MySQL知识点总结(二)——explain执行计划、SQL优化
MySQL知识点总结(二)——explain执行计划、SQL优化
- explain执行计划
-
- type
- possible_keys
- keys
- extra
- SQL优化
-
- SQL优化的流程
- SQL优化技巧
-
- 范围查询优化
- 排序优化
- 分组查询优化
- distinct优化
- 分页查询优化
- join关联查询优化
- 排序分页 + 关联查询
- 分组 + 关联查询 + 排序
- in与exists的选择
- join查询原理
-
- NLJ
- BNL
explain执行计划
explain语句用于查看MySQL对某条SQL的执行计划,是我们进行SQL优化时会使用到的一个工具。

explain包含的所有信息如下。
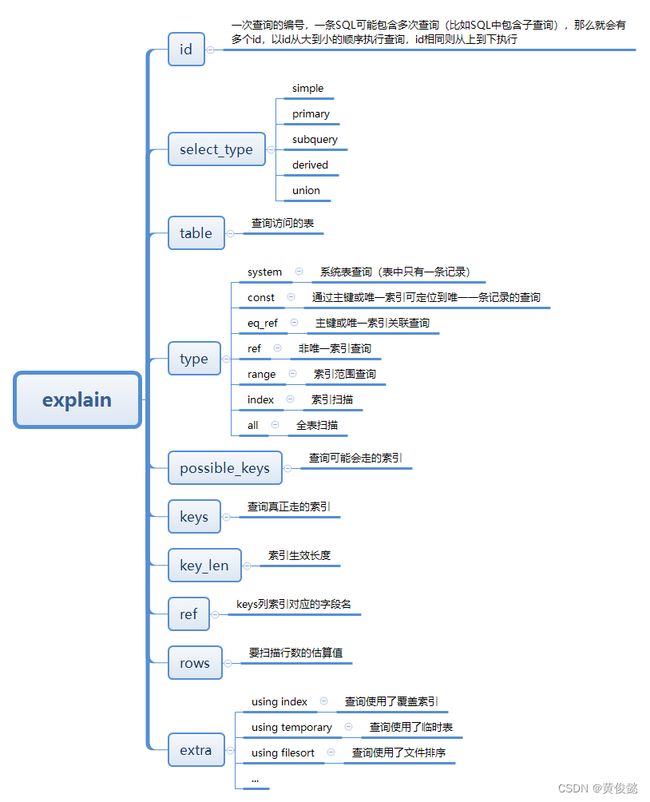
其中比较重要的信息是type、possible_keys、keys、extra这几列。
type
这一个信息比较重要,可以通过type列的信息分析出这次查询是否有走索引、走的是唯一索引还是普通索引。
system:表示当前查询的是系统表,也就是表中只有一条记录的表,这种查询是速度最快的,但这是比较极端的情况,因为一般情况下很少有表是只有一条记录的。
const:表示当前查询通过主键索引或者唯一索引定位到表中的唯一一条记录,这种查询的速度也是非常高的,仅次于system查询。
eq_ref:表示本次查询也是走了主键索引或者唯一索引,但是还需要进一步进行表关联查询。
ref:表示本次查询走了普通索引。
range:表示本次查询利用索引进行范围查询。
index:表示本次查询利用了索引进行全索引扫描。
all:本次查询进行了全表扫描,是性能最低的查询。
一般我们要控制我们的查询至少是range以上,如果出现了all,是要进行优化的。
possible_keys
possible_keys是本次查询可能用到的索引,但不是本次查询真正使用的索引,就是有可能使用了,也有可能没有使用。
比如有一个二级索引,但是如果走这个二级索引需要回表才能取到查询需要返回的字段,而MySQL判断回表次数过多,性能不如全表扫描,就有可能放弃走这个二级索引。
keys
keys是本次查询真正使用到的所有,如果possible_keys中有索引出现,而keys中显示没有走该索引,那么就表示存在索引失效的情况,就要分析失效的原因并进行优化。
比如还是上面那一种情况,possible_keys显示本次查询有一个二级索引可以走,但是keys列却显示MySQL没有使用这个二级索引,那么我么经过分析就可以发现原因就是存在大量的回表导致MySQL放弃了走这个索引。于是我们可以优化这个二级索引,把查询需要返回的字段列也加到二级索引中组成一个联合索引,这样MySQL发现不用回表也能取到所有需要返回的字段,就不会再回表进行查询,这时走二级索引查询的性能就会大大提高,MySQL就会选择走二级索引进行查询。
比如我们有一张student表:
CREATE TABLE `student` (
`studentno` varchar(10) NOT NULL,
`loginpwd` int(11) NOT NULL,
`studentname` varchar(40) NOT NULL,
`sex` varchar(2) NOT NULL,
`gradeid` int(11) NOT NULL,
`phone` varchar(20) NOT NULL DEFAULT '0',
`address` varchar(30) DEFAULT NULL,
`borndate` datetime DEFAULT NULL,
`email` varchar(28) DEFAULT NULL,
PRIMARY KEY (`studentno`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
我们有一个查询:
SELECT borndate, studentname, phone from student where borndate > '1990-06-25 00:00:00';
在没有任何索引时,走的是全表扫描:

如果我们给borndate列加一个普通索引:

然后再次查询执行计划:

发现并没有走我们添加的索引,只是possible_keys出现了我们添加的索引。
然后我们修改一下我们添加的索引,把查询需要返回的字段也加到这个索引里面去。

然后再次查看查询计划:

我们发现这次就走了我们的索引,那是因为在二级索引“idx_borndate”中,已经包含了查询需要返回的“borndate”、“studentname”、“phone”三个字段,不需要回表进行查询,性能比起全表扫描大大提升,因此MySQL就会选取该索引进行查询。
extra
这一列是额外信息,也是非常重要的一列。
比如当我们看到extra这一列出现“using index”时,表示我们当前这个查询使用了索引覆盖,比如我们上面的这个例子最后就使用了索引覆盖。

当我们看到“using filesort”时,表示当前查询的排序使用了文件排序,文件排序性能是比较低的,那就要考虑是否要优化了。

当我们看到extra列显示“using temporary”时,表示查询使用了临时表。比如select distinct查询一般就会使用到临时表,MySQL会创建一张临时表,利用这张临时表进行去重。

SQL优化
SQL优化的流程
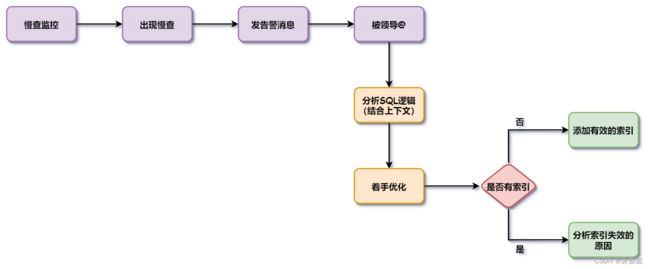
在工作中,有时会遇到SQL优化。比如我们公司的每一个服务,都有慢查询监控,当某个服务出现慢查询时,监控系统就会通过企业微信的机器人发消息的接口,往群里面发一条慢查询的消息。刚好这个是自己负责的服务的话,那么就会被领导@,然后就要进行对这条慢查SQL优化了。
但是在优化之前,我们应该先读懂这条SQL的逻辑,必要时还要回到这条SQL的出处,代码里面写这条SQL的地方,结合上下文理解这条SQL要实现的功能,这样才能保证我们进行SQL优化之后,不会改变这条SQL原有的功能,以至于改出bug。
然后就可以着手进行优化了。首先看一下这条SQL是否没有走索引,如果是的话,就要考虑给这条SQL的查询添加有效的索引;如果已经有索引了,但是却没有走索引,就要分析索引失效的原因。
SQL优化技巧
范围查询优化
就是上面的那个覆盖索引优化的例子。
SELECT borndate, studentname, phone from student where borndate > '1990-06-25 00:00:00';
当我们发现查询没有走我们预先创建的二级索引时,一般是由于有大量回表导致的,我们把查询需要返回的字段也添加到索引中,组成一个联合索引,一般就会走索引。
排序优化
比如我们有一个查询:
SELECT studentname, phone FROM student ORDER BY studentname DESC;
查询执行计划,走的是文件排序。

