MIT6.5830 实验2
前置回顾
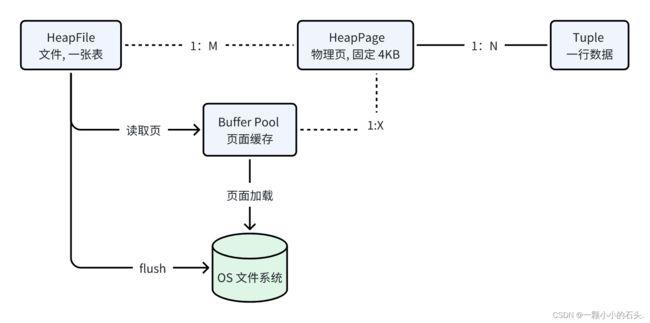
在实验一中,我们完成了基本的数据存储层功能,以及实现了最核心的几个数据结构,Tuple、HeapFile、HeapPage、Buffer Pool 等,对他们的增删查改已经支持,但没有和上层的逻辑 sql 关联起来。实验二需要对 Tuple 数据结构有深刻的理解,这里附上实验一的核心内容。
HeapFile:物理上对应一个操作系统的文件,即实验中的 .dat 文件。 逻辑上对应一张表。
HeapPage: 物理概念。内存和磁盘存储的最小单位,固定为 4096B 大小。承上启下的作用,逻辑代码读取内存存储使用 Page ,内存中的数据想写入到磁盘中,也是利用 Page。 和 HeapFile 是一对多。
Tuple: 逻辑上,理解为数据表中的一行。 物理存储上,和 Page 是一对多的关系,Tuple 中包含自己属于那个Page的哪个 Slot 槽位置。
Buffer Pool : 内存中的页面缓存。File和Page虽然是一对多关系,但 File 不能直接从磁盘中读取Page, 需要借助 Buffer Pool 去读取,如果缓存中有直接返回,如果没有,由 Buffer Pool 去磁盘中读取对应的页面。
实验目标
为 GoDB 编写一组运算符来实现表修改(例如,插入和删除记录)、过滤器、联接、聚合等。然后可以进行简单的 sql 查询,但 SQL 解析器不需要自己实现,查询计划和执行逻辑已经提供好。
实验二作为承上启下的关键阶段,实现难度上先易后难,因为有提供可参照的函数实现,所以刚开始比较简单,也能通过各个操作对应的test程序,但当最后运行 easy_parser_test.go 时会发现有各种问题需要修复。
实现思路
先介绍一下本次实验涉及到的各个文件:
| 文件名 |
操作 |
对应sql功能 |
返回值 |
难度 |
| filter_op.go |
过滤 |
where 条件 |
过滤后的行 |
简单 |
| limit_op.go |
截断 |
limit 操作 |
固定数量的行 |
简单 |
| order_by_op.go |
排序 |
order 操作 |
排过序的行 |
中等 |
| insert_op.go |
插入 |
insert 语句 |
成功插入的行数 |
简单 |
| delete_op.go |
删除 |
delete 语句 |
成功删除的行数 |
简单 |
| project_op.go |
投影 |
select 操作 |
仅包含指定列的行 |
困难 |
| join_op.go |
连接 |
join on 操作 |
连接后的行 |
困难 |
| agg_op.go |
聚合 |
max() min() |
聚合后的行 |
中等 |
基本概念
TupleDesc 行描述符
在实验一中,Tuple指的是表中的一行数据,其中 tupleDesc 是行的列信息。在实验二中, tuple 的概念得到了延伸,不再限定于表里的一行数据,它可以是任何地方的一行数据。例如:
-
join 两个表得到的中间结果是一行数据
-
例如insert 操作逻辑上返回的是成功插入的行数,实现上返回的是一个值为Rows的Tuple
-
例如 max 聚合操作逻辑上返回的是最大值,实现上返回的是一个值为 RowValue 的Tuple
总之,所有操作的请求入参和返回出参都是 Tuple
Iterator 迭代器
在实验一中已经接触过迭代器,它采用闭包的方式逐个返回要取出的元素,而非一次性全部取出。在实验二中,大部分op操作结束后返回Tuple都是用迭代器的方式。理由如下:
某些情况下数据库通过迭代器等方式向上层返回数据,而不是一次性获取所有数据。例如mysql客户端使用scan方法手动逐行读取。否则如果select出的数据非常多,多到连内存都放不下,就不能很好的处理。用分批返回的方式即可解决。例如MySQL server层中的net buffer缓冲区就是服务端有大量数据需要返回给客户端的时候,放置分批数据的地方。当然也可以直接使用scan方法读取mysql内部结果的迭代器。
思考:所有操作都可以用迭代器的方式逐个返回吗?并不是,例如 order by 操作,必须把所有数据都读到内存中才能排序,虽然排序完依然使用迭代器返回,但核心优势无法利用上。
Operator 操作
是一个接口,含义是某种 sql 操作, 对应上表中的各种操作类型。接口有两个方法:
-
Descriptor() 获取列信息。 刚才提到操作中的列信息不再一定是一行的列了,而可能是部分行,例如 filter 过滤操作针对是指定的两列,这两列可能不是原始行中的列,例如 select from t where max(age) > avg(age)
-
Iterator() 获取迭代器。 刚才提到,所有操作的结果都使用迭代器的方式去返回,在迭代器迭代的过程中才真正执行一些操作,即惰性计算。
Expr 表达式
exprs.go 中的 Expr 接口含义为,能够应用于 Tuple 上以获取值的操作。 例如:
-
select age - 18 from t 中的中的减操作,需要对每个Tuple 的 age 减 18 的到一个值。
-
select * from t where age1 > age2 中,需要分别取出每个 tuple 中的 age1 和 age2 列的值再做比较。
所以,表达式接口给定了3种实现,分别是 FieldExpr、ConstExpr、FuncExpr 分别代表 取列值、常量值、经过函数运算后的值。
Exercise 1
根据实验手册 lab2.readMe 文件,从最简单的开始, filter_op.go 和 join_op.go
type Filter[T constraints.Ordered] struct {
op BoolOp // 布尔操作,比较左值和右值的大小
left Expr // 左值表达式,使用 EvalExpr 可获取值
right Expr // 右值表达式,使用 EvalExpr 可获取值
child Operator // 子操作迭代器,也就是需要执行过滤操作的 Tuple 集合。
getter func(DBValue) T // 数据类型转换,从 DBValue 转换到 泛型T,例如从 IntField 转 int
}其中的 child 是 Operator 接口,有迭代器方法,可以从中获取需要执行过滤操作的 tuple , 例如
-
select * from t where age > 18 那么 child 就是整个表 HeapFile 对象。
-
select * from t1 where age > (select age from t2) 那么 child 就是子表的 Project 对象。
filter_op : Iterator
很简单,取待过滤的 Tuple ,即 child 中的 Tuple , 循环迭代器直到找到一个符合条件的 Tuple 的返回。
左值和右值都是一个表达式,直接用提供好的 EvalExpr 方法获取列值,值之前的比较用提供好的 evalPred 方法。
注意返回值也是一个迭代器,注意闭包嵌套的写法。

