Java基础面试问题总结
Java面向对象的四个基本特征?
- 抽象,先不考虑细节
- 封装,隐藏内部实现
- 继承,复用现有代码
- 多态,改写对象行为
多态的理解?
- 方法重载 overload 实现编译时的多态性
- 方法重写 override 实现运行时的多态性
- 子类继承并重写父类的抽象方法,使用父类型引用子类型对象,同样的引用调用同样的方法会根据子类的实际对象的不同而表现出不同的行为
重载(Overload)和重写(Override)的区别是什么?
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。
- 重写发生在子类与父类之间, 重写方法返回值和形参都不能改变,与方法返回值和访问修饰符无关。即外壳不变,核心重写!
- 重载(overloading) 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。每个重载的方法(或者构造函数)都必须有一个独一无二的参数类型列表。最常用的地方就是构造器的重载。
如何确定引用变量调用的方法是谁的方法
- 先看方法是哪个类定义的,如果是属于父类定义的,就到父类中找,如果是属于子类定义的,就到子类去找对应的方法
- 再看方法有没有被重写,如果是父类定义的,1)看引用变量实际如果是子类对象的话,那么继续到子类中找是否被重写,如果有被重写,就是重写的方法,如果没有被重写,就还是父类的方法,2)看引用变量实际如果是当前类(没有引用子类对象),那么就是当前类中定义的方法
Java语言有哪些特点?
- 面向对象(抽象、封装,继承,多态);
- 平台无关性,平台无关性的具体表现在于,Java 是“一次编写,到处运行(Write Once,Run any Where)”的语言,因此采用 Java 语言编写的程序具有很好的可移植性,而保证这一点的正是 Java 的虚拟机机制。在引入虚拟机之后,Java 语言在不同的平台上运行不需要重新编译。
- 可靠性、安全性;
- 支持多线程。C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持;支持网络编程并且很方便。
- Java 语言诞生本身就是为简化网络编程设计的,因此 Java 语言不仅支持网络编程而且很方便;
- 编译与解释并存;
面向对象六个基本原则?
- 单一职责原则(SRP) 对于一个类,有且仅有一个引起它变化的原因。
- 开放封闭原则(OCP) 一个软件实体应该对扩展开放,对修改关闭。
- 里氏替换原则(LSP) 所有引用基类(父类)的地方必须能透明地使用其子类的对象。
- 依赖倒置原则(DIP) 高层模块不应依赖低层模块,两个都应依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
- 接口隔离原则(ISP) 一个类对另一个类的依赖应该建立在最小的接口上,客户端不应该依赖它不需要的接口。
- 迪米特法则(LOD) 一个软件实体应当尽可能少地与其他实体发生相互作用。
S O L I D + 迪米特
- S:单一
- O:开闭
- L:里氏替换
- I:接口隔离
- D:依赖倒置
什么是字节码?
Java之所以可以“一次编译,到处运行”,一是因为 JVM 针对各种操作系统、平台都进行了定制,二是因为无论在什么平台,都可以编译生成固定格式的字节码(.class文件)供JVM使用。因此,也可以看出字节码对于Java生态的重要性。
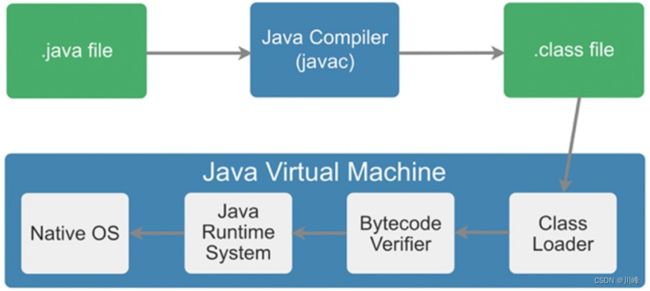
之所以被称之为字节码,是因为字节码文件由十六进制值组成,而 JVM 以两个十六进制值为一组,即以字节为单位进行读取。在Java中一般是用 javac 命令编译源代码为字节码文件,一个.java文件从编译到运行的示例如图所示。
采用字节码的好处是什么?
Java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以Java程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同的计算机上运行。
Java有哪些数据类型?
Java 语言的数据类型分为两种:基本数据类型和引用数据类型。
- 基本数据类型包括 boolean(布尔型)、float(单精度浮点型)、char(字符型)、byte(字节型)、short(短整型)、int(整型)、long(长整型)和 double (双精度浮点型)共 8 种,如下表所示。