之所以走文件排序,是因为“studentname”字段是无序的,只能开辟一块空间,使用这一块空间进行排序。
如果“studentname”字段的排列是有序的,MySQL是不会使用文件排序的,而给“studentname”字段创建索引,就是使其排列变成有序的方式。
于是,我们给它建立一个联合索引,包含“studentname”和“name”这两列,之所以是联合索引,是因为如果只给“studentname”这一列建立索引的话,那么还是不会走这个索引,因为还要回表去取phone这一列的值。

查询执行计划,发现使用到了我们创建的索引,并且extra列中的“using filesort”消失了。

分组查询优化
比如我们有一个查询:
EXPLAIN SELECT gradeid, sum(gradeid) FROM student GROUP BY gradeid;
查看执行计划:

extra列出现了“Using temporary; Using filesort”,表示即使用了临时表,又有文件排序。
MySQL默认会对分组后的结果进行排序,如果这个排序不是我们需要的,我们可以在SQL语句后面添加“order by null”就可以避免排序。

而“Using temporary”表示使用到了临时表,之所以用了临时表,是因为要分组的字段(gradeid)在表中是无序的,因此要建立一张临时表,进行分组统计,如果要分组的字段在表中是有序的,那么只需要顺序遍历,就可以完成分组统计。
因此我们添加一个索引:

再次执行查询计划:

此时发现分组查询走了索引,extra列中没有了“Using temporary; Using filesort”,而且也不需要添加“order by null”语句。
distinct优化
比如我们还是对“gradeid”这个字段进行去重统计。
SELECT DISTINCT gradeid FROM student;

发现extra列显示了“Using temporary”,表示MySQL使用了临时表进行去重。这里使用临时表的原因,和上面分组统计的使用临时表的原因是一样的,如果我们给要去重的字段添加索引,就不需要使用临时表进行去重了。
因此我们添加一个索引:

再次查询执行计划:

发现“Using temporary”已经没了。
分页查询优化
分页查询的SQL应该是经常出现性能问题的SQL了,因为我们做业务开发的很多场景都有分页查询,是出现频率最高的SQL类型。
比如我们要对人员的出生日期从大到小做倒序排序,然后分页查询人员姓名和出生日期:
SELECT studentname, borndate FROM student ORDER BY borndate DESC limit 20, 10;
查看执行计划:

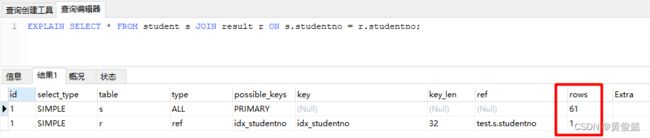
发现做了全表扫描,并且使用了文件排序。这里可以注意一下“rows”这里列,我这个表只有61条数据,这里显示“61”,表示扫描了整张表的61条数据。
这里使用文件排序的原因还是因为borndate字段是无序的,我们给borndate添加索引。

执行查询计划

发现还是走了全部扫描加文件排序,这是因为使用“idx_borndate”这个索引有回表查询的成本,MySQL于是放弃该索引。而回表的原因是“idx_borndate”这个索引没有studentname这个字段,而studentname这个字段时查询需要返回的字段,是必须的,但是通过“idx_borndate”这个索引无法取到,因此只能回表。
于是,我们可以通过内连接进行优化。
SELECT studentname, borndate FROM student t1 INNER JOIN (SELECT studentno FROM student ORDER BY borndate DESC limit 20, 10) t2 on t1.studentno = t2.studentno;
再次查看执行计划:

此时我们发现文件排序没有了,而且MySQL走了我们创建的索引“idx_borndate”。而且扫描行数比原先的61行要少,如果表数据量大的话,这个效果会更加明显。
经过内连接优化后,MySQL首先通过“idx_borndate”索引,找到分页后的要返回的行数据对应的主键studentno,然后扫描这10个studentno,从主键索引中取到对应行记录的studentname和borndate字段。
还有一种优化手段,就是建立联合索引“(borndate, studentname)”,这样就不需要回表也能拿到studentname字段,于是MySQL就会选择走我们的索引。