filter_op : Descriptor
过滤操作针对的是左值和右值,直接返回左右表达式对应的 FieldType 即可。

EqualityJoin : Descriptor
type EqualityJoin[T comparable] struct {
// Expressions that when applied to tuples from the left or right operators,
// respectively, return the value of the left or right side of the join
leftField, rightField Expr
left, right *Operator //operators for the two inputs of the join
// Function that when applied to a DBValue returns the join value; will be
// one of intFilterGetter or stringFilterGetter
getter func(DBValue) T
// The maximum number of records of intermediate state that the join should use
// (only required for optional exercise)
maxBufferSize int
}
等值 join, 相当于from t1 join t2 on t1.xx = t2.yy,其中 left, right 分别对应左右两个表,leftField, rightField 分别代表连接的字段。
根据函数注释,Descriptor 函数返回的是左右两边的 desc 组合, 借助之前实现的 TupleDesc 的 merge 方法

EqualityJoin : Iterator
表连接的实际逻辑就相当于两层嵌套的 for 循环,外层循环表 t1 的每一行,内层循环表 t2 的每一行去匹配外层的行
最直接的实现也是这样的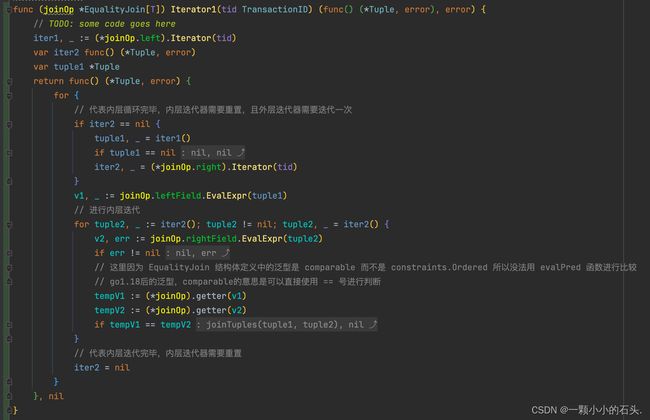
需要注意的是,这里因为 EqualityJoin 结构体定义中的泛型是 comparable 而不是 constraints.Ordered 所以没法用 filter 里面的evalPred 函数进行比较, go1.18后的泛型,comparable的意思是可以直接使用 == 号进行判断。 实验手册已经指明了,表连接就是等值连接,不支持其他大小关系。
以上直接 join 的方式无法通过 join_op_test.go 中的 TestBigJoinOptional 测试,原因是性能太差导致超时。优化后可以获得额外的课程分数奖励。Join 操作是常见的 SQL 操作,所以优化方案备受关注和研究,常见的手段有 Sort-Merge Join 、Hash Join 等,无论怎么优化都但无法避免两个表的笛卡尔积操作,但可以以空间换时间来提高性能,例如这里使用 Sort-Merge Join.
先对两个表进行排序[根据 join 列值],时间复杂度为 O(n*logn),因为把两个表的所有数据都拉取到内存中了,所以空间复杂度 O(m+n),当然如果join列有索引的话,那么相当于已经有序,直接迭代器取出来即可,不需要在内存中再做排序。然后对排序好序的两个表进行连接,其实就是双指针算法,leetCode 上一大把,可抽象为找出数组 [1,2,2,4,5] 和 [0,2,2,4,4,6] 的相等元素对,有6组 [2,2] [2,2] [2,2] [2,2] [4,4] [4,4] 最大时间复杂度为 O(m+n)

如果考虑空间复杂度不超过 maxBufferSize 的要求,则需要采用 Hash Join 方法, 为其中一张表(通常是较小的表,称为 "build" 表)创建一个在内存中的临时哈希表,驱动另外一个表做循环匹配。需要注意的是解决 hash 冲突问题。时间复杂度约等于 O(m/size * n) 空间复杂度为 O(size)
通过理论推导和实际验证,得出一般情况下 join 操作选择小表做驱动表有更好的性能。又根据被驱动表有无索引,分别为 ndex nested-loop join 和 block nested-loop join 两种方法,进一步multi-range read优化,针对多个id先排序再去回表,约等于顺序读聚簇索引。大表的join对buffer pool不断的读入和淘汰,不仅实时影响其他事务,而且在join结束后也要靠后续的查询去恢复命中率。
Exercise 2
agg_op
实现一些聚合操作,对应 sql 中的 select name,max(age) from t group by name
agg_op.go 中已经提供了一个 CountAggState 案例做参考,那么基本可以直接依葫芦画瓢直接cv
// interface for an aggregation state
type AggState interface {
// Initializes an aggregation state. Is supplied with an alias,
// an expr to evaluate an input tuple into a DBValue, and a getter
// to extract from the DBValue its int or string field's value.
Init(alias string, expr Expr, getter func(DBValue) any) error
// Makes an copy of the aggregation state.
Copy() AggState
// Adds an tuple to the aggregation state.
AddTuple(*Tuple)
// Returns the final result of the aggregation as a tuple.
Finalize() *Tuple
// Gets the tuple description of the tuple that Finalize() returns.
GetTupleDesc() *TupleDesc
}AddTuple(): 指的是对一个新的 tuple 做聚合会发生什么,例如对于 sum 操作会发生相加,对于 max 操作会和已有的 max 值做比较赋值。
Finalize():执行完聚合操作后,最终返回一个 tuple ,例如对于 avg 会返回一个平均值 tuple
GetTupleDesc(): 返回执行聚合后形成的列信息,例如 sum 操作最后会返回一个 int 列 tuple
以下给出 AvgAggState的代码,其他的聚合agg代码类似。

