python进程通信方式总结(三):共享内存
引言
在上一篇中,重点探讨了队列的原理以及它在进程通信的原理与应用场景,顺带提了下信号,因为我对信号用的不多,那么本篇想总结的是第五种通信方式——共享内存。
共享内存说明
共享内存是System V版本的最后一个进程间通信方式。共享内存,顾名思义就是允许两个不相关的进程访问同一个逻辑内存,共享内存是两个正在运行的进程之间共享和传递数据的一种非常有效的方式。不同进程之间共享的内存通常为同一段物理内存。进程可以将同一段物理内存连接到他们自己的地址空间中,所有的进程都可以访问共享内存中的地址。如果某个进程向共享内存写入数据,所做的改动将立即影响到可以访问同一段共享内存的任何其他进程。

具体内容参考: 进程间通信——共享内存(Shared Memory)
python共享内存
python中的共享内存如果单从multiprocessing来考虑,在python3.8前是有两种,managers和sharedctypes,managers是支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信和共享内存,而sharedctypes顾名思义,通过加载ctypes中的数据接口,来定义并共享数据类型。而到python3.8之后,官方又对多进程进行了更新,在manager下多加了几个类,其中包含了第三种内存共享类,叫SharedMemoryManager。
manager共享
关于manager的共享机制,因为它有socket网络在里面,所以支持的数据类型会多一点,但也会慢很多,它与上一节提到的manager一样,创建一个BaseManager对象。创建后,需要调用start()或get_server().server_forever()确保对象对于的管理器进程已经启动。
参数为:
- address参数,管理器服务进程监听的地址。如果值是None,则任意主机的请求都能建立连接。
- authkey参数,byte类的字符串。认真标识(验证码)
使用方法为:
-
start(), 为管理器开启子进程。
-
get_server(),返回一个Server对象。
-
connect(), 连接本地管理器对象到一个远程管理器进程
-
shutdown() 停止管理器的进程。配合start()。
-
register(typid, callable) 重要的类方法,凡是注册到管理器的类型/对象,就可以被网络上的不同进程共享了。
关于它的使用demo,一定要用类才能体现它的优势,所以个人推荐:
【原创】python multiprocessing.managers 分布式进程
上述例子根据张雪峰在多进程中的讲解,比较具有参考意义,但因为是Python2的代码,我将其改为了python3并跑了下试试:
# -*- coding:utf-8 -*-
# @version: 1.0
# @author: ZhangZhipeng
# @date: 2015-08-03
"""
稍微写了一下,linux/win7运行通过。个人建议分成四个模块
Server: 服务端, 数据中转
Server-Producer: 生产者,发送任务给Server
Server-Consumer: 消费者,处理Server收到Client的结果
Client: 客户端, 消费者处理任务
(没有想到好的类名,暂且这么表示吧)
下面是示例,Server和Master命名意义冲突,自行定义。
"""
import sys
import queue
import random
from multiprocessing.managers import BaseManager
from multiprocessing import freeze_support
SERVER_IP = '127.0.0.1'
SERVER_PROT = 9010
class ServerManager(BaseManager):
pass
class Server(object):
"""服务端
由于: 1.manager.start()后,client连接不上;
2. serve_forver()之前无法获取[结果队列],函数是循环函数(好像是阻塞进程),无法继续函数后代码
因此: 有一个类Master,用于获取[结果]。
建议:本类只作为服务端中转。 另建生产者,用于解耦。(put_data()生产数据)
"""
def __init__(self, task_queue=None, result_queue=None):
if not task_queue:
task_queue = queue.Queue()
if not result_queue:
result_queue = queue.Queue()
self.__task_queue = task_queue
self.__result_queue = result_queue
# 因为本类有充当了生产者,因此,不建议使用lambda
ServerManager.register("get_task_queue", callable=self._task_queue)
# ServerManager.register("get_result_queue", callable=self._result_queue)
# ServerManager.register("get_task_queue", callable=lambda:task_queue)
ServerManager.register(
"get_result_queue", callable=lambda: result_queue)
self._server_manager = ServerManager(
address=(SERVER_IP, SERVER_PROT), authkey=b'z')
def start(self):
print("Server: Start.")
server_manager = self._server_manager.get_server()
# start() 在linux 上也有问题.
# self._server_manager.start()
self._put_data()
server_manager.serve_forever()
print("Server: End.")
def _put_data(self):
for i in ["张志鹏", "罗静静"]:
print("Server: Put:%s" % i)
self._task_queue().put(i)
def _task_queue(self):
return self.__task_queue
# def _result_queue(self):
# return self.__result_queue
class Master(object):
"""服务端:创建Master类的原因见Server
此处仅作用于获取客户端发送至服务端的[结果],还可以当作生产者或者另建类.
