容器化对数据库的性能有影响吗?
引言
容器化是一种将应用程序及其依赖项打包到一个独立、可移植的运行环境中的技术。容器化技术通过使用容器运行时引擎(比如Docker/Containerd)来创建、部署和管理容器。Kubernetes(通常简称为 k8s)是一个开源的容器编排和管理平台,它提供了一个集中式的、可伸缩的平台来自动化容器的部署、扩展、管理和调度。
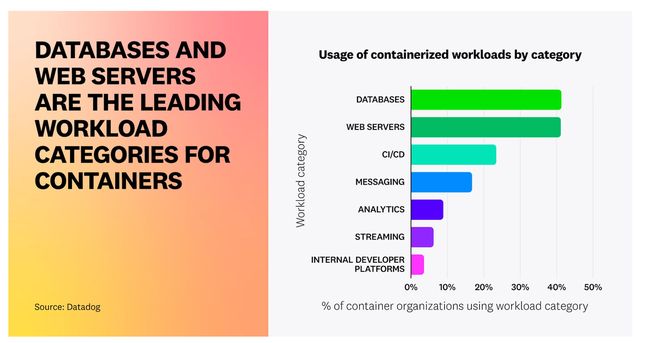
Fig. 1. Usage of containerized workloads by category [4]
数据库容器化的趋势已经非常明显,如图.1 所示,数据库+分析类的 workload 已经占据了半壁江山,但是依然有很多人在做技术选型时面临一个难题:容器化是否对数据库性能有影响?如果有,影响的因素是什么?如何面对容器化带来的性能甚至是稳定性的问题?
容器化优势和技术原理
容器化的优势
灵活性和可移植性:容器化技术提供了灵活性和可移植性的优势,使得数据库的部署和迁移变得更加简单和可靠,容器化也是 IaC 的基础。
资源隔离和可扩展性:容器化技术通过使用容器运行时引擎提供了资源隔离和可扩展性的优势。每个容器都有自己的运行时环境和资源分配,因此数据库实例可以在容器中独立运行,相互之间影响降到最低。这种资源隔离使得数据库实例能够更好地利用计算资源,并提供更好的性能和可靠性。
更友好的调度策略:由于容器化后的资源粒度更小,对上层调度更为友好,可以在不同场景应用不同的调度策略,比如通过离线和在线混合部署来错峰使用计算资源,多种引擎混部提升整体利用率,通过提升部署密度来降低计算成本。
容器化技术原理和分类
虚拟化
说到容器,那就不得不提虚拟化,虚拟化是一种将计算资源进行抽象和隔离的技术,使得多个虚拟实例可以在同一物理服务器上同时运行。它通过在硬件和操作系统之间引入虚拟机监视器(Hypervisor)的软件层,将物理服务器分割为多个虚拟机,并为每个虚拟机提供独立的操作系统和资源。每个虚拟机都可以运行完整的操作系统,并具有独立的内核和资源,类似于在物理服务器上运行一个完整的计算机。
容器化是一种更为轻量的虚拟化技术,它使用操作系统级别的虚拟化来隔离和运行应用程序及其依赖的环境。容器化和虚拟化一般搭配使用,以满足用户对不同隔离场景的需求。
虚拟化+容器化分类
根据容器运行时的资源隔离和虚拟化方式,可以将目前的主流虚拟化+容器技术分为这么几类:
1.标准容器,符合 OCI (Open Container Initiative)规范,如 docker/containerd,容器运行时为 runc,这是目前 k8s workload 的主要形态
2.用户态内核容器,如 gVisor,也符合 OCI 规范,容器运行时为 runsc,有比较好的隔离性和安全性,但是性能比较差,适合比较轻量的 workload
3.微内核容器,使用了 hypervisor,如 Firecracker、Kata-Container,也符合 OCI 规范,容器运行时为 runc 或 runv,有比较好的安全性和隔离性,性能介于标准容器和用户态内核容器之间
4.纯虚拟机,如 KVM、Xen、VMWare,是主流云厂商服务器的底层虚拟化技术,一般作为 k8s 中的 Node 存在,比容器要更低一个层次
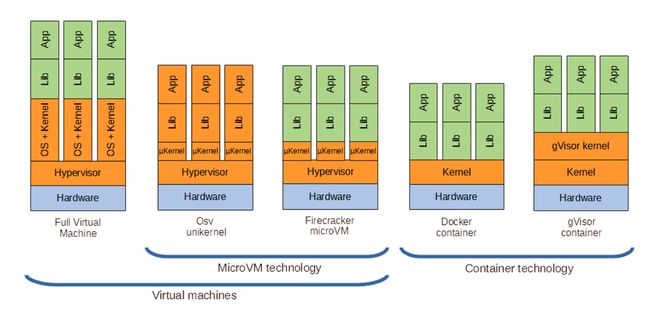
Fig. 2. Comparison of system architecture of various lightweight virtualization methods. Orange parts are kernel space, while green parts are user space.[2]
OCI 主流容器技术实现
下面我们对符合 OCI 规范的几款主流容器化技术做一下分析
-
1.runc:
runc 是一个符合 OCI 标准的容器运行时,它是 Docker/Containerd 核心容器引擎的一部分。它使用 Linux 的命名空间(Namespace)和控制组(Cgroup)技术来实现容器的隔离。
在运行容器时,runc 使用命名空间隔离容器的进程、网络、文件系统和 IPC(进程间通信)。它还使用控制组来限制容器内进程的资源使用。这种隔离技术使得容器内的应用程序可以在一个相对独立的环境中运行,与宿主机和其他容器隔离开来。
runc 的隔离技术虽然引入了一定开销,但是这种开销仅限于命名空间映射、限制检查和一些记账逻辑,理论上影响很小,而且当 syscall 是长耗时操作时,这种影响几乎可以忽略不计,一般情况下,基于 Namespace+Cgroup 的隔离技术对 CPU、内存、I/O 性能的影响较小。
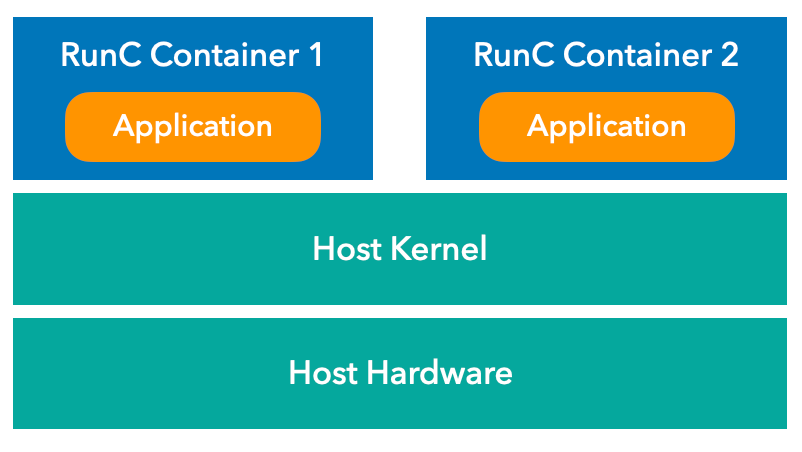
Fig. 3. Runc Architecture -
2.Kata Containers:
Kata Containers 是一个使用虚拟机技术实现的容器运行时,它提供了更高的隔离性和安全性。Kata Containers 使用了 Intel 的 Clear Containers 技术,并结合了轻量级虚拟机监控器和容器运行时。