agg_state
对应 group by 分组和聚合器逻辑。
type Aggregator struct {
// Expressions that when applied to tuples from the child operators,
// respectively, return the value of the group by key tuple
groupByFields []Expr
// Aggregation states that serves as a template as to which types of
// aggregations in which order are to be computed for every group.
newAggState []AggState
child Operator // the child operator for the inputs to aggregate
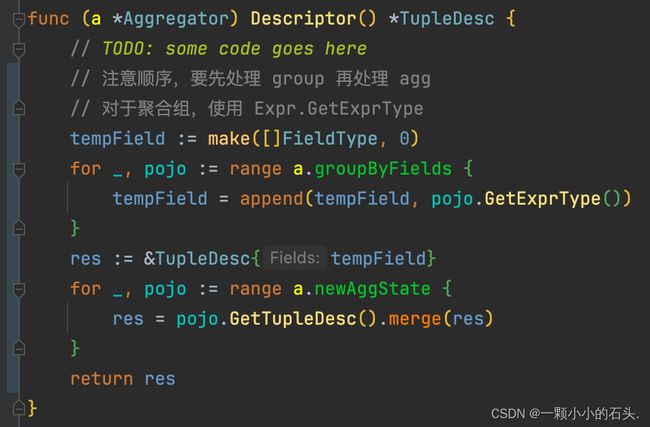
}Descriptor
对于一个 sql 分组查询: select name,max(age) from t group by name , 很明显返回的列应该是分组列 + 聚合列,所以这里拼接一下。
extractGroupByKeyTuple
已经实现好的 Iterator 中调用,作用是 从给定的 tuple 中提取聚合字段, 生成新的 tuple 并返回

getFinalizedTuplesIterator
例如 select name,count(name) from t1 group by name 结果应该是 :
列信息: name,count 行信息 :sam,1 geo,3
入参 groupByList 就是结果所有的分组列组成的行,例如 sam 和 geo
入参 aggState 是聚合列以及列的结果, 例如在name列上聚合的 1 和 3
需要把上面两种列组装起来,返回一个迭代器

Exercise 3
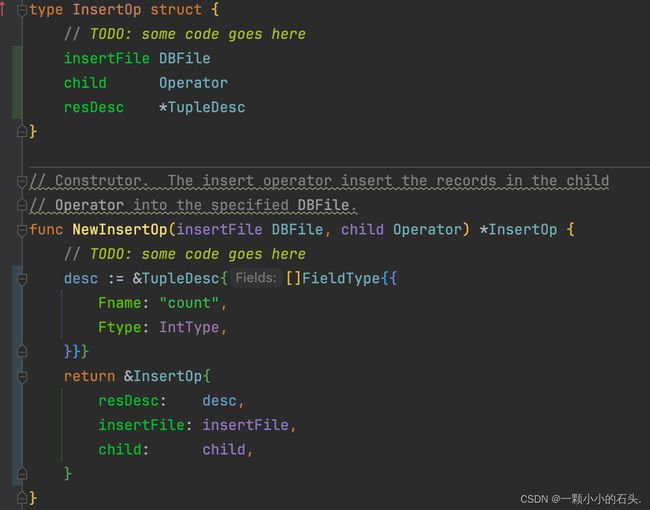
删除和新增操作,比较简单,这里以新增为例。注意返回值是一个名为 count 的列,表示成功了多少行数据。

Exercise 4
project_op 投影操作是整个实验二的难点,比较抽象。在之前实验一的 tuple.go 中,我们实现了 project 方法,功能是 根据 fields 把 tuple 中的匹配字段挑出来形成新的 tuple,理解了"投影"的内涵。
project_op: Descriptor
// Project 投影,针对某个Tuple集合,仅选取指定的列 例如:select name,age from person
type Project struct {
selectFields []Expr // required fields for parser
outputNames []string // 相当于 select name as n 中的 as 重新命名
child Operator
//add additional fields here
// TODO: some code goes here
distinct bool
}列描述符不难理解,直接取 selectFields 字段就可以,但必须把输出的名字 outputNames 注入进去,也就是列名 alias , 否则在重命名的场景下无法通过测试。

project_op: Iterator
迭代器的难点不在于 distinct 的逻辑,而是如何构造返回数据,具体说就是如何选取列。

Exercise 5
排序操作
// TODO: some code goes here
type OrderBy struct {
orderBy []Expr // OrderBy should include these two fields (used by parser)
child Operator
//add additional fields here
ascendingList []bool
}order_by_op:Descriptor

