排序(3)——堆排序
四、堆排序
1.简介
堆排序,看名字就能知道这种排序是基于堆这种数据结构所设计出的一种排序方式。堆排序实际上是基于选择排序做出的一些升级。选择排序是通过每次遍历的方法来选出最大元素,毫无疑问限制其效率的主要因素就是遍历的开销,那么有没有其他方法能够高效实现选数呢,这时候堆就脱颖而出了。
我们知道堆顶的元素是具有特殊性质的。对于大堆,堆顶的元素就是最大值;对于小堆,堆顶元素就是最小值。因此我们将待排序数据构成一个堆,那么选数不就很容易了。这也正是堆排序的核心所在。
2.思路与代码
(1)向下调整算法与向上调整算法
我们曾经在堆的实现中介绍过向下调整算法和向上调整算法,它们的目的都是调整堆中的数据位置,使得整个数组继续维持堆的特性。
向下调整发生在一个结点其左右子树都已经是堆,而此结点不符合堆的情况。
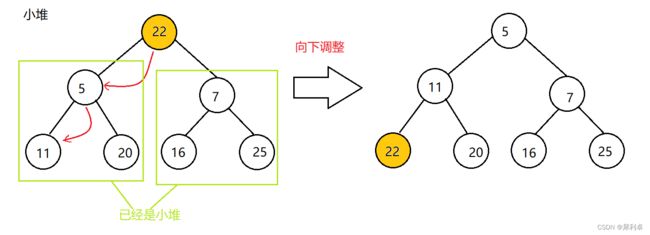
①确定要调整的结点为父结点;
②选出子结点中较小者(小堆,大堆应选出较大者),判断与父结点的大小关系;
③如果满足堆关系,即小堆下父结点小于子结点,大堆下父结点大于子结点,则终止向下调整。否则就交换父子结点,并调整父结点与子结点坐标。
注:父结点*2+1=左孩子 父结点*2+2=右孩子
//小堆向下调整
void AdjustDownMin(int* a, int size, int parent)
{
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] < a[child])
{
child++;
}
if (a[parent] > a[child])
{
swap(&a[parent], &a[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//大堆向下调整
void AdjustDownMax(int* a, int size, int parent)
{
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] > a[child])
{
child++;
}
if (a[parent] < a[child])
{
swap(&a[parent], &a[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}向上调整发生在堆底插入数据的情况,即在除该结点外的堆满足堆的要求,插入该结点需要调整位置使得满足堆结构。
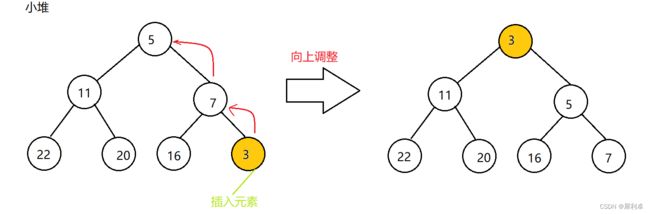
①确定要要调整的结点为子结点;
②由子结点得到父结点下标,并进行比较;
③ 如果满足堆关系,即小堆下父结点小于子结点,大堆下父结点大于子结点,则终止向上调整。否则就交换父子结点,并调整父结点与子结点坐标。
注:父结点=(子结点-1)/2
//小堆向上调整
void AdjustUpMin(int* arr, int size)
{
int child = size - 1;
int parent = (child - 1) / 2;
while (child > 0)
{
if (arr[child] < arr[parent])
{
swap(&arr[child], &arr[parent]);
child = parent;
parent = (parent - 1) / 2;
}
else
{
break;
}
}
}
//大堆向上调整
void AdjustUpMax(int* arr, int size)
{
int child = size - 1;
int parent = (child - 1) / 2;
while (child > 0)
{
if (arr[child] > arr[parent])
{
swap(&arr[child], &arr[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}(2)建堆——大堆or小堆
为了完成堆排序,建堆是我们第一步要干的事。
首先需要考虑的是建什么堆。首先要明确我们所要建立的堆并非再专门开辟一块空间,而是在原数组基础上将其改造成为堆。堆起到选择数据的作用,如果我们要排升序,那我们应该建大堆。这是因为如果采用小堆,选出的是最小的元素,需要放在数组左端,而我们的堆又是以左端为首,这样的话就会导致堆结构被破坏,难以恢复。
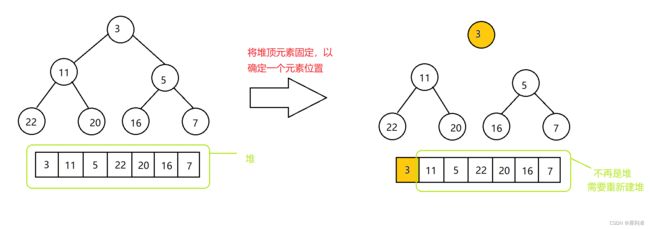
而大堆可以选出最大的元素,放在队尾,这时只需要向下调整即可。
向下调整与向上调整的时间复杂度很明显是 ,重新建堆的效率肯定是不及向下调整的(重新建堆的效率我们会在下文中进行计算)。所以我们一般采取升序用大堆,降序用小堆的策略。
,重新建堆的效率肯定是不及向下调整的(重新建堆的效率我们会在下文中进行计算)。所以我们一般采取升序用大堆,降序用小堆的策略。
(3)建堆——向上调整建堆or向下调整建堆
在明确了建什么堆后,我们应该继续解决如何建堆的问题。对于建堆我们一般有两种方案,采用向上调整算法进行建堆和采用向下调整算法建堆。那么他们孰优孰劣呢?
