Redis的核心数据结构以及高性能底层原理
文章目录
- 一、Redis的单线程和高性能
- 二、Redis的核心数据结构
- 总结
一、Redis的单线程和高性能
Redis是单线程吗?
Redis实际意义上来说不是单线程的。Redis的单线程是指网络IO键值对的读写以及执行命令是由一个线程完成的,但是异步删除、AOF文件重写、持久化以及集群的数据同步都是由其他线程来完成的。
Redis 单线程为什么还能这么快?
Redis的所有操作都是基于内存中实现的,执行的速度较快。而且使用一个线程来处理读写逻辑过程中,避免了上下文切换。所以Redis单线程还能很快的原因。
要注意的一点:正是因为Redis是单线程的,所以我们在使用Redis的时候需要注意那些可能引起Redis阻塞的操作,防止Redis的线程进入阻塞状态,导致Redis效率降低。
Redis 单线程如何处理那么多的并发客户端连接?
Redis是一个NIO模型。它将所有的请求放入一个队列中,一个一个地处理请求。通过文件事件分派器将请求发送给事件处理器也就是Redis的线程去处理请求。所以Redis单线程还可以处理很多的并发客户端连接。

Scan渐进式遍历键
SCAN cursor [MATCH pattern] [COUNT count]
scan 参数提供了三个参数,第一个是 cursor 整数值(hash桶的索引值),第二个是 key 的正则模式,第三个是一次遍历的key的数量(参考值,底层遍历的数量不一定),并不是符合条件的结果数量。第一次遍历时,cursor 值为 0,然后将返回结果中第一个整数值作为下一次遍历的 cursor。一直遍历到返回的 cursor 值为 0 时结束。
注意:但是scan并非完美无瑕, 如果在scan的过程中如果有键的变化(增加、 删除、 修改) ,那么遍历效果可能会碰到如下问题: 新增的键可能没有遍历到, 遍历出了重复的键等情况, 也就是说scan并不能保证完整的遍历出来所有的键, 这些是我们在开发时需要考虑的。
SCAN cursor[游标] match 表达式 count 数量
SCAN扫描的数量并不是一次扫描符合表达式的次数,而是扫描所有key的次数。并不是符合条件的结果数量。每次返回会返回下次游标的值已经扫描符合条件的结果,然后继续安装给的游标的值继续扫描一直到返回的游标值为0.所有的返回结果加起来就是我们要获取的结果。–它就是分开获取所有符合条件的key,如果使用keys *可能key太多了,就会造成阻塞。
127.0.0.1:6379[5]> keys *
1) "lpc1"
2) "lpc3"
3) "lpc7"
4) "lpc6"
5) "lpc4"
6) "lpc2"
7) "lpc8"
8) "lpc9"
9) "lpc5"
127.0.0.1:6379[5]> SCAN 0 lpc* 3
(error) ERR syntax error
127.0.0.1:6379[5]> SCAN 0 match lpc* count 3
1) "14"
2) 1) "lpc4"
2) "lpc2"
3) "lpc6"
127.0.0.1:6379[5]> SCAN 14 match lpc* count 3
1) "13"
2) 1) "lpc1"
2) "lpc3"
3) "lpc7"
127.0.0.1:6379[5]> SCAN 13 match lpc* count 3
1) "0"
2) 1) "lpc8"
2) "lpc9"
3) "lpc5"
127.0.0.1:6379[5]>
二、Redis的核心数据结构
String类型
常用的操作
SET key value //存入字符串键值对
MSET key value [key value ...] //批量存储字符串键值对
SETNX key value //存入一个不存在的字符串键值对
GET key //获取一个字符串键值
MGET key [key ...] //批量获取字符串键值
DEL key [key ...] //删除一个键
EXPIRE key seconds //设置一个键的过期时间(秒)
原子加减
INCR key //将key中储存的数字值加1
DECR key //将key中储存的数字值减1
INCRBY key increment //将key所储存的值加上increment
DECRBY key decrement //将key所储存的值减去decrement
对象缓存
1.set user:1 {name:lupengcheng,age:20}
2.set user1:name lupengcheng set user:1:age 20
分布式锁
SETNX product:10001 true //返回1代表获取锁成功
SETNX product:10001 true //返回0代表获取锁失败
。。。执行业务操作
DEL product:10001 //执行完业务释放锁
SET product:10001 true ex 10 nx //防止程序意外终止导致死锁
业务场景
1.文章的阅读量
//设置文章的key
set actitle:1 0
//每次点击一次阅读功能文章的阅读量+1
incrby arcitle:1 1
//取出id为1的文章的阅读量
get arcitle:1

