如果是,那么我们已经找到了正确的单元格,并停止搜索。否则,我们检查列表中的下一个单元格。
这种简单的技术对于大数据来说速度不够快。相反,我们使用加速搜索技术。它们基于空间组织结构,如八叉树或三维哈希表。其思想如下:我们创建许多“桶”或数据占位符,通过它们在全局空间中的位置来访问它们。在每个桶内,我们标记部分或完全位于桶内的所有点或单元格。然后,为了找到包含点p的特定单元格,我们找到包含p的存储单元,并获得与该存储单元相关联的所有单元格。然后我们计算这个缩略单元格列表的inside/outside,以找到包含p的单个单元格。(更详细的描述请参见292页的“搜索”。)
全局到数据集坐标转换代价昂贵的第二个原因是,我们必须求解p的参数坐标的插值函数。有时我们可以分析地做到这一点,但在其他情况下,我们必须使用数值技术求解参数坐标。
考虑一条直线的插值函数(图8 - 2)。我们可以精确地解出这个方程

类似的关系存在于任何单元,其插值函数是参数坐标的线性组合。这包括顶点、直线、三角形和四面体。四边形和六面体插值函数是非线性的,因为它们是参数坐标线性表达式的产物。因此,我们必须借助数值技术来计算全局到数据集的坐标转换。像素和体素的插值函数也是非线性的,但由于它们相对于x、y和z坐标轴的特殊方向,我们可以精确地求解它们。(我们将在第295页的“图像数据的特殊技术”中更深入地讨论像素和体素类型。)
为了求解参数坐标的插值函数,我们必须使用非线性技术来求解方程组。一种简单有效的方法是牛顿法[Conte72]。
为了使用牛顿方法,我们首先用插值函数Wi = Wi(r,s,t)定义已知全局坐标p = p(x,y,z)的三个函数

然后,用泰勒级数近似展开函数,
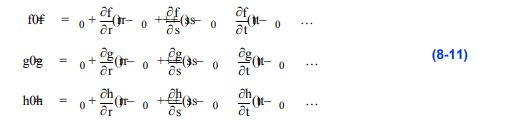
我们可以开发一个迭代过程来求解参数坐标。这就得到了一般形式

幸运的是,牛顿的方法是二次收敛的(如果它收敛的话),我们在这里提出的插值函数表现良好。在实践中,公式8-12在几次迭代中收敛。

图8-26计算一维线单元的导数
8.5导数计算
插值函数使我们能够计算单元内任意位置的数据值。它们还允许我们计算数据值的变化率或导数。例如,给定单元点的位移,我们可以计算单元应变和应力,或者,给定压力值,我们可以计算指定位置的压力梯度。
为了介绍这个过程,我们将从研究最简单的情况开始:计算一维线上的导数(图8 - 26)。利用几何参数,我们可以计算r参数空间中的导数,根据

其中si是点i处的数据值。在与r坐标系平行的局部坐标系中(即沿着向量),其导数为

l是直线的长度。
推导公式8-14的另一种方法是使用图8- 3中的插值函数和导数的链式法则。链式法则
允许我们用

通过插值函数,我们可以计算出关于r的导数
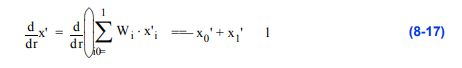
当结合方程8-16和方程8-13求s导时,得到
Equation8-14。
还有最后一步。坐标系中的导数必须转换为全局的x-y-z系统。我们可以通过创建一个单位向量

其中和为直线两端的位置。然后在x, y和z方向上的导数可以通过沿轴的点积来计算。

为了总结这个过程,导数计算在局部r-s-t参数空间使用单元插值。然后它们被转换成一个局部笛卡尔系统。然后,如果
如果系统未与全局坐标系对齐,则需要进行另一次转换以生成结果。
我们可以把这个过程推广到三维空间。用偏导的链式法则
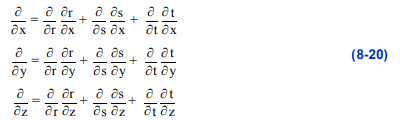
或者重新整理后
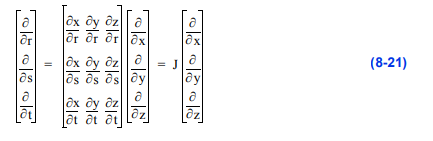
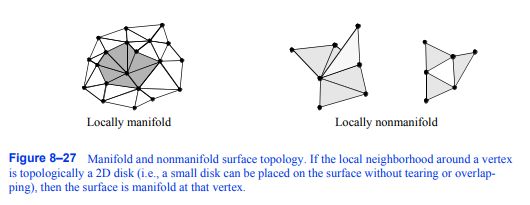
图8-27流形和非流形表面拓扑如果一个顶点周围的局部邻域在拓扑学上是一个二维磁盘(即,一个小磁盘可以放在表面上而不撕裂或重叠),那么该顶点的表面是流形的
矩阵J称为雅可比矩阵,它将参数坐标导数与全局坐标导数联系起来。我们可以把8-21式改写成更紧凑的形式

通过求雅可比矩阵的逆来求全局导数

只要参数坐标系和全局坐标系一一对应,雅可比矩阵的逆就始终存在。这意味着对于任何(r, s, t)坐标,只有一个(x, y, z)坐标对应。这适用于任何参数坐标系在这里提出,只要病理条件,如细胞自我交叉或细胞折叠在自己是避免。(单元格折叠的一个例子是当一个四边形变成非凸的时候。)
在一维的例子中,沿直线的导数是常数。然而,其他方面
8.6拓扑操作
许多可视化算法需要关于单元格或数据集的拓扑信息。提供这种信息的操作称为拓扑操作。这些操作的示例包括获取单元格的拓扑维度,或访问共享公共边或面的相邻单元格。我们可以使用这些操作来决定是渲染一个单元格(例如,只渲染一维线),还是通过流场传播粒子(例如,穿过公共边界遍历单元格)。
在继续之前,我们需要定义一些拓扑学术语。流形拓扑描述了围绕拓扑连接的点的区域。也就是说,点周围的区域在拓扑上等价于一个小的“圆盘”(二维)或“球”(三维)。非流形的拓扑称为非流形。流形和非流形几何的例子如图8 - 27所示。