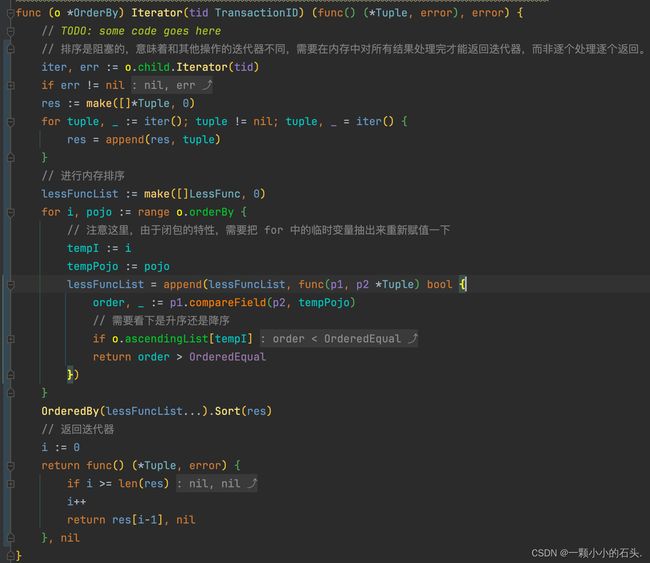
order_by_op:Iterator
重点是排序函数的编写,注释中已经指引了,在 golang 语言中需要让对象数组实现 sort.Sort 接口,并让我们去参考 https://pkg.go.dev/sort 中的代码,发现正是我们想要的,直接依葫芦画瓢。
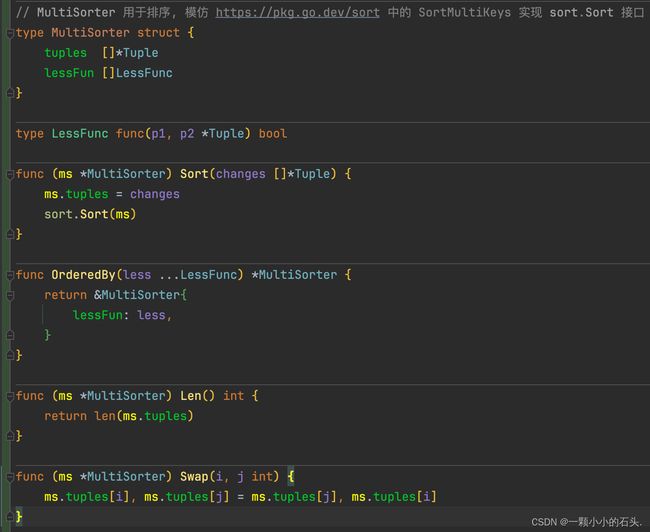

Golang 中的接口是隐式实现,不像 Java 那样明确。所以 GoLand IDE 的提示就很重要了。实现好排序 Sort 接口之后,进一步实现迭代器接口就很容易了。
Exercise 6
Limit 截取操作
type LimitOp struct {
child Operator //required fields for parser
limitTups Expr
//add additional fields here, if needed
}实现起来也比较简单,只需要在迭代器外维护一个计数器即可
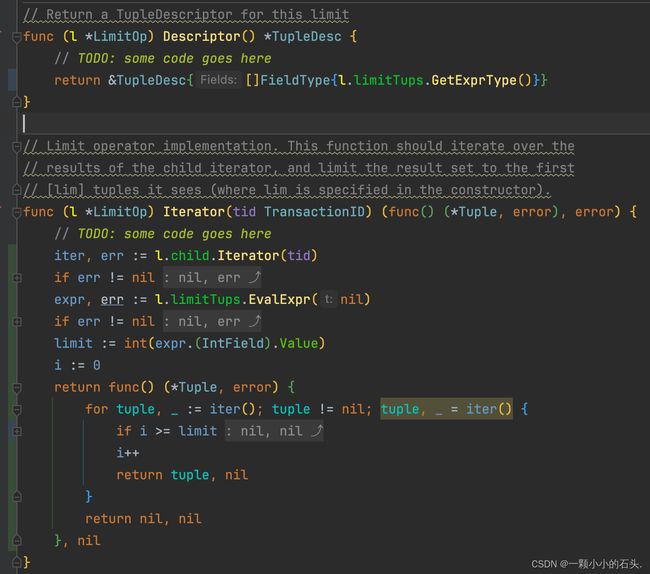
Exercise 7
检测我们的上述实现是否能跑通基本的SQL。无需任何修改直接 运行 simple_query_test.go 如果全部通过,不一定说明代码没问题,还需要能跑通 easy_parser_test.go 检测程序。
思考
SQL 解析器
实验仅仅让编写基础操作的代码,但上层调用者没有让人编写。最精髓的 SQL 解析器已经提供了,代码在 parser.go 中 ,复杂度和难度都较大,值得学习和参考。详细阅读逻辑执行计划和物理执行计划。
其他
通过实验能理解到作为普通 curd body 考虑不到的地方。例如:
-
实现底层join逻辑之后,对不同的 join 算法、有无索引等对查询的性能和内存影响是怎样的?
-
实现 select distinct 逻辑之后,了解 distinct 导致迭代器需要先拉取全量数据对性能的影响,order by同理。