中国文化之光:微博数据的探索与可视化分析
大家好,我是八块腹肌的小胖
下面我们针对主题“中国文化”相关的微博数据进行爬取
使用LDA、情感分析、情感演化、词云等可视化操作进行相关的展示
1、导包
第一步我们开始导包工作
下面这段代码,首先,pandas被请来了,因为它是处理数据的高手,能把数据弄得井井有条。然后,gensim也加入了,它擅长于自然语言处理,就像是让数据说话的魔术师。
接着,咱们用了simple_preprocess,这个就像是个文本切割机,能把长长的文本切成小块,便于后面的处理。还有corpora,它的任务是建立词袋模型,就像是给每个词分个类,整理得井井有条。
然后轮到了LDA模型出场,它的任务是把那些看起来杂乱无章的文本变成有意义的主题,就像是个魔法师,能从一堆文字中找出隐藏的秘密。
最后,为了让分析更加精准,nltk里的stopwords也来帮忙了,它负责去除那些像“的”、“和”这样的常见但不太有意义的词。
import pandas as pd
import gensim
from gensim import corpora
from gensim.models import LdaModel
from gensim.models import CoherenceModel
from gensim.utils import simple_preprocess
import pandas as pd
from gensim.utils import simple_preprocess
from gensim import corpora
from gensim.models import LdaModel
from nltk.corpus import stopwords
2、读取数据、数据预处理、构建LDA模型
下面这段代码
首先,咱们用pandas读取了一个叫data.csv的文件,就像是把一箱宝藏打开,准备好挖掘里面的珍宝。
接下来,用jieba来进行分词。这就像是用小刀把文字切成一块块,方便咱们更好地理解它们。
同时,咱们还读取了一个叫stop_words.txt的文件,里面有一堆停用词,这些词就像是箱子里的沙子,咱们把它们筛出去,留下的就是更有价值的内容。
然后,咱们用gensim的corpora来创建词袋模型。这就像是给每个词贴上标签,分好类。
每个词都变成了一个有编号的小盒子,整整齐齐。
现在来到了最激动人心的部分!咱们用LDA模型来分析这些词。
设定了10个主题,这模型就会告诉咱们,在这些文本里,有哪些热门的话题。就像是个神奇的放大镜,能让咱们看到文字背后的世界。
最后,通过打印出来的主题,咱们可以看到每个主题下最重要的20个词。这就像是从混沌中找到了秩序,一切都变得清晰可见。
# 读取数据
data = pd.read_csv('data.csv') # 替换成你的数据文件路径
# 分词去停用词
import jieba
with open('stop_words.txt', 'r', encoding='utf-8') as file:
stop_words = [line.strip() for line in file]
processed_data = data['text'].map(lambda x: [word for word in simple_preprocess(x) if word not in stop_words])
# 创建词袋模型
dictionary = corpora.Dictionary(processed_data)
corpus = [dictionary.doc2bow(text) for text in processed_data]
# 构建LDA模型
num_topics = 10 # 主题数量,可以根据需求进行调整
lda_model = LdaModel(corpus=corpus, id2word=dictionary, num_topics=num_topics)
# 查看主题词
topics = lda_model.print_topics(num_words=20)
for topic in topics:
print(topic)它们的输出如下:

3、主题词可视化展示
这次咱们的主角是可视化!
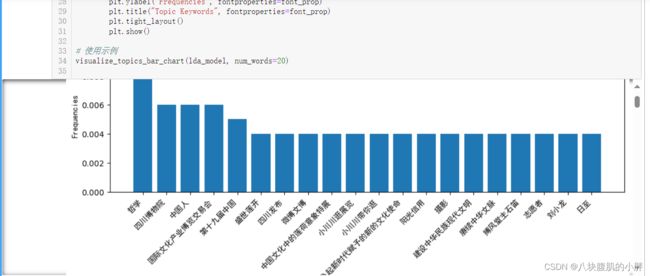
这段代码的大意是,把那些通过LDA模型找到的热门话题变成一幅幅好看的柱状图。
首先,定义了一个叫visualize_topics_bar_chart的函数,这个函数就像是个画家,专门负责画柱状图。lda_model和num_words=20是它的画笔和颜料,用来确定要画什么和怎么画。
函数里首先提取了每个主题的前20个关键词。这些关键词和它们的频率就像是画布上的主角,每个都有自己的位置和重要性。
然后,代码把这些词按频率排序,确保最重要的词能被突出显示。接着,用matplotlib(一个绘图大师)来绘制柱状图,把这些词和它们的频率以柱子的形式展示出来。
因为处理的是中文数据,所以还特别设置了中文字体,确保图表上的文字清晰、美观。
最后,函数会展示出一幅幅柱状图,每一幅都代表一个主题,柱子的高矮显示了各个词的重要性。让人一目了然。
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
def visualize_topics_bar_chart(lda_model, num_words=20):
topics = lda_model.print_topics(num_words=num_words)
for topic in topics:
topic_words = {}
words = topic[1].split(" + ")
for word in words:
freq, term = word.split("*")
term = term.replace('"', '').strip()
topic_words[term] = float(freq)
sorted_words = sorted(topic_words.items(), key=lambda x: x[1], reverse=True)
terms = [w[0] for w in sorted_words]
frequencies = [w[1] for w in sorted_words]
# 指定中文字体文件路径
font_path = 'SimHei.ttf'
# 加载中文字体
font_prop = FontProperties(fname=font_path)
plt.figure(figsize=(10, 5))
plt.bar(range(len(terms)), frequencies)
plt.xticks(range(len(terms)), terms, rotation=45, ha="right", fontproperties=font_prop)
plt.xlabel("Words", fontproperties=font_prop)
plt.ylabel("Frequencies", fontproperties=font_prop)
plt.title("Topic Keywords", fontproperties=font_prop)
plt.tight_layout()
plt.show()
# 使用示例
visualize_topics_bar_chart(lda_model, num_words=20)
4、词云展示
咱们接着来看这段代码,这回是要制作一幅词云图!