图8-28三维及以下的简化图。
我们可以使用一些简单的规则来确定一个近似于单元格的表面或区域是流形还是非流形。在二维空间中,如果一个二维单元的每条边都被另一个单元使用,那么这个平面就是局部流形的。在三维空间中,如果一个三维单元的每一个面都恰好被另一个单元使用,则该区域是局部流形的。
在某些情况下,我们也会使用术语单纯形。维数n的单纯形是由n+1个独立点的集合定义的凸区域。顶点、直线、三角形和四面体分别为0、1、2和3维的简简体,如图8 - 28所示。
单元操作
单元格操作返回关于单元格拓扑结构的信息。通常,我们想知道单元的拓扑顺序或单元边界的拓扑结构。
给定一个拓扑维数为d的胞元Ci,该胞元(隐式)由拓扑阶为d-1及以下的边界胞元组成。例如,一个四面体由四个二维三角形、六条一维边和四个零维顶点组成。单元格操作返回关于特定拓扑维度的边界单元数的信息,以及定义每个边界单元的有序点列表。
另一个有用的单元格操作返回维度为d-1的最近边界单元格,给定单元格的参数坐标。与参数坐标系相比,该操作将几何图形绑定到单元的拓扑,而参数坐标系将拓扑绑定到几何图形。最接近的边界单元操作是通过将每个单元划分为不同的区域来实现的,如图8 - 29所示。为了确定最近的边界单元,我们只需要确定点所在的参数区域,然后返回适当的边界单元。
另一个有用的单元格操作是将单元格分解为简体。每个单元格都可以分解为简单体的集合。通过这样做,并通过操作单纯形分解而不是单元本身,我们可以创建独立于单元类型的算法。例如,如果我们想要交叉两个不同单元类型的数据集,如果没有单纯形分解,我们就必须创建方法来交叉每个可能的单元组合。通过单纯形分解,我们可以创建一个交集操作,该操作只对有限的单纯形集进行操作。这种方法的显著优点是,当新的单元格被添加到可视化系统中时,只有单元格对象(包括它的单纯形分解方法)必须实现,而不需要修改其他对象。
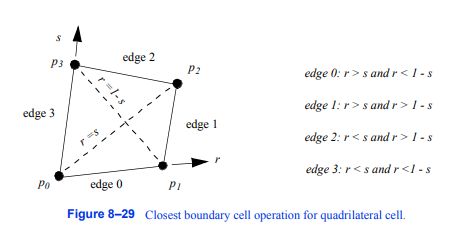
图8-29四边形单元格的最近边界单元格操作。
数据集操作
数据集操作返回关于数据集的拓扑信息或关于单元邻接关系的拓扑信息。典型的操作包括确定单元格的邻居或返回使用特定点的所有单元格的列表。
我们可以通过继续讨论124页的“单元格类型”来形式化邻接操作。邻接方法用于获取单元的邻居信息。一个特定单元Ci的邻居仅仅是一个与Ci有一个或多个共同点的单元。顶点邻居是共享一个或多个顶点的邻居。边邻居是共享一条或多条边的邻居。面邻居是一个单元格,共享定义单元格的一个面的顶点。注意,面邻居也是边邻居,边邻居也是顶点邻居。
邻接操作符是简单的集合操作。对于一个由点定义的特定单元Ci
和点列表,其中通常对应于定义Ci的边界单元的点;Ci的邻居是邻接集。邻接集就是每个点的使用集的交集,不包括单元格
邻接集表示各种有用的信息。例如,在由多面体表示的流形对象中,每个多边形的每条边都必须有一个相邻边。没有邻居的边是边界边;具有多个边邻居的边表示非流形拓扑。由三维单元格(例如,非结构化网格)组成的数据集在拓扑上是一致的,只有当每个单元格的每个面都有一个面邻居时。没有邻居的脸在数据集的边界上。多个面邻居意味着邻居是自相交的(在三维空间中)。
8.7搜索
搜索是查找包含指定点p的单元格的操作,或者查找p周围区域内的单元格或点的操作。需要此操作的算法包括流线生成,我们需要在单元格内找到起始位置;探测,其中在某一点上的数据值从包含单元内插;或者碰撞检测,即必须对特定区域中的单元格进行交叉评估。有时(例如,图像数据集),由于数据的规律性,搜索是一个简单的操作。然而,在结构化程度较低的数据中,搜索操作更加复杂。
要找到包含p的单元格,可以使用下面的简单搜索过程。遍历数据集中的所有单元格,找到包含p的单元格(如果有的话)。为了确定一个单元格是否包含一个点,对参数坐标(r,s,t)计算单元格插值函数。如果这些坐标在单元格内,那么p也在单元格内。这里的基本假设是单元格不重叠,因此最多一个单元格包含给定点p。为了确定位于p周围区域的单元格或点,我们可以遍历单元格或点,看看它们是否位于p周围的区域内。例如,我们可以选择将该区域定义为以p为中心的球体。那么,如果一个点或组成单元格的点位于球体内,点或单元格被认为在p周围的区域内。
除了最小的数据集,这些简单的过程是不可接受的,因为它们是O(n)阶的,其中n是单元格或点的数量。为了提高搜索性能,我们需要引入补充的数据结构来支持空间搜索。这样的结构是众所周知的,包括MIP映射、八叉树、kd树和二叉球树(见本章末尾第315页的“书目注释”)。
这些空间搜索结构背后的基本思想是将搜索空间细分为更小的部分或桶。每个存储桶包含其中的点或单元格的列表。桶以结构化的方式组织,因此可以在常量或对数时间内访问任何桶。例如,如果我们将2D欧几里得空间的一部分分配到一个由n * m个桶组成的网格中,p在特定桶中的位置可以通过两个减法和两个除法确定:一个常数时间访问。类似地,p在非均匀细分八叉树中的位置是在对数时间内确定的,因为需要递归插入到八叉子树中。一旦找到bucket,搜索就被限制在其中包含的点或单元格。在一个合理设计的空间搜索结构中,一个桶中的点或单元格的数量是单元格总数的一小部分,小于一个固定值。因此,在桶内搜索的时间可以由一个固定的常数限定。结果是,引入空间搜索结构将搜索时间减少到最大O(log n),或者更好的是O(n)。
在应用空间搜索结构时,我们有两种选择。我们可以在搜索结构中插入点,也可以插入单元格,这取决于应用程序。这两种方法各有优缺点。将单元格插入存储桶并不是一个简单的操作。一般来说,单元格的方向和形状是任意的,不会完全放入单个桶中。因此,单元格通常跨越多个存储桶。要可靠地确定单元格是否在bucket中,需要进行几何相交测试,这是一项成本高昂的操作。另一种方法是使用单元格的边界框来确定单元格属于哪个bucket。我们只需要将边界框与桶相交来确定单元格是否属于桶。不幸的是,尽管这个操作通常很快,但单元格通常与存储桶相关联,尽管它们实际上可能不在存储桶中,这会浪费(在大型模型中)内存资源和额外的处理时间。