Kata Containers 在每个容器内运行一个独立的虚拟机,每个虚拟机都有自己的内核和用户空间。这种虚拟化技术能够提供更严格的隔离,使得容器内的应用程序无法直接访问宿主机的资源。然而,由于引入了虚拟机的启动和管理开销,相对于传统的容器运行时,Kata Containers 在系统调用和 I/O 性能方面可能会有一些额外的开销。
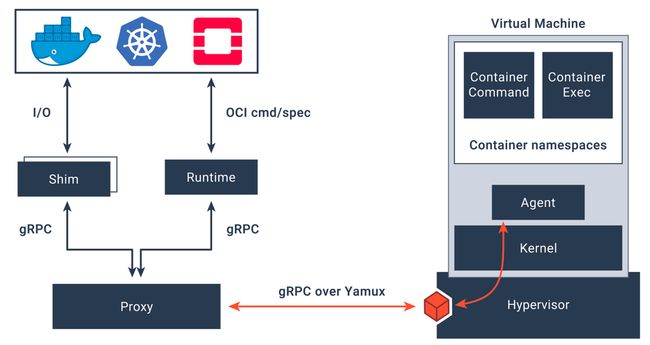
Fig. 4. Kata Containers Architecture -
3.gVisor:
gVisor 是一个使用用户态虚拟化技术实现的容器运行时,它提供了更高的隔离性和安全性。gVisor 使用了自己的内核实现,在容器内部运行。
gVisor 的内核实现,称为 “Sandboxed Kernel”,在容器内部提供对操作系统接口的模拟和管理。容器内的应用程序和进程与宿主内核隔离开来,无法直接访问或影响宿主内核的资源。这种隔离技术在提高安全性的同时,相对于传统的容器运行时,可能会引入一些额外的系统调用和 I/O 性能开销。
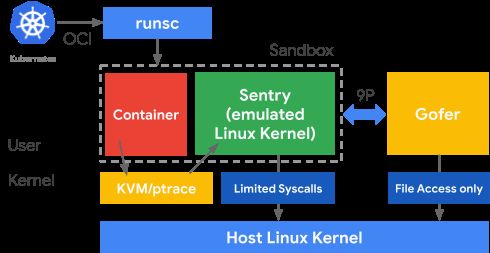
Fig. 5. gVisor Architecture -
4.Firecracker:
Firecracker 是一种针对无服务器计算和轻量级工作负载设计的虚拟化技术。它使用了微虚拟化技术,将每个容器作为一个独立的虚拟机运行。
Firecracker 使用 KVM(Kernel-based Virtual Machine)技术作为底层虚拟化技术。每个容器都在自己的虚拟机中运行,拥有独立的内核和根文件系统,并使用独立的虚拟设备模拟器与宿主机通信。这种隔离技术提供了较高的安全性和隔离性,但相对于传统的容器运行时,Firecracker 可能会引入更大的系统调用和 I/O 性能开销。
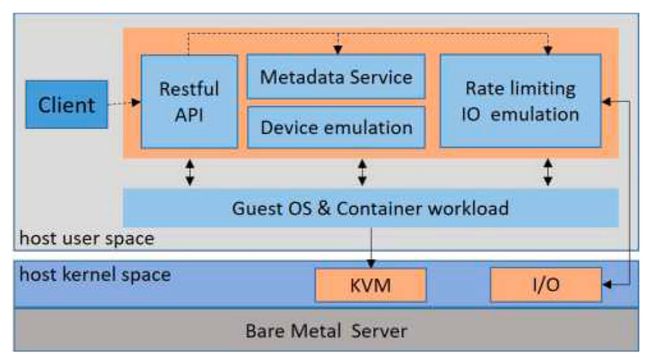
Fig. 6. Firecracker Architecture
实现原理对比:
Table. 1: Overview of implementations of virtualization and isolation in Containerization
| Containerd-runc | Kata-Container | gVisor | FireCracker-Containerd | |
|---|---|---|---|---|
| 隔离原理 | Namespace + Cgroup | Guest Kernel | Sandboxed Kernel | microVM |
| OCI Runtime | runc | Clear Container + runv | runsc | runc |
| 虚拟化技术 | Namespace | QEMU/Cloud Hypervisor+KVM | Rule-Based Execution | rust-VMM + KVM |
| vCPU | Cgroup | Cgroup | Cgroup | Cgroup |
| Memory | Cgroup | Cgroup | Cgroup | Cgroup |
| Syscall | Host | Guest + Host | Sentry | Guest + Host |
| Disk I/O | Host | virtio | Gofer | virtio |
| Network I/O | Host + veth | tc + veth | netstack | tap + virtio-net |
还有人对 Container Engine 的不同实现做了对比,比如 Containerd 和 CRI-O [3][5],这个对比也不在本文讨论范围内,留给感兴趣的读者自己去了解。
K8s + 容器化对数据库的影响:
容器化对数据库有很多正面的影响:比如容器化可以简化数据库的部署和管理、为数据库提供标准的隔离运行环境、可以让数据库在不同的复杂环境中轻松部署和灵活迁移、对数据库的版本管理也更加规范和方便。而且在 k8s 的加持下,数据库中的多种角色和组件可以被灵活有机地编排在一起。
容器化对数据库的挑战:
但是,k8s+容器化对数据库也带来了很多挑战,这和数据库本身的特点也有很大关系,与普通的无状态应用相比,数据库有如下特点:
-
1.数据库是一个有多种角色的复杂应用:一个完整的数据库有多种不同的角色,比如 MySQL 主备形态中,同样是两个 MySQL 容器,一个是主,一个是备,角色并不对等,这种不对等的关系需要被正确表达,而且在创建、重启、删除、备份、高可用等各种运维操作中都要被正确管理,本质上这是一种容器之间对于数据状态的互相依赖,对于这种依赖目前的容器和 k8s 都没有很好地抽象与解决。
-
2.数据库对数据的持久性和一致性有很高的需求:数据库对存储有很高的需求,简单的容器化并不能满足一个生产级别的 workload,还需要配套的 CSI 和 PersistentVolume,对存储的选型也影响着数据库可选的操作选项,比如云盘有很高的 durability,提供 snapshot 备份功能,并能在不同的计算节点上 attach 和 detach,对数据库的备份恢复和高可用操作非常友好;但在本地盘上,这种选择就会更窄一些,比如 node 宕机时我们可能就会永远失去一个数据副本,高可用操作处理起来会更有挑战,备份操作也只能选择物理/文件(physical)备份或逻辑(logical)的方式。不同的存储方案对应着不同的持久化能力和不一样的数据库架构。