首先,这段代码从LDA模型的主题中提取了所有的关键词。
然后,把这些挑选出来的词连成一串,用空格隔开。这就像是在准备画布,把所有的“颜料”(也就是词汇)摆好位置。
接下来,用WordCloud这个工具来创建词云。这个工具就像是个神奇的画笔,能把单调的文字变成有趣的图形。
这里还特别设置了词云的大小和背景颜色,还有中文字体,确保一切看起来既美观又清晰。
用matplotlib来展示这幅词云图。词云里的每个词都有不同的大小,这表示它们在主题中的重要程度。

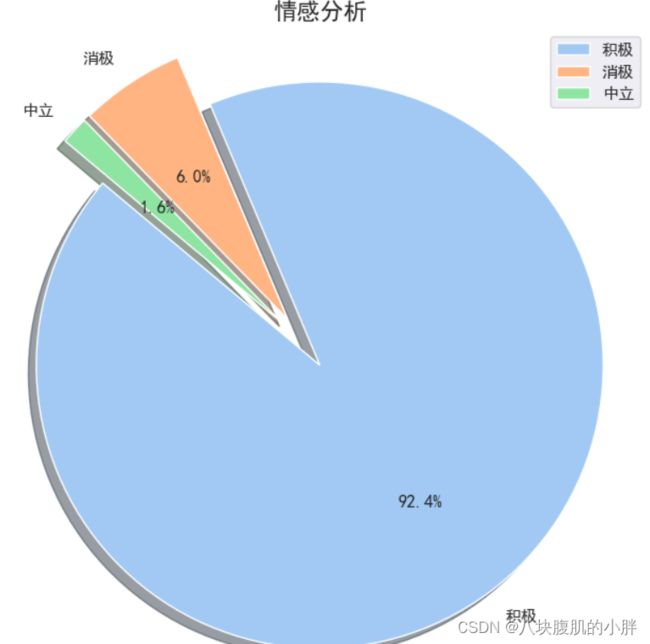
5、情感倾向性分析饼状图展示
咱们这段代码,给数据做了个情感检查,然后用一幅饼图来展示结果!
首先,用pandas读取了data.csv文件,里面装的是一些文本数据。
接下来,用SnowNLP来分析这些文本的情感倾向。这个过程就像是对每段文字进行情感测量,看看它们是开心的、悲伤的,还是居中的。
然后,根据情感分数,统计出积极、消极和中立的文本数量。这就像是把情感分成三个篮子,看看每个篮子里有多少故事。
接着,用matplotlib和seaborn把这些统计结果绘制成一幅饼图。这幅图用不同的颜色和大小展示了每种情感的比例,还特别标注了百分比,让人一眼就能看明白。
最后,还对图表进行了美化,比如设置了中文字体、图表标题和图例。然后展示出这幅图,让人一眼就能感受到这些数据背后的情感色彩。
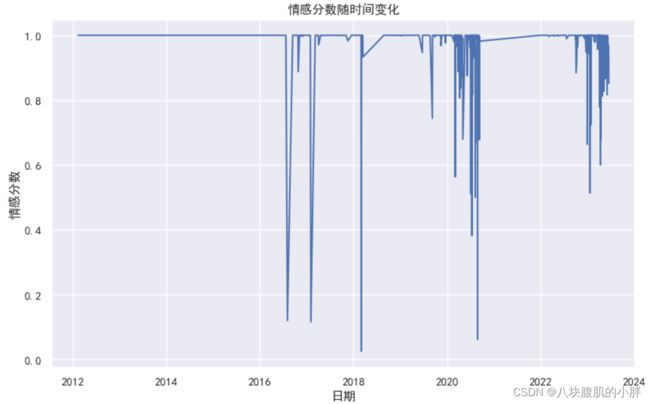
6、情感分值随时间变化的展示
下面的diamond首先,用pandas读取了data.csv文件,里面装着一堆数据。然后,把created_at字段中的日期字符串转换成了真正的日期格式,这样就方便咱们后面按日期来分析情感了。
用SnowNLP来分析每段文本的情感。这个过程就像是给每段故事打个情感标签,比如高兴、伤心或者是中立。
然后,把这些情感分数加到数据表里,每一行数据都有了自己的情感得分。这就像是给数据表每个单元格贴上了情感小贴纸。
这里有意思了,咱们按照日期来分组,计算每天的情感得分平均值。这就像是把每天的情感做了个总结,看看每天的整体心情怎么样。
最后,用matplotlib来画一幅折线图,展示了情感得分随时间的变化。每个点都代表一天的平均情感得分,线条连接着这些点,就像是在时间轴上跳舞的心情线。图表上还有标题、日期标签和情感分数标签。