图8-30使用搜索结构(含点)查找单元格(a)点与适当的桶相关联。点p用于索引桶,并找到最近的点(s)。使用pi的单元格对包含p的单元格进行评估。(b)有时,包含p的单元格不使用最接近的点pi。
在搜索结构中插入点更容易,因为点可以唯一地放置在一个bucket中。插入点还允许我们搜索点和单元格。可以使用p将单元格索引到适当的存储桶中。然后定位到p的最近点(s)。使用拓扑邻接操作符来检索使用点pi的单元格,然后我们可以在这些单元格中搜索包含p的单元格。然而,这个过程必须谨慎使用,因为包含p的单元格可能不使用最近的点(图8 - 30)。
8.8单元格与行相交
一个重要的几何运算是线与单元格的交点。此操作可用于从呈现窗口中交互式地选择单元格、执行光线投射以进行呈现或以几何方式查询数据。
在可视化工具箱中,每个单元格必须能够与一条直线相交。图8 - 31总结了VTK支持的9种线性主单元类型的这些操作。(复合单元格的交叉是通过依次交叉每个原始单元格来实现的。)注意,交叉高阶单元格的过程是相同的。
0D、1D和2D单元格的线/单元格相交遵循标准方法。与3D单元的交叉是困难的。这是因为这些细胞的表面是参数化描述的,不一定是平面的。例如,要使一条线与一个四面体相交,我们可以使这条线与四面体的四个三角形面相交。然而,六面体可以有非平面的面。因此,我们不能将这条线与六个四边形的平面相交。相反,我们使用线/面交点作为初始猜测,并将交点投影到单元格的表面。这将产生一个近似的结果,但对于大多数应用程序来说已经足够准确。
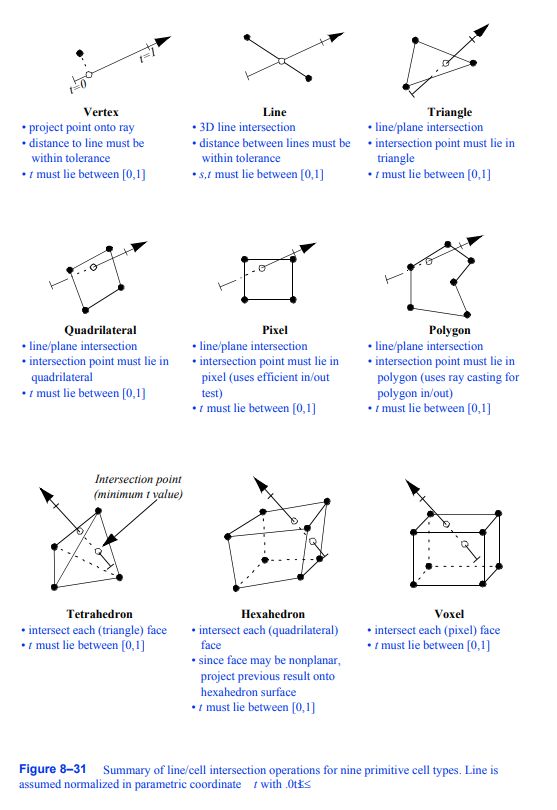
图1
投影点到射线上
•到线路的距离必须在公差范围内
•t必须位于[0,1]之间
图2
•三维线相交
线与线之间的距离必须在公差范围内
•s,t必须在[0,1]之间
图3
•线/面相交
交点必须在三角形内
•t必须位于[0,1]之间
图4
•线/面相交
•交点必须为四边形
•t必须位于[0,1]之间
图5
•线/面相交
•交点必须在像素内(使用有效的in/out测试)
•t必须位于[0,1]之间
图6
•线/面相交
交点必须在多边形内(多边形内/外使用射线投射)
•t必须位于[0,1]之间
图7
•与每个(三角形)面相交
•t必须位于[0,1]之间
图8
•与每个(四边形)面相交
•由于面可能是非平面的,将先前的结果投影到六面体表面
•t必须位于[0,1]之间
图9
与每个(像素)面相交
•t必须位于[0,1]之间
图8-31九种基本单元格类型的行/单元格交集操作汇总。假设直线在参数坐标t中以.0t1££归一化
8.9标量和颜色
标量数据和颜色之间有密切的对应关系。我们在第163页的“颜色映射”中谈到了这一点,在那里我们看到了如何使用颜色表将标量值映射到颜色规范(即红色、绿色、蓝色和alpha或RGBA)。然而,在某些情况下,我们希望绕过这个映射过程。当提供的是颜色数据而不是标量数据时,就会出现这种情况。
一个常见的例子发生在成像中。回想一下,图像是一个规则的二维点数组。这些点定义了像素,这些像素又形成了一个二维图像数据集。图像通常与数据值一起作为一对维度存储。数据值可以是黑白(如位图)、灰度或彩色(如像素图)之一。位图和灰度图像可以直接转换为单值标量数据的形式,我们可以使用前面的方法。然而,像素地图由(至少)每个像素的红、绿、蓝三个值组成。(有时,还会包含第四个alpha不透明度值。)因此,像素图不能直接转换为标量形式。
为了适应颜色数据,必须定义多分量颜色数据和单值标量之间的转换。每个类都必须充当标量:也就是说,在特定点上对数据的请求必须返回单个标量值。这允许我们使用标准的标量可视化技术,如轮廓或翘曲。因此,需要从RGB或RGBA颜色坐标映射到单个标量值。
最简单的转换是在颜色元组中选择n个分量中的一个,并将其用作标量值。另一种常见映射返回颜色的亮度Y。给定三个分量,RGB,亮度为
如果颜色包括透明度,RGBA,亮度为
使用这种抽象可以使我们将单值标量和由多值颜色组成的标量视为相同的。最终结果是,我们可以将这两种类型的标量数据混合到我们的可视化网络中。
8.10图像数据的特殊技术
使用2维和3维图像数据的一个重要吸引力是计算的速度和简单性。在本节中,我们将探索利用图像数据的特殊规则拓扑和几何结构的特定技术。
坐标变换
给定一个点p,我们可以通过执行三次除法运算来找到结构化的坐标
(Figure8-32)。取整型地板函数得到结构化的坐标。压裂段

图8-32图像数据坐标变换。
结果的Tional部分产生单元格的参数坐标。然后,我们可以使用公式8-3转换为数据集坐标。
由于图像数据集平行于坐标x、y和z轴,并且这些方向上的点间距是规则的,因此可以使用有限差分格式来计算单元格点的偏导数。根据图8 - 33,我们可以看到,在三个方向上都可以使用中心差,根据公式:
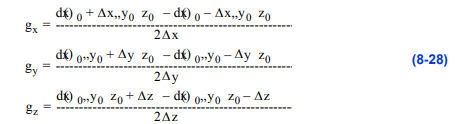
(注意,在数据集的边界,可以使用单边差异。)我们也可以用这些方程来计算细胞内的导数。我们简单地从公式8-28中计算每个单元格点的导数,然后使用单元格插值函数来计算单元格内点的导数。
拓扑学
结构化数据集有助于高效的拓扑操作(即图像数据和结构化网格)。给定一个单元id,可以使用

图8-33利用有限差分对图像数据求导
简单的常数时间运算。首先,给定三维结构化数据集中的单元格id,我们使用除法和模算法的组合来计算结构化坐标
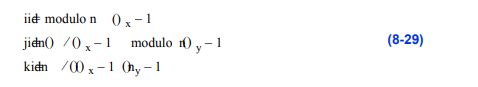
面近邻是通过增加i、j或k指标之一来确定的。边邻通过任意两个指标的递增来确定,而顶点邻通过所有三个指标的递增来确定。在递增时必须小心,以确保指数落在范围内

