Linux ---- Shell编程三剑客之AWK
一、awk处理文本工具
1、awk概述
- awk 是一种处理文本文件的语言,是一个强大的文本分析工具。
- AWK是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描、过滤、统计汇总工作。用来处理列。
- 数据可以来自标准输入也可以是管道或文件。
- 读取一行处理一行,
2、awk工具
- 功能强大的编辑工具
- 无交互情况下实现复杂的文本操作
命令格式
awk 选项 '模式或条件 {处理动作}' 文件 1 文件 2 …
awk -f 脚本文件 文件 1 文件 2 …
program分为两部分
①处理动作 {print {print}},,print可以写多个,可以嵌套
②正则表达式常用选项
-F 指定分隔符,指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符
-v var=value 自定义变量
-F 和 -FS 不要一起使用, -F的优先级高二、工作原理
- 当读到第一行时,匹配条件,然后执行指定动作,再接着读取第二行数据处理,不会默认输出
- 如果没有定义匹配条件默认是匹配所有数据行,awk隐含循环,条件匹配多少次动作就会执行多少次
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
- sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个""字段"然后再进行处理。
- awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。
- 在使用awk命令的过程中,可以使用逻辑操作符"
- &&“表示"与”、“||表示"或”、"!“表示非”;还可以进行简单的数学运算,如+、一、*、/、%、^分别表示加、减、乘、除、取余和乘方。
三、基础用法
1、print动作
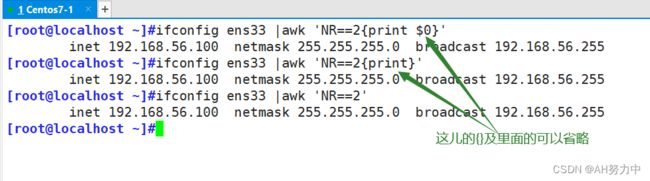
ifconfig ens33 |awk '{print}' ##打印ens33网卡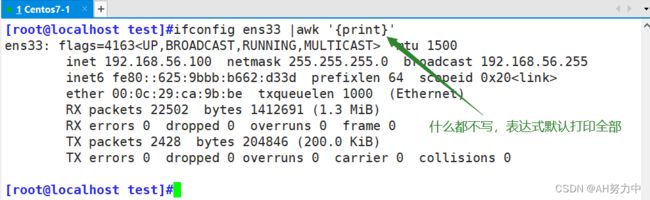
ifconfig ens33 |awk '/netmask/{print}' ##查找包含netmask的行

awk '{print "hello"}'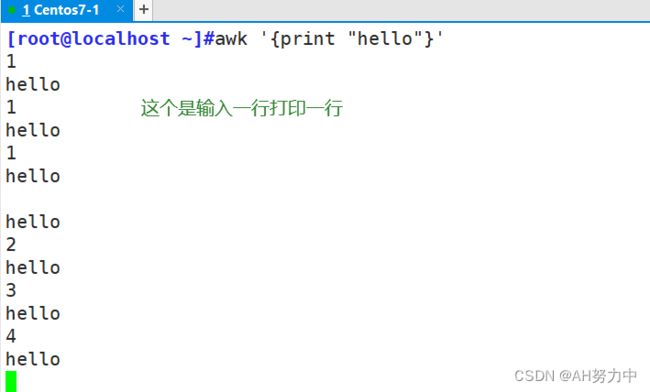
你有多少行文件就打印多少行hello

awk 'BEGIN{print 100+200}' ##直接打印出结果
200
awk '{print 100+200}' ###有几行打印几次结果
awk 'BEGIN{print 100*200}' ##也可以相乘
20000
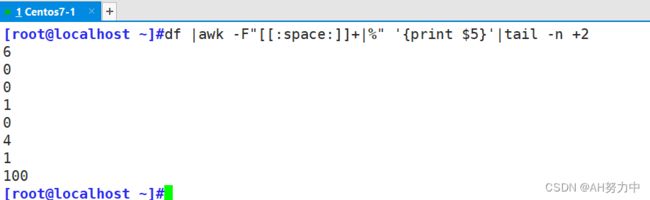
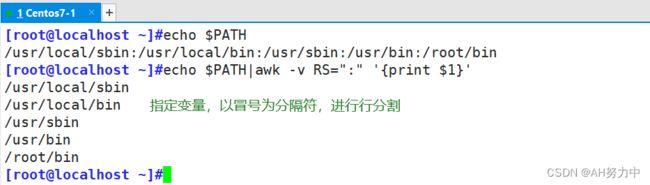
用awk提取磁盘 "已用" 列
+号代表空格有多个

