- 情绪觉察日记第37天
露露_e800
今天是家庭关系规划师的第二阶最后一天,慧萍老师帮我做了个案,帮我处理了埋在心底好多年的一份恐惧,并给了我深深的力量!这几天出来学习,爸妈过来婆家帮我带小孩,妈妈出于爱帮我收拾东西,并跟我先生和婆婆产生矛盾,妈妈觉得他们没有照顾好我…。今晚回家见到妈妈,我很欣赏她并赞扬她,妈妈说今晚要跟我睡我说好,当我们俩躺在床上准备睡觉的时候,我握着妈妈的手对她说:妈妈这几天辛苦你了,你看你多利害把我们的家收拾得
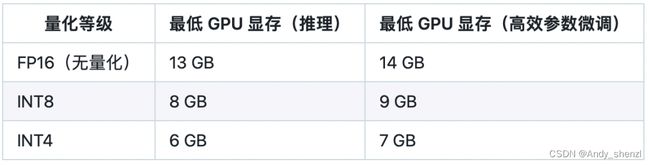
- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 铭刻于星(四十二)
随风至
69夜晚,绍敏同学做完功课后,看了眼房外,没听到动静才敢从书包的夹层里拿出那个心形纸团。折痕压得很深,都有些旧了,想来是已经写好很久了。绍敏同学慢慢地、轻轻地捏开折叠处,待到全部拆开后,又反复抚平纸张,然后仔细地一字字默看。只是开头的三个字是第一次看到,让她心漏跳了几拍。“亲爱的绍敏:从四年级的时候,我就喜欢你了,但是我一直不敢说,怕影响你学习。六年级的时候听说有人跟你表白,你接受了,我很难过,但
- OC语言多界面传值五大方式
Magnetic_h
iosui学习objective-c开发语言
前言在完成暑假仿写项目时,遇到了许多需要用到多界面传值的地方,这篇博客来总结一下比较常用的五种多界面传值的方式。属性传值属性传值一般用前一个界面向后一个界面传值,简单地说就是通过访问后一个视图控制器的属性来为它赋值,通过这个属性来做到从前一个界面向后一个界面传值。首先在后一个界面中定义属性@interfaceBViewController:UIViewController@propertyNSSt
- UI学习——cell的复用和自定义cell
Magnetic_h
ui学习
目录cell的复用手动(非注册)自动(注册)自定义cellcell的复用在iOS开发中,单元格复用是一种提高表格(UITableView)和集合视图(UICollectionView)滚动性能的技术。当一个UITableViewCell或UICollectionViewCell首次需要显示时,如果没有可复用的单元格,则视图会创建一个新的单元格。一旦这个单元格滚动出屏幕,它就不会被销毁。相反,它被添
- 学点心理知识,呵护孩子健康
静候花开_7090
昨天听了华中师范大学教育管理学系副教授张玲老师的《哪里才是学生心理健康的最后庇护所,超越教育与技术的思考》的讲座。今天又重新学习了一遍,收获匪浅。张玲博士也注意到了当今社会上的孩子由于心理问题导致的自残、自杀及伤害他人等恶性事件。她向我们普及了一个重要的命题,她说心理健康的一些基本命题,我们与我们通常的一些教育命题是不同的,她还举了几个例子,让我们明白我们原来以为的健康并非心理学上的健康。比如如果
- Cell Insight | 单细胞测序技术又一新发现,可用于HIV-1和Mtb共感染个体诊断
尐尐呅
结核病是艾滋病合并其他疾病中导致患者死亡的主要原因。其中结核病由结核分枝杆菌(Mycobacteriumtuberculosis,Mtb)感染引起,获得性免疫缺陷综合症(艾滋病)由人免疫缺陷病毒(Humanimmunodeficiencyvirustype1,HIV-1)感染引起。国家感染性疾病临床医学研究中心/深圳市第三人民医院张国良团队携手深圳华大生命科学研究院吴靓团队,共同研究得出单细胞测序
- 《策划经理回忆录之二》
路基雅虎
话说三年变六年,飘了,飘了……眨眼,2013年5月,老吴回到了他的家乡——油城从新开启他的工作幻想症生涯。很庆幸,这是一家很有追求,同时敢于尝试的,且实力不容低调的新星房企——金源置业(前身泰源置业)更值得庆幸的是第一个盘就是油城十路的标杆之一:金源盛世。2013年5月,到2015年11月,两年的陪伴,迎来了一场大爆发。2000个筹,5万/筹,直接回笼1个亿!!!这……让我开始认真审视这座看似五线