试图在这些范围之外建立索引表明存在问题的邻居不存在
搜索
给定一个点,我们可以用图8 - 32中给出的方程来确定包含p的单元格。这些方程生成结构化坐标(i, j, k),然后可以使用公式8-3将其转换为单元格id(即数据集坐标)。
为了找到离p最近的点,我们通过舍入到最近的整数值(而不是使用floor函数)来计算结构化坐标。因此,
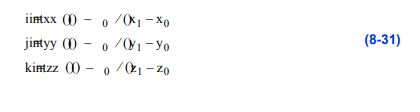
8.11把一切放在一起
在本节中,我们将完成前面对非结构化数据实现的描述。我们还为单元格和数据集定义了一个高级的抽象接口。这个接口允许我们在可视化工具包中实现通用(即特定于数据集的)算法。我们还描述了颜色标量、搜索和选择的实现,并通过一系列示例来演示其中的一些概念。
结构化拓扑
在第5章中,我们描述了非结构化数据集类型vtkPolyData和vtkUnstructuredGrid的数据表示。仔细检查这个数据结构可以发现,检索拓扑邻接的操作效率很低。事实上,要实现检索顶点、边或面邻居的任何操作都需要搜索单元格数组,导致O(n)时间复杂度。这对于除了最小的应用程序之外的所有应用程序都是不可接受的,因为遍历单元格数组和检索邻接信息的任何算法都处于最小O(n2)。
这种低效率的原因是数据表示是一个“向下”的层次结构(图8 - 34 (b))。
也就是说,给定一个单元,我们可以快速确定拓扑层次结构中较低的拓扑特征,如面、边和点。然而,给定一个面、边或点,我们必须搜索单元格数组以确定拥有的单元格。为了提高数据表示的效率,我们必须向层次结构中引入额外的信息,以允许“向上”层次结构遍历(类似于图8 - 34 (a)所示)。此问题的解决方案是使用单元链接扩展非结构化数据结构。cell links数组是使用每个点的单元格列表的列表,对应于图8 - 34 (c)的向上链接。cell links数组将图5 - 13的层次结构转换为环形结构。单元格引用它们的组成点,而点又引用使用它们的单元格。完整的非结构化数据结构如图8 - 35所示。
单元格链接数组实际上是公式5-1的使用集的实现。如果使用一个点的最大单元格数量远远小于数据集中的点数量,我们可以使用这个方程在常数时间内计算邻接操作。为了看到这一点,我们参考公式8-25,并看到邻接操作由有限数量的集合交点组成。每个操作都是每个点的链接列表的交集。如果每个链表中的单元格数量是“小”的,那么交集操作可以被一个固定的时间常数所限制,总的操作可以被认为是一个常数时间操作。
这种数据表示有几个重要的特征。
•单元格链接数组是基本非结构化数据表示的扩展。因此,我们可以将单元链接的构建推迟到需要时。通常不需要单元链接,也不需要计算机资源来计算或存储。
•构建单元链接是一个线性O(n)操作。遍历每个单元格,对于该单元格使用的每个点,将扩展该点的使用单元格列表以包括当前单元格。构建单元链接作为初始化步骤只需要一次。

图8-34增强非结构化数据的分层表示。(a)几何模型的常规拓扑层次。(b)基本非结构化数据层次结构。(c)完整的非结构化数据层次结构。通过引入从点到单元格的向上引用,非结构化数据层次结构可以有效地在两个方向上遍历,并且比传统的拓扑层次结构更紧凑。
•数据表示相对于其他拓扑表示方案(例如,翼边结构和径向边缘结构[Baumgart74] [Weiler88])是紧凑的。这些其他数据结构包含中间拓扑的显式表示,如边、环、面或特殊邻接信息,如相邻边(翼边结构)或广泛的“使用”描述(径向边结构)。表示的紧凑性对于可视化特别重要,因为数据通常很大。
可视化工具包中的非结构化数据结构由vtkPoints(及其子类)、vtkCellArray、vtkCellTypes和vtkCellLinks四个类实现。这个数据结构的构建是递增的。至少,点和单元格是使用vtkPoints和vtkCellArray表示的。如果需要随机访问或额外的类型信息,则使用对象vtkCellTypes。如果需要邻接信息,则创建类vtkCellLinks的实例。这些操作在幕后执行,通常不需要应用程序程序员额外的知识。
抽象接口
随着第五章和第八章的完成,我们可以总结单元格、数据集和点数据属性的抽象接口。这些伪代码描述封装了类vtkDataSet、vtkCell和vtkPointData及其子类的核心功能。本文中介绍的所有算法都可以使用这些方法的组合来实现。