-
3.数据库对性能也有很高的需求:数据库对性能的需求比较多样,如果从 CPU、内存、网络、存储这几个方面来进行划分,有 CPU + 存储 I/O 密集型,如 OLAP 产品 ClickHouse、Greenplum 等;有内存 + 网络 I/O 密集型,如 Redis 和内存数据库;有 CPU + 存储 I/O 密集型,如 MySQL、Postgresql 等传统 OLTP 数据库。而且根据查询场景不同,即使是同一个数据库进程在不同的 SQL 中对资源的需求也大相径庭。
-
4.数据库对安全性的要求:数据库中的数据一般都比较核心和敏感,因此对运行环境隔离、数据访问控制、日志审计都有一定的规范化要求。
总而言之,将数据库跑在容器+k8s 上,对数据库是一种很大的挑战,比如数据库要去适应生命周期短暂的容器、浮动的 IP、频繁更新的基础设置、复杂的性能环境;对容器+k8s 也是很大的挑战,比如角色的引入、容器之间的状态和数据依赖、对性能的苛刻需求、对完整安全体系的合规要求。
关于上面提到的 1,2,4 这三点,在我们开发的 KubeBlocks 项目中已经有比较成体系的解决方案,感兴趣的可以去围观 kubeblocks.io。回到本文的主题,在下面的部分会对容器化对数据库性能的影响做进一步的深入分析。
K8s +容器化对数据库性能的影响
如上所述,数据的性能主要受 CPU、内存、存储、网络 这几个因素的影响,我们将围绕这几个方面分析 k8s 和容器化对数据库性能的影响,虽然 k8s 中的一些调度和亲和性策略也会对性能有潜在影响,但这些策略和容器化无关,因此并不在本次讨论范围内。
我们从上述几个维度来综述一下容器化对应用(包括数据库)性能的影响,在本次综述中我们整理了业界近几年的一些论文和测试数据,会对其中的一些测试数据和偏移项进行分析,指出其中的原因与不合理之处,针对一些缺乏的场景我们补了一些测试,比如 k8s CNI 对网络性能的影响。
CPU:
测试服务器:Quad-Core Hyper Thread 4 Intel Core i5-7500 8GB RAM,1TB disk,Ubuntu 18.04 LTS
测试场景:这里的数据和测试场景来自论文 [1],case1 是用 sysbench 4 并发做质数计算,最终汇报每秒发生的 events,属于纯计算场景,几乎所有指令都跑在 user space, syscall 调用可忽略,所以理论上几种容器技术的表现会差不多
测试结果:几种容器的 CPU 表现差不多,相比裸金属,其他场景性能下降都在 4% 左右
分析:这个 4% 的下降应该是 Cgroup 对 CPU 的限制所造成,当 Sysbench 并发等于 Hyper Thread 数量时,被 Cgroup Thottle 的概率非常高,当有 Cgroup Throttle 发生时,进程会被强制等待一个 jiffy(10ms),Cgroup 对资源的计算周期是以 jiffy 为粒度,不是以秒为粒度,所以 4 vCPU 的容器几乎不可能跑到 400%,有一定 loss 是正常的,一般被 Throttle 的次数可以从 Cgroup 的 cpu.stat 文件中查找到
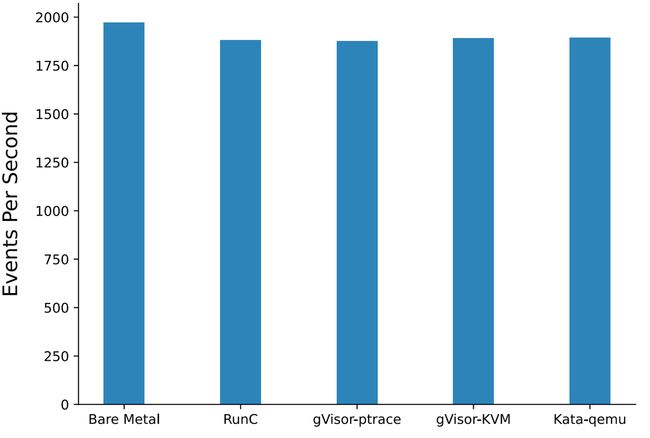
Fig. 7. CPU performance (Sysbench benchmark) (Xingyu Wang 2022)
测试场景:Davi1d 视频解码,视频大小在几百兆左右,在该测试中,由于需要读取磁盘上的数据,所以会有大量的 syscall 调用,syscall 调用会对应用性能造成一部分影响
测试结果:runc 和 kata-qemu 损失 4% 左右,和质数测试结果类似;gVisor-ptrace 损失有 13%,而 gVisor-KVM 能和裸金属持平
分析:视频解码属于顺序读取,顺序读取在 linux 中会有 read ahead 优化,所以绝大部分 I/O 都是直接从 page cache 中读取数据,runc 主要还是受 Cgroup 影响,其他三个方案主要受 syscall 实现方案的影响,论文中并没有就 gVisor-ptrace 和 gVisor-KVM 差别做进一步分析,gVisor 使用了 gofer 做文件系统,gofer 还有自己一些的 cache 策略,进一步的分析可能要从 gVisor syscall 和 cache 策略入手
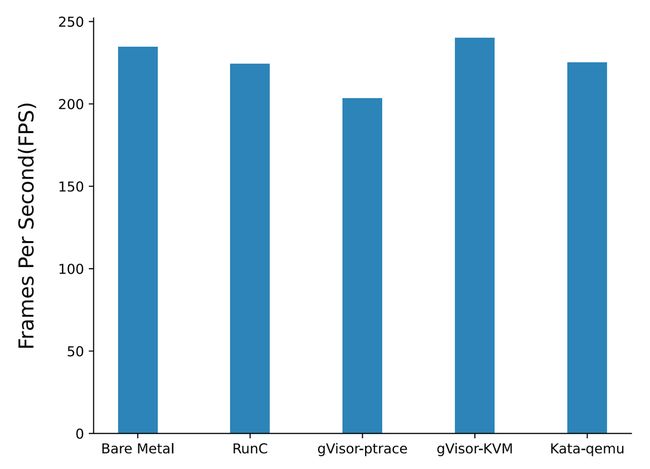
Fig. 8. CPU performance (Dav1d benchmark) (Xingyu Wang 2022)
Memory:
测试场景:RAMSpeed,有 4 个子场景(Copy,Scale,Add,Triad),具体原理就不展开了
测试结果:几种方案都差不多
分析:当内存分配好并做好缺页中断(page fault)后,理论上容器化对内存访问没有影响,真正影响内存性能的是 mmap 和 brk 之类的 syscall 调用,但是这个测试中,此类 syscall 占比极小
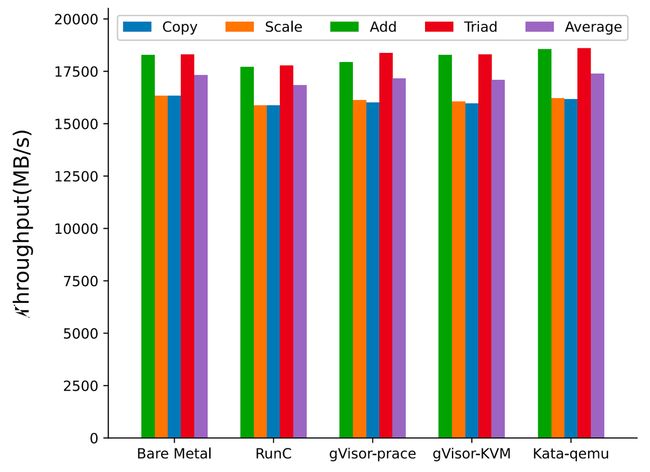
Fig. 9. Memory access performance (Xingyu Wang 2022)