"""
def __init__(self):
ServerManager.register("get_result_queue")
self._server_manager = ServerManager(address=(SERVER_IP, SERVER_PROT), authkey=b'z')
def start(self):
print("Server Master: Start.")
self._server_manager.connect()
self._get_result()
@property
def task_queue(self):
return self._server_manager.get_task_queue()
@property
def result_queue(self):
return self._server_manager.get_result_queue()
def _get_result(self):
print("Server Master: Try Get Result...")
while not self.result_queue.empty():
name = self.result_queue.get(timeout=10)
print("Server Master: Get: %s" % name)
class Client(object):
"""客户端:处理任务"""
def __init__(self):
ServerManager.register("get_task_queue")
ServerManager.register("get_result_queue")
self._server_manager = ServerManager(
address=(SERVER_IP, SERVER_PROT), authkey=b'z')
def start(self):
print("Client: Start.")
self._server_manager.connect()
task_queue = self.task_queue
result_queue = self.result_queue
while not task_queue.empty():
name = task_queue.get(timeout=1)
print("Client: Get: %s" % name)
user = {"name": name, "age": random.randint(20, 26)}
print("Client: Set: %s" % user)
result_queue.put(user)
@property
def task_queue(self):
return self._server_manager.get_task_queue()
@property
def result_queue(self):
return self._server_manager.get_result_queue()
if __name__ == "__main__":
freeze_support()
argv = sys.argv
argv.append("-")
def has_in_argv(keys):
if type(keys) in [int or bytes or str]:
return True if keys in argv else False
for key in keys:
if key in argv:
return True
return False
if has_in_argv(["-t", "--client", "client"]):
Client().start()
elif has_in_argv(["-m", "--matser", "master"]):
Master().start()
else:
Server().start()
基本上能说明manager的作用:

sharedctypes共享
关于这个,应该是目前python能达到的最快共享内存的方式,在python3.9以前,即使是3.8出来的shared_memory,我虽然没有做benchmark,但从感觉上sharedctypes一定快,因为它基于的是ctypes。
ctypes一般用来加载C中的dll或者so文件,通过其调用外部语言函数,我这里只考虑Linux下的so,因为Linux如果要运行python程序,其实开始是要通过动态库去找寻索引的,C语言为什么快我就不多说了,如果将调用ctypes的模块再编译成so文件,那运行起来该文件速度一定起飞,不过我没测过,python编译so文件可以看我之前的博文,而关于ctypes的官方文档为:
ctypes — Python 的外部函数库
文档中详细说明了支持数据类型,加载动态库只是它的基本功能,它比较实用的为结构体联合与传递指针(或以引用方式传递形参),前者结构体不用多说,它就是python的底层,而指针的话,因为在python里,变量都是使用的相对引用,基本上获取不到真正的指针,有了ctypes,才能比较完善的做更多关于内存的东西,具体的案例与demo可以看上述链接。讲回进程,multiprocessing也提前映射好了一组类型:
typecode_to_type = {
'c': ctypes.c_char, 'u': ctypes.c_wchar,
'b': ctypes.c_byte, 'B': ctypes.c_ubyte,
'h': ctypes.c_short, 'H': ctypes.c_ushort,
'i': ctypes.c_int, 'I': ctypes.c_uint,
'l': ctypes.c_long, 'L': ctypes.c_ulong,
'f': ctypes.c_float, 'd': ctypes.c_double
}
https://github.com/python/cpython/blob/master/Lib/multiprocessing/sharedctypes.py
这是开头直接定义的一个全局变量,然后sharedctypes.py中源码涉及到的主要函数为RawValue、RawArray、Value和Array,一般都习惯于用RawArray,那么demo为:
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import ctypes
import multiprocessing
import random
import time
import os
from multiprocessing import sharedctypes
import numpy as np
import cv2
def make_array(shape=(1,), dtype=np.uint8, shared=False, fill_val=None):
start = time.time()
np_type_to_ctype = {np.float32: ctypes.c_float,
np.float64: ctypes.c_double,
np.bool: ctypes.c_bool,
np.dtype('uint8'): ctypes.c_ubyte,
np.uint8: ctypes.c_ubyte,
np.uint64: ctypes.c_ulonglong}
if not shared:
np_arr = np.empty(shape, dtype=dtype)
else:
numel = int(np.prod(shape))
print(numel,"...nume1")
arr_ctypes = sharedctypes.RawArray(np_type_to_ctype[dtype], numel)
print(arr_ctypes,"......arr_ctypes")
np_arr = np.frombuffer(arr_ctypes, dtype=dtype, count=numel)
np_arr.shape = shape
if not fill_val is None:
np_arr[...] = fill_val
if time.time() - start > 0.002:
print("make time", time.time() - start)
return np_arr
class producer(multiprocessing.Process):
def __init__(self, queue):
multiprocessing.Process.__init__(self)
self.queue = queue
def run(self):
path = r"D:\Pictures\1200"
files = os.listdir(path)
images = []
for j, file in enumerate(files):
print(os.path.join(path,file),"........1111")
img = cv2.imread(os.path.join(path,file))
if img is None:
continue
if j > 100:
break
img = make_array(shape=img.shape, dtype=img.dtype, shared=True, fill_val=img)
images.append(img)
for i in range(20):
for j in range(len(images) - 1):
# print(images[j],"..........111111")
self.queue.put((images[j], j))
# time.sleep(0.05)
print("The size of queue is %s" % self.queue.qsize())
class consumer(multiprocessing.Process):
def __init__(self, queue):
multiprocessing.Process.__init__(self)
self.queue = queue
def run(self):
i = 0
# time.sleep(25)
start1 = time.time()
start = time.time()
print('start', start)
while True:
i += 1
(item, a) = self.queue.get()
# print('get time',time.time() - start, item.shape, self.name)
print(i, 'totaltime', time.time() - start1, time.time() - start)
start = time.time()
if __name__ == '__main__':
queue = \
multiprocessing.Queue()
process_producer1 = producer(queue)
process_producer2 = producer(queue)
process_consumer = consumer(queue)
process_producer1.start()
process_producer2.start()
process_consumer.start()
process_producer1.join()
process_producer2.join()
process_consumer.join()
参考自 python sharedctypes 多进程性能测试
有做修改,针对某些问题。上述能对sharedctypes中的rawarray直接进行测试速度,然后作者直接否定了rawarray的速度,这确实没有直接array来得快,因为从表层来看,array能直接申请得到,而rawarray还需要经过一层周转,往深了讲,在stack上有个大佬也贴出了两者在C语言上的不同。
我大概翻译一下就是我们有C代码在热循环中Array_init调用Python代码(setitem)。太慢了。 那这里就有必要搞清楚什么是热循环,关于python的源码构造是这样写的:
Array_init 热循环(较慢):
for (i = 0; i < n; ++i) {
PyObject *v;
v = PyTuple_GET_ITEM(args, i);
if (-1 == PySequence_SetItem((PyObject *)self, i, v))
return -1;
}
Array_ass_subscript 热循环(更快):
for (cur = start, i = 0; i < otherlen; cur += step, i++) {
PyObject *item = PySequence_GetItem(value, i);
int result;
if (item == NULL)
return -1;
result = Array_ass_item(myself, cur, item);
Py_DECREF(item);
if (result == -1)
return -1;
}
于是笔者尝试修改了热循环Array_init中的构造,重新编译让它更快,最终将3倍的时间差拉到持平,那么最后在排除其它小开销的情况下,笔者认为确实是热循环导致了rawarray的效率偏低,具体链接为:
Demystifying sharedctypes performance
但事实上抛开这个不讲,上述引用opencv的例子,其实是写的有问题的,我们前面提到了指针,而上述例子完全没有用到这个概念,sharedctypes的好处在于对于I/O较高的场景,我们能传递指针给其余进程,然后该进程再从共享内存中拿到图片或者大文件,上述例子的问题在于每读取到一张图片便申请了一块内存,然后put完就释放掉,但如果开始就申请一块很大的内存,传递指针与开始结束,那么速度将会有很大提升,这我是做过benchmark的,而且把一个几兆的文件丢队列里,会很慢,甚至会崩溃,而云存储的时间又不再可接受范围,那么这将是一个极其快的方式。
未完待续。。
2023/05/02更新
这篇博文上面内容是当初疫情第二年过年没回家,在图书馆更新了我对于python进程通信的一些理解,涉及层面还是有点薄,现在回过头来再做做更新,虽然我也有两年多没看过相关的,emmm,主要这种东西不会一直去动,写一次没出问题就延续了,不过还是重新做了一些功课,另外也是因为遇到一些事故,跟同事探讨了很多,感觉比较有收获,所以下面会多从源码角度去考虑。(PS:记起了那天在图书馆没位置,找了个书架,靠着边写,那时候很有感觉,以至于写到没电,草草结尾,留下了未完待续,但第二天来得早有座位却没感觉续写了,所以看书看了一天,然后就搁置了,emmm)
share_memory共享说明
这个东西,如果我没有记错的话,具体似乎是python 3.8.3以后的版本加入并完善的,因为2020年11月下旬的时候发布的Python3.8.6,当时该文件还处于更新状态,我看PR还有进行过一些修改,但到目前为止,应该是已经非常成熟了。