图8-35包括链表在内的完整的非结构化数据表示。有m个单元格和n个点。链表中的n个结构是使用每个顶点的单元格列表。
每个链表的长度是可变的。
数据抽象。数据集是VTK中的中心数据表示。数据集由一个或多个单元格和点组成。与这些点相关的是由标量、向量、法线、纹理坐标和张量组成的属性数据。
type = GetDataObjectType()
返回数据集的类型(例如,vtkPolyData, vtkImageData, vtkStructuredGrid, vtkreciplineargrid,或vtkUnstructuredGrid)。返回数据集中的点数。
numCells = GetNumberOfCells()
返回数据集中的单元格数量。给定一个点id,返回该点的(x,y,z)坐标。给定一个cell id,返回一个指向cell对象的指针。返回由cell id指定的cell类型
cell = GetCell(cellId)
给定单元格id,返回一个指向单元格对象的指针。
类型= GetCellType(cellId)
返回由cell id指定的单元格类型。
返回组成数据集的单元格类型的列表。给定一个点id,返回使用该点的单元格。给定单元格id,返回定义单元格的点id(例如,连接列表)。给定一个单元id和一个组成单元边界面的点列表,返回该单元共享这些点的邻居。给定一个坐标值x,一个由cell和cellId定义的初始搜索单元格,以及一个公差测量值(平方),返回包含点及其插值函数权重的单元格id和子id。初始搜索单元格用于在已知位置x在单元格附近时加快搜索过程。如果没有找到单元格,则celllid <返回0。返回一个指向对象维护点属性数据的指针。这包括标量、向量、法线、张量和纹理坐标,以及字段携带的任何其他数据数组。cellData = GetCellData()返回一个指针,指向维护单元格属性数据的对象。这包括标量、向量、法线、张量和纹理坐标,以及字段携带的任何其他数据数组。bounds = GetBounds()获取数据集的边界框。length = GetLength()返回数据集的包围框对角线的长度。center = GetCenter()获取数据集边界框的中心。一个方便的方法,返回与数据集相关的标量属性数据的(最小,最大)范围。dataSet = NewInstance()复制当前数据集。一个“虚拟”构造函数。(通常,引用计数方法用于复制数据。)使用提供的数据集更新当前结构定义(即几何和拓扑)。
细胞的抽象。细胞是VTK的原子结构。单元格由拓扑(由一组有序点id序列定义)和几何(由点坐标定义)组成。单元格坐标由单元格id、子单元格id和参数坐标组成。subbid指定位于复合单元格(如三角形带)内的主单元格。单元格的边和面从单元格的拓扑中隐式定义。type = GetCellType()返回单元格类型。必须是12个VTK单元格类型之一(或空单元格类型)。返回单元格的拓扑定义。order = GetInterpolationOrder()返回单元格的插值多项式的次。(12种细胞类型都是1度;numberPoints = GetNumberOfPoints()返回定义单元格的点数。返回一个定义单元格的点id列表。返回单元格中的边数。给定一个edge id()返回一个指向单元格的指针,该单元格表示单元格的一条边。返回单元格中的面数。给定一个face id()返回一个指向一个单元格的指针,该单元格表示该单元格的一个面。给定单元格的子标和参数坐标,返回一个点id列表,这些点id定义了单元格最近的边界面。同时返回该点是否在单元格中。inOutStatus = EvaluatePosition(x, closepoint, subId, pcoordinates, weights, dist2)给定一个点坐标x,如果x位于单元格内,则返回单元格的子id、参数坐标和插值权重。位置closestPoint是单元格中距离x最近的点(可能是相同的),dist2是它们之间距离的平方。该方法返回一个inOutStatus,指示x在拓扑上是在单元格内部还是外部。也就是说,点可以满足参数坐标条件,但可以位于单元格表面之外(例如,点位于多边形上方)。使用inOutStatus和dist2来确定点在单元格中是否在拓扑上和几何上都在。
给定一个点的位置(即子id和参数坐标),返回点的位置x和插值权重。给定单元格点的轮廓值和标量值,生成轮廓原语(具有关联点和属性数据值的顶点、线或多边形)。这些点被放置在一个定位器对象中(参见297页的“搜索”),它合并了重合的点,属性数据值从inputPointData插值到outputPointData(沿着单元格边缘)。给定单元格点上的轮廓值和标量值,剪辑单元格以生成与原始单元格具有相同拓扑维度的新单元格。这些点被放置在一个定位器对象中(参见297页的“搜索”),该对象合并了重合点,属性数据值从inputPointData插入(或复制)到outputPointData。剪切的单元格被放置在单元格列表中。给定单元格位置(即,subId和参数坐标)和单元格点上的数据值,返回dim*3个导数(即,对应于x, y和z方向乘以数据维度)。inOutStatus = IntersectWithLine(p1, p2, tol, t, x, pcoordinates, subId)给定由两点p1和p2定义的有限线和交点公差,返回交点x。同时返回沿直线的参数坐标t和交点的单元格位置。如果发生交集,则返回非零。Triangulate(index, ptIds, points)将单元格分解为与拓扑单元格维度相等的简单维度。索引是一个整数,如果可能有多个三角测量,则它控制三角测量。简式由点id及其对应坐标的有序列表定义。返回单元格的边界框。
点和单元格属性抽象。点和单元格属性数据是与数据集的点和单元格相关联的信息。这些信息由标量、向量、法线、张量和纹理坐标组成。数据集中的点和单元格与其对应的点和单元格属性数据之间是一对一的关系。例如,位置100上的点标量值与点id 100相关联。下面描述的许多方法都处理将数据从过滤器的输入移动到输出。由于将来可能会添加新类型的属性数据,因此
移动数据的细节被尽可能地隐藏(即,尽量减少过滤器对特定属性类型的了解)。因此,像CopyData()这样的泛型函数允许在不知道该数据是什么的情况下将数据从输入复制到输出。CopyScalarsOn() / CopyScalarsOff()打开/关闭布尔标志,控制从过滤器的输入到输出复制标量数据。CopyVectorsOn() / CopyVectorsOff()打开/关闭布尔标志,控制矢量数据从过滤器的输入到输出的复制。CopyNormalsOn() / CopyNormalsOff()打开/关闭布尔标志,控制正常数据从过滤器的输入到输出的复制。CopyTensorsOn() / CopyTensorsOff()打开/关闭布尔标志,控制张量数据从输入到输出的复制。CopyTextureCoordsOn() / CopyTextureCoordsOff()打开/关闭布尔标志,控制纹理坐标数据从过滤器的输入到输出的复制。CopyAllOn() / CopyAllOff()打开/关闭所有控制从输入到输出的所有属性数据复制的布尔标志。根据前面列出的复制标志,将所有点属性数据(pointData)传输到输出。为逐点复制进程初始化和分配存储空间。给定点数据和特定的点id,将点属性数据(pointData)复制到输出点。InterpolateAllocate(pointData)为逐点插值过程初始化和分配存储空间。给定输入点数据(pointData)和一组点及其插值权重,将数据插值到指定的输出点。InterpolateEdge(pointData, toId, p1, p2, t)从两个点p1和p2定义的边开始,在边参数坐标t处插入pointData,并将插入的属性数据复制到输出点ptId。NullPoint(int ptId)将指定输出点id的数据值设置为空值
SetScalars() / GetScalars()设置/返回标量数据。GetScalars()方法可以返回一个NULL值,在这种情况下标量没有定义。设置/返回向量数据。GetVectors()方法可以返回一个NULL值,在这种情况下向量没有定义。SetNormals() / GetNormals()设置/返回正常数据。GetNormals()方法可以返回一个NULL值,在这种情况下,法线没有定义。SetTensors() / GetTensors()设置/返回张量数据。GetTensors()方法可以返回一个NULL值,在这种情况下,没有定义张量。SetTextureCoords() / GetTextureCoords()设置/返回纹理坐标数据。GetTextureCoords()方法可以返回一个NULL值,在这种情况下,纹理坐标没有定义。由VTK实现的数据集抽象提供了遍历点和单元的简单技术。有时我们想要遍历中间拓扑,如边或面。例如,为了识别三角形网格中的边界边,我们必须遍历每条边,计算使用每条边的三角形的数量。(记住,边界边只被一个三角形使用。)不幸的是,没有明显的方法来遍历边缘。如果我们想遍历包含3D单元格的数据集的表面,同样的问题也成立。
一个简单的解决方案是遍历每个单元格,然后获取组成单元格的边(或面)。这种方法的问题是,边和面通常被多个单元格使用,导致对同一面或边的多次访问。这在某些算法中可能是可以接受的,但通常我们只访问每条边或面一次。
这个问题的一个更好的解决方案是像以前一样遍历每个单元格,但是如果当前单元格具有最小的单元格id,则只处理中间拓扑。(当前单元格是遍历过程中被访问的单元格。)为了确定当前单元格是否具有最小的单元格id,我们使用中间拓扑获取所有单元格。该信息可以使用前面描述的拓扑邻接运算符(例如,公式8-25)获得。
为了说明这个过程,可以考虑访问一个三角形网格的边缘。我们从第一个三角形t开始,然后是它的边。对于每条边,我们确定使用该边的相邻三角形(如果有的话)。如果相邻三角形s的id大于三角形t的id,或者没有相邻三角形,那么我们就知道要处理当前的边。(当然,第一个三角形的id总是最小的——但随着遍历的进行,这将发生变化。)然后我们继续遍历三角形列表寻找新的t。通过这种方式,网格的所有边缘都将被访问。
颜色标量数据
多值标量数据,或由各种颜色表示的标量,由可视化工具包专门处理。例如,当使用颜色规范直接控制对象的颜色而不是通过查找表映射标量值时,就会出现这些数据。(更多信息见163页的“颜色映射”。)
默认情况下,将标量映射到颜色的过程如下(vtkMapper和子类负责实现此行为):
•如果标量类型是unsigned char,元组大小在1到4个组件之间,则数据被认为是颜色数据。
•四分量数据假设为RGBA(红-绿-蓝-alpha透明度)颜色规范。三分量数据被假定为RGB颜色规范。两组数据被假设为IA(强度- α)表示。单分量数据假设为I(强度)值。
•任何其他数据类型或包含四个以上成分的数据都被假定为表示标量值。在这种情况下,标量通过查找表进行映射,以在渲染过程中产生颜色。
可以通过查找表强制映射无符号字符数据。vtkMapper方法SetColorModeToMapScalars()强制通过查找表映射所有数据(无论类型如何)。
可视化工具包提供了两个类来执行数据集点和单元格的搜索。它们是vtkPointLocator和vtkCellLocator。(这两个类都是vtkLocator的子类,后者是空间搜索对象的抽象基类。)vtkPointLocator用于搜索点,如果与拓扑数据集操作符GetPointCells()一起使用,也用于搜索单元格。vtkCellLocator用于查找单元格。
vtkPointLocator实现为常规的桶网格(即,与图像数据集具有相同的拓扑和几何结构)。桶的数量可以由用户指定,或者更方便地根据数据集点的数量自动计算。平均而言,vtkPointLocator提供了对点的固定时间访问。然而,在点分布不均匀的情况下,一个桶中的点数量可能会有很大的变化,给出O(n)个最坏情况的行为。在实践中,这很少是一个问题,但自适应空间搜索结构(例如,八叉树)有时可能是一个更好的选择。
使用vtkPointLocator(以及其他空间搜索结构)确定距离点p最近的点是一个三步过程。在第一步中,使用适当的插入方案找到包含p的bucket。(对于vtkPointLocator,这是确定桶索引(i, j, k)的三个部分。)接下来,搜索此bucket中的点列表以确定最近的点。然而,如图8 - 36所示,这可能不是真正的最近点,因为相邻桶中的点可能更近。因此,有必要最后搜索邻近的存储桶。搜索距离是a
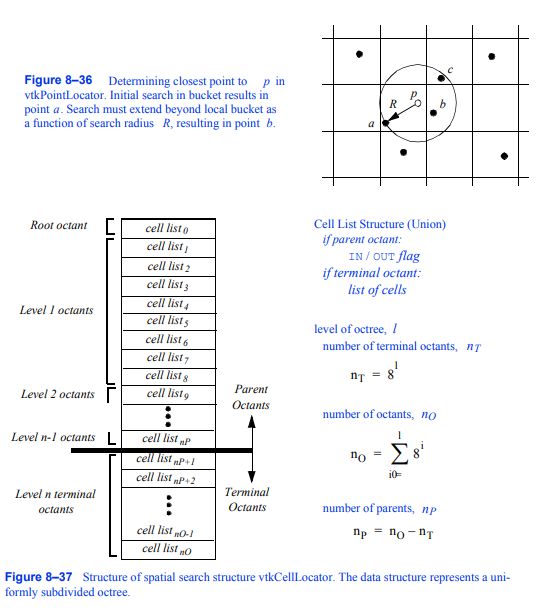
图8-36在vtkPointLocator中确定距离p最近的点。在桶中初始搜索的结果是点a,搜索必须超出本地桶,搜索半径为R,结果是点b。
图8-37空间搜索结构vtkCellLocator. zip数据结构表示一个统一细分的八叉树。
到当前最近点的距离函数。一旦搜索了这个距离内的所有邻居,就返回最近的点。
vtkCellLocator实现为一个具有一些特殊特征的统一细分八叉树(图8 - 37)。传统的八叉树表示使用向上的父结点和向下的子结点来跟踪父结点和子结点。除了每个八分区中所需的实体(即点或单元)列表之外,还可以保持关于八分区水平、中心和大小的其他信息。这就产生了具有显著开销的柔性结构。开销是维护指针的内存资源,加上分配和删除内存的开销。
相比之下,vtkCellLocator使用一个数组来表示八叉树。该阵列被分为两部分。第一部分包含父八分程列表,根据级别和八分程排序