测试场景:Redis-Benchmark,测试了子场景 GET, SET, LPUSH, LPOP, SADD
测试结果:runc 和 kata-qemu 影响很小,gVisor 受影响很大,gVisor-ptrace 损失在 95% 左右,gVisor-KVM 损失在 56% 左右
分析:redis 是单线程重网络 I/O 的一种应用,网络 I/O 都是通过 syscall 进行,所以 gVisor 会有很大的性能损失,原论文中认为损失主要是由内存分配引起,这应该是一种误解,Redis 内部使用用户态内存管理工具 jemalloc,jemalloc 会通过调用 mmap syscall 来向 OS 批发大块内存,然后再做本地小块分配,由于 jemalloc 有比较成熟的内存分配和缓存机制,所以调用 mmap 的几率会很小。当 redis 满载时,网络 I/O 消耗的 CPU (CPU sys) 在 70% 左右,所以这里 gVisor 的性能损耗主要由 syscall 劫持和内部的网络栈 netstack 引起,这个测试也说明 gVisor 目前并不适合重网络 I/O 的场景
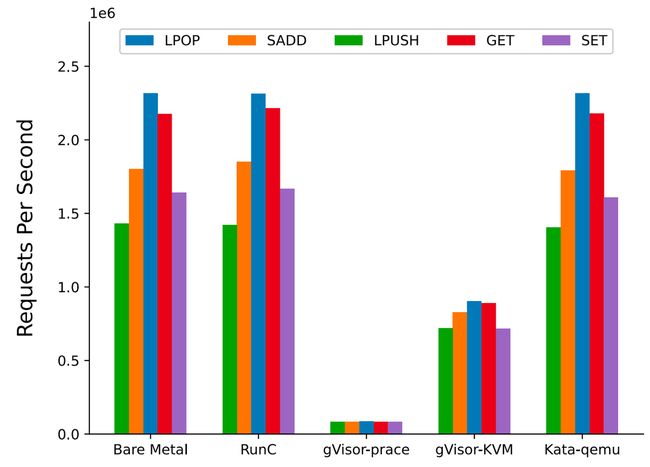
Fig. 10. Redis performance for different container runtimes (Xingyu Wang 2022)
Disk I/O:
测试场景:IOZone 读写 16GB 文件
测试结果:顺序读写影响不大,kata-qemu 受影响较大,影响范围为 12-16%
分析:大块读写其实就是顺序读写,如前所述,顺序读 OS 有 read ahead,顺序读写其实操作的大部分是 page cache,原论文对 kata-qemu 做了分析,认为和 virtio-9p 文件系统有关,virtio-9p 针对网络设计,对虚拟化并没有做针对优化
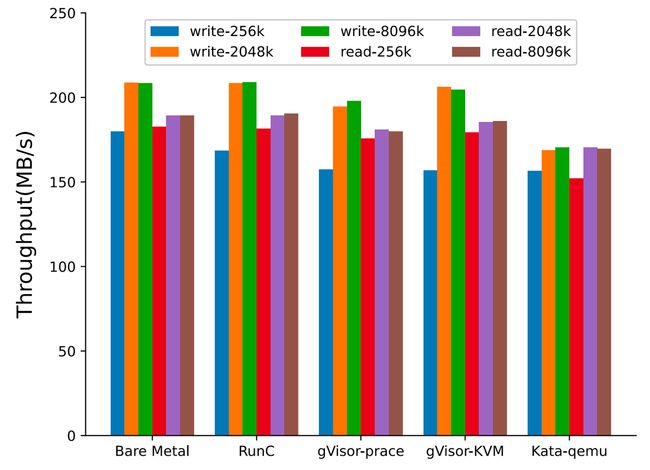
Fig. 11. Disk read and write performance (Xingyu Wang 2022)
测试场景:直接基于 tmpfs(shared memory)做测试,单纯用来衡量 syscall+内存 copy 对性能的影响
测试结果:除了 gVisor,其他都差不多
分析:gVisor syscall 成本比较高,结果和 redis-benchmark 类似
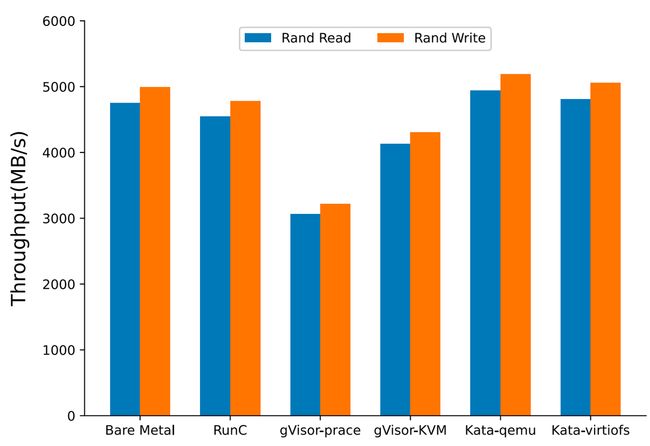
Fig. 12. Disk read and write performance (tmpfs overlay) (Xingyu Wang 2022)
测试场景:SQLite 单线程插入测试,耗时越少越好
测试结果:runc 和裸金属相近,kata 耗时多出 17%,gVisor 耗时多出 125%
分析:数据库 workload 比较复杂,是 CPU、内存、网络、Disk I/O 的综合影响,对 syscall 的调用非常频繁,gVisor 不是很适合此类场景
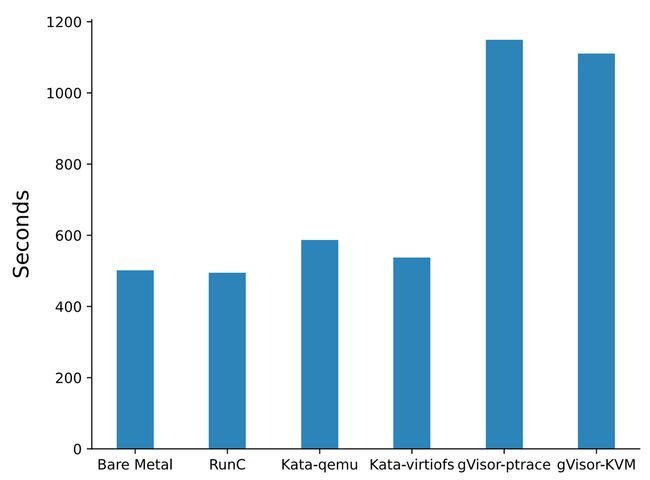
Fig. 13. Database record insertion performance (Xingyu Wang 2022)
Network I/O:
测试场景:TCP stream 吞吐测试,throughtput 越多越好
测试结果:gVisor 网络性能比较差,和在 redis-benchmark 中看到的类似,其他几个影响不大
分析:gVisor 受限于 syscall 机制和 netstack 实现,整体吞吐较差
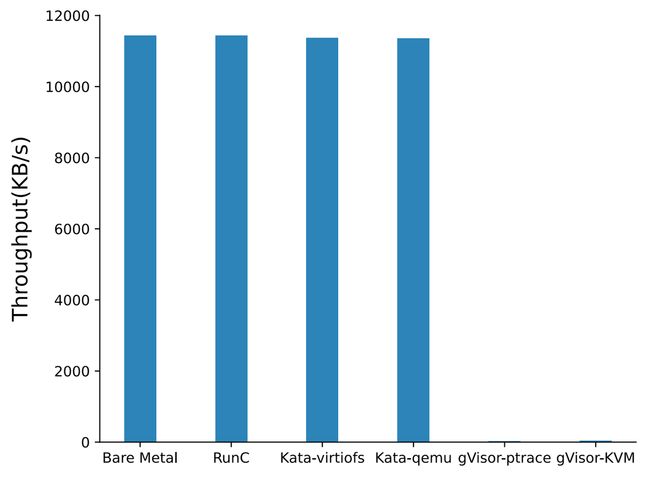
Fig. 14. TCP_STREAM network performance (Xingyu Wang 2022)
测试场景:测试 TCP_RR, TCP_CRR, UDP_RR,RR 是 request & response 的缩写,指的是一个 TCP 请求来回,TCP 链接只建立一次,后续复用,CRR 是指每次测试都创建一条新的 TCP 链接,TCP_RR 对应着长链接的场景,TCP_CRR 对应着短链接的场景
测试结果:runc 和裸金属相近,kata 有较小的损失,gVisor 损失很大,原理同上
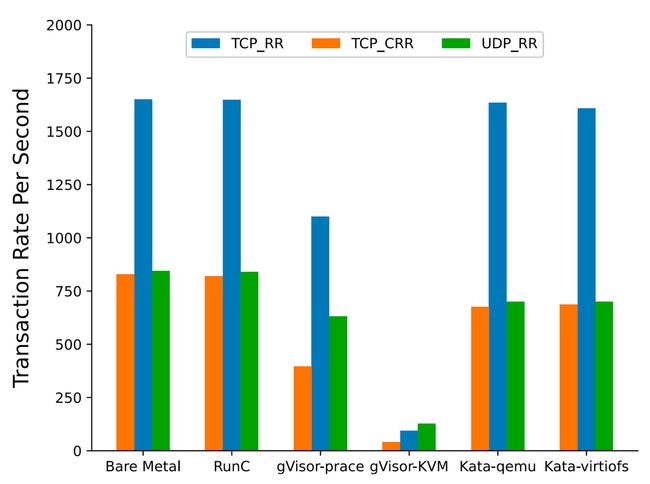
Fig. 15. TCP_RR, TCP_CRR and UDP_RR performance (Xingyu Wang 2022)
CNI Network:
容器一般搭配 k8s 使用,基于 k8s 的容器编排已经是事实上的标准,在 k8s 环境中,网络一般由 CNI + 容器技术共同实现,常见的 CNI 有很多,比较主流的有 Calico, Flannel, Cilium…,在最新的版本中 Calico 和 Cilium 都大量使用了 eBPF 的技术,虽然具体实现不同,但是这两个 CNI 在很多测试场景中性能表现相当,具体的测试数据见 [6]。
在接下来的测试中,我们选取 Cilium eBPF legacy host-routing 和 Cilium eBPF 两种模式做对比,测试 CNI 对数据库性能的具体影响。
-
·legacy host-routing:
在传统主机路由模式(legacy host-routing)下,Cilium 使用 iptables 来进行包过滤和转发,iptables 仍然是必需的,并且用于配置和管理网络流量的转发规则,Cilium 通过 iptables 规则将流量引导到 Cilium 代理,然后由代理进行处理和转发。
在传统主机路由模式下,Cilium 会利用 iptables 的 NAT 功能来修改源 IP 地址和目标 IP 地址,以实现网络地址转换(NAT)和服务负载均衡。
-
·eBPF-based host-routing:
在新的 eBPF-based 路由模式下,Cilium 不再依赖 iptables,它使用 Linux 内核的扩展 BPF(eBPF)功能来进行包过滤和转发。eBPF 主机路由允许绕过主机命名空间中的所有 iptables 和上层栈开销,以及在遍历虚拟网卡时的一部分上下文切换开销。网络数据包尽早从面向网络的网络设备中捕获,并直接传递到 Kubernetes Pod 的网络命名空间中。在出口方面,数据包仍然通过 veth pair 进行遍历,被 eBPF 捕获并直接传递到外部面向网络接口。路由表直接由 eBPF 查询,因此此优化完全透明,并与系统上运行的任何其他提供路由分发的服务兼容。
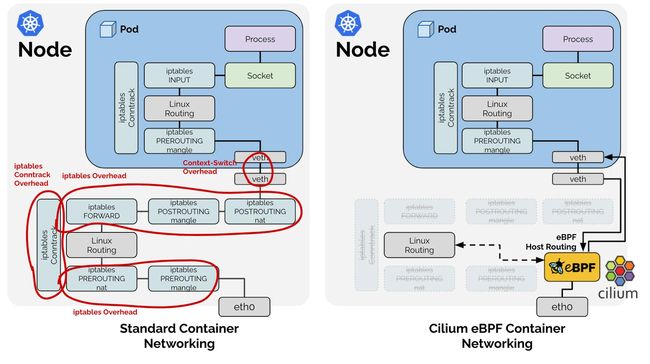
Fig. 16. Comparison of legacy and eBPF container networking [6]
测试环境:
Kubernetes: v1.25.6 CNI: cilium:v1.12.14
Node CPU: Intel® Xeon® CPU E5-2680 v4 @ 2.40GHz RAM 128G
Redis: 7.0.6, 2 vCPU, Maxmemory: 2Gi
测试场景:
Table. 2. Overview of different service routing paths in K8s
| Network | Source | Target | |
|---|---|---|---|
| NodeLocal2HostPod | Hostnetwork | Node | 本机 Pod |
| NodeLocal | Ethernet | Node | 本机进程 |
| PodLocal2Pod | Pod | Pod | 本机 Pod |
| Node2HostPod | Hostnetwork | Node | 远程 Pod |
| NodeLocal2NodePort | NodePort | Node | 本机 NodePort |
| Node2Node | Ethernet | Node | 远程进程 |
| NodeLocal2Pod | Pod | Node | 本机 Pod |
| Pod2Pod | Pod | Pod | 远程 Pod |
| Node2NodePort | NodePort | Node | 远程 NodePort |
| Pod2NodePort | Pod + NodePort | Pod | 远程 NodePort |
| Node2Pod | Pod | Node | 远程 Pod |
测试结果:
Legacy host-routing with iptables:
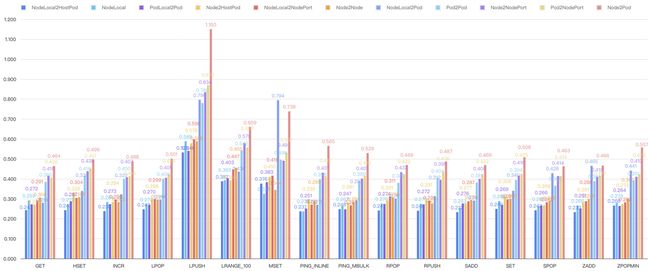
Fig. 17. Redis benchmark under legacy host-routing with iptables
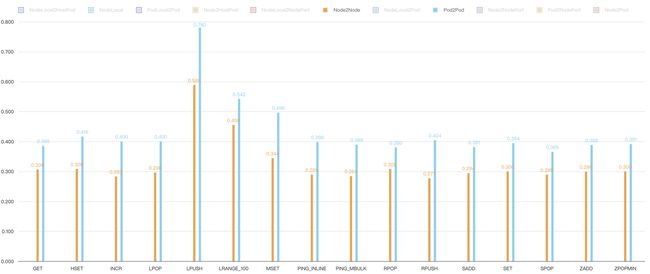
Fig. 18. Comparison between Host network and Pod network under legacy host-routing
eBPF-based host-routing
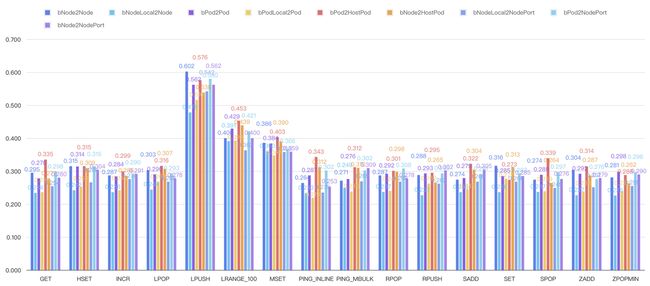
Fig. 19. Redis benchmark under eBPF-based host-routing
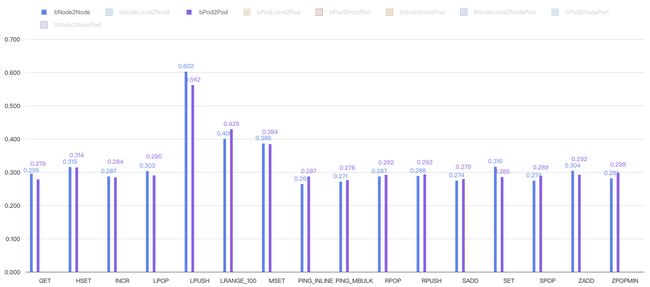
Fig. 20. Comparison between Host network and Pod network under eBPF-based host-routing
分析:legacy host-routing 对网络性能的影响较大,Pod 网络和 host 网络性能能差出 40%,eBPF-base host-routing 基本能将 Pod 网络延迟和 host 网络打平。eBPF-based host-routing 能将延迟做到和路由规则数量无关,并彻底消除 host 网络和 Pod 网络之间的差距,是一种普适性的提升,当然也非常适合 redis 之类的重网络 I/O 应用。
总结:
在 CPU、内存和 Disk I/O 几个维度,runc 的性能最接近 bare metal,kata-containers 性能略低于 runc,但是在安全性和隔离性上有更好的表现,gVisor 由于受 syscall 实现的影响,性能表现最差,这可能和 gVisor 更关注安全特性有关,不过 gVisor 新版本也在一直不断提升性能。
