多模态融合新方向!21篇2024年最新顶会论文汇总!(附PDF)
在人工智能领域,多模态融合正迅速成为研究的热点,它涉及到将不同类型的数据,如文本、图像、音频等,整合到一个统一的模型中,以实现更丰富和深入的理解。2024年,随着技术的不断进步,多模态融合的研究也呈现出了一些新的方向和突破。
今天就整理了21篇2024年目前顶会录用的多模态融合论文,这些论文涵盖了多模态融合的最新进展和创新成果,一起看看吧!
AAAI 2024
1、MESED: A Multi-modal Entity Set Expansion Dataset with Fine-grained Semantic Classes and Hard Negative Entities
MESED:具有细粒度语义类和硬否定实体的多模态实体集扩展数据集
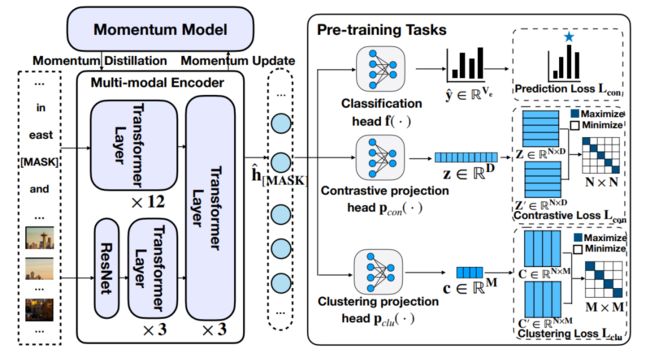
简述:多模态融合面临挑战,本文提出多模态实体集扩展(MESE)以集成多模态信息表示实体。MESE的好处:互补信息、统一信号、同义实体的鲁棒对齐。为评估,构建MESED数据集,它是首个大规模精细的ESE多模态数据集。并提出MultiExpan模型,在4个多模态预训练任务上预训练。MESED实验证明数据集和模型的有效性,为未来研究指明方向。
2、MmAP: Multi-modal Alignment Prompt for Cross-domain Multi-task Learning
MmAP :用于跨领域多任务学习的多模态对齐提示
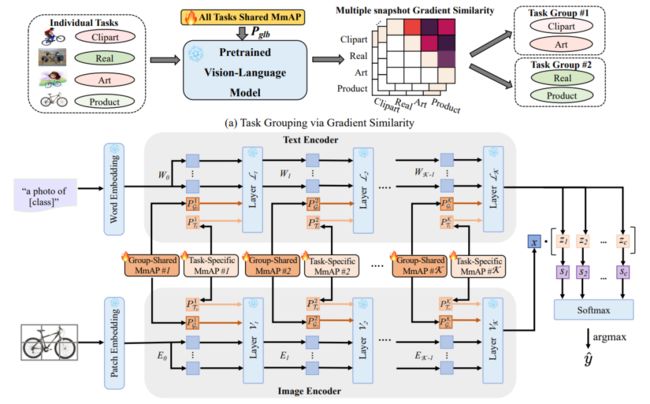
简述:本文提出了一种集成视觉语言模型CLIP的多任务学习框架,该模型具有强大的零样本泛化能力,并开发了多模态对齐提示(MmAP),研究人员在微调过程中对齐文本和视觉模态。通过任务分组和特定任务的MmAP,提高了高相似性任务的互补性,同时保留了每个任务的独特特征。实验表明,该方法在两个大型多任务学习数据集上实现了显著的性能改进,同时只使用了大约0.09%的可训练参数。
3、LAMM: Label Alignment for Multi-Modal Prompt Learning
LAMM:用于多模态提示学习的标签对齐
简述:本文提出了一种创新的标签对齐方法LAMM,通过端到端训练动态调整下游数据集的类别嵌入,并采用分层损失,包括参数空间、特征空间和对数空间的对齐,以改善标签分布。在11个下游视觉数据集上的实验表明,这种方法显著提升了多模态提示学习模型在小样本场景中的性能,平均准确率比最先进的方法高出2.31%。LAMM在持续学习任务中表现出色,并能与现有提示调优方法协同工作,进一步提升性能。

4、Structure-CLIP: Towards Scene Graph Knowledge to Enhance Multi-modal Structured Representations
Structure-CLIP:利用场景图知识增强多模态结构化表示
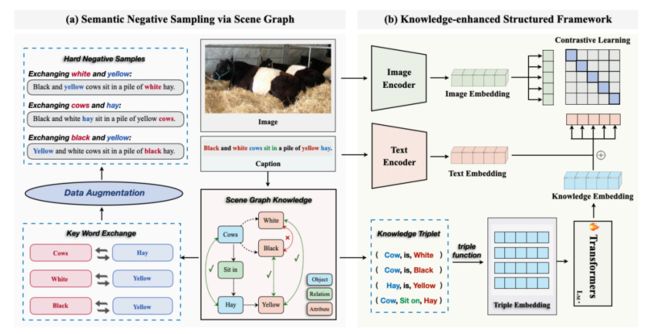
