Logstash 7.7.1版本安装&系统梳理
前言
上一篇文章介绍了 《ElasticSearch7.7.1集群搭建 & Kibana安装》,今天说一下 Logstash的安卓和配置;
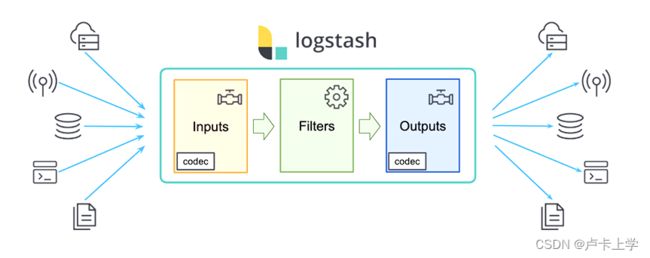
Logstash是一个开源的数据收集引擎,具有实时管道功能。它可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。Logstash常用于日志关系系统中做日志采集设备。
Logstash的事件(logstash将数据流中等每一条数据称之为一个event)处理流水线有三个主要角色完成:inputs –> filters –> outputs。Inputs负责产生事件,常用如File、syslog、redis、beats(如Filebeats);filters负责数据处理与转换,常用如grok、mutate、drop、clone、geoip;outputs负责数据输出,常用如elasticsearch、file、graphite、statsd。其中inputs和outputs支持codecs(coder&decoder),使得logstash可以更好更方便的与其他有自定义数据格式的运维产品共存,比如graphite、fluent、netflow、collectd,以及使用msgpack、json、edn等通用数据格式的其他产品等。
简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
一、Logstash 下载&安装
在服务器上直接通过
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.7.1.tar.gz
下载到安装路径(/usr/local/webserver), 也可以在我的资源来进行下载
$ tar zxvf logstash-7.7.1.tar.gz
$ cd logstash-7.7.1 目录结构如下
测试安装是否成功
$ ./bin/logstash -e 'input { stdin {} } output { stdout {} }'
二 Logstash 项目实践简述
1、Mysql 读取数据到 ElasticSearch7.7.1集群
首先我们在 logstash-7.7.1 /config-mysql 目录 用于存放配置文件
1.1、input 部分说明,jdbc 可以配置多个配置不同的 tags
input {
stdin {
}
#search
jdbc {
# 数据库链接配置
jdbc_connection_string => "jdbc:mysql://10.10.1.1:3306/web_db?zeroDr=CONVERT_TO_NULL&characterEncoding=utf-8"
# 数据库用户名密码
jdbc_user => "app_dba"
jdbc_password => "coaaBtLc0n"
# 链接数据库的jar包的位置
jdbc_driver_library => "/data/software/logstash-7.7.1/mysql-connector-java-8.0.11.jar"
# mysql的 Driver
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "3000"
lowercase_column_names => "false"
record_last_run => true
use_column_value => "true"
tracking_column => "updatetime"
#执行获取数据的sql语句
statement => "select * from logstash_search where updatetime > :sql_last_value order by updatetime"
schedule => "* * * * *"
#tags
tags => "jdbc_logstash_search"
#数据记录执行日志,主要就是记录 sql_last_value 变量的值
last_run_metadata_path => "/data/software/logstash-7.7.1/data_config/last_run_value_search.log"
}
}1.2、filter 部分,通过 tags 做判断进行格式处理
filter {
#===================search
if "jdbc_logstash_search" in [tags]{
json {
source => "location"
}
mutate {
remove_field => ["@version","@timestamp","type","updatetime"]
}
}
}1.3、output部分,通过tags判断输出到不到的数据存储位置
output {
stdout {
codec => "json_lines"
}
#search
if "jdbc_logstash_search" in [tags]{
elasticsearch {
hosts => "10.10.1.10:9200"
# index名
index => "searchv1"
# 需要关联的数据库中有一个id字段,对应索引的id号
document_id => "%{esid}"
document_type => "search"
}
}
} 2、Mysql读起数据导 Kafka集群
input 部分、filter 部分 基本一致
主要是output部分,通过 tags 进行区分存储
output {
stdout {
codec => "rubydebug"
}
#house_recommend
if ("jdbc_logstash_search_0" in [tags]) or ("jdbc_logstash_search_1" in [tags]) {
kafka {
codec => "json"
topic_id => "Realinfo_search"
#kafka集群
bootstrap_servers => "dmp01:9092,dmp02:9092,dmp3:9092"