- 2021-08-26
影幽
在生活中,女人与男人的感悟往往有所不同。人生最大的舞台就是生活,大幕随时都可能拉开,关键是你愿不愿意表演都无法躲避。在生活中,遇事不要急躁,不要急于下结论,尤其生气时不要做决断,要学会换位思考,大事化小小事化了,把复杂的事情尽量简单处理,千万不要把简单的事情复杂化。永远不要扭曲,别人善意,无药可救。昨天是张过期的支票,明天是张信用卡,只有今天才是现金,要善加利用!执着的攀登者不必去与别人比较自己的
- 消息中间件有哪些常见类型
xmh-sxh-1314
java
消息中间件根据其设计理念和用途,可以大致分为以下几种常见类型:点对点消息队列(Point-to-PointMessagingQueues):在这种模型中,消息被发送到特定的队列中,消费者从队列中取出并处理消息。队列中的消息只能被一个消费者消费,消费后即被删除。常见的实现包括IBM的MQSeries、RabbitMQ的部分使用场景等。适用于任务分发、负载均衡等场景。发布/订阅消息模型(Pub/Sub
- ArcGIS栅格计算器常见公式(赋值、0和空值的转换、补充栅格空值)
研学随笔
arcgis经验分享
我们在使用ArcGIS时通常经常用到栅格计算器,今天主要给大家介绍我日常中经常用到的几个公式,供大家参考学习。将特定值(-9999)赋值为0,例如-9999.Con("raster"==-9999,0,"raster")2.给空值赋予特定的值(如0)Con(IsNull("raster"),0,"raster")3.将特定的栅格值(如1)赋值为空值,其他保留原值SetNull("raster"==
- 三大师传
beca酱
巴尔扎克的作品被誉为“法国社会的一面镜子”。文学大师维克多·雨果对巴尔扎克的评价是:“在最伟大的人物中间,巴尔扎克是名列前茅者;在最优秀的人物中间,巴尔扎克是佼佼者之一。”一个原本寂寂无名的小人物,从地中海的某个海岛上,只身一人来到巴黎,没有朋友,也没有名望。作为一个一文不名的外乡人,凭着赤手空拳赢得了巴黎,征服了整个法兰西,并且赢得了世界。这个人就是十九世纪法国伟大的军事家、政治家,法兰西第一帝
- 我的烦恼
余建梅
我的烦恼。女儿问我:“你给学生布置什么作文题目?”“《我的烦恼》。”“他们都这么大了,你觉得他们还有烦恼吗?”“有啊!每个人都会有自己烦恼。”“我不相信,大人是没有烦恼的,如果说一定有的话,你的烦恼和我写作业有关,而且是小烦恼。不像我,天天被你说,有这样的妈妈,烦恼是没完没了。”女儿愤愤不平。每个人都会有自己的烦恼,处在上有老下有小的年纪,烦恼多的数不完。想干好工作带好孩子,想孝顺父母又想经营好自
- 《大清方方案》| 第二话
谁佐清欢
和珅究竟说了些什么?竟能令堂堂九五之尊龙颜失色!此处暂且按下不表;单说这位乾隆皇帝,果真不愧是康熙从小带过的,一旦决定了要做的事,便杀伐决断毫不含糊。他当即亲自拟旨,着令和珅为钦差大臣,全权负责处理方方事件,并钦赐尚方宝剑,遇急则三品以下官员可先斩后奏。和珅身负皇上重托,岂敢有半点怠慢,当夜即率领相关人等,马不停蹄杀奔江汉。这一路上,和珅的几位幕僚一直在商讨方方事件的处置方案。有位年轻幕僚建议快刀
- 【一起学Rust | 设计模式】习惯语法——使用借用类型作为参数、格式化拼接字符串、构造函数
广龙宇
一起学Rust#Rust设计模式rust设计模式开发语言
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言一、使用借用类型作为参数二、格式化拼接字符串三、使用构造函数总结前言Rust不是传统的面向对象编程语言,它的所有特性,使其独一无二。因此,学习特定于Rust的设计模式是必要的。本系列文章为作者学习《Rust设计模式》的学习笔记以及自己的见解。因此,本系列文章的结构也与此书的结构相同(后续可能会调成结构),基本上分为三个部分
- 回溯 Leetcode 332 重新安排行程
mmaerd
Leetcode刷题学习记录leetcode算法职场和发展