简述:本文介绍了一个名为Structure-CLIP的端到端框架,该框架集成了场景图知识(SGK)来增强多模态结构化表示,框架通过使用场景图指导语义否定样本的构建,并提出了一个知识增强编码器(KEE)来利用SGK进一步强化结构化表示。实验表明,Structure-CLIP在VG-Attribution和VG-Relationship数据集上实现了最先进的性能,分别领先多模态SOTA模型12.5%和4.1%。在MSCOCO数据集上,该框架在保持一般表示能力的同时,显著增强了结构化表示。
5、Bi-directional Adapter for Multi-modal Tracking
用于多模式跟踪的双向适配器
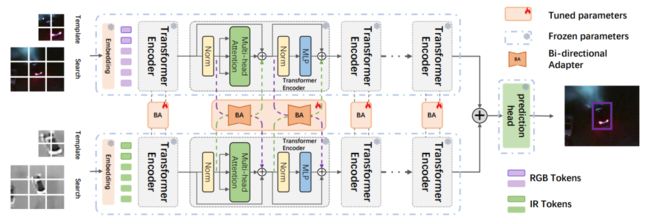
简述:本文提出了一种多模态视觉提示跟踪模型,采用通用双向适配器,结合多个共享参数的特定模态变压器编码器。模型利用冻结的预训练基础模型提取特征,并通过光特征适配器自适应地融合不同模态的信息。相比完全微调方法或基于提示学习的方法,该模型仅需极少量(0.32M)可训练参数,即实现了卓越的跟踪性能。
6、Learning Multimodal Volumetric Features for Large-Scale Neuron Tracing
学习用于大规模神经元追踪的多模态体积特征
简述:本文旨在通过预测神经元片段连接来减少人工工作量,同时利用显微镜图像和3D形态学特征。为此研究人员构建了FlyTracing数据集,包含数百万成对连接片段,规模远超现有数据集,并提出连通性感知对比学习方法,学习体积电磁图像嵌入,可与任何形态表示结合实现自动追踪。对不同组合方案比较表明所提方法优越,尤其在严重成像伪影位置如截面缺失和错位处。
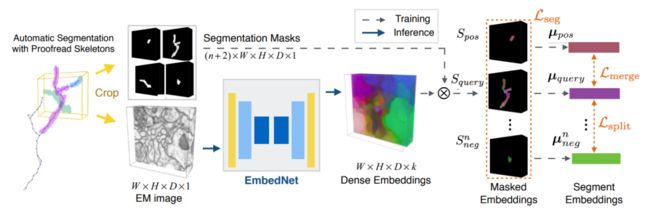
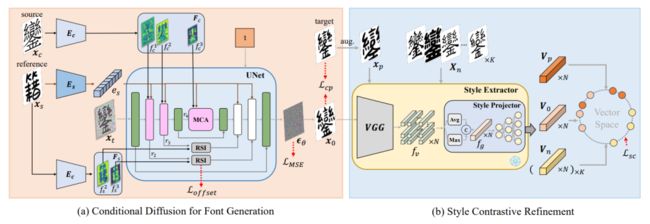
7、FontDiffuser: One-Shot Font Generation via Denoising Diffusion with Multi-Scale Content Aggregation and Style Contrastive Learning
FontDiffuser:通过多尺度内容聚合和风格对比学习的去噪扩散进行一次性字体生成
简述:本文提出了FontDiffuser,一种基于扩散的一次性字体生成方法。它创新地将字体模仿建模为噪声到去噪范式,引入了多尺度内容聚合模块和风格对比细化模块,前者增强复杂字符的保存,后者更好地管理风格迁移中的变化。实验证明,FontDiffuser在生成复杂字符和样式方面优于以前的方法。
ICLR2024
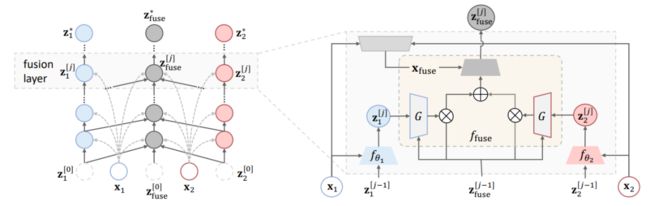
8、Deep Equilibrium Multimodal Fusion
深度平衡多模态融合
简述:本文提出了一种名为深度均衡(DEQ)的新方法,通过寻找动态多模态融合过程的固定点,以自适应和递归方式建模特征相关性。DEQ方法能够编码模态内部和之间的丰富信息,从低级到高级,实现有效的下游多模态学习,并易于集成到各种多模态框架中。在多个多模态基准测试中,DEQ融合始终如一地实现最先进的性能。
