大数据组件笔记 -- Spark 入门
文章目录
- 一、简介
- 二、Spark 运行模式
-
- 2.1 本地模式
- 2.2 集群角色
- 2.3 Standalone 模式
- 2.4 Yarn模式
- 2.5 总结
- 三、WordCount 开发案例实操
一、简介
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
- Spark 历史

Spark 虽然有自己的资源调度框架,但实际中常用 Yarn 来进行统一资源管理。
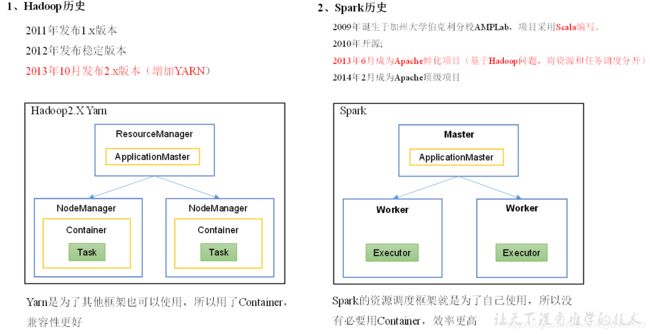
- Spark 框架

- Spark内置模块

- Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
- Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
- Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。 - Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。
- 集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。
- Spark特点
- 快:与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中的。
- 易用:Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的Shell,可以非常方便地在这些Shell中使用Spark集群来验证解决问题的方法。
- 通用:Spark提供了统一的解决方案。Spark可以用于,交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。减少了开发和维护的人力成本和部署平台的物力成本。
- 兼容性:Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。
二、Spark 运行模式
- 部署Spark集群大体上分为两种模式:单机模式与集群模式
大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。但是在生产环境中,并不会使用单机模式。因此,后续直接按照集群模式部署Spark集群。
- Local模式:在本地部署单个Spark服务
- Standalone模式:Spark自带的任务调度模式。(国内常用)
- YARN模式:Spark使用Hadoop的YARN组件进行资源与任务调度。(国内常用)
- Mesos模式:Spark使用Mesos平台进行资源与任务的调度。
2.1 本地模式
- 安装
[omm@bigdata01 soft]$ tar -zxf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
[omm@bigdata01 soft]$ cd ../module/
[omm@bigdata01 module]$ mv spark-2.1.1-bin-hadoop2.7 spark-local
spark-submit
[omm@bigdata01 spark-standalone]$ bin/spark-submit
Usage: spark-submit [options] <app jar | python file> [app arguments]
Usage: spark-submit --kill [submission ID] --master [spark://...]
Usage: spark-submit --status [submission ID] --master [spark://...]
Usage: spark-submit run-example [options] example-class [example args]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of local jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor.
--conf PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Spark standalone with cluster deploy mode only:
--driver-cores NUM Cores for driver (Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
--principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to
the node running the Application Master via the Secure
Distributed Cache, for renewing the login tickets and the
delegation tokens periodically.
[omm@bigdata01 spark-standalone]$
- 官方求PI案例
[omm@bigdata01 spark-local]$ pwd
/opt/module/spark-local
[omm@bigdata01 spark-local]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.11-2.1.1.jar \
10
...
Pi is roughly 3.1397911397911398
...
[omm@bigdata01 spark-local]$
--class:表示要执行程序的主类;--master local[2]
2.1local: 没有指定线程数,则所有计算都运行在一个线程当中,没有任何并行计算
2.2local[K]:指定使用K个Core来运行计算,比如local[2]就是运行2个Core来执行
2.3local[*]: 自动帮你按照CPU最多核来设置线程数。比如CPU有4核,Spark帮你自动设置4个线程计算。spark-examples_2.11-2.1.1.jar:要运行的程序;10:要运行程序的输入参数(计算圆周率π的次数,计算次数越多,准确率越高);
- WordCount 案例
- 模拟数据
[omm@bigdata01 mr]$ pwd
/opt/module/datas/mr
[omm@bigdata01 mr]$ cat mr1.txt
hello july
hello september
hello november
hello july
[omm@bigdata01 mr]$ cat mr2.txt
hallo monday
hallo friday
hallo freitag
hallo sonntag
[omm@bigdata01 mr]$
- Spark Shell
[omm@bigdata01 spark-local]$ bin/spark-shell
Spark context Web UI available at http://192.168.1.101:4040
Spark context available as 'sc' (master = local[*], app id = local-1616811495360).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_271)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
sc是SparkCore程序的入口;spark是SparkSQL程序入口;master = local[*]表示本地模式运行。
scala> sc.textFile("/opt/module/datas/mr/").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((hallo,4), (november,1), (july,2), (freitag,1), (hello,4), (monday,1), (sonntag,1), (friday,1), (september,1))
scala>
2.2 集群角色
- Master和Worker