[1] 向上调整算法建堆
向上调整算法建堆是比较符合我们常规逻辑的方法,即对于一个数组,我们从堆大小为0开始扩展,每扩展一步就将其视为元素入堆进行向上调整。
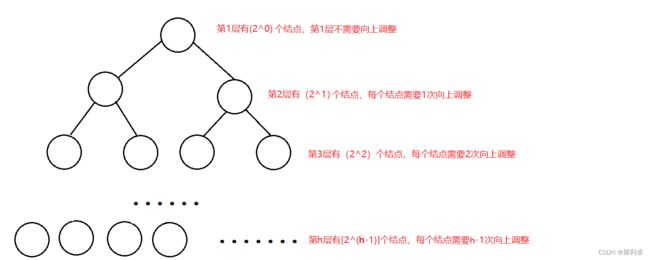
假设整个树具有n个结点,具有h层。我们以满二叉树来考虑以简化问题,实际上我们所要计算的复杂度只是数量级关系,所以考虑为满二叉树对结果的影响可以忽略不计。那么此时结点个数和层数之间满足关系:![]() ,也即
,也即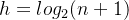 。
。
对于这样一个树,整个向上调整建堆的过程需要向上调整的总次数S就是每一层结点数与需要调整次数的乘积,即:![]() 。利用无穷级数求和的相关方法,先求导再积分即可得出结果(在这里复习一下高数的知识):
。利用无穷级数求和的相关方法,先求导再积分即可得出结果(在这里复习一下高数的知识):
对![]() 进行计算,我们先分出一个x得到
进行计算,我们先分出一个x得到![]() ,对求和符号进行积分再求和最后求导,整理得
,对求和符号进行积分再求和最后求导,整理得![]() 。这时令x=2,即可求得S的值为:
。这时令x=2,即可求得S的值为:![]() 。由于n与h之间存在等价关系,所以我们可以替换得到:
。由于n与h之间存在等价关系,所以我们可以替换得到:![]() ,通过大O渐进表示法,我们可以得出结论:向上调整建堆的时间复杂度为
,通过大O渐进表示法,我们可以得出结论:向上调整建堆的时间复杂度为![]() 。
。
[2] 向下调整算法建堆
向下调整算法建堆则是建堆的另一种方案。因为向下调整算法发生在左右子树均为堆的情况下,所以所有叶子结点不需要向下调整,就像整棵树的根结点不需要向上调整一样。向下调整从最后一个非叶子结点开始,从后向前依次调整,这是为了保证调整到任一结点其左右子树都是经过调整后的堆形式。
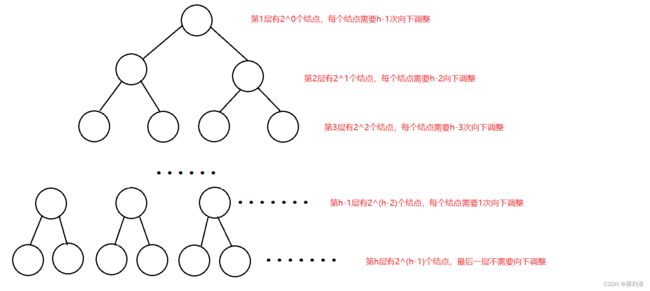
我们计算向下调整总次数时,思路与向上调整相似,等价关系依然成立。
整个向下调整建堆的过程需要的向下调整的总次数S依旧是每一层结点数与需要调整次数的乘积,即:![]() 。
。
对于![]() ,我们能够直接通过等比数列求和公式得出结果:
,我们能够直接通过等比数列求和公式得出结果:![]() 。
。
对于![]() ,我们采取积分再求和最后求导:
,我们采取积分再求和最后求导:![]() 。
。
通分整理合并,得到![]() 。这时令x=2,即可求得S的值为:
。这时令x=2,即可求得S的值为:![]() 。由于n与h之间存在等价关系,所以我们可以替换得到:
。由于n与h之间存在等价关系,所以我们可以替换得到:![]() ,通过大O渐进表示法,我们可以得出结论:向上调整建堆的时间复杂度为
,通过大O渐进表示法,我们可以得出结论:向上调整建堆的时间复杂度为 。
。
(4)代码
通过以上计算,我们会发现采取向下调整算法建堆的代价最小,是最理想的方案,所以我们此处也采取向下调整算法建堆。
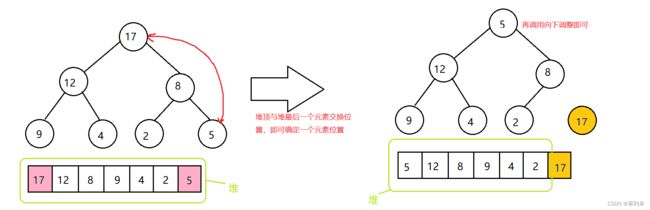
使用向下调整算法建堆需要确定最后一个非叶子结点的下标,而这个结点正是最后一个结点的父结点,所以我们可以直接通过父结点与子结点的关系得到。在建堆完成后我们只需要将堆顶有元素换位到合适位置然后向下调整即可。