打印passwd文件的第一列和第三列

以冒号为分隔符

也可以改为其他分隔符
++++
tab分隔符"\t"
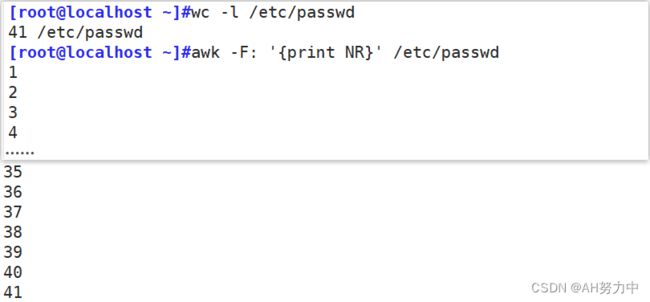
[root@localhost ~]#wc -l /etc/passwd
45 /etc/passwd
[root@localhost ~]#awk -F: '{print $0}' /etc/passwd #$0代表全部元素
[root@localhost ~]#awk -F: '{print $1}' /etc/passwd #代表第一列
[root@localhost ~]#awk -F: '{print $1,$3}' /etc/passwd #代表第一第三列
[root@localhost ky15]#awk '/^root/{print}' passwd #已root为开头的行
[root@localhost ky15]#grep -c "/bin/bash$" passwd #统计当前已/bin/bash结尾的行
22、awk常见的内置变量
awk 选项 '模式{print }’
选项
-v:定义变量 awk中的变量,,不会影响bash
-F:指定分隔符
FS :指定每行文本的字段分隔符,缺省默认为空格或制表符(tab)。与 “-F”作用相同 -v "FS=:"
OFS:输出时的分隔符
NF:当前处理的行的字段个数 *****
NR:当前处理的行的行号(序数) *****
$0:当前处理的行的整行内容
$n:当前处理行的第n个字段(第n列)
FILENAME:被处理的文件名
RS:行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是\n1.FS :指定每行文本的字段分隔符,缺省默认为空格或制表符(tab)。与 “-F”作用相同 -v "FS=:"
-F -FS 一起使用时,-F的优先级高


打印passwd文件的第一列和第三列


fs

OFS:输出时的分隔符

RS:行分隔符
NF: 代表字段个数 *****




打印倒数第二例


NR:显示行号 *****



ifconfig ens33 |awk 'NR ==1,NR==3{print}' ##打印1到三行
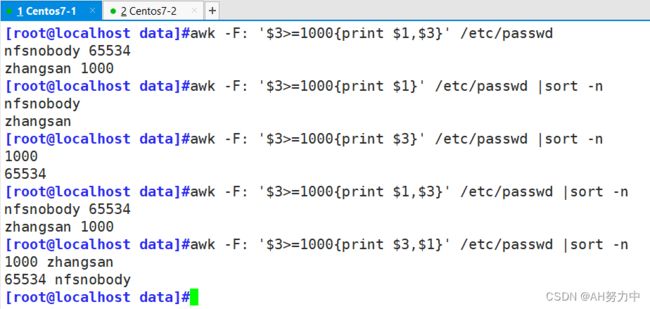
awk -F: '$3>=1000{print $1,$3}' /etc/passwd