图8-38 VTK的摘机结构vtkAbstractPropPicker的所有子类都返回被选中的vtkProp实例。该信息作为vtkAssemblyPath返回。程序集路径是必要的,因为程序集层次结构中可能存在一些道具。类vtkWorldPointPicker和vtkPropPicker是硬件加速挑选类。其他的都使用软件光线投射。
孩子数量。在第二部分是末梢,或叶八分。终端八位符在常规桶数组上排序,与vtkLocator相同。末端八分区包含八分区内实体的列表。父八分区保持一个值,指示八分分区是否为空,或者八分分区内是否有东西。(这两种类型的信息都在八分区结构的同一部分中表示。)因为八叉树是统一细分的,所以可以使用简单的除法运算快速计算父子关系以及八叉位置。
这种结构的优点是可以快速分配和删除内存。此外,插入到八叉树与使用vtkLocator完全相同,并且比传统的八叉树更简单。父八分位提供了快速筛选功能,因为它们的状态(空或非空)允许我们停止某些类型的搜索操作。缺点是,由于八叉树是统一细分的,如果数据分布不均匀,这种结构会浪费内存资源。
我们使用这里描述的搜索结构的经验是,它们可以很好地处理许多类型的可视化数据。但是,如果您的数据是不统一的,您可能希望实现自己的特殊搜索类。
可视化工具包提供了各种各样的类来执行actor(或vtkProp)、点、单元格和世界点的选择(图8 - 38)。根据所使用的拾取器,可以使用基于软件的几何交叉,也可以使用硬件拾取。下面详细描述每种选择器类型。
所有的拾取器都是定义基本拾取接口的vtkAbstractPicker的子类。用户必须在显示坐标中为指定的vtkRenderWindow实例指定一个选择点,并调用Pick()方法。至少,该类必须返回世界坐标中的x-y-z选择位置。可以将选择候选对象限制在一个vtkProps列表(PickList)中。该类还调用StartPickEvent、PickEvent和EndPickEvent事件,这些事件分别在拾取之前、拾取期间和拾取之后调用。
可以返回指示它们所选择的vtkProp的信息的类是vtkAbstractPropPicker的子类。在pick操作之后,vtkAbstractPropPicker返回一个vtkAssemblyPath。程序集路径是vtkProp实例和可能关联的转换矩阵的有序列表。路径表示程序集的级联层次结构
节点(参见第74页的“程序集和vtkProp的其他类型”,了解更多关于程序集和程序集的信息)。
对象vtkPicker与所有可选的和不透明的vtkProp3D的包围框相交叉,从摄像机位置到屏幕坐标(即像素)。(如果一个vtkProp的pickable实例变量为真,那么它就是可选的。)vtkPicker选择操作的结果是返回一个包含边界框相交的vtkProp3D的列表。离摄像机位置最近的道具也会返回。
对象vtkPointPicker将射线与定义每个vtkProp3D的点相交,并返回最接近摄像机位置的点坐标,以及该点所属的vtkProp3D。由于屏幕分辨率无法精确地选择一个点,因此必须指定光线周围的公差。公差表示为呈现窗口大小的一个分数。(渲染窗口大小是通过窗口对角线测量的。)点必须在这个公差范围内才能被选中。
对象vtkCellPicker将射线与定义每个vtkProp3D的单元格相交,并返回交点,以及单元格所属的vtkProp3D。如果您试图选择属于特定vtkProp3D的单元格,则可以使用vtkCellPicker对象,因为它执行曲面(或单元格)交叉。不幸的是,由于更大的计算需求,vtkCellPicker是最慢的选择器。
类vtkWorldPointPicker返回呈现窗口中一个pick的(x,y,z)坐标值。为了确定该信息,它将显示(x,y)值与z-缓冲区深度值结合起来。在所有的选择器中,这是最快的,但它不能确定实际选择的单元格、点或vtkProp,因为它不是vtkAbstractPropPicker的子类。(注意:在某些系统上z-buffer操作无效,该对象将不能正常工作。)
默认情况下,使用类vtkPropPicker执行拾取。这个类使用硬件加速拾取——因此它通常比基于软件的拾取更快。与其他硬件加速类(vtkWorldPointPicker)不同,它返回被选择的vtkProp实例以及(x,y,z)世界坐标值。
图8 - 39总结了五个具体的选择类。选择是内置到vtkRenderWindowInteractor类使用“p”键(见“介绍vtkRenderWindowInteractor”在第68页)。默认情况下创建并使用一个vtkPropPicker,但您可以自由指定自己的选择器类型。
为了结束本节,我们将研究如何使用一些数据集、单元格和点属性操作。这些操作通常由类开发人员使用。如果您通过使用现有过滤器构建可视化管道来构建应用程序,则不需要使用它们。
找到自由边。在我们的第一个例子中,我们将看一下过滤器vtklinearextrusifilter。该过滤器实现以下建模操作。给定一个多边形网格,在给定的方向上挤压网格,从自由边缘构造一个“裙子”或“墙壁”。如果多边形示例是一个正方形,则此操作的结果是一个立方体。或者,如果多边形数据由单行组成,则操作的结果是一个四边形。一个点会生成一条直线,如图8 - 40 (A)所示。
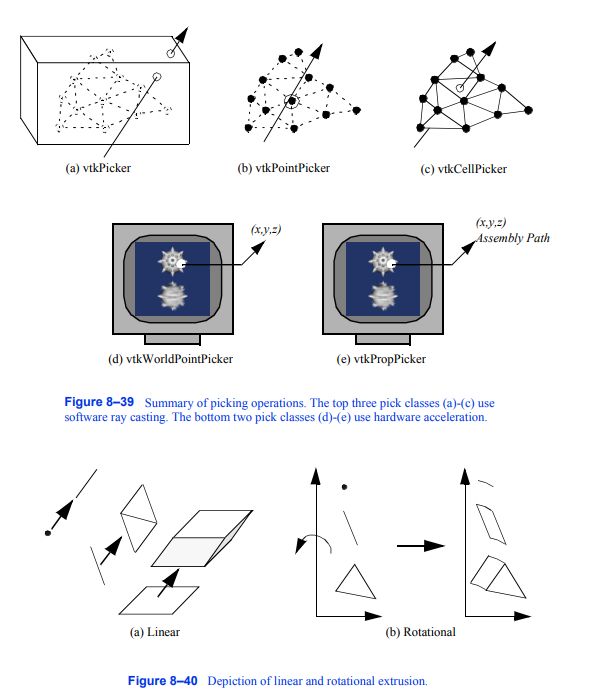
图8-39采摘操作汇总前三个选择类(a)-(c)使用软件光线投射。底部的两个选择类(d)-(e)使用硬件加速。
图8-40线性挤压和旋转挤压示意图
回想一下,自由边是仅供一个多边形使用的边。我们可以使用数据集拓扑操作GetCellEdgeNeigbors()来确定这个信息。我们使用公式8-25和定义多边形边缘的两个点来确定邻接集(即共享这条边的多边形)。如果没有其他多边形使用此边,则挤压该边以生成三角形条。
c++伪代码如下所示。