根据目前3.11.3的标准库文档可以知道,share_memory目前是写了三个类:
- class multiprocessing.shared_memory.SharedMemory :创建一个新的共享内存块或者连接到一片已经存在的共享内存块。每个共享内存块都被指定了一个全局唯一的名称。通过这种方式,进程可以使用一个特定的名字创建共享内存区块,然后其他进程使用同样的名字连接到这个共享内存块。
- class multiprocessing.shared_memory.ShareableList:提供一个可修改的类 list 对象,其中所有值都存放在共享内存块中。这限制了可被存储在其中的值只能是 int, float, bool, str (每条数据小于10M), bytes (每条数据小于10M)以及 None 这些内置类型。它另一个显著区别于内置 list 类型的地方在于它的长度无法修改(比如,没有 append, insert 等操作)且不支持通过切片操作动态创建新的 ShareableList 实例。
- class multiprocessing.managers.SharedMemoryManager:BaseManager 的子类,可用于管理跨进程的共享内存块。调用 SharedMemoryManager 实例上的 start() 方法会启动一个新进程。这个新进程的唯一目的就是管理所有由它创建的共享内存块的生命周期。想要释放此进程管理的所有共享内存块,可以调用实例的 shutdown() 方法。这会触发执行它管理的所有 SharedMemory 对象的 SharedMemory.unlink() 方法,然后停止这个进程。通过 SharedMemoryManager 创建 SharedMemory 实例,我们可以避免手动跟踪和释放共享内存资源。
参考来自:https://docs.python.org/zh-cn/3/library/multiprocessing.shared_memory.html
SharedMemory 使用方法
首先考虑SharedMemory,我根据说明,大致写了个demo,与之前的一样,还是以图像为例,简单版本如下:
import multiprocessing
import numpy as np
import cv2
from multiprocessing import shared_memory, Process
from multiprocessing.synchronize import Event
def write_process(shared_mem_name, shape, dtype, event):
# 打开现有共享内存对象
shared_mem = shared_memory.SharedMemory(name=shared_mem_name)
# 获取共享内存缓冲区
shared_array = np.ndarray(shape=shape, dtype=dtype, buffer=shared_mem.buf)
img = cv2.imread('image.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
np.copyto(shared_array, img)
# 发出同步信号
event.set()
# 关闭共享内存对象
shared_mem.close()
def read_process(shared_mem_name, shape, dtype, event):
# 等待同步信号
event.wait()
shared_mem = shared_memory.SharedMemory(name=shared_mem_name)
shared_array = np.ndarray(shape=shape, dtype=dtype, buffer=shared_mem.buf)
img = cv2.cvtColor(shared_array, cv2.COLOR_RGB2BGR)
cv2.imwrite('1_Image.jpg', img)
# 关闭共享内存对象
shared_mem.close()
if __name__ == '__main__':
ctx = multiprocessing.get_context()
event = ctx.Event()
# 创建共享内存对象并获取其名称
shape = (720, 1080, 3)
dtype = np.uint8
shared_mem = shared_memory.SharedMemory(create=True, size=int(np.prod(shape) * np.dtype(dtype).itemsize))
shared_mem_name = shared_mem.name
# 创建写进程
p1 = multiprocessing.Process(target=write_process, args=(shared_mem_name, shape, dtype, event))
p1.start()
# 创建读进程
p2 = multiprocessing.Process(target=read_process, args=(shared_mem_name, shape, dtype, event))
p2.start()
p1.join()
p2.join()
# 销毁共享内存对象
shared_mem.close()
shared_mem.unlink()
这里代码基本很简单,转格式其实也不需要,主要是刚开始写完,发现生成的是黑帧,加了些额外的操作,但没有效果,于是感觉可能是没有热启动,我写进程释放太快了,于是先对后一个进程做了sleep,发现是对的,又修改了下,加了同步机制。
这也证明,这种共享机制比较快,我于是又改了下读写函数,对读函数加入了循环次数:
def write_process(shared_mem_name, shape, dtype, event, num_iter):
# 打开现有共享内存对象
shared_mem = shared_memory.SharedMemory(name=shared_mem_name)
# 获取共享内存缓冲区
shared_array = np.ndarray(shape=shape, dtype=dtype, buffer=shared_mem.buf)
for i in range(num_iter):
img = cv2.imread('park.png')
cc = time.time()
print(f"current image {i} , and time is {cc}")
np.copyto(shared_array, img)
# 发出同步信号
event.set()
# 关闭共享内存对象
shared_mem.close()
def read_process(shared_mem_name, shape, dtype, event, num_iter):
# 打开现有共享内存对象
shared_mem = shared_memory.SharedMemory(name=shared_mem_name)
# 获取共享内存缓冲区
shared_array = np.ndarray(shape=shape, dtype=dtype, buffer=shared_mem.buf)
for i in range(num_iter):