- Driver和Executor

- 通用运行流程
- Master和Worker是Spark的守护进程,即Spark在特定模式下正常运行所必须的进程。
- Driver和Executor是临时程序,当有具体任务提交到Spark集群才会开启的程序。
2.3 Standalone 模式
Standalone模式是Spark自带的资源调动引擎,构建一个由Master + Slave构成的Spark集群,Spark运行在集群中。
这个要和Hadoop中的Standalone区别开来。这里的Standalone是指只用Spark来搭建一个集群,不需要借助其他的框架。是相对于Yarn和Mesos来说的。
- 安装
[omm@bigdata01 ~]$ tar -zxf /opt/soft/spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
[omm@bigdata01 ~]$ mv /opt/module/spark-2.1.1-bin-hadoop2.7 /opt/module/spark-standalone
[omm@bigdata01 ~]$ cd /opt/module/spark-standalone/
[omm@bigdata01 spark-standalone]$ cp conf/slaves.template conf/slaves
[omm@bigdata01 spark-standalone]$ vi conf/slaves
[omm@bigdata01 spark-standalone]$ cat conf/slaves
bigdata01
bigdata02
bigdata03
[omm@bigdata01 spark-standalone]$
[omm@bigdata01 spark-standalone]$ cp conf/spark-env.sh.template conf/spark-env.sh
[omm@bigdata01 spark-standalone]$ vi conf/spark-env.sh
[omm@bigdata01 spark-standalone]$ cat conf/spark-env.sh
#!/usr/bin/env bash
SPARK_MASTER_HOST=bigdata01
SPARK_MASTER_PORT=7077
[omm@bigdata01 spark-standalone]$
[omm@bigdata01 spark-standalone]$ vi sbin/spark-config.sh
[omm@bigdata01 spark-standalone]$ tail -1 sbin/spark-config.sh
export JAVA_HOME=/opt/module/jdk
[omm@bigdata01 spark-standalone]$ cd ..
[omm@bigdata01 module]$ xsync spark-standalone # !! 分发
[omm@bigdata01 module]$
[omm@bigdata01 spark-standalone]$ sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-standalone/logs/spark-omm-org.apache.spark.deploy.master.Master-1-bigdata01.out
bigdata03: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-omm-org.apache.spark.deploy.worker.Worker-1-bigdata03.out
bigdata01: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-omm-org.apache.spark.deploy.worker.Worker-1-bigdata01.out
