redis集群的搭建
redis单机版,出现单机故障后,导致redis无法使用,如果程序使用 redis,间接导致程序出错。
redis集群的搭建方式一共有三种:主从复制模式,哨兵模式和主从模式。哨兵模式是对主从模式的一种补充,而集群模式相当于前两种模式的补充。真正在公司中用到的还是集群模式。想要学习集群模式,就要先从前两种模式开始学起。
一、主从复制模式
一主多从模式。一个主节点,多个从节点,那么主节点可以负责:读操作, 写操作。 从节点只能负责读操作,不能负责写操作。 这样就可以把读的压 力从主节点分摊到从节点,以减少主节点的压力。
当主节点执行完写的命令,会把数据同步到从节点。
1、搭建主从复制模式
按理我们应该开三个电脑或者开三个虚拟机来演示,这里为了方便,我们直接可以在一台虚拟机中演示,只要让redis服务的配置文件复制为3份,每一份代表一个redis服务,这三个redis的端口号不相同,代替了三个不同的服务器。
主节点的所有数据都会同步到从节点中!
主节点能读能写,从节点只能读!
(1)配置三个redis服务的配置文件(我们这里配置三个redis的端口号分别为:主(6379(默认))从:(7002 7003))
- 修改端口号
- 修改rdb文件名称


![]()
![]()
为了区分,你也可以像我一样,在redis根目录创建一个目录master-salve,将修改的三个配置文件放到这里,以防混乱。
(2)启动服务,并连上客户端

(3)查看三个redis服务的主从关系:
info replication

因为我们还没有配置三个redis服务的主从关系,所以他们三个现在都是默认为master。
主从复制模式的原则是:配从不配主。 就是说我们只需要配置从服务器(salve)即可,不需要对master主服务器进行配置。
(4)设置7002和7003服务为从节点
slaveof 主节点ip 主节点端口号
看到下图中的info replication中的信息可见我们已经配置成功!
(5)测试
主节点可以读和写。但是从节点只能读。
尝试在主节点写:

写入成功!
尝试在从节点写入:

写入失败!验证了写操作只能在主节点进行。
尝试在主和从节点中都进行读操作:

主从节点都读取成功!可见读取可以发生在主节点和从节点。
思考:
(1)这种模式,如果我们的主节点宕机以后,从节点会代替主节点变成主节点吗?答案是不会。除非我们手动设置,但是这显然不现实。
(2)如果新增加一个从节点,那新的从节点中会有主节点中的全部数据吗?答案是会。主节点会将所有的数据都复制到从节点中。
那么这种模式的痛点就显而易见了。主节点宕机,我们的从节点不能代替主节点,写入操作无法执行。那么第二种模式——哨兵模式就发挥作用了。
二、哨兵模式
由于主从模式,主节点单机后,从节点不会自动上位。 增加一个哨兵服 务,该哨兵时刻监控master,如果master挂了,哨兵会在从节点中选举一 位为主节点【哨兵投票机制】。
你可以将哨兵也理解为一台服务器,他负责监控主节点并在主节点宕机时选择从节点作为新的主节点。
1、启动哨兵模式
(1)找到我们的哨兵模式的配置文件
![]()
(2)修改其配置文件
它的配置文件我们只需要修改一个地方即可。
![]()
这里的哨兵认可数如何理解?就好比投票机制。当主节点宕机以后,剩下的从节点获得了哨兵的选中,就意味着获得了哨兵认可,即上图中的1,作为1个哨兵认可数。只要从节点获得1个哨兵认可数,那么他就会被选中为主节点。你也可以修改为2个,3个等等,理所应当的,想要让从节点获得三个哨兵认可数,起码要开启三个哨兵。这里我们开启一个哨兵就够用了。
注意:哨兵认可数,不意味着开启的哨兵的个数!而是从节点被多少个哨兵选中。
(3)启动哨兵
redis-sentinel sentinel.conf(配置文件名)

(4)测试
我们还是让6379为主节点,7002 和 7003为从节点。然后我们让6379关闭服务,看看哨兵会不会帮我们从两个从节点中选择一个新的主节点。
关闭主节点服务:

等待一段时间之后,可以看到我们的哨兵发生了一些变化:

可以看到当我们的主节点宕机以后,哨兵好像帮我们选择了7002这个从节点作为新的主节点。
真的是这样吗?让我们用info replication看看7001 和 7002 的主从关系:
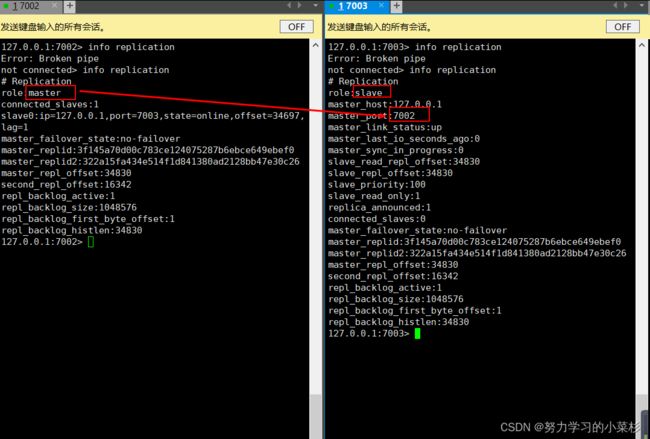
可以看到,7002成功变成主节点,7003变为7002的从节点。哨兵模式测试成功!
2. 思考
上一个主节点假如这时候恢复了,从新上线了,那上一个主节点还会重新变成主节点吗?
我们不如直接用结果说话:
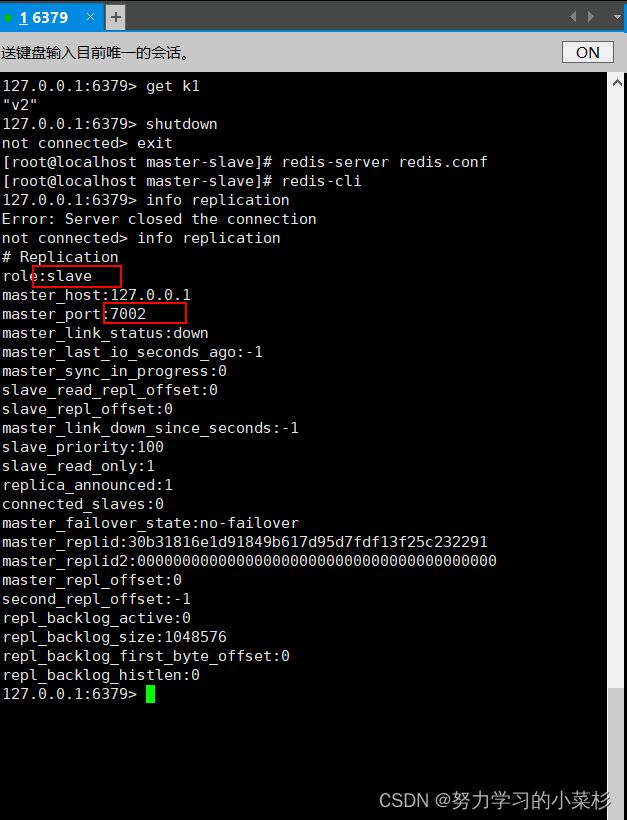
可以看到就算它恢复了,它依然是7002的从节点。地位不复当年。
现在我们可以通过主从辅助实现帮帮助主节点分担读的压力,而且也实现了当主节点宕机时从节点之一自动转换为主节点。但是,我们主节点的写入的压力依旧没有被分担。这时,第三种模式——集群化模式就起作用了。
三、集群化模式
不管上面的主从还是哨兵模式,都无法解决单节点写操作的问题。如果这 时写操作的并发比较高。这是可以实验集群化模式【去中心化模式】
集群化实现原理:
redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一 个 key-value时,redis 先对 key 使用 crc16 算法算出一个整数结果, 然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0- 16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射 到不同的节点。
当你往Redis Cluster中加入一个Key时,会根据crc16(key) mod 16384计算这个key应该分布到哪个hash slot中,一个hash slot中会有 很多key和value。你可以理解成表的分区,使用单节点时的redis时只 有一个表,所有的key都放在这个表里;改用Redis Cluster以后会自动 为你生成16384个分区表,你insert数据时会根据上面的简单算法来决 定你的key应该存在哪个分区,每个分区里有很多key。
理解一下上面这段话。redis集群化内置了16384个哈希槽,它将这些哈希槽均等分给了我们的n个主节点的服务器。比如两个个主节点服务器,那么1号服务器对应的就是哈希槽就是0~8191,2号服务器对应的哈希槽就是8200~16383。当客户进行了读写操作,在读写操作发送到我们redis服务器之前,会经过一个crc16的算法对客户传入的key值转化为一个整数,然后将这个整数对16384取余,结果就对应了我们的哈希槽的值,然后根据哈希槽的值来判断这次操作应该分给哪个服务器。
注意:
- 每个key值对应的哈希槽的值都是固定不变的
- 一个哈希槽可以储存多个key值
- 一个哈希槽可以存储多个key值(也就是说key值不同,哈希槽的值可能会相同)
- 我们搭建集群化的主节点的个数应当为奇数个。
1、搭建集群化模式
(1)准备工作
因为搭建集群化服务器,主节点个数必须为奇数个,所以我们最少要实现三主三从6个服务器(1个主节点就没有集群化的意义了)。
主节点端口号:6001 6002 6003
从节点端口号:5001 5002 5003
(2)配置6个服务器的配置文件。(为了防止混乱,我们在根目录建一个目录cluster将6个配置文件都放在这里面)
需要配置的内容:(我们以其中一个服务器(6001)的配置文件为例)
1、修改端口号
![]()
2、 设置远程可访问
![]()
注意:不要忘记关闭防火墙 或者 防火墙放行这些端口号!!!!
3、设置后台开启(不然我们得起码开7个窗口,如果都在一个虚拟机演示的话)
![]()
4、修改各自的rbd文件的文件名(不然6个服务器的rdb都会公用一个)
![]()
5、打开aof持久化
![]()
6、修改各自的aof文件名(道理同第4条)
![]()
7、集群的配置文件,该文件自动生成
![]()
注意:这一条默认写好,但是被注释掉了,别忘记把注释去掉!
8、设置集群的超时时间
![]()
注意:这一条默认写好,但是被注释掉了,别忘记把注释去掉!
9、开启集群
![]()
上面的这8个配置,其中没有标红加粗的配置,是因为我们在一台虚拟机上配置了6个服务器,所以才需要修改,真正公司里可别这么干!!肯定都是一个服务器对应一个redis服务。只需要修改标红部分的配置即可。我们配置完之后就如下图所示:

(3)启动6台redis服务:

(4)分配槽 非常重要!!
redis-cli --cluster create --cluster-replicas 1 ip:port ip:port ip:port ip:port ip:port ip:port
其中的 1 代表为每个主节点配置1个从节点。所以对应的咱们这6个服务器,前三个为主节点,后三个为从节点。如下图所示:
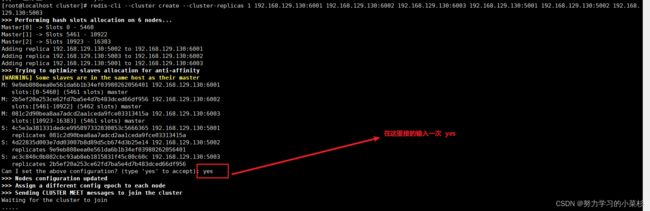
显示OK以后代表最终配置成功!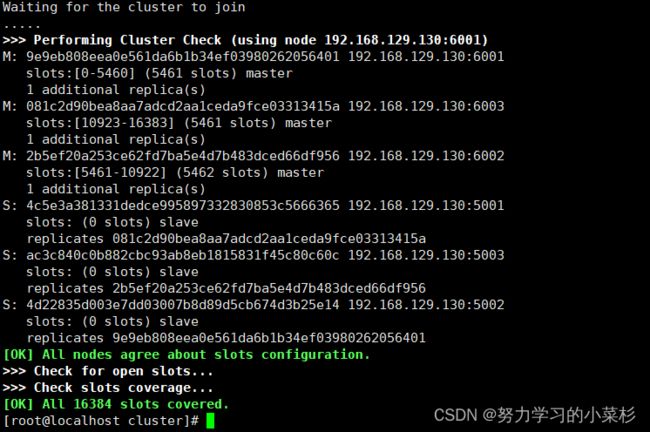
注意:一定要确保每个节点都没有数据。
(5)测试:
redis-cli -c -h ip -p port 千万别忘记了 -c 不然进不去集群化的客户端
我们随便进入其中任意一台服务端即可。以6001为例:

使用集群化,使读写操作均摊到了不同的节点上,大大减轻了主节点的压力。