}
}
}三 Logstash 扩展知识点
启动配置 输入(input),过滤器(filter),输出(output)
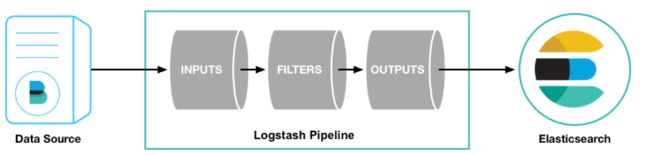
1、数据的输入(input) 插件:
Stdin(标准数据)、File(文件)、jdbc(数据库)、filebeat(日志) 等等 官方文档input-plugins
1.1、文件类型(file)
input{
file{
#path属性接受的参数是一个数组,其含义是标明需要读取的文件位置
path => [‘pathA’,‘pathB’]
#表示多就去path路径下查看是够有新的文件产生。默认是15秒检查一次。
discover_interval => 15
#排除那些文件,也就是不去读取那些文件
exclude => [‘fileName1’,‘fileNmae2’]
#被监听的文件多久没更新后断开连接不在监听,默认是一个小时。
close_older => 3600
#在每次检查文件列 表的时候, 如果一个文件的最后 修改时间 超过这个值, 就忽略这个文件。 默认一天。
ignore_older => 86400
#logstash 每隔多 久检查一次被监听文件状态( 是否有更新) , 默认是 1 秒。
stat_interval => 1
#sincedb记录数据上一次的读取位置的一个index
sincedb_path => ’$HOME/. sincedb‘
#logstash 从什么 位置开始读取文件数据, 默认是结束位置 也可以设置为:beginning 从头开始
start_position => ‘beginning’
#注意:这里需要提醒大家的是,如果你需要每次都从同开始读取文件的话,关设置start_position => beginning是没有用的,你可以选择sincedb_path 定义为 /dev/null
}
}
1.2、数据库类型(jdbc)
input{
jdbc{
#jdbc sql server 驱动,各个数据库都有对应的驱动,需自己下载
jdbc_driver_library => "/etc/logstash/driver.d/sqljdbc_2.0/enu/sqljdbc4.jar"
#jdbc class 不同数据库有不同的 class 配置
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
#配置数据库连接 ip 和端口,以及数据库
jdbc_connection_string => "jdbc:sqlserver://200.200.0.18:1433;databaseName=test_db"
#配置数据库用户名
jdbc_user =>
#配置数据库密码
jdbc_password =>
#上面这些都不重要,要是这些都看不懂的话,你的老板估计要考虑换人了。重要的是接下来的内容。
# 定时器 多久执行一次SQL,默认是一分钟
# schedule => 分 时 天 月 年
# schedule => * 22 * * * 表示每天22点执行一次
schedule => "* * * * *"
#是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => false
#是否需要记录某个column 的值,如果 record_last_run 为真,可以自定义我们需要表的字段名称,
#此时该参数就要为 true. 否则默认 track 的是 timestamp 的值.
use_column_value => true
#如果 use_column_value 为真,需配置此参数. 这个参数就是数据库给出的一个字段名称。当然该字段必须是递增的,可以是 数据库的数据时间这类的
tracking_column => create_time
#是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run => true
#们只需要在 SQL 语句中 WHERE MY_ID > :last_sql_value 即可. 其中 :last_sql_value 取得就是该文件中的值
last_run_metadata_path => "/etc/logstash/run_metadata.d/my_info"
#是否将字段名称转小写。
#这里有个小的提示,如果你这前就处理过一次数据,并且在Kibana中有对应的搜索需求的话,还是改为true,
#因为默认是true,并且Kibana是大小写区分的。准确的说应该是ES大小写区分
lowercase_column_names => false
#你的SQL的位置,当然,你的SQL也可以直接写在这里。
#statement => SELECT * FROM tabeName t WHERE t.creat_time > :last_sql_value
statement_filepath => "/etc/logstash/statement_file.d/my_info.sql"
#数据类型,标明你属于那一方势力。单了ES哪里好给你安排不同的山头。
type => "my_info"
}
注意:外载的SQL文件就是一个文本文件就可以了,还有需要注意的是,一个jdbc{}插件就只能处理一个SQL语句, #如果你有多个SQL需要处理的话,只能在重新建立一个jdbc{}插件。
1.3、多端口beats类型,可同时启用
用来接收各个来源的log(搭配filebeat使用)
```bash
input {
beats {
id => "web_log"
port => 6043
}
beats{
port => 6044
}
beats {
type => "nginx_log"
id => "v3"
port => 6045
}
}
数据在线程之间以 事件 的形式流传,因为 logstash 可以处理多行事件。
Logstash 会给事件添加一些额外信息。最重要的就是 @timestamp,用来标记事件的发生时间。因为这个字段涉及到Logstash 的内部流转,所以必须是一个 joda 对象(java的时间类库),如果你尝试自己给一个字符串字段重命名为 @timestamp 的话,Logstash 会直接报错。所以,请使用 filters/date 插件 来管理这个特殊字段。