网络比较特殊,因为还需要考虑 k8s CNI 的影响,在 Cilium eBPF + runc 的组合测试中,容器网络能够做到和 Host 网络一样的性能,Cilium 也支持 kata-containers,不过对其他容器技术的支持较少。
总体而言,runc 在各个层面都能达到和裸金属相当的性能表现,也是目前 k8s workload 最常用的选择;kata-containers 性能略低于 runc,但是有比较好的隔离性,是性能和安全都能兼顾的一种选择;gVisor 有比较灵活的隔离性,但是性能还比较差,比较适合对安全性要求很高,对性能要求不那么苛刻的场景;Firecracker 的应用场景和 kata-containers 比较类似。
所以,如果是跑数据库的 workload,优先推荐 runc 和 kata-containers。
常见的数据库性能问题:
很多人常常受数据库性能问题的困扰,在此,我们对常见的数据库性能问题场景做了总结和原理分析,也可以让大家一窥数据库和基础设施的复杂性以及我们努力的方向。
Disk IO hang:
当有大量 BufferedIO 下发时,比如 MySQL 写外排临时文件的场景,写的是 page cache,并会频繁更新 Ext4 文件系统的元数据,此时 CPU 和 I/O 可能都会很忙,MySQL 进程会被频繁 CPU Throttle,脏页持续增多,然后触发文件系统 flush 脏页,大量刷脏 I/O占满硬件通道,如果进程被 CPU Throttle 调度走时又恰巧持有了 Ext4 Journal Lock,那么其他共享该 Ext4 文件系统的进程都被挂起,当被挂起的次数和时间足够久,就会造成 IO hang,这种现象常见于共享本地盘的场景,如 bare metal 和 hostpath CSI。主流的解决方案就是给 BufferedIO 限流,Cgroup V2 已支持该功能。
通过这个例子也可以看出,有时候瓶颈并不是某个单项因素所决定的,是由多个关联的因素联动产生,在 Disk IO hang 中,page cache 和内存、Disk I/O 相关,CPU Throttle 和 CPU 调度相关,Ext4 Journal 又和 Lock 有关,所以这些因素共同作用、互相影响才形成了一个完整的 IO hang。
值得一提的是,为了优化 I/O 操作,很多数据库厂商都推荐将 XFS 作为文件系统的第一选择。对于 Disk I/O 对数据库的深度影响,可以参考《PosgreSQL@k8s 性能优化记》[7]。
Out Of Memory (OOM):
当使用 Cgroup 对内存进行隔离后,OS 的内存管理路径会和 bare metal 变得不同,在内存分配(page allocation)和内存回收(page reclaim)上面临的压力会比 bare metal 更高。
比如有一个 Pod,内存 request 和 limit 都为 1G ,内存的分配和回收都要在 1G 的物理内存空间内进行,而数据库又是一个对内存资源要求比较高的负载类型,仅仅启动一个空的数据库进程可能就要消耗数百兆的内存,所以其实留给实际应用的空间非常小,此时如果再搭配上监控或日志采集之类的 sidecar,数据库内存耗尽的概率就会非常高。
但是真正可怕的并不是 OOM,而是在 OOM 之前慢慢步入死亡的过程,这个过程可能会无比漫长,在真正触发 OOM 之前,page reclaim 模块会尝试一切办法去回收足够的内存,并调用耗时很久的 slow path,然后一遍又一遍地重复整个过程,直到超过限定次数退出,在这个过程中数据库客户端可能会观测到大量事务超时退出。
Page reclaim slow path 还不仅仅影响一个 Cgroup Namespace,由于 OS 中的很多数据结构在 Host 这一层是共享的, 比如虽然 Pod 内存逻辑上属于某个 Cgroup Namespace,但是在 Host Kernel 中,真实的内存管理还是基于同一个 Buddy System,对这些物理内存的管理需要全局的锁机制,所以一个内存压力很大的 Pod 触发的 page reclaim slow path 也会影响其它健康 Pod 的内存管理路径,有的时候整个 Node 上的数据库都变慢可能只是因为有一个 Pod 的 limit 内存太小了。
彻底解决此类问题就需要一些更高级别的隔离方案,比如基于微内核或 VM 的隔离方案,让两个 Pod 属于不同的内存管理空间;还有一种改进方案是当内存回收变得不可避免时,尽量在数据库的层面对各种运行指标进行判断,做到 fail fast。
Too many Connections:
对于 OLTP 数据库,一般都有专属的预分配的 buffer pool,这部分内存相对是固定的,可变的部分主要来自 Connection 结构体、work mem 中间计算结果、页表、page cache 等。
对于多进程模型的数据库如 Postgresql 和 Oracle,一条 Connection 对应一个进程,当使用的 buffer pool 本身就很大时,fork 一个进程所需的页表项也非常可观,假设 page 4k,页表项 8 字节,那么页表和 buffer pool 的比例关系是 8/4k = 1/512,当有 512 条链接时,OS 需要的页表内存就和 buffer pool 一样大,这种多进程模型严重影响了数据库的扩展性,在需要大并发量的场景会有比较高的额外内存成本,但是这种成本一般很容易被人忽略。