# 等待同步信号
event.wait()
dd = time.time()
print(f"current image {i} , and time is {dd}")
cv2.imwrite(f'output/{i}_Image.jpg', shared_array)
# 发出同步信号
event.clear()
# 关闭共享内存对象
shared_mem.close()
使用tracemalloc测试了大概1000张为(1080,720,3)的image,测试结果为:
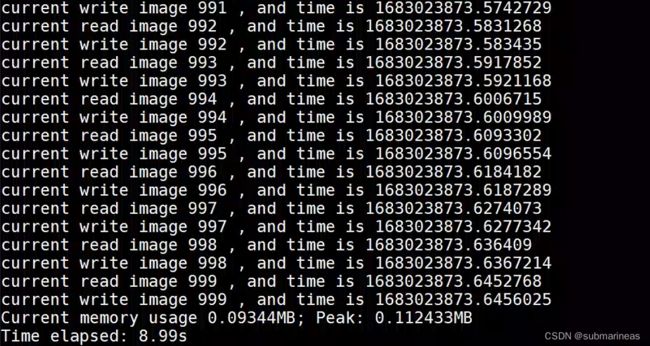
当然,这里还算了读和写的时间,以及开关进程,真实应该还会小很多,而且我这里只开两个进程,多进程下会比这个复杂,以及还要考虑读写锁了,因为读者——写者模型衍变为了多生产者或者多消费者问题。
另外,如果变成生产消费者模式,这就转化成了异步,所以生产者是不能等消费者处理完,再下一步的,这里可以产生一个四维大小的内存空间,相当于做成了缓存池,就解决了转换问题:
shape = (100, 480, 640, 3) # 100张图像,每张图像480x640x3
dtype = np.uint8
shared_mem = shared_memory.SharedMemory(create=True, size=int(np.prod(shape) * np.dtype(dtype).itemsize))
shared_mem_name = shared_mem.name
ShareableList使用方法
关于这个,我理解字如其名,共享列表,提供一个可修改的类 list 对象。但与上面的SharedMemory 相比,就有点鸡肋了,虽然它能传输的str和bytes能达到单条10M,但肯定算是较慢的,不光是支持如此多的类型而做的泛型,同样我在numpy总结与思维导图 一文中当时分析了List与numpy的差别(PS:这篇写得时候是2018年,过去了整整5年,可能对当前List策略重构了也说不定,因为我没怎么用新版本py,这里Mark一下)所以,可能官方也是为了方便在一些特殊场景下所使用的一种数据结构了,只不过我不太了解,这里贴出具体的使用方法,引用文档中的demo,基本跟正常list一致,除了切片:
>>> from multiprocessing import shared_memory
>>> a = shared_memory.ShareableList(['howdy', b'HoWdY', -273.154, 100, None, True, 42])
>>> [ type(entry) for entry in a ]
[<class 'str'>, <class 'bytes'>, <class 'float'>, <class 'int'>, <class 'NoneType'>, <class 'bool'>, <class 'int'>]
>>> a[2]
-273.154
>>> a[2] = -78.5
>>> a[2]
-78.5
>>> a[2] = 'dry ice' # Changing data types is supported as well
>>> a[2]
'dry ice'
>>> a[2] = 'larger than previously allocated storage space'
Traceback (most recent call last):
...
ValueError: exceeds available storage for existing str
>>> a[2]
'dry ice'
>>> len(a)
7
>>> a.index(42)
6
>>> a.count(b'howdy')
0
>>> a.count(b'HoWdY')
1
>>> a.shm.close()
>>> a.shm.unlink()
>>> del a # Use of a ShareableList after call to unlink() is unsupported
下面的例子演示了一个、两个或多个进程如何通过提供下层的共享内存块名称来访问同一个 ShareableList:
>>>b = shared_memory.ShareableList(range(5)) # In a first process
>>>c = shared_memory.ShareableList(name=b.shm.name) # In a second process
>>>c
ShareableList([0, 1, 2, 3, 4], name='...')
>>>c[-1] = -999
>>>b[-1]
-999
>>>b.shm.close()
>>>c.shm.close()
>>>c.shm.unlink()
那看完上面的例子,是不是感觉特别像SharedMemory?
没错,在该List的源码中,它在初始化时,就是包了一层SharedMemory,即:
def __init__(self, sequence=None, *, name=None):
if name is None or sequence is not None:
sequence = sequence or ()
_formats = [
self._types_mapping[type(item)]
if not isinstance(item, (str, bytes))
else self._types_mapping[type(item)] % (
self._alignment * (len(item) // self._alignment + 1),
)
for item in sequence
]
"""省略"""
requested_size = struct.calcsize(
"q" + self._format_size_metainfo +
"".join(_formats) +
self._format_packing_metainfo +
self._format_back_transform_codes
)
self.shm = SharedMemory(name, create=True, size=requested_size)
else:
self.shm = SharedMemory(name)
"""省略"""
所以之后还是会以SharedMemory为主,不再对List单独介绍,况且下节的例子,同样做到了与本节相关的操作,也就是SharedMemoryManager。
SharedMemoryManager使用方法
关于SharedMemoryManager,作为管理跨进程的共享内存块的子类,一般与SharedMemory 或者 sharedList一并使用,它是进程中的管理者,可以避免手动跟踪和释放共享内存资源。这里给出官方demo为:
with SharedMemoryManager() as smm:
sl = smm.ShareableList(range(2000))
# Divide the work among two processes, storing partial results in sl
p1 = Process(target=do_work, args=(sl, 0, 1000))
p2 = Process(target=do_work, args=(sl, 1000, 2000))
p1.start()
p2.start() # A multiprocessing.Pool might be more efficient