9、Deep Generative Clustering with Multimodal Diffusion Variational Autoencoders
使用多模态变分自编码器进行深度生成聚类
简述:本文提出了一个新的多模态VAE模型,通过扩展潜在空间来学习数据集群,利用跨模态的共享信息。实验表明,该模型在生成性能上优于现有多模态VAEs,尤其在无条件生成任务中。此外,在弱监督环境中,这种方法优于其他聚类方法。研究人员还提出了一种自动选择真实集群数量的后处理程序,避免了需要先验知识的关键限制。

10、IMProv: Inpainting-based Multimodal Prompting for Computer Vision Tasks
IMProv:用于计算机视觉任务的基于修复的多模态提示
简述:本文介绍了IMProv,一种从多模态提示中学习视觉任务的生成模型,该模型在给定视觉任务描述、示例或两者结合的情况下,学习为新测试输入求解。研究人员训练了掩码生成转换器和带标题的大规模图像文本数据集。推理期间,用文本和/或图像示例提示模型,并生成相应输出。实证结果显示,文本条件和数据集大小训练可提高前景分割AP 10%,单对象检测AP 5%,降低LPIPS 20%。表明视觉和语言提示互补,结合可实现更好的情境学习表现。
11、Large-Vocabulary 3D Diffusion Model with Transformer
大词汇量3D扩散模型与Transformer
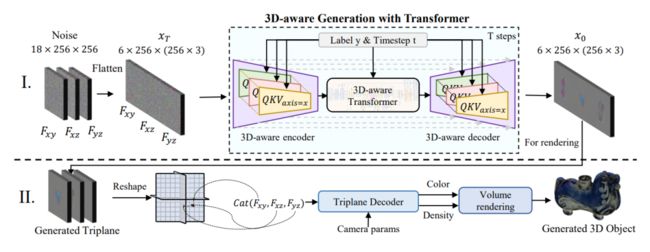
简述:本文介绍了一种名为DiffTF的新型3D物体生成框架,旨在解决大词汇量3D生成面临的三大挑战。它采用了改进的三平面表示,通过学习不同平面之间的交叉平面关系来提取广义3D知识,并将其与专门的3D特征聚合在一起。此外,还设计了3D感知编码器/解码器,以增强编码三平面中的通用3D知识,以处理具有复杂外观的类别。实验结果表明,DiffTF在ShapeNet和OmniObject3D上实现了最先进的大词汇量3D物体生成性能,具有广泛的多样性、丰富的语义和高质量。
12、Fusion is Not Enough: Single Modal Attack on Fusion Models for 3D Object Detection
融合是不够的:对融合模型进行3D目标检测的单模态攻击
简述:本文针对3D目标检测中的多传感器融合模型,特别是那些以摄像头和激光雷达为主要传感器的模型。研究指出,尽管摄像头在融合中可能不是最重要的模态,但它更容易受到攻击。因此,提出了一种仅针对摄像头的攻击框架,通过两阶段优化策略,评估并针对不同的融合模型生成攻击补丁。实验表明,这种攻击能够显著降低模型的检测性能,将平均平均精度从0.824降低到0.353,或将特定目标的检测分数从0.728降低到0.156,这证明了所提出攻击框架的有效性。

13、Transformer Fusion with Optimal Transport
基于最优传输的Transformer融合
简述:本文提出了一种新的方法,通过最优传输技术软对齐不同Transformer网络的架构组件,实现多网络的融合。这种方法不仅适用于同构模型融合,还能处理不同大小的模型(异构融合),为Transformer模型压缩提供了新途径。在图像分类和自然语言处理任务上的实验表明,该方法在微调后性能超越单一模型,证明了软对齐在Transformer融合中的重要性。