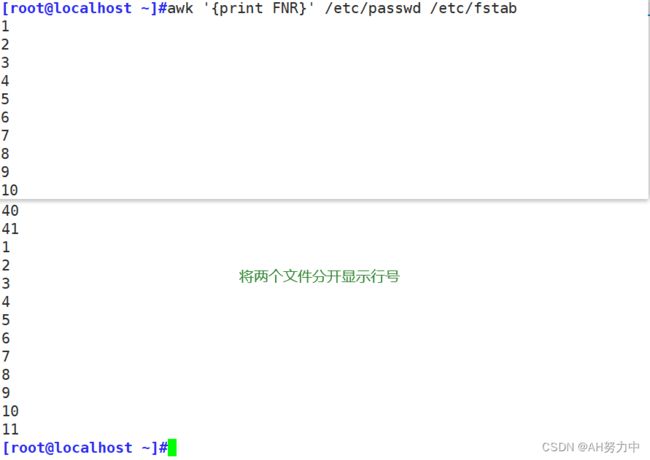
FNR:读取文件的记录行号(从1开始,若读取新的文件依旧是从1开始)
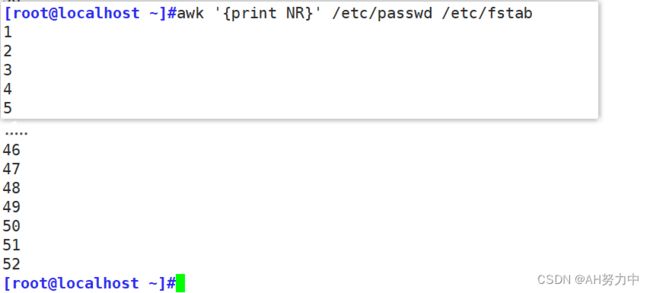
这样他将两个文件的行数并在一起算,passwd一共41行,其他的是fstab的行数
3、自定义变量
printf
- %s:显示字符串
- %d, %i:显示十进制整数
- %f:显示为浮点数
- %e, %E:显示科学计数法数值
- %c:显示字符的ASCII码
- %g, %G:以科学计数法或浮点形式显示数值
- %u:无符号整数
- %%:显示%自身
awk -F: '{printf "%s",$1}' /etc/passwd
awk -F: '{printf "%s\n",$1}' /etc/passwd
awk -F: '{printf "%20s\n",$1}' /etc/passwd
awk -F: '{printf "%-20s\n",$1}' /etc/passwd
awk -F: '{printf "%-20s %10d\n",$1,$3}' /etc/passwd
awk -F: '{printf "Username: %s\n",$1}' /etc/passwd
awk -F: '{printf “Username: %sUID:%d\n",$1,$3}' /etc/passwd
awk -F: '{printf "Username: %25sUID:%d\n",$1,$3}' /etc/passwd
awk -F: '{printf "Username: %-25sUID:%d\n",$1,$3}' /etc/passwd
4、模式pattern
awk '模式{处理动作}'
PATTERN:根据pattern条件,过滤匹配的行,再做处理
1.模式为空
如果模式为空表示每一行都匹配成功,相当于没有额外条件
awk -F: '{print $1,$3}' /etc/passwd
2.正则匹配
/regular expression/:仅处理能够模式匹配到的行,需要用/ /括起来
awk '/^UUID/{print $1}' /etc/fstab
3.line ranges:行范围
- 不支持使用行号,但是可以使用变量NR 间接指定行号加上比较操作符 或者逻辑关系
[root@centos7 ~]#awk 'NR==3{print $1}' /etc/passwd
[root@centos7 ~]#seq 10 | awk 'NR>=3 && NR<=6'
[root@centos7 ~]#awk 'NR>=3 && NR<=6{print NR,$0}' /etc/passwd
[root@centos7 ~]#awk '/^bin/,/^adm/' /etc/passwd
#bin开头 到adm开头
[root@localhost ky15]#awk '{print $1,NR}' /etc/passwd
##行号
[root@localhost ky15]#awk 'NR==2{print $1}' /etc/passwd
#只取第二行的第一个字段
[root@localhost ky15]#awk 'NR==1,NR==3{print}' passwd
#打印出1到3 行
[root@localhost ky15]#awk 'NR==1||NR==3{print}' passwd
#打印出1和3行
[root@localhost ky15]#awk '(NR%2)==0{print NR}' passwd
#打印出函数取余数为0行
[root@localhost ky15]#awk '(NR%2)==1{print NR}' passwd
#打印出函数取余数为1的行
[root@localhost ky15]#awk 'NR>=3 && NR<=6{print NR,$0}' /etc/passwd
[root@localhost ky15]#seq 10|awk 'NR>5 && NR<10'
#取 行间
6
7
8
9
[root@localhost ky15]#awk '$3>1000{print}' /etc/passwd
#注意分隔符
#打印出普通用户 第三列 大于1000 的行算术操作符
x+y, x-y, x*y, x/y, x^y, x%y
-x:转换为负数
+x:将字符串转换为数值
比较操作符:
==, !=, >, >=, <, <=
#####逻辑
与:&&,并且关系
或:||,或者关系
非:!,取反
举例:/pat1/,/pat2/ 面试题 找到10:00 到 11:00 之间的日志
awk '/10/,/11/' 文件名
sed -nr '/10/,/11/p' 文件名4.BEGIN 和END
- 第一步:执行BEGIN{action;… }语句块中的语句
- 第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ action;… }语句块,它逐行扫描文件,
- 从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
- 第三步:当读至输入流末尾时,执行END{action;…}语句块
- BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中
- END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块
- pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块