p1.join()
p2.join() # Wait for all work to complete in both processes
total_result = sum(sl) # Consolidate the partial results now in sl
这里推荐做法是通过 with 语句来保证所有共享内存块在使用完后被释放,可能上述例子还不是很清晰,这里参考找资料时看到一个大佬写得知乎帖子:
Python3.8多进程之共享内存
引用其中的代码为:
from multiprocessing.shared_memory import SharedMemory
from multiprocessing.managers import SharedMemoryManager
from concurrent.futures import ProcessPoolExecutor, as_completed
from multiprocessing import current_process, cpu_count
from datetime import datetime
import numpy as np
import pandas as pd
import tracemalloc
import time
def work_with_shared_memory(shm_name, shape, dtype):
print(f'With SharedMemory: {current_process()=}')
# Locate the shared memory by its name
shm = SharedMemory(shm_name)
# Create the np.recarray from the buffer of the shared memory
np_array = np.recarray(shape=shape, dtype=dtype, buf=shm.buf)
return np.nansum(np_array.val)
def work_no_shared_memory(np_array: np.recarray):
print(f'No SharedMemory: {current_process()=}')
# Without shared memory, the np_array is copied into the child process
return np.nansum(np_array.val)
if __name__ == "__main__":
# Make a large data frame with date, float and character columns
a = [
(datetime.today(), 1, 'string'),
(datetime.today(), np.nan, 'abc'),
] * 5000000
df = pd.DataFrame(a, columns=['date', 'val', 'character_col'])
# Convert into numpy recarray to preserve the dtypes
np_array = df.to_records(index=False)
del df
shape, dtype = np_array.shape, np_array.dtype
print(f"np_array's size={np_array.nbytes/1e6}MB")
# With shared memory
# Start tracking memory usage
tracemalloc.start()
start_time = time.time()
with SharedMemoryManager() as smm:
# Create a shared memory of size np_arry.nbytes
shm = smm.SharedMemory(np_array.nbytes)
# Create a np.recarray using the buffer of shm
shm_np_array = np.recarray(shape=shape, dtype=dtype, buf=shm.buf)
# Copy the data into the shared memory
np.copyto(shm_np_array, np_array)
# Spawn some processes to do some work
with ProcessPoolExecutor(cpu_count()) as exe:
fs = [exe.submit(work_with_shared_memory, shm.name, shape, dtype)
for _ in range(cpu_count())]
for _ in as_completed(fs):
pass
# Check memory usage
current, peak = tracemalloc.get_traced_memory()
print(f"Current memory usage {current/1e6}MB; Peak: {peak/1e6}MB")
print(f'Time elapsed: {time.time()-start_time:.2f}s')
tracemalloc.stop()
# Without shared memory
tracemalloc.start()
start_time = time.time()
with ProcessPoolExecutor(cpu_count()) as exe:
fs = [exe.submit(work_no_shared_memory, np_array)
for _ in range(cpu_count())]
for _ in as_completed(fs):
pass
# Check memory usage
current, peak = tracemalloc.get_traced_memory()
print(f"Current memory usage {current/1e6}MB; Peak: {peak/1e6}MB")
print(f'Time elapsed: {time.time()-start_time:.2f}s')
tracemalloc.stop()
该方案就是将pandas.DataFrame 转化为numpy.recarray 再通过shared给子进程,这种应用场景是非常大的,不管是数据分析还是挖掘等等领域,避免了很多数据传输的耗时,不管数据量大小,都比直接通信要快。
那么,为什么共享内存会更加快呢?
MMAP 技术(可跳过,之后会另开一篇博客详述)
本节内容主要参考CHAPTER 15 Memory Mapping and DMA
在Memory Mapping and DMA文中,画了这样的一张图:

该图显示了这些地址类型与物理内存的关系。这里有5类地址,分别为:User virtual addresses、 Physical addresses、Bus addresses、Kernel logical addresses、Kernel virtual addresses,如下图所示:

这五种地址很好理解,根据图中的I/O外设开始,是用户能看见的虚拟地址,然后上面那条路是物理地址,DMA控制器这里的是总线地址,最后是CPU这里上下两路,分别为内核逻辑和内核虚拟,具体的定义可以看参考以及操作系统一书,这里碍于篇幅不再详述。