14、Parameter-Efficient Multi-Task Model Fusion with Partial Linearizeation
基于部分线性化的参数高效多任务模型融合
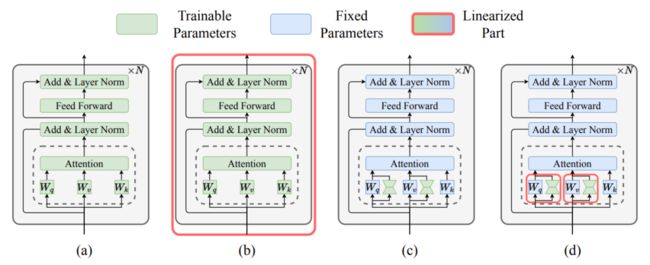
简述:本文提出了一种改进多任务融合的新方法,能够提高参数效率,如LoRA微调技术。这种方法通过仅对适配器模块进行部分线性化,并结合任务算术,保留了模型融合的优势,同时保持了微调和推理的高效性。实验结果显示,它在多任务融合上优于传统方法,并能有效构建统一的多任务模型。评估还表明,随着任务数量的增加,其性能超越了标准参数高效微调技术,显示了部分线性化在多任务模型融合中的优势。
15、Jointly Training Large Autoregressive Multimodal Models
联合训练大型自回归多模态模型
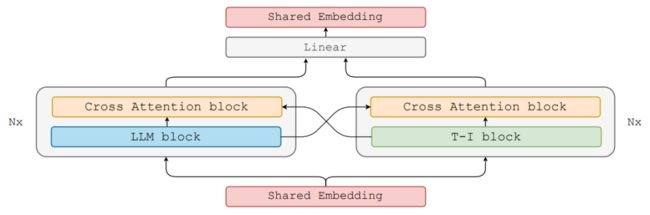
简述:本文提出了联合自回归混合(Joint Autoregressive Mixture,简称JAM)框架,这是一种模块化方法,可以系统地融合现有的文本和图像生成模型。还引入了一种专门针对混合模态生成任务的数据高效指令调整策略。最终指令调整模型在生成高质量多模态输出方面表现出无与伦比的性能,并且是第一个专门为此目的设计的模型。
16、CLIP the Bias: How Useful is Balancing Data in Multimodal Learning?
CLIP的偏见:多模态学习中数据平衡的实用性如何?
简述:本文研究了数据平衡在减轻CLIP模型偏见的有效性,发现CLIP模型可能吸收社会刻板印象。为应对这一问题,研究人员提出了一种新算法,旨在减少多模态数据集中的表征和关联偏见,分析考虑了模型、表征和训练数据大小等因素,并发现微调对抗表征偏见有效,但对关联偏见影响有限。数据平衡对模型性能的影响喜忧参半:它通常提高零样本和少样本分类性能,但可能损害检索性能。最后研究人员提出一系列建议,以提升多模态系统中数据平衡的效果。

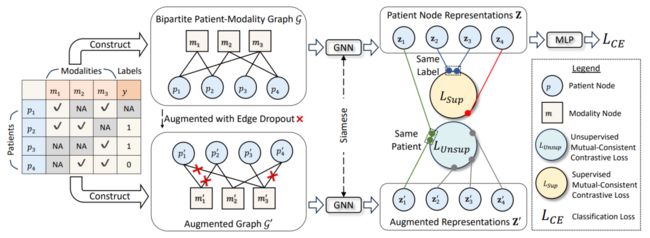
17、Multimodal Patient Representation Learning with Missing Modalities and Labels
缺失模态和标签的多模态患者表示学习
简述:本文提出了MUSE,一种新的相互一致的图对比学习方法,用于处理患者数据的缺失模态和标签问题。它采用二分图表示患者与模态之间的关系,并适应不同的模态缺失情况。通过相互一致的对比学习损失,MUSE能够学习到既通用又与标签相关的特征,避免了模态特征崩溃的问题。其无监督的对比目标可以利用自监督信号,从而包括标签缺失的患者数据。在MIMIC-IV、eICU和ADNI三个公开数据集上,MUSE表现优于所有基线,而MUSE+通过扩展训练范围至标签缺失患者,将性能提升约4%。
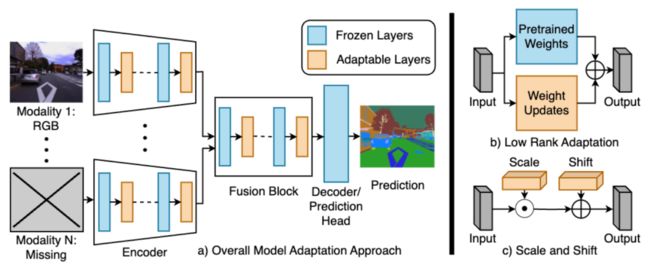