重新安排行程Leetcode332学习记录自代码随想录给你一份航线列表tickets,其中tickets[i]=[fromi,toi]表示飞机出发和降落的机场地点。请你对该行程进行重新规划排序。所有这些机票都属于一个从JFK(肯尼迪国际机场)出发的先生,所以该行程必须从JFK开始。如果存在多种有效的行程,请你按字典排序返回最小的行程组合。例如,行程[“JFK”,“LGA”]与[“JFK”,“LGB
- Python数据分析与可视化实战指南
William数据分析
pythonpython数据
在数据驱动的时代,Python因其简洁的语法、强大的库生态系统以及活跃的社区,成为了数据分析与可视化的首选语言。本文将通过一个详细的案例,带领大家学习如何使用Python进行数据分析,并通过可视化来直观呈现分析结果。一、环境准备1.1安装必要库在开始数据分析和可视化之前,我们需要安装一些常用的库。主要包括pandas、numpy、matplotlib和seaborn等。这些库分别用于数据处理、数学
- 每日一题——第八十四题
互联网打工人no1
C语言程序设计每日一练c语言
题目:编写函数1、输入10个职工的姓名和职工号2、按照职工由大到小顺序排列,姓名顺序也随之调整3、要求输入一个职工号,用折半查找法找出该职工的姓名#define_CRT_SECURE_NO_WARNINGS#include#include#defineMAX_EMPLOYEES10typedefstruct{intid;charname[50];}Empolyee;voidinputEmploye
- 2019-12-22-22:30
涓涓1016
今天是冬至,写下我的日更,是因为这两天的学习真的是能量的满满,让我看到了自己,未来另外一种可能性,也让我看到了这两年这几年的过程中我所接受那些痛苦的来源。一切的根源和痛苦都来自于人生,家庭,而你的原生家庭,你的爸爸和妈妈,是因为你这个灵魂在那一刻选择他们作为你的爸爸和妈妈来的,所以你得接受他,你得接纳他,他就是因为他的存在而给你的学习和成长带来这些痛苦,那其实是你必然要经历的这个过程,当你去接纳的
- 谁家酒器最绝唱,藏在酒厂人未知?景阳冈酒厂先秦藏品大揭秘
李虓酒评论
文/王赛时中国的酒器酒具历史久远,举世闻名。从北京的故宫博物院、中国国家博物馆,到世界各国的大型博物馆,都以能够收藏中国古代酒具而夸耀。但很少有人知道,在山东阳谷景阳冈酒厂,默默地收藏了两千件中国酒器。这些酒器,就封藏在景阳冈的酒道馆里。其中有一些青铜酒器,一睡就是三、四千年,堪称无声国宝,堪作无字史书!今天,我将引领诸位首先窥视一下景阳冈酒道馆的9件先秦藏品,你自己来说震撼不震撼。提示:这只是景
- LLM 词汇表
落难Coder
LLMsNLP大语言模型大模型llama人工智能
Contextwindow“上下文窗口”是指语言模型在生成新文本时能够回溯和参考的文本量。这不同于语言模型训练时所使用的大量数据集,而是代表了模型的“工作记忆”。较大的上下文窗口可以让模型理解和响应更复杂和更长的提示,而较小的上下文窗口可能会限制模型处理较长提示或在长时间对话中保持连贯性的能力。Fine-tuning微调是使用额外的数据进一步训练预训练语言模型的过程。这使得模型开始表示和模仿微调数
- 将cmd中命令输出保存为txt文本文件
落难Coder
Windowscmdwindow
最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再
- 四章-32-点要素的聚合
彩云飘过
本文基于腾讯课堂老胡的课《跟我学Openlayers--基础实例详解》做的学习笔记,使用的openlayers5.3.xapi。源码见1032.html,对应的官网示例https://openlayers.org/en/latest/examples/cluster.htmlhttps://openlayers.org/en/latest/examples/earthquake-clusters.