BEGIN:在打印所有命令之前先打印 -----

END:在打印所有命令之后再打印 -----

5.关系表达式
- 非0为真,0为假


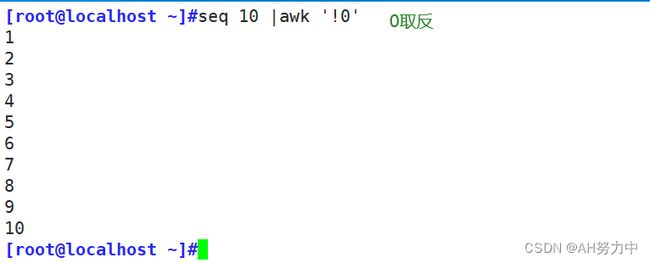
关系表达式打印奇数行
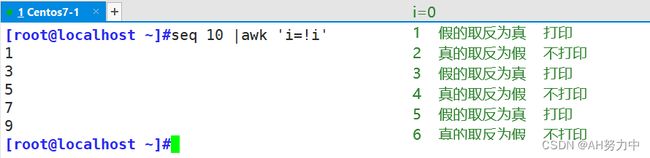
关系表达式打印偶数行

6.条件判断
if(condition){statement;…}[else statement]
if(condition1){statement1}else if(condition2){statement2}else if(condition3){statement3}...... else {statementN}
condition1:条件
statement1:语句
if语句:awk的if语句也分为单分支、双分支和多分支
单分支为if(判断条件){执行语句}
双分支为if(判断条件){执行语句}else{执行语句}
多分支为if(判断条件){执行语句}else if(判断条件){执行语句}else if(判断条件){执行语句}else if(判断条件){执行语句 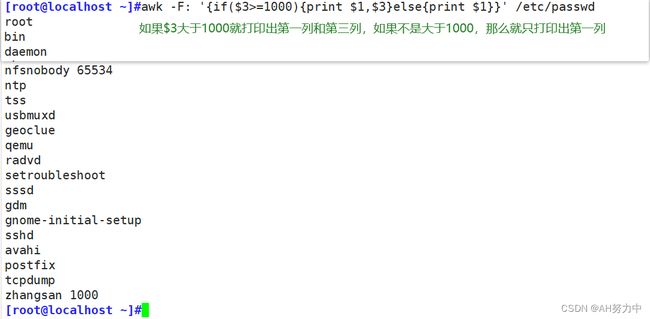
5、for | while
for(expr1;expr2;expr3) {statement;…}
for(variable assignment;condition;iteration process) {for-body}
for(var in array) {for-body}
awk 'BEGIN{sum=0;for(i=1;i<=100;i++){sum+=i};print sum}'
5050
for((i=1,sum=0;i<=100;i++));do let sum=i+sum;done;echo $sum
5050
6、数组
awk数组特性:
awk的数组是关联数组(即key/value方式的hash数据结构),索引下标可为数值(甚至是负数、小数等),也可为字符串 1. 在内部,awk数组的索引全都是字符串,即使是数值索引在使用时内部也会转换成字符串 2. awk的数组元素的顺序和元素插入时的顺序很可能是不相同的
awk数组支持数组的数组
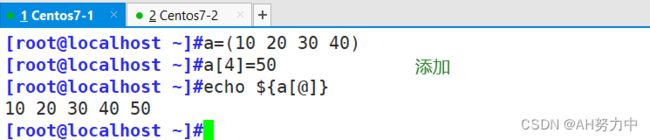
1.访问、赋值数组元素
arr[idx]
arr[idx] = value索引可以是整数、负数、0、小数、字符串。如果是数值索引,会按照CONVFMT变量指定的格式先转换成字符串