2.集群的session共享
spring session + redis的session共享--单点登录
3.分布式全局序列号
分布式集群下,一张订单表可能会分库分表。这样使用mysql提供的主键自增功能就无法使用。我们可以使用redis生成全局序列号
set orderId 0
每次需要一个订单的id就执行incrby命令,这样可以获取到全局序列号
incrby orderId 1
问题:可能有几千万个订单需要生成,那么redis的压力会特别大。所以我们可以一次性取1000条id到内存中。用完了再取。
hash类型
Hash常用操作
HSET key field value //存储一个哈希表key的键值
HSETNX key field value //存储一个不存在的哈希表key的键值
HMSET key field value [field value ...] //在一个哈希表key中存储多个键值对
HGET key field //获取哈希表key对应的field键值
HMGET key field [field ...] //批量获取哈希表key中多个field键值
HDEL key field [field ...] //删除哈希表key中的field键值
HLEN key //返回哈希表key中field的数量
HGETALL key //返回哈希表key中所有的键值
HINCRBY key field increment //为哈希表key中field键的值加上增量increment
对象缓存
HMSET user 1:name jack 1:age 20 1:gender male
hmget user 1:name 1:age 1:gender
1) "jack"
2) "20"
3) "male"
Hash应用场景
购物车
电商购物车功能实现:
1.以用户的id为key–car用户Id
2.以商品的id为field
3.商品的数量为value
例如:hset car:1 good:1 2

功能实现:
1.商品数量增加:HINCRBY car:1 good:1 1—(integer) 3
2.商品数量减少:HINCRBY car:1 good:1 -1—(integer) 2
3.删除商品:HDEL car:1 good:1
4.全选:HGETALL car:1
1) “good:2”
2) “2”
3) “good:3”
4) “3”
5.购物车的商品数量:HLEN car:1
(integer) 2
Hash结构优缺点
优点
1)同类数据归类整合储存,方便数据管理
2)相比string操作消耗内存与cpu更小
3)相比string储存更节省空间
缺点
过期功能不能使用在field上,只能用在key上
Redis集群架构下不适合大规模使用
List结构
List常用操作
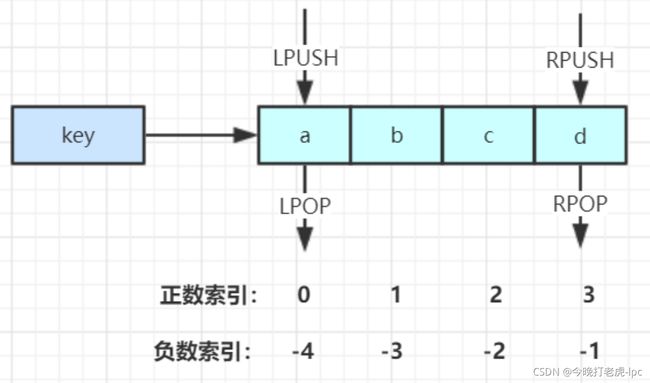
LPUSH key value [value ...] //将一个或多个值value插入到key列表的表头(最左边)
RPUSH key value [value ...] //将一个或多个值value插入到key列表的表尾(最右边)
LPOP key //移除并返回key列表的头元素
RPOP key //移除并返回key列表的尾元素
LRANGE key start stop //返回列表key中指定区间内的元素,区间以偏移量start和stop指定
BLPOP key [key ...] timeout //从key列表表头弹出一个元素,若列表中没有元素,
//阻塞等待timeout秒,如果timeout=0,一直阻塞等待
BRPOP key [key ...] timeout //从key列表表尾弹出一个元素,若列表中没有元素,
//阻塞等待timeout秒,如果timeout=0,一直阻塞等待
List应用场景
微博和微信公号消息流