那有没有一种可能,将外设和内存联系起来呢?即用户虚拟地址与内存物理地址想关联,在此之前,内核已经使用逻辑地址来引用物理内存的页面,在王道的《操作系统复习指导》中第三章对CPU与内存之间的映射与置换做了详细的解释,如下流程图,就是一个页面置换的步骤:
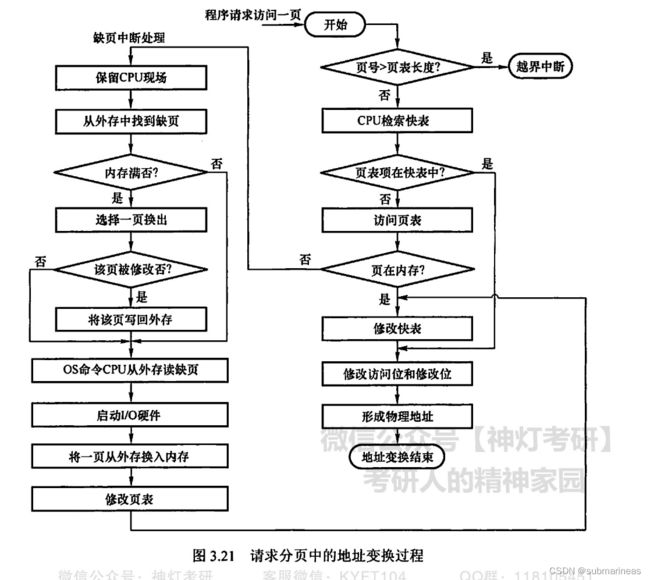
如下图是一个进程在内存中的映像:

这也可以看出,进程的虚拟地址空间,由多个内存区域构成。但并不是所有的进程内存空间都适合共享,只有那些只读的区域才可以共享。一般而言,可重入代码又称纯代码,是一种允许多个进程同时访问但不允许被任何进程修改的代码。但在实际执行时,也可以为每个进程配以局部数据区,把在执行中可能改变的部分复制到该数据区,这样,程序在执行时只需对该私有数据区中的内存进行修改,并不去改变共享的代码。
这里通过一个例子来说明内存共享的实现方式。考虑一个可以同时容纳40个用户的多用户系统,他们同时执行一个文本编辑程序,若该程序有160KB代码区和40KB数据区,则共需8000KB的内存空间来支持40个用户。如果160KB代码是可分享的纯代码,则不论是在分页系统中还是在分段系统中,整个系统只需保留一份副本即可,此时所需的内存空间仅为40KB×40+ 160KB=1760KB。对于分页系统,假设页面大小为4KB,则代码区占用40个页面、数据区占用10个页面。为实现代码共享,应在每个进程的页表中都建立40个页表项,它们都指向共享代码区的物理页号。此外,每个进程还要为自己的数据区建立10个页表项,指向私有数据区的物理页号。
这是在直接内存与CPU的操作,而说回正题,我们还可以将内存映射文件(文件映射内存)的一种共享方式。
这里参考是时候了解下 mmap 了 中的图:

mmap(memory mapping)共享内存是一种在不同进程间共享内存的机制。通过使用mmap系统调用,可以将一个文件或者设备的一段物理内存映射到多个进程的虚拟地址空间中,从而实现多个进程之间共享内存,同时也避免了数据的复制,提高了数据传输效率。在使用mmap共享内存的过程中,可以通过指针直接读写共享内存,从而实现高效的数据传输和共享。如上图所示,text数据段、初始数据段、Bss数据段、堆、栈、内存映射,都是一个独立的虚拟内存区域。而为内存映射服务的地址空间处在堆栈之间的空余部分。
那这里可以看Linux内核中的源码,它怎么去使用这种技术的,这里引出kernel的一个很好的代码指导页:
Memory mapping
简单点说就是通过一系列内核函数触发调用,会去申请一个 vm_area_struct 结构(vma),内核使用它来管理进程的虚拟内存地址。

vm_area_struct 结构中包含区域起始和终止地址以及其他相关信息,同时也包含一个vm_ops 指针,其内部可引出所有针对这个区域可以使用的系统调用函数。这样,进程对某一虚拟内存区域的任何操作都需要的信息,都可以从vm_area_struct 中获得。mmap函数就是要创建一个新的vm_area_struct结构 ,并将其与文件的物理磁盘地址相连。
那到此,mmap就实现了映射关系,实现了加速。将上述内容总结一下,就如下四点:
-
1、进程在用户空间调用函数mmap ,原型:void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
-
2、在当前进程虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址
-
3、为此虚拟区分配一个vm_area_struct 结构,接着对这个结构各个区域进行初始化
-
4、将新建的虚拟区结构(vm_area_struct)插入进程的虚拟地址区域链表或树中
(PS:引用还是来自简书参考)
但进程调用mmap()时,只是在进程空间内新增了一块相应大小的缓冲区,并设置了相应的访问标识,但并没有建立进程空间到物理页面的映射。因此,第一次访问该空间时,会引发一个缺页异常,这样就完成了初始化。
源码介绍
上述简单介绍了mmap的一些概念与原理,主要还是需要学过操作系统那门课,里面很多概念,比如逻辑与物理地址,缺页等等算是一些基础知识,至于C语言源码,可以先熟悉一下Linux内核中的关于内存管理的这一段。
那么为什么要介绍mmap呢?主要还是python中,上述所有方法的底层都是mmap,下面就进行分析。
sharedctypes
这里以RawArray函数为例,它是sharectypes中的一种,也是一种进程共享机制,它首先源码为:
def RawArray(typecode_or_type, size_or_initializer):
'''
Returns a ctypes array allocated from shared memory
'''
type_ = typecode_to_type.get(typecode_or_type, typecode_or_type)
if isinstance(size_or_initializer, int):
type_ = type_ * size_or_initializer
obj = _new_value(type_)
ctypes.memset(ctypes.addressof(obj), 0, ctypes.sizeof(obj))
return obj
else:
type_ = type_ * len(size_or_initializer)
result = _new_value(type_)
result.__init__(*size_or_initializer)
return result
这里面主要两个调用函数,第一个是memset,是Linux 内核中C的一个方法,申请一块内存地址,而主要需要看_new_value方法,它的源码为:
def _new_value(type_):
size = ctypes.sizeof(type_)
wrapper = heap.BufferWrapper(size)
return rebuild_ctype(type_, wrapper, None)
那这里就很明了了,heap是堆,算是基本库,这里继续深入,BufferWrapper为:
class BufferWrapper(object):
_heap = Heap()
def __init__(self, size):
if size < 0:
raise ValueError("Size {0:n} out of range".format(size))
if sys.maxsize <= size:
raise OverflowError("Size {0:n} too large".format(size))
block = BufferWrapper._heap.malloc(size)
self._state = (block, size)
util.Finalize(self, BufferWrapper._heap.free, args=(block,))
看到这里,我当时本来没往下看了,因为我以为malloc就是cpp里的静态创建内存,那感觉可能会有泄漏的风险?但后来发现不是,只是在python这边重写了malloc,中间又经过几层连续调用,最底层的函数即为:
class Arena(object):
"""
A shared memory area backed by a temporary file (POSIX).