此外,大多数时候,还可以见到另外几个:
host 标记事件发生在哪里。
type 标记事件的唯一类型。
tags 标记事件的某方面属性。这是一个数组,一个事件可以有多个标签。
你可以随意给事件添加字段或者从事件里删除字段。事实上事件就是一个 Ruby 对象,或者更简单的理解为就是一个哈希也行。
2、对数据的过滤(filter)
2.1、filter简要说明
Logstash三个组件的第二个组件,也是真个Logstash工具中最复杂,最蛋疼的一个组件,当然也是最有作用的一个组件。每个 logstash 过滤插件,都会有四个方法 add_tag, remove_tag, add_field 和 remove_field 它们在插件过滤匹配成功时生效。官网文档filter-plugins
Logstash从 1.3.0 版开始支持条件判断和表达式。
```bash
表达式支持下面这些操作符:
equality, etc: ==, !=, <, >, <=, >=
regexp: =~, !~
inclusion: in, not in
boolean: and, or, nand, xor
unary: !()通常来说,你都会在表达式里用到字段引用。比如:
if "jdbc_logstash_search_0" not in [tags] {
#内容
} else if [status] !~ /^2\d\d/ and [url] == "/noc.gif" {
#内容
} else {
#内容
}filter插件:Grok、Date、Mutate等等
2.2、Grok插件
grok是一个十分强大的logstash filter插件,他可以通过正则解析任意文本,将非结构化日志数据弄成结构化和方便查询的结构。他是目前logstash 中解析非结构化日志数据最好的方式。
Grok 的语法规则是:%{语法: 语义}
%{IP:clientip}匹配模式将获得的结果为:clientip: 172.16.213.132
%{HTTPDATE:timestamp}匹配模式将获得的结果为:timestamp: 07/Feb/2018:16:24:19 +0800
%{QS:referrer}匹配模式将获得的结果为:referrer: "GET / HTTP/1.1"
%{NUMBER:response}匹配模式将获得的结果为:NUMBER: "403"
%{NUMBER:bytes}匹配模式将获得的结果为:NUMBER: "5039"
通过上面这个组合匹配模式,我们将输入的内容分成了五个部分,即五个字段,将输入内容分割为不同的数据字段,这对于日后解析和查询日志数据非常有用,这正是使用grok的目的。
input{
stdin{}
}
filter{
grok{
match => ["message","%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}"]
}
}
output{
stdout{
codec => "rubydebug"
}
}2.3、Date插件
date插件是对于排序事件和回填旧数据尤其重要,它可以用来转换日志记录中的时间字段,变成LogStash::Timestamp对象,然后转存到@timestamp字段里,这在之前已经做过简单的介绍。
input{
stdin{}
}
filter {
grok {
match => ["message", "%{HTTPDATE:timestamp}"]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
}
output{
stdout{
codec => "rubydebug"
}
}2.4、数据修改(Mutate)
1)正则表达式替换匹配字段
gsub可以通过正则表达式替换字段中匹配到的值,只对字符串字段有效,下面是一个关于mutate插件中gsub的示例(仅列出filter部分):
filter {
mutate {
gsub => ["filed_name_1", "/" , "_"]
}
}这个示例表示将filed_name_1字段中所有"/"字符替换为"_"。
2)分隔符分割字符串为数组
split可以通过指定的分隔符分割字段中的字符串为数组,下面是一个关于mutate插件中split的示例(仅列出filter部分):
filter {
mutate {
split => ["filed_name_2", "|"]
}
}这个示例表示将filed_name_2字段以"|"为区间分隔为数组。
3)重命名字段
rename可以实现重命名某个字段的功能,下面是一个关于mutate插件中rename的示例(仅列出filter部分):
filter {
mutate {
rename => { "old_field" => "new_field" }
}
}这个示例表示将字段old_field重命名为new_field。
4)删除字段
remove_field可以实现删除某个字段的功能,下面是一个关于mutate插件中remove_field的示例(仅列出filter部分):
filter {
mutate {
remove_field => ["timestamp"]
}
}这个示例表示将字段timestamp删除。
详细的配置文件举例:
首先转换成多个字段 --> 去除message字段 --> 日期格式转换 --> 字段转换类型 --> 字段重命名 --> replace替换字段 --> split按分割符拆分数据成为数组
input {
stdin {}
}
filter {
grok {
match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" }
remove_field => [ "message" ]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate {
convert => [ "response","float" ]
rename => { "response" => "response_new" }
gsub => ["referrer","\"",""]
split => ["clientip","\."]