- 如果做到轻松在股市赚钱?只要坚持这三个原则。
履霜之人
大A股里向来就有七亏二平一赚的说法,能赚钱的都是少数人。否则股市就成了慈善机构,人人都有钱赚,谁还要上班?所以说亏钱是正常的,或者说是应该的。那么那些赚钱的人又是如何做到的呢?普通人能不能找到捷径去分一杯羹呢?方法是有的,但要做到需要你有极高的自律。第一,控制仓位,散户最大的问题是追涨杀跌,只要涨起来,就把钱往股票上砸,然后被套,隔天跌的受不了,又一刀切,全部割肉。来来回回间,遍体鳞伤。所以散户首
- 特殊的拜年
飘雪的天堂
文/雪儿大年初一,家家户户没有了轰响的鞭炮声,大街上没有了人流涌动的喧闹,几乎看不到人影,变得冷冷清清。天刚亮不大会儿,村里的大喇叭响了起来:由于当前正值疾病高发期,流感流行的高峰期。同时,新型冠状病毒感染的肺炎进入第二波流行的上升期。为了自己和他人的健康安全着想,请大家尽量不要串门拜年,不要在街里走动。可以通过手机微信,视频,电话,信息拜年……今年的春节真是特别。禁止燃放鞭炮,烟花爆竹,禁止出村
- 2020-04-12每天三百字之连接与替代
冷眼看潮
不知道是不是好为人师,有时候还真想和别人分享一下我对某些现象的看法或者解释。人类社会不断发展进步的过程,就是不断连接与替代的过程。人类发现了火并应用火以后,告别了茹毛饮血的野兽般的原始生活(火烧、烹饪替代了生食)人类用石器代替了完全手工,工具的使用使人类进步一大步。类似这样的替代还有很多,随着科技的发展,有更多的原始的事物被替代,代之以更高效、更先进的技术。在近现代,汽车替代了马车,高速公路和铁路
- 探索OpenAI和LangChain的适配器集成:轻松切换模型提供商
nseejrukjhad
langchaineasyui前端python
#探索OpenAI和LangChain的适配器集成:轻松切换模型提供商##引言在人工智能和自然语言处理的世界中,OpenAI的模型提供了强大的能力。然而,随着技术的发展,许多人开始探索其他模型以满足特定需求。LangChain作为一个强大的工具,集成了多种模型提供商,通过提供适配器,简化了不同模型之间的转换。本篇文章将介绍如何使用LangChain的适配器与OpenAI集成,以便轻松切换模型提供商
- 使用Apify加载Twitter消息以进行微调的完整指南
nseejrukjhad
twittereasyui前端python
#使用Apify加载Twitter消息以进行微调的完整指南##引言在自然语言处理领域,微调模型以适应特定任务是提升模型性能的常见方法。本文将介绍如何使用Apify从Twitter导出聊天信息,以便进一步进行微调。##主要内容###使用Apify导出推文首先,我们需要从Twitter导出推文。Apify可以帮助我们做到这一点。通过Apify的强大功能,我们可以批量抓取和导出数据,适用于各类应用场景。
- 深入理解 MultiQueryRetriever:提升向量数据库检索效果的强大工具
nseejrukjhad
数据库python
深入理解MultiQueryRetriever:提升向量数据库检索效果的强大工具引言在人工智能和自然语言处理领域,高效准确的信息检索一直是一个关键挑战。传统的基于距离的向量数据库检索方法虽然广泛应用,但仍存在一些局限性。本文将介绍一种创新的解决方案:MultiQueryRetriever,它通过自动生成多个查询视角来增强检索效果,提高结果的相关性和多样性。MultiQueryRetriever的工
- 如何部分格式化提示模板:LangChain中的高级技巧
nseejrukjhad
langchainjava服务器python
标题:如何部分格式化提示模板:LangChain中的高级技巧内容:如何部分格式化提示模板:LangChain中的高级技巧引言在使用大型语言模型(LLM)时,提示工程是一个关键环节。LangChain提供了强大的提示模板功能,让我们能更灵活地构建和管理提示。本文将介绍LangChain中一个高级特性-部分格式化提示模板,这个技巧可以让你的提示管理更加高效和灵活。什么是部分格式化提示模板?部分格式化提
- 枚举的构造函数中抛出异常会怎样
bylijinnan
javaenum单例
首先从使用enum实现单例说起。
为什么要用enum来实现单例?