查看执行计划

查询MySQL走了我们的索引,而且SQL也变得简单多了。
join关联查询优化
join查询的优化要记住两点:
- 小表驱动大表
- 被关联表的关联字段要有索引
小表驱动大表的意思是,数据量小的表作为驱动表,去关联查询数据量大的表。如果此时被关联表的关联字段有索引,那么关联查询的扫描行数相当于小表的扫描行数,性能就会比较高。如果关联查询没有走索引的话,MySQL就会使用“join buffer”进行关联查询,性能就会比较低。join buffer可以理解会在内存中开辟一块空间,把驱动表放到这个内存空间,然后扫描被驱动表的每一行,到这个内存空间中进行遍历匹配。
比如我们除student表以外,还有一个成绩表result,记录学生的考试成绩:
CREATE TABLE `result` (
`id` int(11) NOT NULL,
`studentno` varchar(10) NOT NULL,
`subjectid` int(11) NOT NULL,
`score` int(11) NOT NULL,
`examdate` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_studentno` (`studentno`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
在没有任何优化的情况下,两张表的关联查询的执行计划如下:

resutl表有87条记录,student表有61条记录,按理说student表示小表,应该作为驱动表,但是因为result中的studentno字段没有索引,因此MySQL选择result表作为驱动表,这样就可以用上student表中的主键索引,扫描行数就是result表的记录数87条。
如果我们给result表的studentno字段加上索引:
MySQL就会选择student表作为驱动表,因为student表的数据量更小,更适合作为驱动表,而result表中的studentno字段又有索引,关联查询可以通过result表中studentno字段的索引直接定位,这样扫描的行锁更小,优化到61行。
排序分页 + 关联查询
比如我们要对学生的考试成绩从高到低进行倒序排序,然后分页取排序后的第20~29这十条数据,然后关联查询学生表,返回学生姓名和分数。
SELECT s.studentname, r.score FROM student s JOIN result r ON s.studentno = r.studentno ORDER BY r.score DESC LIMIT 20, 10;
没有任何优化时,执行计划是这样:

由于需要对result表的score字段进行排序,因此MySQL还是选择了result表作为驱动表,并且score字段没有索引,所以只能使用文件排序,因此extra列出现了“Using filesort”,排序结果再跳过开始的20行取中间10行,到student表中进行关联查询。
此时我们可以给result表添加一个联合索引来进行优化:
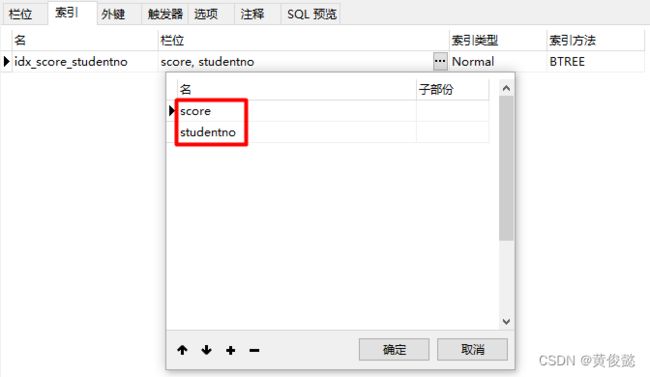
我们修改一下result表中的索引,变成一个联合索引,并且score是索引中的第一个字段,studentno是索引中的字段。这样,因为索引中的score排列是有序的,MySQL就不需要进行文件排序,并且MySQL可以从联合索引中取到关联查询需要的studentno字段,因此,也不需要回表。
查看执行计划:

我们发现文件排序没有了,并且扫描行数优化成30行,如果表数据量大的话,性能提升是很明显的。
但是要注意的时,这里之所以扫描result表时MySQL走了索引,是因为不需要回表查询result表中需要返回的字段,如果返回结果中包含了result表中的某个字段,并且这个字段是“idx_score_studentno”中没有的,那么由于有回表查询的成本,MySQL就不会走这个索引。比如我们把SQL语句改成查询所有字段“select * from …”,在代码中再从查询结果中取studentname和score这两个字段。