}
}
output {
stdout {
codec => "rubydebug"
}
}3、Logstash输出插件(output)
output是Logstash的最后阶段,一个事件可以经过多个输出,而一旦所有输出处理完成,整个事件就执行完成。也就是说可以输出到多个数据终点。
包括 file、elasticsearch、stdout、exec 插件,官网文档Output plugins
3.1、file: 表示将日志数据写入磁盘上的文件。
output {
file {
path => "/data/log/%{+yyyy-MM-dd}/%{host}_%{+HH}.log"
}
}3.2、elasticsearch:表示将日志数据发送给Elasticsearch
output {
elasticsearch {
host => ["192.168.1.1:9200","172.16.213.77:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}- host:是一个数组类型的值,后面跟的值是elasticsearch节点的地址与端口,默认端口是9200。可添加多个地址。
- index:写入elasticsearch的索引的名称,这里可以使用变量。Logstash提供了%{+YYYY.MM.dd}这种写法。在语法解析的时候,看到以+ 号开头的,就会自动认为后面是时间格式,尝试用时间格式来解析后续字符串。这种以天为单位分割的写法,可以很容易的删除老的数据或者搜索指定时间范围内的数据。此外,注意索引名中不能有大写字母。
- manage_template:用来设置是否开启logstash自动管理模板功能,如果设置为false将关闭自动管理模板功能。如果我们自定义了模板,那么应该设置为false。
- template_name:这个配置项用来设置在Elasticsearch中模板的名称。
3.3 stdout 输出到标准输出
output {
stdout {
codec => rubydebug
}
}四、Logstash 本身配置说明
包括:logstash.yaml、pipelines.yml、jvm.options、log4j2.properties、startup.options
1、logstash.yml 核心配置
Logstash配置选项可以控制Logstash的执行。如:指定管道设置、配置文件位置、日志记录选项等。运行Logstash时,大多数配置可以命令行中指定,并覆盖文件的相关配置。
node.name: `hostname`
path.data: LOGSTASH_HOME/data
path.logs: LOGSTASH_HOME/logs
# 指定main pipeline的配置文件路径
path.config:
# 指定main pipeline的配置数据。语法同配置文件
config.string:
# 开启后,检查配置是否有效,然后退出
config.test_and_exit: false
# 开启后,修改配置文件自动加载,过程:暂停管道所有输入;创新新管道并检验配置;检查成功切换到新管道,失败则继续使用老的管道。
config.reload.automatic: false
# 检查配置文件更新的时间间隔
config.reload.interval: 3s
# 内部队列模型,memory(default):内存,persisted:磁盘
queue.type: memory
# 持久队列的数据文件存储路径(queue.type: persisted时启用)
path.queue: path.data/queue
# 持久队列的页容量,持久化以页为单位
queue.page_capacity: 64mb
# 开启后,关闭logstash之前等待持久队列消耗完毕
queue.drain: false
# 队列中允许的最大事件数,默认0表示无限制
queue.max_events: 0
# 事件缓冲的内部队列的总容量,达到限制时Logstash将不再接受新事件
queue.max_bytes: 1024mb
# 强制执行检查点之前的最大ACKed事件数
queue.checkpoint.acks: 1024
# 强制执行检查点之前,可以写入磁盘的最大事件数
queue.checkpoint.writes: 1024
# 对每次检查点写入失败将重试一次
queue.checkpoint.retry: false
# metrics REST endpoint绑定的地址和端口
http.host: "127.0.0.1"
http.port: 9600
# 工作线程ID
pipeline.id: main
# 控制事件排序,auto:如果`pipeline.workers: 1`开启排序。true:如果有多个工作线程,强制对管道进行排序,并防止Logstash启动。false:禁用排序所需的处理,节省处理成本。
pipeline.ordered: auto
# 管道筛选和输出阶段的工作线程数,CPU没有饱和可以增加此数字更好的利用机器处理能力。
pipeline.workers: `number of cpu cores`
