使用python编写web项目,第三节,过渡,从项目文件的拆分到创建数据库模型
上一级讲了怎么对项目文件做一个基本的拆分,以及同步数据库中可能会出现的问题,这一节以讲解思路为主,技术性内容较少
在本篇文章开始之前,先在这里对上一节的一个细节做一个补充说明,上一节为什么讲完文件的拆分后又来同步数据库呢,这个是因为在整理完基本的结构布局之后,接下来就是创建数据库模型,然后开始编写页面的接口等其他的逻辑代码,而编写其他逻辑代码的时候,如果连数据库模型都还没有创建,那么在开发过程中,就不方便测试了,因此需要先创建数据库,所以这个时候同步数据库就比较合理且规范了,在这里小编并不是说这个顺序一定是最标准,最合理的,但是这个也是相对比较规范的
好了,补充说明的就到这里了,下面是这次的内容
项目目录的结构插图:
项目目录 |--- __pycache__ (这个目录用于存放编译后的python字节码文件,以‘.pyc’为后缀名) |--- .vscode (用于调试项目的目录) |--- migrations (同步数据库的迁移目录) |--- __pycache__ |--- versions (存放数据库的历史版本) |... (其他文件) |--- stu_mng (项目的主目录,项目后面的编写都在这个目录中进行) |--- __pycache__ |--- student (编写学生模块的目录,和学生相关的功能在这下面编写) |--- __pycache__ |--- __init__ (在这个文件中创建蓝图对象) |--- models.py (在这个文件中编写学生相关的模型) |--- views.py (在这个文件中编写学生相关的视图) |--- ...... (后续的其他业务模块目录) |--- __init__.py (包的初始化文件) |--- public_model.py (项目的公共模型,在这个文件中编写整个项目都通用的一些基础模型) |--- config.py (项目的配置文件) |--- manager.py (管理文件,相当于项目的入口文件,项目从这里启动) |--- README.txt (项目的说明文件,相当于说明书) |--- request.http (接口测试文件,用来测试项目中的各个接口)这个是本次编写后的最新结构
这个项目开发到这里,整体的项目结构按功能划分的话,是基本上不会再出现新的文件了,说到项目结构的划分,这里简单提一下,项目结构的划分按小的分类有按业务逻辑分类和按代码功能分类两种,按大的分类有MTV架构和MCV架构两种,对这个不清楚的可以上网去搜,小编这里按小的分类属于按业务逻辑划分类型的,按大的分类属于MCV架构
项目的进一步拆分思路:
下面来说一下这次拆分的思路,也就是这次出现的新目录和新文件,为什么会创建
- 首先,在同步完数据库之后,就要开始编写业务逻辑了,然后因为小编采用的是按业务逻辑划分的结构,那么学生管理系统初步分析一下,就有学生,老师和管理者三部分的业务,因此就需要创建一个专门编写学生部分业务的目录,所以在主目录下就有一个student目录
- 然后为了方便后面管理这些业务相关的模块和接口,小编使用了flask框架的蓝图模块,需要创建蓝图对象,从而去管理其他文件中的接口,因为这个是启动项目时一个必要的操作,所以在__init__.py文件中创建蓝图,创建完蓝图之后别忘了和相同业务下的其他文件相互导入,不然程序在运行时可能会漏掉文件执行不到,这个能不能找出其中的关系就看自己的水平了,小编就出现过这个情况
- 接下来,管理用的蓝图创建完之后,就要开始编写学生部分的逻辑了,就包括相关的接口,也就是每个页面所对应的视图函数,和相关的数据库模型,因此就需要创建models.py和views.py文件,用于创建模型和编写视图
- 在创建模型的时候,有时候会需要创建一些公共的模型,其他模型可能都需要使用的,对于这样的模型,一般不会在某个业务模块中创建,而是在主目录下,或者主目录的同级创建,所以这里小编选择在主目录下创建一个public_model.py文件,用于创建一些公共的模型,这些公共的模型也不是说一定需要,这个根据个人的需求来决定
- 在开发过程中,还需要不断的调试代码,就需要在调试栏中进行操作,然后系统就会自动创建.vscode目录,才能进行调试,关于这个目录的具体来源,下面会再补充说明,在调试的时候,因为需要调试API接口,但是这个一般是在图形化界面中操作的,所以在这里需要下载一些插件,这里小编使用的是一个叫REST Client的插件,对于这个插件在下面会进行补充,使用这个插件就可以对接口进行调试了,目录中的request.http文件就是因为这个插件才插件的