可以发现MySQL没有走索引,并且使用了文件排序,原因是“idx_score_studentno”索引中不包含result表中需要返回的所有字段,还要进行回表查询,还不如全部扫描。 所以“select *”这种写法真的会导致很多索引优化失效,我们应该时刻记着要按需查询,按需查询不仅可以减少MySQL查询返回结果的大小,而且可以有效的进行索引优化 。
分组 + 关联查询 + 排序
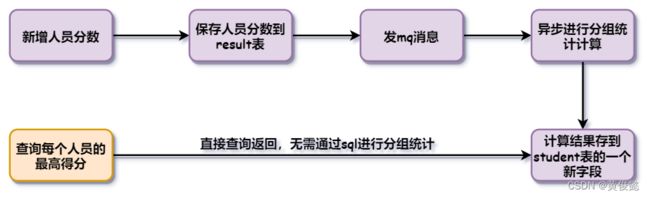
比如我们要分组统计每个学生的最高得分,然后对分组统计结果进行分页查询
SELECT s.studentname, max(r.score) max_score FROM student s JOIN result r ON s.studentno = r.studentno GROUP BY s.studentno ORDER BY max_score DESC LIMIT 20, 10;
没有做任何优化时,查看查询计划:

MySQL选择了先对result表进行分组,得到每个人的最高分,然后到student表关联查询得到studentname学生姓名,这样关联查询可以使用到student的主键索引。
我们给result建立一个联合索引:

这样,MySQL就可以通过result表的索引“idx_studentno_score”得到每个学生的最高分数。
查看执行计划:

虽然还是出现了“Using temporary; Using filesort”,但是扫描行数以大大降低,并且这次MySQL选择了student表作为驱动表,因此关联查询result表是可以走上索引的,性能还是有所提升的。
但是这种分组、排序、关联、分页全都有的SQL,一般是性能问题高发SQL。如果业务上允许的话,可以通过建立冗余字段进行优化去掉关联查询;或者异步进行分组统计的计算,然后拿一个新的字段去存分组统计的结果,查询时就可以直接查询返回,无需再进行分组统计。
in与exists的选择
in查询和exists查询,可以互相替代,也能实现相同的查询效果。但是它们的原理有所不同,在不同情况下使用也有所差别。
比如我们现在有一个SQL:
select * from A where A.b_id in (select id from B);
它可以用下面一条SQL替代:
select * from A where exists(select 1 from B where B.id = A.b_id);
in查询是拿in子查询的结果,到外层查询的表中进行匹配;而exists查询是拿着外层查询的结果,在内层查询里面进行匹配,匹配结果返回true或者false,true则保留这条结果,false则丢弃这条结果。
因此,基于“小表驱动大表”的原则,当B表是小表时,适合是用in查询;如果B表较大,而A表较小,那就应该选择exists查询。

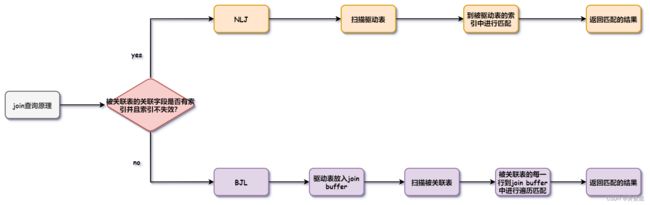
join查询原理
MySQL的join查询有两种算法,一种是Nested-Loop Join(NLJ)算法,一种是Block Nested-Loop Join(BNL)算法。
NLJ
NLJ是当被关联表的关联字段存在索引(并且不失效)时会使用的一种算法。MySQL会扫描驱动表的每一行,然后到被关联表的关联字段对应的索引中进行匹配,返回匹配的数据。
BNL
BNL是当被关联表的关联字段没有索引时会使用的一种算法。MySQL会扫描驱动表,把驱动表(需要返回的字段)放到一个内存区域中(join buffer),然后扫描被驱动的的每一行,到join buffer中进行遍历匹配,返回匹配的记录。
可以看出BNL的性能是比NLJ要差的的,这也是为什么我们在关联查询时一般要保证被关联表的关联字段有索引的原因。