"""
if sys.platform == 'linux':
_dir_candidates = ['/dev/shm']
else:
_dir_candidates = []
def __init__(self, size, fd=-1):
self.size = size
self.fd = fd
if fd == -1:
# Arena is created anew (if fd != -1, it means we're coming
# from rebuild_arena() below)
self.fd, name = tempfile.mkstemp(
prefix='pym-%d-'%os.getpid(),
dir=self._choose_dir(size))
os.unlink(name)
util.Finalize(self, os.close, (self.fd,))
os.ftruncate(self.fd, size)
self.buffer = mmap.mmap(self.fd, self.size)
这里最终是mmap,但可能有小伙伴就会问,为什么这个这么复杂,会不会调用很慢?其实不是,中间的大段操作可以看成是内存更加有序的管理,学过数据结构的都知道,堆是一种很能减少时间复杂度的操作,有最大堆和最小堆,这里相当于做了一个内存池堆,保证了整个过程没有内存泄漏以及多进程能更安全的切换访问。
sharedmemory
相比于ctypes的方式,memory的我理解是,作者还是觉得如果把一些权柄交给C端可能有些复杂,因为上面ctypes的操作都是基于C调用的api,所以就创造了基于python的manager共享通信?我理解。以下是源码的一个分析:
def __init__(self, name=None, create=False, size=0):
if not size >= 0:
raise ValueError("'size' must be a positive integer")
if create:
self._flags = _O_CREX | os.O_RDWR
if size == 0:
raise ValueError("'size' must be a positive number different from zero")
if name is None and not self._flags & os.O_EXCL:
raise ValueError("'name' can only be None if create=True")
if _USE_POSIX:
# POSIX Shared Memory
if name is None:
while True:
name = _make_filename()
try:
self._fd = _posixshmem.shm_open(
name,
self._flags,
mode=self._mode
)
except FileExistsError:
continue
self._name = name
break
""""""
try:
if create and size:
os.ftruncate(self._fd, size)
stats = os.fstat(self._fd)
size = stats.st_size
self._mmap = mmap.mmap(self._fd, size)
这里因为我是Linux系统开发,所以_USE_POSIX肯定为TRUE,代码进来开头即调用了shm_open,相当于创建,而后同样是使用mmap.mmap去做共享内存,但这种相对上面的就简单很多,直接一步到位,没有使用更多的数据结构,也没有用复杂的操作进行空间换时间,单纯从完成功能角度来讲,两者差不多,但如果考虑异常的话,ctypes方案就更加优秀。
sharedmanager
该源码主要就是两个功能,与描述一样,承担起了手动跟踪和释放共享内存资源的任务:
def __init__(self, *args, **kwargs):
if os.name == "posix":
# bpo-36867: Ensure the resource_tracker is running before
# launching the manager process, so that concurrent
# shared_memory manipulation both in the manager and in the
# current process does not create two resource_tracker
# processes.
from . import resource_tracker
resource_tracker.ensure_running()
BaseManager.__init__(self, *args, **kwargs)
util.debug(f"{self.__class__.__name__} created by pid {getpid()}")
def SharedMemory(self, size):
"""Returns a new SharedMemory instance with the specified size in
bytes, to be tracked by the manager."""
with self._Client(self._address, authkey=self._authkey) as conn:
sms = shared_memory.SharedMemory(None, create=True, size=size)
try:
dispatch(conn, None, 'track_segment', (sms.name,))
except BaseException as e:
sms.unlink()
raise e
return sms
而这里的client,其实是个socket,这里继承了basemanager,但本质上,管理进程与共享进程间通信,还是发送了TCP请求进行可靠传输,这里在下一篇与mmap一起可以扩展一下,这里就略过,所以到此,结束。