bigdata02: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-omm-org.apache.spark.deploy.worker.Worker-1-bigdata02.out
[omm@bigdata01 spark-standalone]$ grep MasterWebUI logs/spark-omm-org.apache.spark.deploy.master.Master-1-bigdata01.out
21/03/27 11:58:44 INFO MasterWebUI: Bound MasterWebUI to 0.0.0.0, and started at http://192.168.1.101:8081
[omm@bigdata01 spark-standalone]$
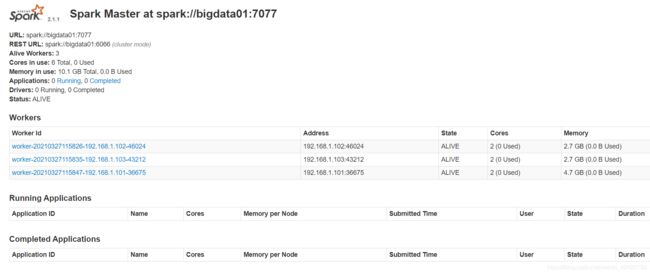
- 官方PI案例
[omm@bigdata01 spark-standalone]$ bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master spark://bigdata01:7077 \
> ./examples/jars/spark-examples_2.11-2.1.1.jar \
> 10
...
Pi is roughly 3.141959141959142
...
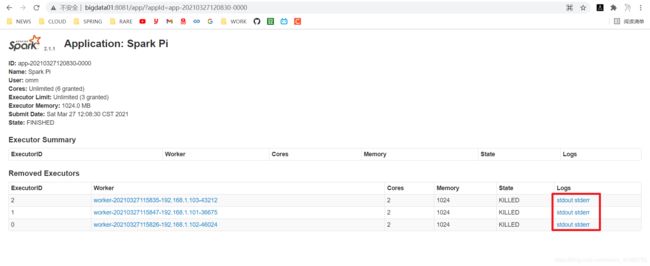
- 安装历史服务器
[omm@bigdata01 conf]$ cp spark-defaults.conf.template spark-defaults.conf
[omm@bigdata01 conf]$ vi spark-defaults.conf
[omm@bigdata01 conf]$ cat spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://bigdata01:8020/spark/history
[omm@bigdata01 conf]$ xsync spark-defaults.conf
[omm@bigdata01 conf]$ hdfs dfs -mkdir -p /spark/history
[omm@bigdata01 conf]$ vi spark-env.sh
[omm@bigdata01 conf]$ cat spark-env.sh
#!/usr/bin/env bash
SPARK_MASTER_HOST=bigdata01
SPARK_MASTER_PORT=7077
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://bigdata01:8020/spark/history
-Dspark.history.retainedApplications=30"
[omm@bigdata01 conf]$ xsync spark-env.sh
[omm@bigdata01 conf]$
[omm@bigdata01 spark-standalone]$ sbin/start-all.sh
[omm@bigdata01 spark-standalone]$ sbin/start-history-server.sh
[omm@bigdata01 spark-standalone]$ jps
5330 Worker
1620 NodeManager
3270 RunJar
1832 NameNode
5225 Master
5401 HistoryServer
5449 Jps
1994 DataNode
3132 RunJar
3532 QuorumPeerMain
[omm@bigdata01 spark-standalone]$
再次运行任务,并查看历史服务器。

