腾讯发表多模态大模型最新综述,从26个主流大模型看多模态效果提升关键方法
在大规模语言模型(LLMs)通往通用人工智能(AGI)的道路中,从传统的单一的“语言模态”扩展到“图像”、“语音”等等的“多模态”必然是大模型进化的必经之路。
在过去的 2023 年,多模态大规模语言模型(MM LLMs)伴随着大模型本身的飞速进化也不断的产生新的突破,而年底谷歌 Gemini 的宣传片更是一举提升了人们对多模态大模型上限的想象。

而最近腾讯 AI Lab 发表了一篇关于多模态大模型的最新综述《MM-LLMs: Recent Advances in MultiModal Large Language Models》,整理归纳了现在多模态大模型的整体架构设计方向,并且提供了现有主流的 26 个多模态大模型的简介,总结了提升多模态大模型性能的关键方法,可谓一文跟上 MM LLMs 的最新前沿,一起来看看吧!
论文题目:
MM-LLMs: Recent Advances in MultiModal Large Language Models
论文链接:
https://arxiv.org/pdf/2401.13601.pdf
多模态大模型架构
如果对过去一年主流的多模态大模型按时间顺序进行排列,可以看到这样一张时间线图:
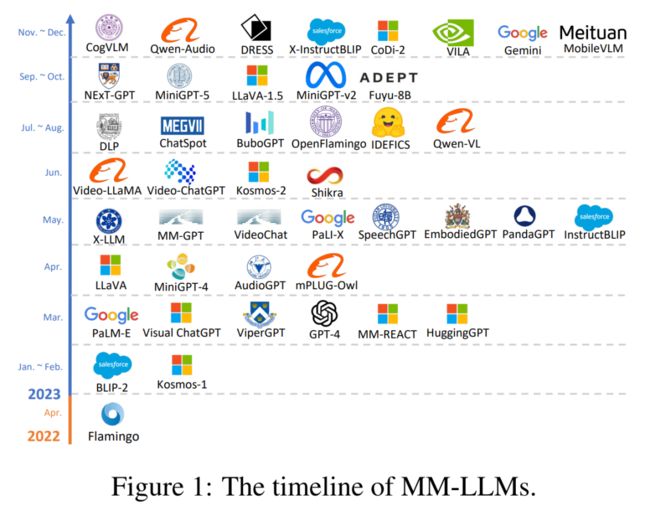
多模态大模型脱胎于大模型的发展,传统的多模态模型面临着巨大的计算开销,而 LLMs 在大量训练后掌握了关于世界的“先验知识”,因而一种自然的想法就是使用 LLMs 作为多模态大模型的先验知识与认知推动力,来加强多模态模型的性能并且降低其计算开销,从而多模态大模型这一“新领域”应运而生。
作为在语言模态上得到了良好训练的 LLMs,MM LLMs 面对的主要任务是如何有效的将 LLMs 与其他模态的信息进行结合,使其可以综合多模态的信息进行协作推理,并且最终使得 MM LLMs 的输出与人类价值观保持一致。
多模态大模型的整体架构可以被归类为如下图的五个部分,整个多模态大模型的训练可以被分为多模态理解与多模态生成两个步骤。多模态理解包含多模态编码器,输入投影与大模型主干三个部分,而多模态生成则包含输出投影与多模态生成器两个部分,通常而言,在训练过程中,多模态的编码器、生成器与大模型的参数一般都固定不变,不用于训练,主要优化的重点将落在输入投影与输出投影之中,而这两部分一般参数量仅占总体参数的 2%。
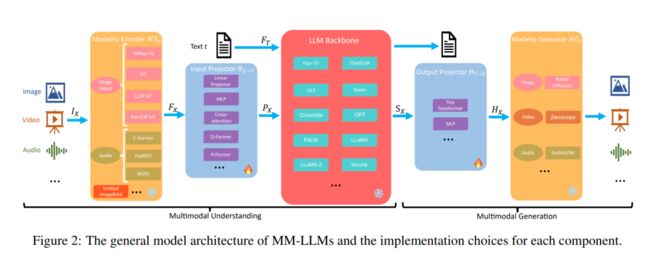
多模态编码器
如果用公式表示,多模态编码器(ME)完成的任务是编码输入的多模态信息 ,将其映射到特征空间中获得 :
这里 用来表示如图像、视频、音频、3D 等的不同多模态信息。不同的模态对应有不同的模态编码器,对于图像,常用的编码器有 NFNet-F6、ViT、CLIP ViT 以及 Eva-CLIP ViT。其中 NFNet-F6 是一种抛弃了 Batch Norm 的 ResNet 变体,而后面三种都基于 Vision Transformer 方法。
对于音频而言,常用的编码器是 CFormer、HuBERT、BEATs 与 Whisper。对于三维点云数据而言,编码器有 ULIP-2,PointBERT 等。而对于视频而言,常用的方法是将视频均匀采样五帧,再进行与图像相同的输入编码。此外,还有类似 ImageBind 这类 any to ang one 的涵盖六种模态的统一编码器可以使用。
输入投影
输入投影主要用于将编码器编码得到的特征向量对齐到大模型擅长的文本模态空间 之中。具体而言:
其中, 一般指输入的 Prompt,为了训练输入投影,其目标是给定多模态数据集{,},最小化其文本生成 Loss:
通常,输入投影可以直接使用多层感知器 MLP,或者也可以使用更加复杂的如 Crossattention、Q-Former、PFormer 等。
大模型主干
作为多模态大模型的核心,大模型主干主要用于参与模式的表示、语义理解、推理与决策输出,一般而言,在MM LLMs,大模型主干主要产生直接的文本输出 与指导多模态生成器生成多模态信息的信号 ,即:
MM LLMs 中常用的大模型主干有 Flan-T5,ChatGLM,UL2,Qwen、Chinchilla、OPT、PaLM、LLaMA、LLaMA-2 和 Vicuna。
输出投影
对称的,在大模型主干后紧跟着输出投影 将多模态信号 映射到多模态生成器的特征空间 :
类似的,给定数据集{,},输出投影的目标在于:
这里 是多模态生成器中文本条件编码器输入文本 后输出的多模态信息。输入投影通常使用 MLP 或者小型的 Transformer 进行构建。
多模态生成器
多模式生成器(MG)的任务是生成不同模态的输出,通常使用潜在扩散模型(Latent Diffusion Models,LDMs) 实现,例如非常有名的用于图像生成的 Stable Diffusion,以及用于视频合成的 Zeroscope、用于音频生成的 AudioLDM-2 等。
在训练过程中,首先将真实标题通过 VAE 获得潜在特征 ,通过给 添加噪音 构建噪音潜在特征 ,使用一个预训练的 Unet 计算条件 LDM 损失 同时优化输入投影与输出投影:
多模态大模型训练
整体多模态大模型的训练可以被划分为两个主要阶段:MM PT 和 MM IT。
其中,MM PT 主要利用 X-Text 数据集,对输入投影与输出投影进行优化,其中 X-Text 数据集有图像文本对 $(),交替图像文本对()$,常用的 X-Text 数据集如下:

类似 InstructGPT 与 InstructBLIP 的思路,MM IT 阶段(Instruction Tuning)主要包含有监督微调(SFT)与基于人类反馈的强化学习(RLHF),旨在使用一组指令数据对预训练的 MM LLMs 进行微调,在 MM IT 的过程在 MM LLMs 通过新的指令来增强其泛化能力,加强其 Zero-shot 的能力。
多模态大模型综述
介绍完多模态大模型的架构,那么多模态大模型哪家强呢?这篇综述总结了 26 种大模型的核心贡献与其发展趋势,归纳成一个表如下:

在这张表中,I——>O表示输入到输出模态,其中 I 表示图像,V 表示视频,A 表示音频,3D 表示点云,而 T 表示文字。整体各个模型详细的归纳整理了多模态大模型架构各个部分使用的各个组件,其中 #.PT 与 #.IT 指代表MM PT 与MM IT 的训练数据集规模。
根据这个表,比较有代表性的 MM LLM 有例如 BLIP-2,在输入投影中创新使用轻量的 Q-Former 引入了更加高效的资源框架,在 23 年 2 月份刚面世时在多个任务中取得 SOTA。LLaVA 首先将 IT 技术(Instruction Tuning)引入多模态领域,构成了最成熟的开源多模态大模型。
Mini GPT-4 将视觉编码器 BLIP-2 和大模型 Vicuna 进行结合训练,产生了许多类似于 GPT-4 中展示的新兴视觉语言能力。X-LLM 是中科院发布的多模态大模型,使用 Q-Former构建的 X2L 接口将多个单模态编码器与 LLM 进行对齐(中科院发布多模态 ChatGPT,图片、语言、视频都可以 Chat ?中文多模态大模型力作)