解决方案一般分为两种,一是在数据库前面增加一层 proxy,通过 proxy 来承接大量的链接,proxy 和数据库之间只建立比较少的链接,比如 proxy 和后端 db 之间只建立 P 条链接,proxy 从应用侧承接 C 条链接(C >> P),通过这种链接复用来降低后端 db 的链接压力;还有一种是采用 Hugepage 的方案,假设 Hugepage size 为 2M,那么页表和 buffer pool 的比例关系就是 8/2M = 1/256k,页表成本几乎可以忽略不计,多进程模型可承载的链接数也大大增加,但是 Hugepage 也是一种副作用很多的技术方案,给资源管理也带来了不小的负担。所以 proxy 方案一般是更友好的选择。
多线程模型又分两种,一种是一个 Connection 对应一个线程,当 Connection 增多时虽然没有页表 copy 的问题,但是也会导致资源争抢、context switch 过多等问题,这些问题又会导致性能持续恶化,当然这种问题也可以通过加 proxy 来解决;一种是 C 条链接对应 P 个线程(C >> P),这种方案一般叫作线程池(Thread Pool),比如 Percona MySQL 就采用了此类方案。
Proxy 和 Thread Pool 本质上是相同的,都是做链接复用,只是实现的地方不同,而且这两个方案也可以搭配使用,进一步提升容量和降低负载。
Table. 3. Overview of different database process-connection models
| 链接数:进程数 | 页表 | 备注 | ||
|---|---|---|---|---|
| 多进程 | Proxy | C:P | *P | C >> P |
| 多进程 | 直连 | C:C | *C | |
| 多线程 | Thread Pool | C:P | *1 | C >> P |
| 多线程 | Per Thread | C:C | *1 |
TCP Retran:
网络对数据库的影响主要体现在两个方面:
延迟:网络延迟会影响数据的传输时长,进而会影响客户端的整体响应时间,当客户侧的请求延迟变高时,单位时间内完成相同请求数量所需要的链接数会变多,客户端链接数变多又会导致内存消耗变大、context switch 变多、争抢更加剧烈,最终导致性能的逐步下降。
带宽:无论是单个 TCP 链接的有效带宽,还是网卡和交换机网口的最大传输带宽,都对网络传输质量和延迟有重大的影响,当某个 TCP 链接、交换机网口或网卡队列变得拥塞时,会在 OS Kernel 或硬件层面触发丢包行为,丢包又会触发重传和乱序,重传和乱序又导致延迟上升,进而引发后续一系列的性能问题。
网络问题触发的不仅是性能问题,还有可用性和稳定性的问题,比如因网络延迟过大心跳超时导致的主备切换、主备之间的复制延迟过大等问题。
CPU schedule wait:
在一些基于 VM 的容器化方案中,容器中的进程和 Host Kernel 中的进程并不是能一一对应的,在 Host Kernel 看来,看到的只有 VM 虚拟化相关的进程,当你在 VM 内部看到一个 process 处于 running 状态,并不意味着它已经在Host 上获取到资源并运行,Host 和 VM 是两套独立的 CPU 调度系统,只有当 VM 内部 process 处于就running 并且所在 Host 上对应的 VM process 也处于 running 状态时,VM 内部 process 才真正得到运行。
从 process 变成 running 状态到真正被执行到的这段时间就是额外的调度等待时间,这个等待时间对数据库的性能也会产生影响,对性能要求比较苛刻的场景可以采取降低 Host 负载或设置 VM CPU affinity 的方法来降低影响。
Lock & Latch:
在数据库领域,Lock 一般保护的是资源(Resource),Latch 保护的是临界区(Critical Region),但是两种技术最终在 OS 层面的内部实现是相同的,在 Linux 中,一般用 futex 来实现上层的互斥锁和等待变量。
当 CPU、I/O、内存都无限供应的时候,数据库的扩展性一般受限于自己内部的事务+锁机制,比如在 TPC-C 测试中,大部分单机数据库的扩展性一般都在 32 Core (64 Hyper Threads) ~ 64 Core (128 Hyper Threads) 之间,超过 32 Core 之后,CPU 数量对数据库性能的边际贡献会非常低。
这个话题和容器的关系不是那么密切,所以在本文中也就不做展开。
几种数据库的性能瓶颈分析:
Table. 4. Overview of different database performance bottlenecks
| 存储引擎 | Disk I/O | I/O unit | 进程模型 | 性能瓶颈 | |
|---|---|---|---|---|---|
| MySQL | InnoDB | DirectIO + BufferedIO | Page | 多线程 | I/O bandwidth + Lock + Connections |
| PostgreSQL | HeapTable | BufferedIO | Page | 多进程 | I/O bandwidth + Lock + Connections |