# 单个工作线程在发送到filters+workers之前,从输入中获取的最大事件数
pipeline.batch.size: 125
# 将小批量事件派送到filters+outputs之前,轮询下一个事件等待毫秒时间,可以理解为未到达批处理最大事件数时延迟发送时间
pipeline.batch.delay: 50
# 开启后,每个pipeline分割为不同的日志,使用pipeline.id作为文件名
pipeline.separate_logs: false
# 开启后,强行退出可能会导致关机期间丢失数据
pipeline.unsafe_shutdown: false
# 启用死信队列,默认false
dead_letter_queue.enable: false
dead_letter_queue.max_bytes: 1024mb
path.dead_letter_queue: path.data/dead_letter_queue
# 指定自定义插件的位置
path.plugins:
# 配置模块,遵循yaml结构
modules:2、高级配置
1. 多管道配置(multiple pipelines configuration)
如果需要在同一个进程中运行多个管道,通过配置pipelines.yml文件来处理,必须放在path.settings文件夹中。并遵循以下结构:
# config/pipelines.yml
- pipeline.id: my-pipeline_1
path.config: "/etc/path/to/p1.config"
pipeline.workers: 3
- pipeline.id: my-other-pipeline
path.config: "/etc/different/path/p2.cfg"
queue.type: persisted不带任何参数启动Logstash时,将读取pipelines.yml文件并实例化该文件中指定的所有管道。如果使用-e或-f时,Logstash会忽略pipelines.yml文件并记录相关警告。
- 如果当前的配置中的事件流不共享相同的输入/过滤器和输出,并且使用标签和条件相互分隔,则使用多个管道特别有用。
- 在单个实例中具有多个管道还可以使这些事件流具有不同的性能和持久性参数(例如,工作线程数和持久队列的不同设置)。
2. 管道到管道的通信(pipeline-to-pipeline Communication)
使用Logstash的多管道功能时,可以在同一Logstash实例中连接多个管道。此配置对于隔离这些管道的执行以及有助于打破复杂管道的逻辑很有用。
3. 重新加载配置文件(Reloading the Config File)
如果没有开启自动重新加载(--config.reload.automatic),可以强制Logstash重新加载配置文件并重新启动管道。
kill -SIGHUP 141754. 管理多行事件(Managing Multiline Events)
5. Glob模式支持(glob pattern support)
注意Logstash不会按照glob表达式中编写的文件顺序执行,是按照字母顺序对其进行排序执行的。
6. Logstash到Logstash通讯(Logstash-to-Logstash Communication)
7. Ingest Node解析数据转换到Logstash解析数据(Converting Ingest Node Pipelines)
8. 集中配置管理(Centralized Pipeline Management)
五、Logstash 命令说明
命令行上设置的所有参数都会覆盖logstash.yml中的相应设置。生产环境建议使用logstash.yml控制Logstash执行。
参数:
- --node.name NAME:指定Logstash实例的名称,默认当前主机名
- -f, --path.config CONFIG_PATH:加载Logstash配置的文件或目录
- -e, --config.string CONFIG_STRING:Logstash配置数据,如果未指定输入,则使用input { stdin { type => stdin } }作为默认的输入,如果未指定输出,则使用output { stdout { codec => rubydebug } }作为默认的输出。
- -M "CONFIG_SETTING=VALUE":覆盖指定的配置
- --config.test_and_exit: 检查配置是否有效,然后退出
- --config.reload.automatic: 修改配置文件自动加载
- --modules MODULE_NAME:指定运行的模块名称
- --setup:是一次性设置步骤,在Elasticsearch中创建索引模式并导入Kibana仪表板和可视化文件。
- ...
启动示例:可以同时驱动多个 配置不同的配置文件即可
bin/logstash -f logstash-simple.conf --config.reload.automatic参考文献:
logstash三大插件 、 Logstash 配置、Logstash-配置 、logstash filter 过滤器详解