VideoChat 来自上海 AI Lab,提出了以 Chat 为中心的端到端视频理解系统,以可学习的方式集成了视频和语言的基础模型,通过构建视频基础模型与 LLMs 的接口,通过对接口进行训练与学习从而完成视频与语言的对齐(上海AI lab提出VideoChat:可以与视频对话啦),InstructBLIP 是 BLIP 作者团队的续作,将指令微调的范式用于 BLIP-2 模型上面,实现了灵活多样的特征提取。PandaGPT 将大型语言模型与不同模态对齐、绑定,实现了跨模态的指令跟随能力。
Qwen-VL 是阿里开源的多模态模型,包含 Qwen-VL 与 Qwen-VL-Chat 两个版本。MiniGPT-5 则以生成式 voken 概念为基础,创新了交错视觉语言生成技术。

从这些大模型之中,作者也归纳总结了 MM LLMs 的发展趋势与方向:
-
从具体的某一模态发展到任意到任意模型的转换(MiniGPT-4 → MiniGPT-5 → NExT-GPT)
-
从有监督微调到基于人类反馈的强化学习(BLIP-2 → InstructBLIP → DRESS)
-
多样化模态扩展(BLIP-2 → X-LLM,InstructBLIP → X-InstructBLIP)
-
更高质量的数据集(LLaVA → LLaVA1.5)
-
更高效的模型架构
多模态大模型 SOTA 与未来
统一上文中的 26 个多模态大模型,综述作者也让这些模型站上擂台,在主流的 18 个 VL 基准上对这些多模态大模型进行了测试,结果如下:

从这些 SOTA 中,作者总结了如下的几个“小trick”:
-
更高的图像分辨率可以纳入更多的视觉细节,有利于需要细粒度的任务,但是更高的分辨率会导致额外的训练与推理成本;
-
高质量的 SFT 数据可以显著的提升特定任务的性能;
-
在 VILA 中,可以发现对 LLM 主干进行微调可以促进对齐,实现更好的上下文学习,并且交替图像文本对也有利于多模态能力的形成
鉴古知今,从过去这一年多以来的多模态大模型的发展出发,作者总结了 MM LLMs 未来的发展方向,在增强模型性能方面:
-
从多模态到更多模态:目前主流的多模态停留在图像、视频、音频、3D和文本数据,但是现实世界中用于更多模态的信息(网页、表格、热图……);
-
统一的多模态:通过将各种类型的多模态大模型进行统一来实现各种具体的现实需求;
-
数据集质量的提高:当前的 MM IT 数据集还有很大的提升空间,未来可以在指令范围多样化等方面增强 MM LLM 的能力;
-
增强生成能力:大模型的主要能力尚且在“理解”这一层面,受制于 LDM 的容量,多模态大模型的生成能力还需要提升。
除了性能以外,当下的多模态大模型也呼唤着更加强大有效的评价基准,目前的基准有可能已经无法充分的挑战多模态大模型的能力。此外,多模态大模型也需要在轻量级/移动设备中部署迈出新的一步,为了在资源受限的平台中使用多模态大模型的能力,轻量级的实现至关重要,目前突出的方法有 MobileVLM,参数量少于 2000 万,大大提升了推理速度。具身智能是通往 AGI 的必由之路,多模态大模型在具身智能上的应用也需要进一步探索,目前的 MM LLMs 很大程度上还是静态的,无法适应具身智能动态多阶段的需求。
总结与讨论
在腾讯 2024 数字科技前沿应用趋势中,强调了“通用人工智能渐行渐近,大模型走向多模态,AI智能体(Agent)有望成为下一代平台”。当下多模态大模型不仅仅是学界新宠,也是未来行业发展进步的一大方向,站在这篇综述的基础之上,期待我们可以更快更好的理解未来多模态大模型的发展,赶上这波通用人工智能的新浪潮!
