mysql-索引与引擎
文章目录
-
- 数据库引擎
-
- using和on关键字
- myisam
-
- 数据存储
- innodb(默认)
- INNODB三大特性
-
- BufferPool
- 自适应Hash索引
- 双写缓冲区
- 索引本质
- 数据结构
- 创建、删除索引
- 聚集索引
- 辅助索引
-
- 索引覆盖
- 回表
- 最左匹配
- 索引下推
- explain
- 优化
-
-
- 查询索引列不要使用表达式(计算、函数等)
- 前缀索引
- 索引扫描排序
- union all、or、in
- 索引使用范围查询
- 强制类型转化索引失效
- limit使用
- 不要使用select *
- 计数count的使用
- join表连接操作
- 强制使用索引
-
- 行转列
- 自定义变量使用
数据库引擎
using和on关键字
select t1.xx,t1.xx,t2.xx,t2.xx from table1 t1 join table2 t2 on t1.id=t2.id
如果在做多表关联时:两个表关联的字段是一样的就可以使用using,这里使用的两个表的id做关联;效果一样
select t1.xx,t1.xx,t2.xx,t2.xx from table1 t1 join table2 t2 using(id)
myisam
数据存储
索引与数据分开存储
.frm:存储表结构
.myd:存储数据
.myi:存储索引
innodb(默认)
索引与数据不分开
.frm:存储表结构
.idb:存储索引和数据
| myisam | innodb | |
|---|---|---|
| 索引类型 | 非聚簇索引 | 聚簇索引 |
| 支持事务 | 否 | 是 |
| 支持表锁 | 是 | 是 |
| 支持行锁 | 否 | 是 |
| 支持外键 | 否 | 是 |
| 支持全文索引 | 是 | 是(5.6后) |
| 适合操作类型 | 大量select | 大量insert/delete/update |
INNODB三大特性
BufferPool
自适应Hash索引,InnoDB存储引擎内部自己去监控索引表,如果监控到某个索引经常用,那么就认为是热数据,然后内部自
己创建一个hash索引,称之为自适应哈希索引( Adaptive Hash Index,AHI),创建以后,如果下次又查询到这个索引,那么直
接通过hash算法推导出记录的地址,直接一次就能查到数据。
InnoDB存储引擎使用的哈希函数采用除法散列方式,其冲突机制采用链表方式。
自适应Hash索引
Buffer Pool,为了提高访问速度,MySQL预先就分配/准备了许多这样的空间,为的就是与MySQL数据文件中的页做交换,
来把数据文件中的页放到事先准备好的内存中。数据的访问是按照页(默认为16KB)的方式从数据文件中读取到 buffer pool
中。Buffer Pool按照最少使用算法(LRU),来管理内存中的页。
Buffer Pool实例允许有多个,每个实例都有一个专门的mutex保护。Buffer Pool中缓存的数据页类型有: 索引页、数据页、
undo页、插入缓冲(insert buffer)、自适应哈希索引、InnoDB存储的锁信息、数据字典信息(data dictionary)等等
双写缓冲区
双写缓冲区,是一个位于系统表空间的存储区域,在写入时,InnoDB先把从缓冲池中的得到的page写入系统表空间的双写缓
冲区。之后,再把page写到.ibd数据文件中相应的位置。如果在page写入数据文件的过程中发生意外崩溃,InnoDB在稍后的
恢复过程中在doublewrite buffer中找到完好的page副本用于恢复。
doublewrite是顺序写,开销比较小。所以在正常的情况下, MySQL写数据page时,会写两遍到磁盘上,第一遍是写到
doublewrite buffer,第二遍是从doublewrite buffer写到真正的数据文件中。
它的主要作用是为了避免partial page write(部分页写入)的问题。因为InnoDB的page size一般是16KB,校验和写入到
磁盘是以page为单位进行的。而操作系统写文件是以4KB作为单位的,每写一个page,操作系统需要写4个块,中间发生了系统断
电或系统崩溃,只有一部分页面是写入成功的。这时page数据出现不一样的情形,从而形成一个"断裂"的page,使数据产生
混乱,此时就能通过双写缓冲进行恢复
索引本质
索引本身也是一种数据,它的存在就是为了提高数据的查询效率;首先看mysql是如何查找数据的。
默认使用B+树 叶子节点使用双向链表指针(方便范围查询)
mysql的数据是存储在磁盘上(磁盘块,通常大小4k)的,而mysql查找数据需要将数据从磁盘读到内存(这就是io中的读),读取是以页的形式往内存中读取(大小通常为16k),索引的节点就等于是一个页,通常一行数据都是小于16k,那么一个节点上可以存储多行数据
数据结构
二叉树:左右不平衡、树高
二叉平衡树:左旋右旋消耗性能、树高增加IO次数
红黑树:左旋右旋消耗性能、树高增加IO次数
B树:非叶子节点也存储真实数据:树高增加IO次数
B+树索引(默认):非叶子节点存储主键和指针,不存储数据,叶子节点存储数据、叶子节点使用双向链表链接;通常树高为3即可支持千万条数据
hash索引:只支持精确查询(=),不支持范围查询
创建、删除索引
创建
alter table user add index index_name(name,age,address)
CREATE INDEX index_name ON table_name (column_list)
查看
show index from user
删除
drop index index_name on user
alter table table_name drop index index_name
alter table table_name drop PRIMARY KEY
聚集索引
innoDB支持,使用主键建立聚集索引,如果没有主键,会以非空唯一的键建立,如果还是没有,会使用默认生成的ID值
聚集索引的特点是非叶子节点不存储整行数据,只会存储主键和指针等相关数据,叶子节点存储整行数据;这样的好处是:节点大小是固定的,主键值肯定比整行数据小,如果非叶子节点也存储整行数据,那么肯定会增减B+树的树高也就会增加io次数
辅助索引
辅助索引的特点是叶子节点存的不是整行数据,而是索引值和主键值
索引覆盖
比如在使用辅助索引:一张表中以name为辅助索引,在执行select name from table where name=“xxx”,这个查询的是name,而在辅助索引的叶子节点上就存存储了name值,直接就查到了
回表
同上如果select * from table where name=“xxx”;查询的字段不只是name,name辅助索引的叶子节点只存储name值和主键值;这样根据辅助索引查到的主键值再去聚集索引中查找数据(聚集索引叶子节点存储整行数据)
最左匹配
例如创建组合索引:(name,age,adress):name(varchar) age(tinyInt) address(varchar )
会走三个 索引全匹配
select * from xx where name='xx' and age=10 and address='xxx'
会走三个 优化器会自动调整顺序
select * from xx where name='xx' and address='xxx' and age=10
使用name age两个索引
select * from xx where name='xx' and age=10
使用name索引
select * from xx where name='xx' and address='xxx'
不使用索引,创建的组合索引(name,age,address),而只使用name,address
select * from xx where age=10 and address='xxx'
范围查询让后面的索引失效,name age两个索引
select * from xx where name='xx' and age>10 and address='xxx'
最左前缀匹配 xx%,让后面的索引失效 使用name一个索引
select * from xx where name='xx%' and age=10 and address='xxx'
不使用索引
select * from xx where name='%xx' and age=10 and address='xxx'
索引下推
针对组合索引;例如建立组合索引 (name,age)
执行查询:select * from xx where name='x' and age=10
第一种执行方式:现根据name查询出所有数据,再根据age过滤数据
第二种执行方式:在根据name查询数据的时候直接根据age过滤出数据即可(5.7版本后优化器会做处理)
explain
分析sql语句
表:

创建索引:
alter table user add index index_name(name,age,address)
explain select * from user where name='xx'
![]()
type:这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行
依次从最优到最差分别为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
extra:如果是using index 则是覆盖索引;using where是回表
优化
查询索引列不要使用表达式(计算、函数等)
select * from user where id+1=5
不会使用索引
select * from user where id=5-1
会使用索引
前缀索引
比如有一个字段:xx 存储的是很多字母;可能前一位字母相同开头的有很多、前两位开头相同的也很多…直到前n位开头到前n+1位开头的数量几乎保持不变;那么在使用索引查询的时候直接使用前n位查就行,没必要使用整条数据创建索引
如何确定使用多少位合适?比如city列
select count(distinct left(city,3))/count(0) as sel3,
count(distinct left(city,4))/count(0) as sel4,
count(distinct left(city,5))/count(0) as sel5,
count(distinct left(city,6))/count(0) as sel6,
count(distinct left(city,7))/count(0) as sel7,
count(distinct left(city,8))/count(0) as sel9 ......
from xx
观察从第几位开始几乎不变;假如是第八位,那么创建索引时指定位数 节省空间
alter table xx add index_name(city(8))
缺点: 因为索引不存储部分值,无法使用索引覆盖、orderBy、groupBy
索引扫描排序
使用order by时 使用索引排序 创建组合索引(name,age,address)
索引使用顺序与创建顺序保持一致(索引排序与使用索引不同)
满足最左匹配
排序顺序保持一致
explain select * from user where name='' order by age, address

不满足条件索引顺序,优化器无法进行顺序调整(因为排序有顺序)
explain select * from user where name='' order by address, age

不满足最左匹配,范围查询后的索引会失效
explain select * from user where name > '' order by age,address