- 配置高可用(HA)
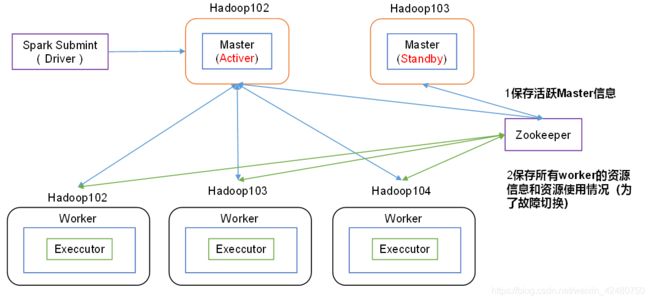
- 修改配置文件
[omm@bigdata01 conf]$ pwd
/opt/module/spark-standalone/conf
[omm@bigdata01 conf]$ vi spark-env.sh
[omm@bigdata01 conf]$ cat spark-env.sh
#!/usr/bin/env bash
# SPARK_MASTER_HOST=bigdata01
# SPARK_MASTER_PORT=7077
# 配置由Zookeeper管理Master,在Zookeeper节点中自动创建/spark目录,用于管理:
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=bigdata01,bigdata02,bigdata03
-Dspark.deploy.zookeeper.dir=/spark"
# Zookeeper3.5的AdminServer默认端口是8080,和Spark的WebUI冲突
export SPARK_MASTER_WEBUI_PORT=8989
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://bigdata01:8020/spark/history
-Dspark.history.retainedApplications=30"
[omm@bigdata01 conf]$ xsync spark-env.sh
[omm@bigdata01 conf]$
- 启动集群及备Master
[omm@bigdata01 spark-standalone]$ sbin/start-all.sh
[omm@bigdata02 spark-standalone]$ sbin/start-master.sh
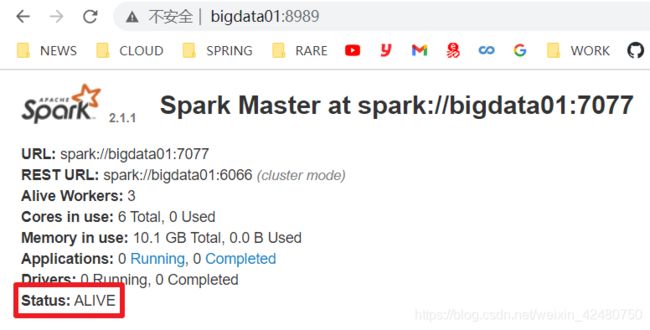
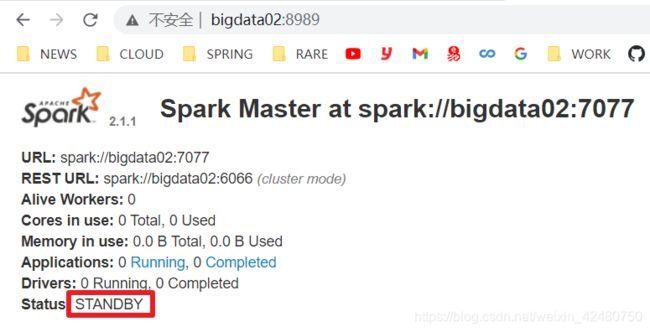
- 高可用方式执行 WordCount
# 准备数据(高可用数据应放在HDFS)
hdfs dfs -mkdir -p /spark/data/input
hdfs dfs -put /opt/module/datas/mr/* /spark/data/input/
# 登录spark-shell
[omm@bigdata01 spark-standalone]$ bin/spark-shell \
> --master spark://bigdata01:7077,bigdata02:7077 \
> --executor-memory 2g \
> --total-executor-cores 2
# 执行
scala> sc.textFile("hdfs://bigdata01:8020/spark/data/input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((hallo,4), (november,1), (july,2), (freitag,1), (hello,4), (monday,1), (sonntag,1), (friday,1), (september,1))
scala>
- 测试高可用主备切换
[omm@bigdata01 spark-standalone]$ jps
6306 Worker
6835 Jps
1620 NodeManager
3270 RunJar
6198 Master
1832 NameNode
5401 HistoryServer
1994 DataNode
3132 RunJar
3532 QuorumPeerMain
[omm@bigdata01 spark-standalone]$ kill 6198
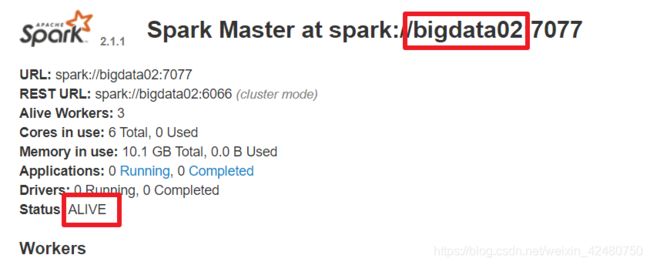
- 运行模式
Spark有standalone-client和standalone-cluster两种模式,主要区别在于:Driver程序的运行节点。
- 客户端模式
--deploy-mode client,表示Driver程序运行在本地客户端
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077,hadoop103:7077 \
--executor-memory 2G \
--total-executor-cores 2 \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
10

