Annotator Consensus Prediction for MedicalImage Segmentation with Diffusion Models
基于扩散模型的医学图像分割的注释器共识预测
摘要
医学图像分割的一个主要挑战是多个专家提供的注释中观察者之间和观察者内部的差异很大。为了解决这一挑战,我们提出了一种利用扩散模型进行多专家预测的新方法。我们的方法利用基于扩散的方法将来自多个注释的信息合并到一个反映多个专家共识的统一分割图中。我们在多个专家注释的医学分割数据集上评估了我们的方法的性能,并将其与最先进的方法进行了比较。
结果证明了该方法的有效性和鲁棒性。我们的代码可以在https://github.com/ tomeramit/Annotator-Consensus-Prediction上公开获得。
1介绍
医学图像分割是一项具有挑战性的任务,需要在复杂和有噪声的图像中准确地描绘出感兴趣的结构和区域。通常使用多个专家注释器来解决这一挑战,为同一图像提供二值分割注释。然而,由于经验、专业知识和主观判断的差异,注释可能会有很大差异,导致观察者之间和内部的可变性。此外,手工标注是一个耗时和昂贵的过程,限制了分割方法的可扩展性和适用性。
为了克服这些局限性,提出了多标注器预测的自动化方法,该方法旨在融合来自多个标注器的标注,生成准确一致的分割结果。现有的多注释器预测方法包括多数投票[7]、标签融合[3]和标签抽样[12]。
近年来,扩散模型已经成为一种很有前途的图像分割方法,例如使用学习到的语义特征[2]。通过对迭代过程中图像强度值的扩散进行建模,扩散模型可以捕获图像的底层结构和纹理,并可以将感兴趣的区域从背景中分离出来。此外,扩散模型可以处理
噪声和图像伪影,并适应不同的图像模式和分辨率。
在这项工作中,我们提出了一种新的多注释器预测方法,使用扩散模型进行医学二值分割。多注释器预测的目标是融合来自不同注释器的同一图像的多个注释,从而获得更准确、更可靠的分割结果。在实践中,我们利用基于扩散的方法为每个级别的共识创建一个地图。为了得到最终的预测结果,我们对得到的图进行平均,得到一个软图。
我们在由多个注释者注释的医学图像数据集上评估了所提出方法的性能。我们的结果证明了所提出的方法在处理观察者之间和观察者内部的可变性方面的有效性和鲁棒性,并实现了比最先进的方法更高的分割精度。该方法可以提高医学图像分割的效率和质量,便于临床决策。
2 相关工作
多注释器策略。最近的研究重点集中在多注释器标签问题上[7,12]。在训练过程中,Jensen等[12]对每张图像随机抽取不同的标签。这种方法产生了一个更精确的模型。Guan等[7]分别预测每个注释者的评分,并获得相应的权重用于最终预测。Kohl等人[15]使用相同的采样策略来训练概率模型,该模型基于U-Net结合条件变分自编码器。另一种最近的概率方法[20]将扩散模型与KL散度结合起来,以捕获不同注释器之间的可变性。在我们的工作中,我们使用共识图作为基础事实,并将其与其他策略进行比较。
扩散概率模型(Diffusion Probabilistic Models, DPM)[23]是一类基于马尔可夫链的生成模型,它可以将简单分布(如高斯分布)转换为从复杂分布中采样的数据。扩散模型能够生成高质量的图像,可以与最新的GAN方法竞争,甚至优于GAN方法[23,9,19,5]。Huang等人[11]引入了扩散模型似然估计的变分框架。
随后,Kingma等人[14]提出了一种变分扩散模型,该模型在图像密度的似然估计中产生了最先进的结果。
在我们的工作中,我们使用扩散模型作为条件生成来解决图像分割问题,给定图像。扩散模型的条件生成包括类条件生成的方法,它是通过在时间步嵌入中加入一个类嵌入来获得的[19]。文献[4]提出了一种指导DDPM生成过程的方法。这种方法允许基于给定的参考图像生成图像,而无需任何额外的学习。在超分辨率领域,将低分辨率图像上采样,然后在每次迭代时将低分辨率图像以通道方式拼接到生成的图像中[21,10]。一个类似的
该方法在拼接之前将低分辨率图像通过卷积块[16]。
先前的研究直接应用扩散模型,基于条件输入图像生成分割掩码[1]。Baranchuk等人[2]从预训练的扩散模型中提取特征用于训练分割网络,而我们的扩散模型生成输出掩码。与Wolleb等人[26]基于扩散的图像分割方法相比,我们的架构在两个主要方面有所不同:(i)条件信号的拼接方法,(ii)处理条件信号的编码器。我们还使用较低的T值,这减少了运行时间。
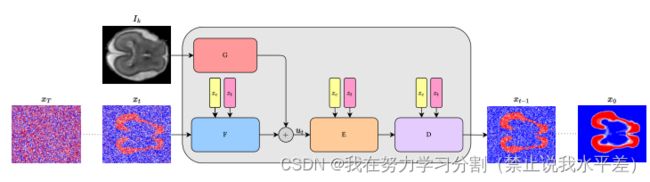
图1所示。下图展示了我们提出的多注释器分割方法。带噪声分割映射xt的输入Ik图像在我们的网络中迭代传递T次,以获得输出分割映射x0。每个网络接收共识级别c作为嵌入zc以及时间步长数据。
3 方法
我们使用多注释器进行二值分割的方法采用了一个扩散模型,该模型以输入图像I∈RW ×H、步长估计t和共识指数c为条件。扩散模型使用步长估计函数ϵθ迭代地更新其当前估计xt。如图1所示。
给定一组C注释{Aik}Ci=1与输入样本Ik相关联,我们定义C层的基础真值一致映射为

在训练过程中,我们的算法迭代采样共识c ~ U的随机水平[1,2,…], C]和一个输入输出对(Ik, mck)。迭代次数1≤t≤t从均匀分布中采样,XT从正态分布中采样。
然后由xt, ck, t计算出xt:

其中¯α是一个常数,它定义了附加噪声的时间表。