| MongoDB | WiredTiger | BufferedIO/DirectIO | Page | 多线程 | I/O bandwidth + Lock + Connections |
| Redis | RDB + Aof | BufferedIO | Key-Value | 单线程* | CPU Sys(网络) |
- MySQL 需要特别关注外排临时文件,由于临时文件使用的是 BufferedIO,如果没有 Cgroup 限制,会很快触发 OS 大量的脏页刷脏,这个刷脏过程会占用存储设备的几乎所有通道,造成正常请求卡住,这种现象是比较经典的 Disk IO hang。
- PostgreSQL 是多进程模式,所以需要十分关注链接数和页表大小,虽然使用 Hugepage 方案可以降低页表的负担,但是 Hugepage 本身还是有比较多的副作用,利用 pgBouncer 之类的 proxy 做链接复用是一种更好的解法;当开启 full page 时,PostgreSQL 对 I/O 带宽的需求非常强烈,此时的瓶颈为 I/O 带宽;当 I/O 和链接数都不是瓶颈时,PostgreSQL 在更高的并发下瓶颈来自内部的锁实现机制。具体可以参考《Postgresql@k8s 性能优化记》[7]。
- MongoDB 整体表现比较稳定,主要的问题一般来自 Disk I/O 和链接数,WiredTiger 在 cache 到 I/O 的流控上做得比较出色,虽然有 I/O 争抢,但是 IO hang 的概率比较小,当然 OLTP 数据库的 workload 会比 MongoDB 更复杂一些,也更难达到一种均衡。
- Redis 的瓶颈主要在网络,所以需要特别关注应用和 Redis 服务之间的网络延迟,这部分延迟由网络链路决定,Redis 满载时 70%+ 的 CPU 消耗在网络栈上,所以为了解决网络性能的扩展性问题,Redis 6.0 版本引入了网络多线程功能,真正的 worker thread 还是单线程,这个功能在大幅提升 Redis 性能的同时也保持了 Redis 简单优雅的特性。
总结:
本文在综合业界研究成果的基础上,补足了容器 + 网络 CNI 部分的测试,对容器化在 CPU、Memory、Disk I/O、Network 几个方面的影响做了进一步的分析,借机阐明了容器化对性能的影响机制和解决方法,并且通过分析测试数据,我们发现 runc + cilium eBPF 是一种和 bare metal 性能几乎持平的容器化方案,如果考虑到更好的安全性和隔离性,kata-containers 也是一种很好的选择。
然后在容器化的基础上,对数据库的常见的性能瓶颈做了原理分析,并指出数据库这种 heavy workload 对 Host kernel 的复杂依赖,引导人们重新关注页表、Journal Lock、TCP Retran、CPU schedule wait 这些容易被忽视的因素,当然这里的很多问题和容器化无关,是一种普遍的存在。最后我们对几款流行的数据库做了定性分析,也根据我们团队多年的运维经验对一些常见问题做了总结,希望这些问题能被持续关注并从架构层面得到解决。
数据库容器化是最近经常被提起的话题,to be or not to be 也是萦绕在每个决策者心中的问题,在我们看来,数据库容器化面临的性能、稳定性、有状态依赖等关键问题都在被一一解决,每个问题都会有一个完美的答案,只要有需求在。
参考文献
[1] Wang, Xing et al. “Performance and isolation analysis of RunC, gVisor and Kata Containers runtimes.” Cluster Computing 25 (2022): 1497-1513.
[2] Goethals, Tom et al. “A Functional and Performance Benchmark of Lightweight Virtualization Platforms for Edge Computing.” 2022 IEEE International Conference on Edge Computing and Communications (EDGE) (2022): 60-68.
[3] Espe, Lennart et al. “Performance Evaluation of Container Runtimes.” International Conference on Cloud Computing and Services Science (2020).
[4] https://www.datadoghq.com/container-report/
[5] https://www.reddit.com/r/kubernetes/comments/x75sb4/kube_container_performance_crio_vs_containerd/
[6] https://cilium.io/blog/2021/05/11/cni-benchmark/
[7] Postgresql@k8s 性能优化记:https://mp.weixin.qq.com/s/0kbWa6AnkCr5jkN4WIgu5Q