- 集群模式模式
--deploy-mode cluster,表示Driver程序运行在集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077,hadoop103:7077 \
--executor-memory 2G \
--total-executor-cores 2 \
--deploy-mode cluster \
./examples/jars/spark-examples_2.11-2.1.1.jar \
10

查看http://hadoop102:8989/页面,点击Completed Drivers里面的Worker
![]()
跳转到Spark Worker页面,点击Finished Drivers中Logs下面的stdout

最终打印结果如下

2.4 Yarn模式
Spark客户端直接连接Yarn,不需要额外构建Spark集群。
- 安装使用
- 停止 Stand alone 集群
[omm@bigdata01 spark-standalone]$ sbin/stop-all.sh
[omm@bigdata01 spark-standalone]$ sbin/stop-history-server.sh
[omm@bigdata02 spark-standalone]$ sbin/stop-master.sh
[omm@bigdata01 spark-standalone]$ /opt/module/zookeeper/bin/zkServer.sh stop
[omm@bigdata02 spark-standalone]$ /opt/module/zookeeper/bin/zkServer.sh stop
[omm@bigdata03 spark-standalone]$ /opt/module/zookeeper/bin/zkServer.sh stop
- 准备软件包
[omm@bigdata01 ~]$ tar -zxf /opt/soft/spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
[omm@bigdata01 ~]$ ln -s /opt/module/spark-2.1.1-bin-hadoop2.7 /opt/module/spark
- 因为测试环境虚拟机内存较少,防止执行过程进行被意外杀死,做如下配置
[omm@bigdata01 spark]$ vi /opt/module/hadoop/etc/hadoop/yarn-site.xml
[omm@bigdata01 spark]$ tail -15 /opt/module/hadoop/etc/hadoop/yarn-site.xml
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
[omm@bigdata01 spark]$ cd /opt/module/hadoop/etc/hadoop/
[omm@bigdata01 hadoop]$ xsync yarn-site.xml
[omm@bigdata01 hadoop]$
- 添加YARN_CONF_DIR配置,保证后续运行任务的路径都变成集群路径
[omm@bigdata01 spark]$ cp conf/spark-env.sh.template conf/spark-env.sh
[omm@bigdata01 spark]$ vi conf/spark-env.sh
[omm@bigdata01 spark]$ cat conf/spark-env.sh
#!/usr/bin/env bash
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
[omm@bigdata01 spark]$
- 启动HDFS以及YARN
[omm@bigdata01 ~]$ start-dfs.sh
[omm@bigdata02 ~]$ start-yarn.sh
- 提交Yarn任务
[omm@bigdata01 spark]$ bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master yarn \
> ./examples/jars/spark-examples_2.11-2.1.1.jar \
> 10
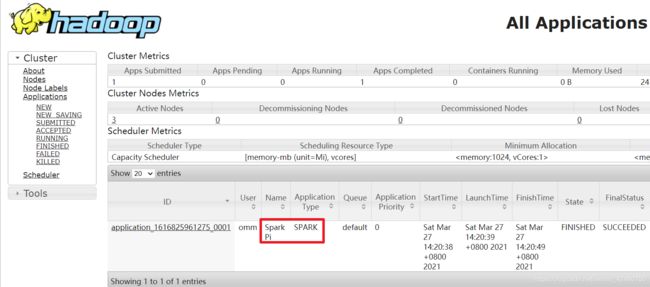
如果运行的时候,抛出如下异常:ClassNotFoundException:com.sun.jersey.api.client.config.ClientConfig
# -原因分析
# Spark2中jersey版本是2.22,但是yarn中还需要依赖1.9,版本不兼容
# -解决方式
# 在yarn-site.xml中,添加
<property>
<name>yarn.timeline-service.enabled</name>
<value>false</value>
</property>
- 配置历史服务
由于spark-shell停止掉后,hadoop102:4040页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
[omm@bigdata01 spark]$ cp conf/spark-defaults.conf.template conf/spark-defaults.conf
[omm@bigdata01 spark]$ vi conf/spark-defaults.conf
[omm@bigdata01 spark]$ cat conf/spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://bigdata01:8020/spark/history
spark.yarn.historyServer.address=bigdata01:18080
spark.history.ui.port=18080
[omm@bigdata01 spark]$
[omm@bigdata01 spark]$ vi conf/spark-env.sh
[omm@bigdata01 spark]$ cat conf/spark-env.sh
#!/usr/bin/env bash
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://bigdata01:8020/spark/history
-Dspark.history.retainedApplications=30"
[omm@bigdata01 spark]$ sbin/start-history-server.sh
[omm@bigdata01 spark]$ bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master yarn \
> ./examples/jars/spark-examples_2.11-2.1.1.jar \
> 10