排序顺序不保持一致
explain select * from user where name>'' order by address, age

union all、or、in
union all和union:union会多一个去重操作效率更低
in和or:建议用in,但是in的数量有限制(1000),不过更多的in用于子查询
索引使用范围查询
使用索引范围查询会使后面的索引使用失效
强制类型转化索引失效
为name创建索引:name是varchar类型
explain select * from user where name='1'

name本身就是varchar类型,查询字符串;用到了索引
explain select * from user where name=1

name是varchar,查询使用整型,数据库会做类型转化,使索引失效
limit使用
如果能确定查询结果只有一条的,尽量使用:limit 1
limit 200000,5优化:例如一张user表,id为自增主键
select * from user where limit 200001,5
但limit的第一个参数太大,会导致全表扫描,效率较低
select * from user where id > (select id form user where id>200000) limit 5
使用子查询,子查询中用到了id,而且是索引覆盖,直接快速将数据定位到第20000条,再取5条数据
不要使用select *
不要使用select *:只查询自己需要的数据;多表关联也不要使用select *
计数count的使用
如果数据库引擎是myisam并且计数没有where条件时:这个效率会很高,因为myisam会将数据的条数存到磁盘中,一定是没有条件的计数
select count(*) as count from table #没有where条件
其实select count(*) 、select count(1)、select count(字段)的效率是一样的
join表连接操作
基于索引 如果两表关联的字段是主键,那么主表在关联其他表时,在查询另一张表时会使用索引而不是全表扫描
基于join buffer:如果两表关联的字段有索引,那么主表在关联其他表时,在查询另一张表时会使用全表扫描
强制使用索引
force index(xx)
select * from table force index(PRI) where id+1>xx #强制使用主键索引
select * from table force index(birth) where year(birth)='2000'#强制使用索引,索引名
行转列
有这样一张表
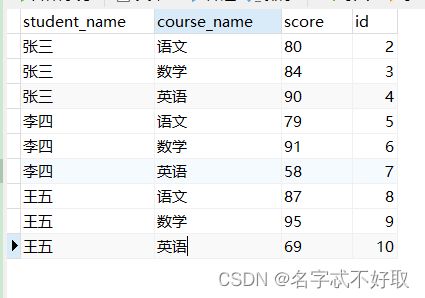
如何将它查询展示成这样:

方法一:case when
select t.student_name,
max(case t.course_name when '语文' then t.score end) '语文' ,
max(case t.course_name when '数学' then t.score end) '数学' ,
max(case t.course_name when '英语' then t.score end) '英语'
from course_score as t GROUP BY t.student_name
如果不使用min函数和group by的效果:
select t.student_name,
case t.course_name when '语文' then t.score end '语文' ,
case t.course_name when '数学' then t.score end '数学' ,
case t.course_name when '英语' then t.score end '英语'
from course_score as t

因为结果是需要一个sdutent_name只有一条结果,自然就想到使用group by student_name,但又因为同一个学生有三条记录,而且每一行只有一个值,按student_name分组就必须使用聚合函数来配合分组,因为其他值都是null,所以不管是用min、max、avg效果都一样(因为null不参与计算)
嵌套select
select t.student_name,
(select score from course_score where course_name='语文' and student_name=t.student_name) '语文',
(select score from course_score where course_name='数学' and student_name=t.student_name) '数学',
(select score from course_score where course_name='英语' and student_name=t.student_name) '英语'
from course_score t GROUP BY t.student_name
子查询不加student_name=t.student_name条件会报错,子查询结果不止一条;因为只是用course_name='语文’条件,表中三位同学都有语文分数,一个同学就会对应三条语文分数;加上student_name=t.student_name才能唯一匹配同学的语文分数
select t.student_name,
(select score from course_score where course_name='语文' and student_name=t.student_name) '语文',
(select score from course_score where course_name='数学' and student_name=t.student_name) '数学',
(select score from course_score where course_name='英语' and student_name=t.student_name) '英语'
from course_score t
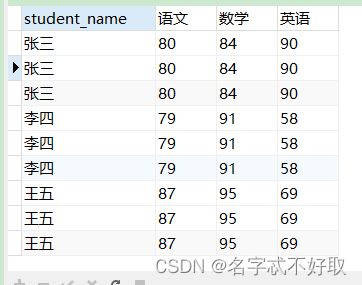
再跟sdutent_name分组即可
join操作
select t1.student_name ,t1.score '语文',t2.score '数学',t3.score '英语' from
(select score,student_name from course_score where course_name='语文') t1 inner join
(select score,student_name from course_score where course_name='数学') t2 using(student_name) inner join
(select score,student_name from course_score where course_name='英语') t3 using(student_name)
自定义变量使用
自定义变量的范围是:当前会话,也就是一次连接有效
赋初始值:@xxx=值 @a=1
值计算:@xxx:=计算 @a:=@+1
查看值:select @xxx select @a
排名
查询添加排名:按语文成绩降序并添加rank排名字段
set @rank=0;
select * ,@rank:=@rank+1 as rank from (select t.student_name,
max(case t.course_name when '语文' then t.score end) '语文' ,
max(case t.course_name when '数学' then t.score end) '数学' ,
max(case t.course_name when '英语' then t.score end) '英语'
from course_score as t GROUP BY t.student_name ) ttt order by 语文 desc

在更新值时获取值
不使用自定义变量:
update course_score set score =100 where id =2;
select score from course_score where id =2
使用自定义变量,减少一次select查询操作
set @score=0;
update course_score set score =100 where id =2 and @score:=100;
select @score;