vtkRotationalExtrusionFilter也使用了同样的方法(图8 - 40 (b))。这两个函数之间的区别在于,运动类型是旋转的,而不是线性的(vtkLinearExtrusionFilter)。这两个过滤器可以用来执行一些漂亮的建模操作。线性挤压可用于创建任意横截面的柱状图,或扫出三维字体。旋转挤压过滤器可用于创建旋转对称的物体,如瓶子或酒杯。这些技术的示例如图8 - 41所示。
发现细胞。在本例中,我们将选择和拓扑操作结合起来,以选择共享公共点的单元格。具体来说,我们使用vtkPointPicker和拓扑数据集操作GetPointCells()。如图8 - 42所示。我们还包含了实现此过程的c++代码片段。注意,这个过程将适用于任何数据集类型,即使几何图形是隐式定义的(例如,vtkImageData)。
这个过程中最困难的部分是采摘过程。选择点必须在像素坐标中指定。vtkPointPicker使用发生选择的渲染器将这些坐标转换为世界坐标,然后转换为数据集坐标。(渲染器使用其主动摄像机的变换矩阵进行坐标变换。)
在vtkRenderWindowInteractor中可以方便地管理拾取过程。该对象允许在拾取之前和拾取之后执行函数的规范(即“AddObserver StartPickEvent”和“AddObserver EndPickEvent”)。使用这个工具,我们可以定义一个后取函数来检索点id,然后执行GetPointCells()操作。流程如图8 - 42所示。

图8-41线性挤压和旋转挤压模型
点调查。在这个例子中,我们将展示如何使用本章描述的数据集和单元格操作来构建一个点探测。点探针的定义如下。给定一个(x,y,z)点坐标,找到单元格坐标(即单元格id,子单元格id和参数坐标)和插值权值。一旦找到插值权值,我们就可以计算(x,y,z)处的本地数据值。
点探测是使用数据集操作FindCell()实现的。这种方法需要在全局坐标中指定一个点(我们的(x,y,z)值)和一个公差。由于数值精度或在3D单元格表面附近或在0D、1D和2D单元格上选取时,公差通常是必要的。FindCell()操作返回我们需要的信息,加上包含点探针的单元格的插值权重。为了确定探测点的数据值,我们需要检索单元格点上的数据值。然后,我们可以使用公式8-4中的插值函数来确定探测标量值。
图8 - 43描述了这个过程,并包含了c++代码。在本例中,我们使用带有对象vtkCursor3D、vtkProbeFilter和vtkGlyph3D的燃烧器数据集。光标的作用是控制探测点的位置。类vtkProbeFilter执行探测