- 运行流程
- Spark有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出。
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
10

yarn-cluster:Driver程序运行在由ResourceManager启动的APPMaster适用于生产环境。
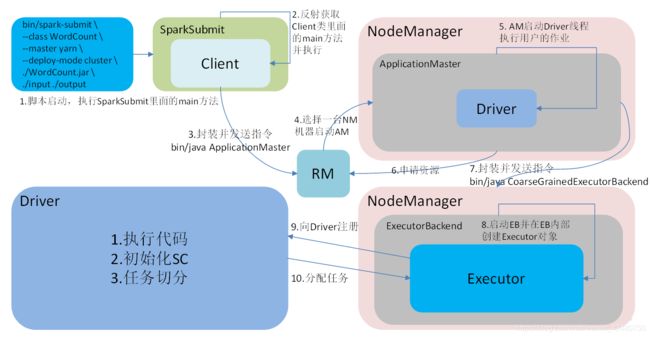
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.11-2.1.1.jar \
10
http://bigdata02:8088/cluster。
注意:hadoop历史服务器也要启动
mr-jobhistory-daemon.sh start historyserver
注意:hadoop历史服务器也要启动
mapred --daemon start historyserver



2.5 总结
- Mesos模式(了解)
Spark客户端直接连接Mesos;不需要额外构建Spark集群。国内应用比较少,更多的是运用Yarn调度。
- 几种模式对比
| 模式 | Spark安装机器数 | 需启动的进程 | 所属者 |
|---|---|---|---|
| Local | 1 | 无 | Spark |
| Standalone | 3 | Master及Worker | Spark |
| Yarn | 1 | Yarn及HDFS | Hadoop |
- 端口号总结
- Spark历史服务器端口号:18080 (类比于Hadoop历史服务器端口号:19888)
- Spark Master Web端口号:8080(类比于Hadoop的NameNode Web端口号:9870(50070))
- Spark Master内部通信服务端口号:7077 (类比于Hadoop的8020(9000)端口)
- Spark查看当前Spark-shell运行任务情况端口号:4040
- Hadoop YARN任务运行情况查看端口号:8088
- Hadoop HDFS:9870
三、WordCount 开发案例实操
- BOM
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.1.1version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.4.6version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
log4j.properties
# !!! /opt/module/spark/conf/log4j.properties
# Set everything to be logged to the console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
- 业务逻辑
package com.simwor.bigdata.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//1. 创建SparkConf配置文件
val conf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
//2. 创建SparkContext对象
val sc: SparkContext = new SparkContext(conf)
//3. 读取指定
//val textRDD: RDD[String] = sc.textFile("E:\\BUFFER\\IdeaProjects\\bigdata2021\\spark\\input")
val textRDD: RDD[String] = sc.textFile(args(0))
//4. 编写业务逻辑
textRDD.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile(args(1))
//5. 关闭资源
sc.stop()
}
}
- 打包插件
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>3.0.0version>
<configuration>
<archive>
<manifest>
<mainClass>com.simwor.bigdata.spark.WordCountmainClass>
manifest>
archive>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
- 提交YARN任务
[omm@bigdata01 jars]$ pwd
/opt/module/spark/jars
[omm@bigdata01 jars]$ ll | grep WordCount.jar
-rw-rw-r-- 1 omm omm 7460 Mar 27 17:06 WordCount.jar
[omm@bigdata01 spark]$ bin/spark-submit \
> --class com.simwor.bigdata.spark.WordCount \
> --master yarn \
> jars/WordCount.jar \
> /spark/data/input \
> /spark/data/output
[omm@bigdata01 spark]$
- 查看输出结果
[omm@bigdata01 spark]$ hdfs dfs -ls /spark/data/output
Found 3 items
-rw-r--r-- 3 omm supergroup 0 2021-03-27 17:13 /spark/data/output/_SUCCESS
-rw-r--r-- 3 omm supergroup 77 2021-03-27 17:13 /spark/data/output/part-00000
-rw-r--r-- 3 omm supergroup 25 2021-03-27 17:13 /spark/data/output/part-00001
[omm@bigdata01 spark]$ hdfs dfs -cat /spark/data/output/part-00000
(hallo,4)
(november,1)
(july,2)
(freitag,1)
(hello,4)
(monday,1)
(sonntag,1)
[omm@bigdata01 spark]$