2.遍历数组

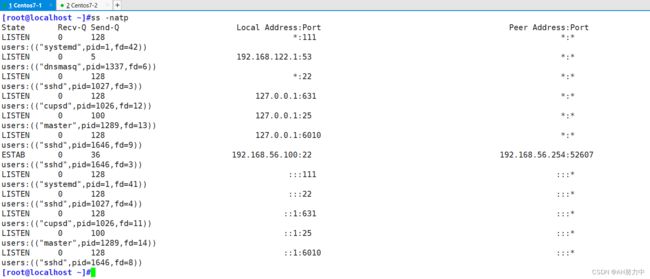
统计LISTEN变量出现多少次

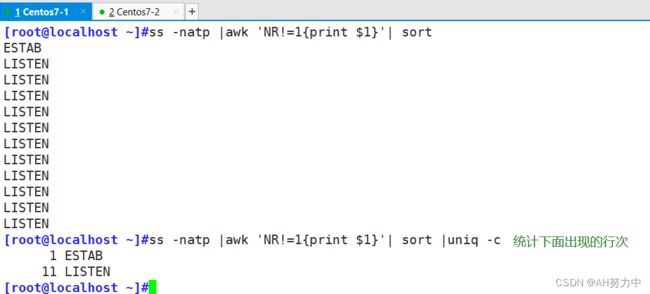

扩展一个


3。模糊匹配

7、awk脚本
[root@centos7 ~]#cat test.awk
#!/bin/awk -f 声明解释器
#this is a awk script
{if($3>=1000)print $1,$3}
[root@centos8 ~]#chmod +x test.awk
[root@centos8 ~]#./test.awk -F: /etc/passwd
nobody 65534
zhangsan 1000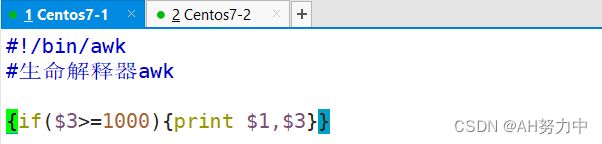

练习:
提取下面的字段中的 IP地址和时间
vim test
58.87.87.99 - - [09/Jun/2020:03:42:43 +0800] "POST /wp-cron.php?doing_wp_cron=1591645363.2316548824310302734375 HTTP/1.1" ""sendfileon
128.14.209.154 - - [09/Jun/2020:03:42:43 +0800] "GET / HTTP/1.1" ""sendfileon
64.90.40.100 - - [09/Jun/2020:03:43:11 +0800] "GET /wp-login.php HTTP/1.1"""sendfileo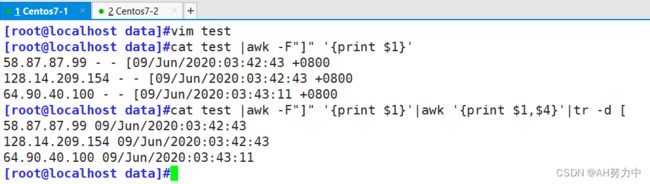

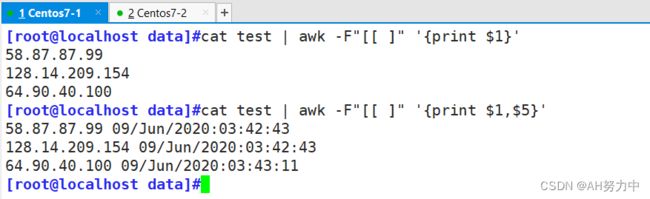
提取地址

host.txt主机名后再放回host.txt文件
vim host.txt
www.kgc.com
mail.kgc.com
ftp.kgc.com
linux.kgc.com
blog.kgc.com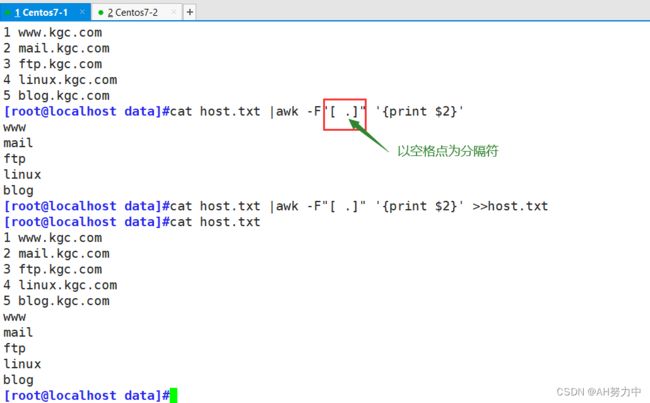


统计/etc/fstab文件中每个文件系统类型出现的次数

统计/etc/fstab文件中每个真单词出现的次数

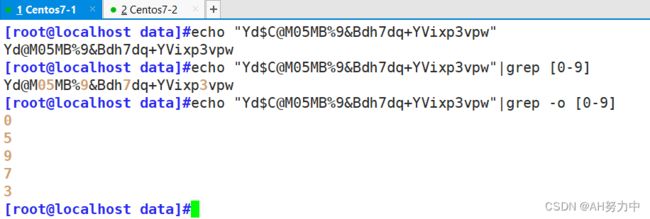
提取出字符串Yd$C@M05MB%9&Bdh7dq+YVixp3vpw中的所有数字
查出/tmp/的权限,以数字方式显示

查出用户UID最大值的用户名、UID及shell类型