这篇文章(
http://javarevisited.blogspot.sg/2012/07/why-enum-singleton-are-better-in-java.html)阐述了三个理由:
1.enum单例简单、容易,只需几行代码:
public enum Singleton {
INSTANCE;
- CMake 教程
aigo
C++
转自:http://xiang.lf.blog.163.com/blog/static/127733322201481114456136/
CMake是一个跨平台的程序构建工具,比如起自己编写Makefile方便很多。
介绍:http://baike.baidu.com/view/1126160.htm
本文件不介绍CMake的基本语法,下面是篇不错的入门教程:
http:
- cvc-complex-type.2.3: Element 'beans' cannot have character
Cb123456
springWebgis
cvc-complex-type.2.3: Element 'beans' cannot have character
Line 33 in XML document from ServletContext resource [/WEB-INF/backend-servlet.xml] is i
- jquery实例:随页面滚动条滚动而自动加载内容
120153216
jquery
<script language="javascript">
$(function (){
var i = 4;$(window).bind("scroll", function (event){
//滚动条到网页头部的 高度,兼容ie,ff,chrome
var top = document.documentElement.s
- 将数据库中的数据转换成dbs文件
何必如此
sqldbs
旗正规则引擎通过数据库配置器(DataBuilder)来管理数据库,无论是Oracle,还是其他主流的数据都支持,操作方式是一样的。旗正规则引擎的数据库配置器是用于编辑数据库结构信息以及管理数据库表数据,并且可以执行SQL 语句,主要功能如下。
1)数据库生成表结构信息:
主要生成数据库配置文件(.conf文
- 在IBATIS中配置SQL语句的IN方式
357029540
ibatis
在使用IBATIS进行SQL语句配置查询时,我们一定会遇到通过IN查询的地方,在使用IN查询时我们可以有两种方式进行配置参数:String和List。具体使用方式如下:
1.String:定义一个String的参数userIds,把这个参数传入IBATIS的sql配置文件,sql语句就可以这样写:
<select id="getForms" param
- Spring3 MVC 笔记(一)
7454103
springmvcbeanRESTJSF
自从 MVC 这个概念提出来之后 struts1.X struts2.X jsf 。。。。。
这个view 层的技术一个接一个! 都用过!不敢说哪个绝对的强悍!
要看业务,和整体的设计!
最近公司要求开发个新系统!
- Timer与Spring Quartz 定时执行程序
darkranger
springbean工作quartz
有时候需要定时触发某一项任务。其实在jdk1.3,java sdk就通过java.util.Timer提供相应的功能。一个简单的例子说明如何使用,很简单: 1、第一步,我们需要建立一项任务,我们的任务需要继承java.util.TimerTask package com.test; import java.text.SimpleDateFormat; import java.util.Date;
- 大端小端转换,le32_to_cpu 和cpu_to_le32
aijuans
C语言相关
大端小端转换,le32_to_cpu 和cpu_to_le32 字节序
http://oss.org.cn/kernel-book/ldd3/ch11s04.html
小心不要假设字节序. PC 存储多字节值是低字节为先(小端为先, 因此是小端), 一些高级的平台以另一种方式(大端)
- Nginx负载均衡配置实例详解
avords
[导读] 负载均衡是我们大流量网站要做的一个东西,下面我来给大家介绍在Nginx服务器上进行负载均衡配置方法,希望对有需要的同学有所帮助哦。负载均衡先来简单了解一下什么是负载均衡,单从字面上的意思来理解就可以解 负载均衡是我们大流量网站要做的一个东西,下面我来给大家介绍在Nginx服务器上进行负载均衡配置方法,希望对有需要的同学有所帮助哦。
负载均衡
先来简单了解一下什么是负载均衡
- 乱说的
houxinyou
框架敏捷开发软件测试
从很久以前,大家就研究框架,开发方法,软件工程,好多!反正我是搞不明白!