例如jack关注了大V【curry】
如果curry发布了一条动态,那么jack在看朋友圈的时候应该刷到curry发的动态。如果多条动态则按时间顺序排序【最新的在前面】–满足list的栈结构
LPUSH mesg:{用户Id} 动态id
如果大Vjames也发布了一条动态,也要加入jack的信息集合中
LPUSH mesg:{用户Id} 动态id
当jack打开朋友圈,执行LRANGE mesg:用户Id start end-查看最新的动态
LPUSH mesg:1 mesg1 mesg2 mesg3 mesg4 mesg5
(integer) 5
127.0.0.1:6379[2]> LRANGE mesg:1 0 3
1) "mesg5"
2) "mesg4"
3) "mesg3"
4) "mesg2"
Set结构
Set常用操作
SADD key member [member ...] //往集合key中存入元素,元素存在则忽略,若key不存在则新建
SREM key member [member ...] //从集合key中删除元素
SMEMBERS key //获取集合key中所有元素
SCARD key //获取集合key的元素个数
SISMEMBER key member //判断member元素是否存在于集合key中
SRANDMEMBER key [count] //从集合key中选出count个元素,元素不从key中删除
SPOP key [count] //从集合key中选出count个元素,元素从key中删除
Set运算操作
SINTER key [key ...] //交集运算
SINTERSTORE destination key [key ..] //将交集结果存入新集合destination中
SUNION key [key ..] //并集运算
SUNIONSTORE destination key [key ...] //将并集结果存入新集合destination中
SDIFF key [key ...] //差集运算
SDIFFSTORE destination key [key ...] //将差集结果存入新集合destination中
Set应用场景
抽奖的场景:
点击参与抽奖:SADD active:1 用户ID
查看全部:SMEMBERS active:1
参与抽奖的用户加入到活动集合中,如果只有一轮抽奖那么可以使用SRANGE随机抽取中奖用户;如果抽奖分为一等奖 二等奖 三等奖的话使用SPOP每次将随机的中奖用户删除进行下一轮的抽奖环节
//参与活动1抽奖的用户为10个
127.0.0.1:6379[3]> SMEMBERS active:1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "213"
9) "223"
10) "2112"
//只抽取3个中奖用户--随机的,每次都不一样
127.0.0.1:6379[3]> SRANDMEMBER active:1 3
1) "213"
2) "1"
3) "3"
127.0.0.1:6379[3]> SRANDMEMBER active:1 3
1) "213"
2) "2"
3) "2112"
127.0.0.1:6379[3]> SRANDMEMBER active:1 3
1) "4"
2) "223"
3) "2"
127.0.0.1:6379[3]> SRANDMEMBER active:1 3
1) "213"
2) "4"
3) "2"
//抽取3个三等奖
127.0.0.1:6379[3]> SPOP active:1 3
1) "3"
2) "2"
3) "4"
//抽取2个二等奖
127.0.0.1:6379[3]> SPOP active:1 2
1) "2112"
2) "5"
//抽取1个一等奖
127.0.0.1:6379[3]> SPOP active:1 1
1) "213"
//剩余用户
127.0.0.1:6379[3]> SMEMBERS active:1
1) "1"
2) "6"
3) "7"
4) "223"
1、点赞
SADD like:消息ID 用户ID
2、取消点赞
SREM like:消息ID 用户ID
3、检查用户是否点赞–如果点赞了那小爱心会变为红色
SISMEMBER like:消息ID 用户ID
4、获取点赞的用户列表
SMEMBERS like:消息ID
5、获取点赞的用户数量
SCARD like:消息ID
6、本人查看评论列表
当一个好友给“我”的动态进行评论,评论ID会记录在“我” 的comments:消息ID集合中,然后SMEMBERS comments:消息ID获得所有评论
集合操作

集合操作实现微博微信关注模型[很重要]

//jack关注的人-1
Focus:jackId = {merry,james}
//merry关注的人-2
Focus:merryId = {jack,tom}
//tom关注的人-3
Focus:tomId = {merry}
//james关注的人-4
Focus:jamesId = {merry,jack}
//【微关系--共同关注功能】假如我是jack,我和james共同关注的人:
SINTER Focus:jackId Focus:jamesId = {merry}
SINTER focus:1 focus:4
1) "2"
//可能认识的人--我关注的人,他关注的人是我可能认识的人[这里加入这个人是merry-如果复杂一点可以将jack的所有关注的人的关注的人集合一起取差集]
SDIFF focus:2 focus:1 //当然这里除去自己
1) "1"
2) "3"
//我关注的人也关注她--1为true 0为false
SISMEMBER focus:4 2
ZSet有序集合结构
ZSet常用操作
ZADD key score member [[score member]…] //往有序集合key中加入带分值元素
ZREM key member [member …] //从有序集合key中删除元素
ZSCORE key member //返回有序集合key中元素member的分值
ZINCRBY key increment member //为有序集合key中元素member的分值加上increment
ZCARD key //返回有序集合key中元素个数
ZRANGE key start stop [WITHSCORES] //正序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES] //倒序获取有序集合key从start下标到stop下标的元素
Zset集合操作
ZUNIONSTORE destkey numkeys key [key ...] //并集计算
ZINTERSTORE destkey numkeys key [key …] //交集计算
Zset应用场景

Zset集合操作实现排行榜
1)点击新闻
ZADD hotNew:20210801 1 守护香港
2)展示当日排行前十
ZREVRANGE hotNew:20210801 0 9
3)七日搜索榜单计算
ZUNIONSTORE hotNew:20210720-23 4 hotNew:20210720 hotNew:20210721 hotNew:20210722 hotNew:20210723
(integer) 6
127.0.0.1:6379[4]> ZREVRANGE hotNew:20210720-23 0 -1 WITHSCORES
1) "wyf"
2) "363562"
3) "dmz"
4) "40045"
5) "lpc"
6) "13466"
7) "ym"
8) "5246"
9) "hh"
10) "4800"
11) "wyb"
12) "2000"
展示七日排行前十
//展示四日排行前5
127.0.0.1:6379[4]> ZREVRANGE hotNew:20210720-23 0 4
1) "wyf"
2) "dmz"
3) "lpc"
4) "ym"
5) "hh"
总结
基本介绍了Redis的各种数据结构以及使用场景。这也只是一小部分的使用,有很多地方都可以使用到redis。不仅仅只有String哦。需要我们认真的思考决定使用哪种数据结构。