图8-42选择共享点的单元格组。(a)原始数据。(b)拐角上的选定单元共用点。为了清晰,细胞收缩了。小圆球表示所选点。(c)选取例程中的c++代码片段。
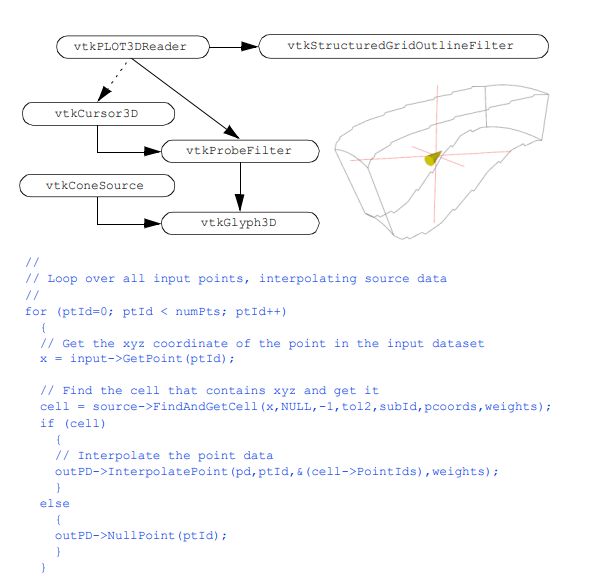
图8-43创建点探针可视化网络如图所示。c++代码显示了vtkProbeFilter的内部循环和燃烧室数据(探头。cxx)。
刚才描述的操作。vtkGlyph3D用于在光标焦点处放置一个定向的、按比例缩放的圆锥。这给了我们关于探针上的标量和矢量的视觉反馈。当然,如果这很重要,我们可以提取数值并将它们显示给用户。
8.12章节小结
三个重要的可视化坐标系是世界坐标系、数据集坐标系和结构化坐标系。世界坐标系是一个x-y-z笛卡尔三维空间。图8-43创建点探针可视化网络如图所示。c++代码显示了vtkProbeFilter的内部循环和燃烧室数据(探头。cxx)。vtkStructuredGridOutlineFilter vtkProbeFilter vtkGlyph3D vtkConeSource vtkCursor3D vtkPLOT3DReader // //循环遍历所有输入点,插值源数据// (ptId=0;ptId & lt;numPts;ptId++){//获取输入数据集中点的xyz坐标x = input->GetPoint(ptId);//找到包含xyz的单元格并获取它cell = source->FindAndGetCell(x,NULL,-1,tol2,subId, pcods,weights);if (cell){//插值点数据输出pd ->插值点(pd,ptId,&(cell->PointIds),weights);} else {outPD-> null点(ptId);315坐标系由单元格id、子单元格id和参数坐标组成。结构化坐标系由(i,j,k)个整数指标构成一个矩形拓扑域。
可视化数据通常采用离散形式。插值函数用于在已知数据值之间的点上获得数据。插值函数取决于特定的单元格类型。插值函数的形式是位于每个单元格点的加权值。插值函数构成了从数据集到全局坐标的转换基础,反之亦然。插值函数也用于计算数据导数。
拓扑操作符提供关于单元格或数据集的拓扑信息。获取特定单元格的相邻单元格是一项重要的可视化操作。此操作可用于确定单元格边界是否在数据集的边界上,或逐单元格遍历数据集。
由于图像数据集固有的规律性,与其他数据集类型相比,操作可以有效地实现。这些操作包括坐标变换、导数计算、拓扑查询和搜索。
8.13书目注释
插值函数在许多数值技术中都有应用。有限元法尤其依赖于插值函数。如果你想了解更多关于插值函数的信息,请参考下面建议的有限元参考文献[Cook89] [Gallagher75] [Zienkiewicz87]。这些文本还讨论了导数计算在插值函数的上下文中。
可视化高阶数据集是一个开放的研究课题。虽然[Schroeder06]描述了一种方法,但基于GPU程序的方法正在出现。其他方法包括针对特定单元类型的定制算法。
基本拓扑参考可从许多来源获得。关于拓扑数据结构的两个很好的描述来自Weiler [Weiler86] [Weiler88]和Baumgart [Baumgart74]。维勒描述了径向边缘结构。该数据结构可以表示流形和非流形几何。鲍姆加特所描述的翼边结构广为人知。它被用来表示流形几何。Shephard [Shephard88]描述了通用的有限元数据结构——这些结构类似于可视化结构,但包含与分析和几何建模相关的额外信息。
关于空间搜索结构有大量的参考文献。Samet [Samet90]提供了一些概述。八叉树最初由Meagher [Meagher82]开发用于3D成像。参见[Williams83]、[Bentley75]和[Quinlan94],分别获得关于MIP映射、kd树和二叉球树的信息。
8.14参考资料
[鲍姆加特74]李志强。计算机视觉的几何建模博士论文,斯坦福大学,帕洛阿尔托,加州,1974年。316高级数据表示法[j]。用于关联搜索的多维二叉搜索树ACM通信。18(9): 509 - 516年,1975年。[Conte72]孔蒂。基本数值分析。麦格劳-希尔图书公司,1972年出版。
[Cook89]李国强,李国强。有限元分析的概念与应用“,”约翰·威利父子,纽约,1989年。
[加拉格尔75]李志强。有限元分析:基础。Prentice Hall, Upper Saddle River, NJ, 1975。
[米格尔82]李国强。任意三维物体的高效合成图像生成IEEE模式识别与图像处理会议论文集。第473-478页,1982年。
[昆兰94]李志强。“非凸物体之间的有效距离计算”IEEE机器人与自动化国际会议论文集。1994.
[陈晓明,李志强,等。空间数据结构设计与分析“,”Addison-Wesley, Reading, MA, 1990。
[施洛德06]王晓明,王晓明,王晓明,Pébay。可视化高阶有限元的方法和框架计算机图形学学报,2006(4):446-460。
[谢泼德88]谢泼德;“迈向自动模型生成。”最先进的计算力学研究。A. K.诺尔、J. T.奥登主编。,美国机械工程师协会,第335-366页,1989。
[刘文杰,李文杰,李文杰,等。几何建模的拓扑结构。博士论文,伦斯勒理工学院,特洛伊,纽约,1986年5月。
[韦勒88]李志刚。径向边缘结构:非流形几何边界表示的拓扑表示。M. J.沃兹尼、H. W.麦克劳克林和J. L.恩卡纳索编。CAD应用的几何建模。第3-36页,北荷兰,1988年。
[威廉斯,83]李志强。“锥体参数化”。计算机图形学(SIGGRAPH ' 83)。17(3): 1 - 11, 1983年。
[齐恩凯维奇,刘志伟,刘志伟,等。有限元法-第1卷。McGraw Hill图书公司,纽约,第4版,1987年。
8.15运动
8.1给定一个尺寸为原点(1.0,2.0,3.0)和体素间距(0.5,
0.5, 1.0)。
a)计算最小点位置。

b)计算最大点位置。
c)对于单元id为342,计算单元最小点位置和最大点位置。
d)哪些点(列表id)定义单元id 342?e)在结构坐标中指定的给定点为;
,计算全局坐标。
f)给定点id 342;计算全局坐标。
8.2计算数据集坐标中指定点的全局坐标和插值权值(参见图8 - 44 (a-d))。
a)与。
b)与。
c)体素与。
8.3计算图8 - 44中单元格的参数坐标(a-d)。
a)与。
b)与。
c)体素与。
8.4给定图8 - 44 (a)所示的直线,如果标量数据值为,方向上的导数是多少?
8.5参考图8 - 44 (d),以数字表示单元格id,字母表示点id。
a)列出使用点a的单元格
b)列出使用点b的单元格
c)列出使用边的单元格这个列表与你在上面a)和b)部分的答案有什么对应关系?图8-44练习图B 1 2 3 4 5 6 7 8 11 10 9 (A) (d) (B) (e) (c)(0, 0, 0)(2 0 0)(0, 0, 0)(5、4、3)(1 1 0)(1、2、3)(0,0,0)ijk =(364年),rst,, = () 0.10.20.5 r0.5 = rs = () 0.250.33, rst, = () 0.250.330.5,, = () 0.30.60.9 xyz, xyz, = () 0.50.250.0,, = () 0.50.42.0 xyz, s0 s1 () , = () 0.00.25 xyz,, () AB 318先进数据表示
8.6指Figure8-44 (e)。有多少边界的脸?b)有多少“内部”面孔?
8.7描述一条有限线相交的过程。容忍值是如何发挥作用的?
8.8描述一条直线与三角形相交的过程。三角形有什么特殊的特征可以用来加速这个操作吗?
8.9对比图8 - 34中三种非结构化网格数据结构的内存需求。假设两个单元格使用每个面,四个面使用每个边,六个边使用每个顶点(即结构化数据集)。
8.10使用抽象单元格和数据集接口,编写一个程序来计算a)数据集中的点数,b)数据集中的单元格数,c)数据集中的边数,d)数据集中的面数。
8.11给定一个体积的尺寸。a)有多少个内面(即两个体素使用)?b)有多少个边界面(即一个体素使用的边界面)?
8.12编写一个通用的挤压过滤器,沿着一条路径扫描一个对象来构造一个新的表面。假设路径由一系列变换矩阵定义。你能想到一种防止自我交叉的方法吗?
本书为英文翻译而来,供学习vtk.js的人参考。