这两天看好多人研究敏捷模型,瀑布模型!也没太搞明白.
不过感觉和程序开发语言差不多,
瀑布就是顺序,敏捷就是循环.
瀑布就是需求、分析、设计、编码、测试一步一步走下来。而敏捷就是按摸块或者说迭代做个循环,第个循环中也一样是需求、分析、设计、编码、测试一步一步走下来。
也可以把软件开发理
- 欣赏的价值——一个小故事
bijian1013
有效辅导欣赏欣赏的价值
第一次参加家长会,幼儿园的老师说:"您的儿子有多动症,在板凳上连三分钟都坐不了,你最好带他去医院看一看。" 回家的路上,儿子问她老师都说了些什么,她鼻子一酸,差点流下泪来。因为全班30位小朋友,惟有他表现最差;惟有对他,老师表现出不屑,然而她还在告诉她的儿子:"老师表扬你了,说宝宝原来在板凳上坐不了一分钟,现在能坐三分钟。其他妈妈都非常羡慕妈妈,因为全班只有宝宝
- 包冲突问题的解决方法
bingyingao
eclipsemavenexclusions包冲突
包冲突是开发过程中很常见的问题:
其表现有:
1.明明在eclipse中能够索引到某个类,运行时却报出找不到类。
2.明明在eclipse中能够索引到某个类的方法,运行时却报出找不到方法。
3.类及方法都有,以正确编译成了.class文件,在本机跑的好好的,发到测试或者正式环境就
抛如下异常:
java.lang.NoClassDefFoundError: Could not in
- 【Spark七十五】Spark Streaming整合Flume-NG三之接入log4j
bit1129
Stream
先来一段废话:
实际工作中,业务系统的日志基本上是使用Log4j写入到日志文件中的,问题的关键之处在于业务日志的格式混乱,这给对日志文件中的日志进行统计分析带来了极大的困难,或者说,基本上无法进行分析,每个人写日志的习惯不同,导致日志行的格式五花八门,最后只能通过grep来查找特定的关键词缩小范围,但是在集群环境下,每个机器去grep一遍,分析一遍,这个效率如何可想之二,大好光阴都浪费在这上面了
- sudoku solver in Haskell
bookjovi
sudokuhaskell
这几天没太多的事做,想着用函数式语言来写点实用的程序,像fib和prime之类的就不想提了(就一行代码的事),写什么程序呢?在网上闲逛时发现sudoku游戏,sudoku十几年前就知道了,学生生涯时也想过用C/Java来实现个智能求解,但到最后往往没写成,主要是用C/Java写的话会很麻烦。
现在写程序,本人总是有一种思维惯性,总是想把程序写的更紧凑,更精致,代码行数最少,所以现
- java apache ftpClient
bro_feng
java
最近使用apache的ftpclient插件实现ftp下载,遇见几个问题,做如下总结。
1. 上传阻塞,一连串的上传,其中一个就阻塞了,或是用storeFile上传时返回false。查了点资料,说是FTP有主动模式和被动模式。将传出模式修改为被动模式ftp.enterLocalPassiveMode();然后就好了。
看了网上相关介绍,对主动模式和被动模式区别还是比较的模糊,不太了解被动模
- 读《研磨设计模式》-代码笔记-工厂方法模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
package design.pattern;
/*
* 工厂方法模式:使一个类的实例化延迟到子类
* 某次,我在工作不知不觉中就用到了工厂方法模式(称为模板方法模式更恰当。2012-10-29):
* 有很多不同的产品,它
- 面试记录语
chenyu19891124
招聘
或许真的在一个平台上成长成什么样,都必须靠自己去努力。有了好的平台让自己展示,就该好好努力。今天是自己单独一次去面试别人,感觉有点小紧张,说话有点打结。在面试完后写面试情况表,下笔真的好难,尤其是要对面试人的情况说明真的好难。
今天面试的是自己同事的同事,现在的这个同事要离职了,介绍了我现在这位同事以前的同事来面试。今天这位求职者面试的是配置管理,期初看了简历觉得应该很适合做配置管理,但是今天面
- Fire Workflow 1.0正式版终于发布了
comsci
工作workflowGoogle
Fire Workflow 是国内另外一款开源工作流,作者是著名的非也同志,哈哈....