18、Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
通过参数高效适应实现带缺失模态的鲁棒多模态学习
简述:本文提出了一个简单且参数高效的适配方法,用于预训练的多模态网络。该方法通过低秩适配和中间特征调制来补偿缺失模态,显著减少性能损失,有时甚至超越为特定模态组合训练的独立网络。所需新增参数极少,实验证明,在RGB-热成像、RGB-深度语义分割、多模态材料分割和情感分析等任务上,这种方法表现出色,优于当前针对缺失模态的多模态学习方法。
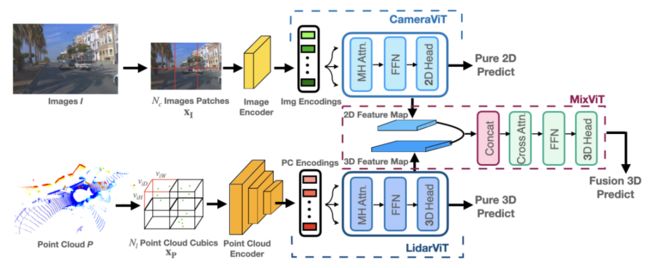
19、FusionViT: Hierarchical 3D Object Detection via Lidar-Camera Vision Transformer Fusion
FusionViT:通过LiDAR进行分层3D目标检测-Camera Vision Transformer Fusion
简述:本文提出了FusionViT,一种基于视觉转换器的新型3D目标检测模型。与现有方法不同,FusionViT采用分层架构,扩展transformer模型嵌入图像和点云,实现有效表示学习。多模态数据嵌入通过融合视觉转换器进一步融合,特征馈送至目标检测头,定位3D对象。在KITTI和Waymo Open数据集上,FusionViT实现最先进性能,优于基线方法和多模态融合方法。
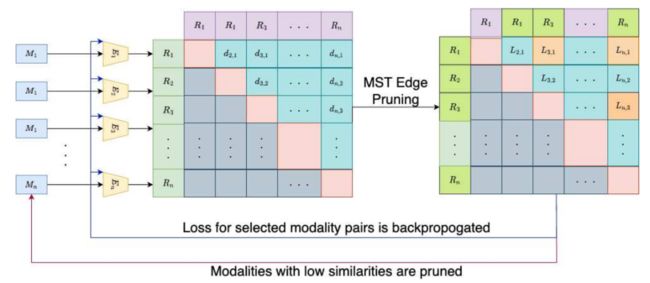
20、Optimal and Generalizable Multimodal Representation Learning Framework through Adaptive Graph Construction
通过自适应图构建实现最优和可泛化的多模态表示学习框架
简述:本文介绍了一种名为AutoBIND的新型对比学习框架,该框架可以从任意数量的模态中学习表征。AutoBIND利用基于图的策略自动选择最相关的模态,并通过对比损失学习表征。该框架在训练过程中能动态更新图结构,因此对缺失模态具有鲁棒性。在多种任务和数据模态(包括阿尔茨海默病检测、房价预测、3D图像、2D图像和表格数据)上的评估显示,AutoBIND优于先前方法,展现了其泛化能力。
21、Simultaneous Dimensionality Reduction: A Data Efficient Approach for Multimodal Representations Learning
同时降维:一种数据高效的多模态表征学习方法
简述:本文探索了独立降维(IDR)和同时降维(SDR)两类降维方法。IDR独立压缩模态,力求保留个体差异;SDR同时压缩模态,最大化简化描述之间的协变。研究人员引入生成线性模型研究这些方法的准确性和数据集大小要求。实验表明,线性SDR优于线性IDR,使用更小数据集产生更高质量、简洁的降维表示。正则化CCA可识别低维弱协变结构,即使样本数量远小于维数。这些发现表明,当检测协变比保留变异更重要时,应优先选择SDR。
码字不易,欢迎大家点赞评论收藏!
关注下方《享享学AI》
回复【2024多模态融合】获取完整论文