- 图中还有一个用省略号表示的目录,这个后续的其他业务部分,因为还没有编写,但是结构和学生部分的一样,所以就简单说明一下
数据库模型的基本创建:
在拆分思路分析完之后,再说一下基本的数据库模型的创建
既然要创建模型,就肯定需要操作模型,那么因为是在python中操作数据库,所以需要使用SQLAlchemy模块,但是这里用的是flask 框架,所以需要下载的模块是flask-sqlalchemy
# 使用这个命令就可以下载 pip install flask-sqlalchemy
# 学生模型 class Student(db.Model,Time): __tablename__ = 'students' id = db.Column(db.Integer, primary_key=True, autoincrement=True) name = db.Column(db.String(32), nullable=False, unique=True) s_id = db.Column(db.String(16), nullable=False, unique=True) phone = db.Column(db.String(11), nullable=False, unique=True) gender = db.Column(db.String(4), nullable=False) age = db.Column(db.Integer, nullable=False) faculties = db.Column(db.String(128), nullable=False) profession = db.Column(db.String(128), nullable=False) class_ = db.Column(db.String(128), nullable=False)
这个模型只是一个很基础的模型,所以就简单的说一下各个关键字(这一块适合刚学sqlalchemy的新手)
__tablename__ = 'xxx',这个是模型映射到数据库中的名字,也就是表名
db.Column,通过对象的这个关键字创建字段
db.Integer,通过这个关键字设置字段的数据类型为整数类型
db.String(),通过这个关键字设置字段的数据类型为字符串类型,后面的括号是设置字段的长度,必填
primary_key=True,设置字段为主键,在一个模型或者一个表中只能有一个字段设置主键
autoincrement=True,设置字段自增长,默认值为False
nullable=False,设置字段不能为空,默认值为True
补充:(这个参数如果记不清是允许还是不允许,可以这么记忆,null表示空,able表示允许,连在一起就是允许为空,所以如果设置为True就是允许为空,False就是不允许为空)
unique=True,设置字段的数据是唯一的,默认值为False
模型中继承的两个对象,db是小编在其他文件中创建的sqlalchemy对象,Time是一个公共的基础类
关于.vscode目录:
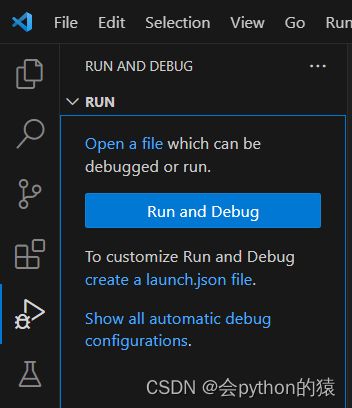 在项目中,他的调试不同于平时学习的单个文件,单个文件可以直接调试,在这里,不管你是想测试哪一段代码,都必须运行整个项目,也就是打开并执行项目的启动文件,那么就会很麻烦,因此可以点击图中的 ‘ create a launch.json file ’ 这行文字,创建这个文件,然后系统就会自动创建这个目录,并在目录中创建这个调试文件,然后不管在哪个文件中,都可以启动项目进行调试
在项目中,他的调试不同于平时学习的单个文件,单个文件可以直接调试,在这里,不管你是想测试哪一段代码,都必须运行整个项目,也就是打开并执行项目的启动文件,那么就会很麻烦,因此可以点击图中的 ‘ create a launch.json file ’ 这行文字,创建这个文件,然后系统就会自动创建这个目录,并在目录中创建这个调试文件,然后不管在哪个文件中,都可以启动项目进行调试
关于REST Client插件:
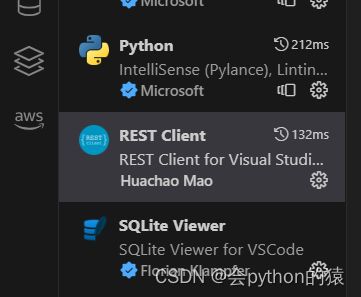
搜索图中这个插件下载即可,按照插件上的教程,创建相应的文件,在文件中编写调试代码即可对接口进行调试
以上就是这次关于进一步拆分文件的思路和创建数据库模型的简单解说,都说程序员经常熬夜写代码,修改bug什么的,小编现在还没有成为程序员,就已经开始在为这个文章熬夜了,嘿嘿嘿,小编都那么辛苦了,就麻烦路过的朋友点个赞,收藏一下,顺便在加个关注,哈哈哈