官方网站是 http://www.fireflow.org
经过大家努力,Fire Workflow 1.0正式版终于发布了
正式版主要变化:
1、增加IWorkItem.jumpToEx(...)方法,取消了当前环节和目标环节必须在同一条执行线的限制,使得自由流更加自由
2、增加IT
- Python向脚本传参
daizj
python脚本传参
如果想对python脚本传参数,python中对应的argc, argv(c语言的命令行参数)是什么呢?
需要模块:sys
参数个数:len(sys.argv)
脚本名: sys.argv[0]
参数1: sys.argv[1]
参数2: sys.argv[
- 管理用户分组的命令gpasswd
dongwei_6688
passwd
NAME: gpasswd - administer the /etc/group file
SYNOPSIS:
gpasswd group
gpasswd -a user group
gpasswd -d user group
gpasswd -R group
gpasswd -r group
gpasswd [-A user,...] [-M user,...] g
- 郝斌老师数据结构课程笔记
dcj3sjt126com
数据结构与算法
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
- yii2 cgridview加上选择框进行操作
dcj3sjt126com
GridView
页面代码
<?=Html::beginForm(['controller/bulk'],'post');?>
<?=Html::dropDownList('action','',[''=>'Mark selected as: ','c'=>'Confirmed','nc'=>'No Confirmed'],['class'=>'dropdown',])
- linux mysql
fypop
linux
enquiry mysql version in centos linux
yum list installed | grep mysql
yum -y remove mysql-libs.x86_64
enquiry mysql version in yum repositoryyum list | grep mysql oryum -y list mysql*
install mysq
- Scramble String
hcx2013
String
Given a string s1, we may represent it as a binary tree by partitioning it to two non-empty substrings recursively.
Below is one possible representation of s1 = "great":
- 跟我学Shiro目录贴
jinnianshilongnian
跟我学shiro
历经三个月左右时间,《跟我学Shiro》系列教程已经完结,暂时没有需要补充的内容,因此生成PDF版供大家下载。最近项目比较紧,没有时间解答一些疑问,暂时无法回复一些问题,很抱歉,不过可以加群(334194438/348194195)一起讨论问题。
----广告-----------------------------------------------------
- nginx日志切割并使用flume-ng收集日志
liyonghui160com
nginx的日志文件没有rotate功能。如果你不处理,日志文件将变得越来越大,还好我们可以写一个nginx日志切割脚本来自动切割日志文件。第一步就是重命名日志文件,不用担心重命名后nginx找不到日志文件而丢失日志。在你未重新打开原名字的日志文件前,nginx还是会向你重命名的文件写日志,linux是靠文件描述符而不是文件名定位文件。第二步向nginx主
- Oracle死锁解决方法
pda158
oracle
select p.spid,c.object_name,b.session_id,b.oracle_username,b.os_user_name from v$process p,v$session a, v$locked_object b,all_objects c where p.addr=a.paddr and a.process=b.process and c.object_id=b.
- java之List排序
shiguanghui
list排序
在Java Collection Framework中定义的List实现有Vector,ArrayList和LinkedList。这些集合提供了对对象组的索引访问。他们提供了元素的添加与删除支持。然而,它们并没有内置的元素排序支持。 你能够使用java.util.Collections类中的sort()方法对List元素进行排序。你既可以给方法传递
- servlet单例多线程
utopialxw
单例多线程servlet
转自http://www.cnblogs.com/yjhrem/articles/3160864.html
和 http://blog.chinaunix.net/uid-7374279-id-3687149.html
Servlet 单例多线程
Servlet如何处理多个请求访问?Servlet容器默认是采用单实例多线程的方式处理多个请求的:1.当web服务器启动的