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void AdjustDownMax(int* a, int size, int parent)
{
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] > a[child])
{
child++;
}
if (a[parent] < a[child])
{
swap(&a[parent], &a[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void AdjustDownMin(int* a, int size, int parent)
{
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] < a[child])
{
child++;
}
if (a[parent] > a[child])
{
swap(&a[parent], &a[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
// 堆排序
// 升序——建大堆
void HeapSort1(int* a, int n)
{
//向下调整建堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDownMax(a, n, i);
}
//换位取数,向下调整
for (int i = n - 1; i > 0; i--)
{
swap(&a[0], &a[i]);
AdjustDownMax(a, i, 0);
}
}
// 降序——建小堆
void HeapSort2(int* a, int n)
{
//向下调整建堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDownMin(a, n, i);
}
//换位取数,向下调整
for (int i = n - 1; i > 0; i--)
{
swap(&a[0], &a[i]);
AdjustDownMin(a, i, 0);
}
}3.复杂度与稳定性分析
(1)时间复杂度
堆排序主要可以看作两部分,一部分是向下调整建堆的部分,这部分我们已经计算过其所需要的时间复杂度为O(n)。第二部分为换位再向下调整,我做出如下分析:

可见其调整次数为![]() ,可见其表达式中
,可见其表达式中![]() 部分与向上调整算法复杂度计算相同,我们已经得知向上调整总次数
部分与向上调整算法复杂度计算相同,我们已经得知向上调整总次数![]() 。因此换位向下调整部分的调整总次数
。因此换位向下调整部分的调整总次数![]() 。等价关系仍然成立,所以我们可计算得到
。等价关系仍然成立,所以我们可计算得到![]() 。依旧是通过大O渐进表示法,我们可以知道第二部分的换位再向下调整的时间复杂度为
。依旧是通过大O渐进表示法,我们可以知道第二部分的换位再向下调整的时间复杂度为![]() 。
。
总和两部分,我们可以通过我们已有的计算结果精确地将二者调整次数求和:![]() 。不难得出结论:堆排序的时间复杂度为
。不难得出结论:堆排序的时间复杂度为![]() 。
。
(2)空间复杂度
堆排序并未用到多余额外的空间,所以空间复杂度是 。
。
(3)稳定性
堆排序是不稳定的。
堆排序中存在大量数据的来回调整换位,其相对顺序明显是不可控的,所以是不稳定的。