对于 boolean,官方文档未明确定义,它依赖于 JVM 厂商的具体实现。逻辑上理解是占用 1 位,但是实际中会考虑计算机高效存储因素。
Java虚拟机规范讲到:在JVM中并没有提供boolean专用的字节码指令,而 boolean 类型数据在经过编译后在 JVM 中会通过 int 类型来表示,此时 boolean 数据 4 字节 32 位,而 boolean 数组将会被编码成Jav a虚拟机的 byte 数组,此时每个 boolean 数据 1 字节占 8 bit。
- 引用数据类型建立在基本数据类型的基础上,包括数组、类和接口。引用数据类型是由用户自定义,用来限制其他数据的类型。另外,Java 语言中不支持 C++中的指针类型、结构类型、联合类型和枚举类型。
switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String 上?
- Java5 以前 switch(expr)中,expr 只能是 byte、short、char、int。
- 从 Java 5 开始,Java 中引入了枚举类型, expr 也可以是 enum 类型。
- 从 Java 7 开始,expr还可以是字符串(String),但是长整型(long)在目前所有的版本中都是不可以的。
在 Java 7 以后, switch 语句中可以使用 String 类型的变量。然而, switch 不支持 long 类型。这是因为 switch 语句是基于整数比较的,而 long 类型的变量在 Java 中是 64 位的,因此无法用于 switch 语句。
访问修饰符 public、private、protected、以及不写(默认)时的区别?
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。Java 支持 4 种不同的访问权限。
- default (即默认,什么也不写): 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。
- private : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
- public : 对所有类可见。使用对象:类、接口、变量、方法
- protected : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类(外部类)。

final、finally、finalize的区别?
final 用于修饰变量、方法和类。
- final 变量:被修饰的变量不可变,不可变分为引用不可变和对象不可变,final 指的是引用不可变,final 修饰的变量必须初始化,final成员变量表示常量,只能被赋值一次,赋值后其值不再改变。final修饰的变量还会禁止指令重排序。
- final 方法:被修饰的方法不允许任何子类重写,子类可以使用该方法。
- final 类:被修饰的类不能被继承,所有方法不能被重写。final类中所有的成员方法都会隐式的定义为final方法。
finally 作为异常处理的一部分,它只能在 try/catch 语句中,并且附带一个语句块,表示这段语句最终一定被执行(无论是否抛出异常),经常被用在需要释放资源的情况下,System.exit (0) 可以阻断 finally 执行。
finalize 是在 java.lang.Object 里定义的方法,也就是说每一个对象都有这么个方法,这个方法在 GC启动,该对象被回收的时候被调用。
一个对象的 finalize 方法只会被调用一次,但 finalize 被调用不一定会立即回收该对象,所以有可能调用 finalize 后,该对象又不需要被回收了,然后到了真正要被回收的时候,因为前面调用过一次,所以不会再次调用 finalize 了,进而产生问题。 即使通过可达性分析判断不可达的对象,也不是“非死不可”,它还会处于“缓刑”阶段, 因此建议大家尽量不要使用 finalize 方法,因为这个方法太不可靠。在生产中你很难控制方法的执行或者对象的调用顺序,建议大家忘了finalize方法!因为在finalize方法能做的工作,java中有更好的,比如try-finally或者其他方式可以做得更好。
是否可以在 static 环境中访问非 static 变量?为什么在静态方法中不能访问非静态变量?
- static变量在Java中是属于类的,它在所有的实例中的值是一样的。当类被Java虚拟机加载类的过程中,准备阶段会对static变量进行初始化。而非static的变量是属于对象的实例的。
- 因为静态方法被虚拟机加载时,普通对象实例还没有被初始化,虚拟机按照顺序先初始化静态方法的成员,再去初始化非静态的。
java静态变量、代码块、和静态方法的执行顺序是什么?
基本上代码块分为三种:Static静态代码块、构造代码块、普通代码块
- 代码块执行顺序:静态代码块——> 构造代码块 ——> 构造函数——> 普通代码块
- 继承中代码块执行顺序:父类静态代码块——>子类静态代码块——>父类普通代码块——>父类构造器——>子类普通代码块——>子类构造器
想要深入了解,可以参考这篇文章 :https://juejin.cn/post/6844903986475040781
抽象类和接口的区别是什么?
语法层面上的区别:
- 抽象类可以提供成员方法的实现细节,而接口中只能存在 public abstract 方法;
- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是 public static final 类型的;
- 接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
- 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
设计层面上的区别:
- 抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。
- 设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。
抽象类能使用 final 修饰吗?
- 不能,定义抽象类就是让其他类继承的,如果定义为 final 该类就不能被继承,这样彼此就会产生矛盾,所以 final 不能修饰抽象类
java 创建对象有哪几种方式?
java中提供了以下四种创建对象的方式:
- new 创建新对象
- 通过 反射 机制
- 采用 clone 机制
- 通过 序列化 机制
前两者都需要显式地调用构造方法。对于clone机制,需要注意浅拷贝和深拷贝的区别,对于序列化机制需要明确其实现原理,在java中序列化可以通过实现Externalizable或者Serializable来实现。

什么是不可变对象? 好处是什么?
- 不可变对象指对象一旦被创建,状态就不能再改变,任何修改都会创建一个新的对象,如 String、Integer及其它包装类.
- 不可变对象最大的好处是线程安全.
能否创建一个包含可变对象的不可变对象?
当然可以,比如 final Person[] persons = new Persion[]{} persons是不可变对象的引用,但其数组中的Person实例却是可变的.这种情况下需要特别谨慎,不要共享可变对象的引用.这种情况下,如果数据需要变化时,就返回原对象的一个拷贝.
值传递和引用传递的区别的什么?为什么说Java中只有值传递?
- 值传递:指的是在方法调用时,传递的参数是按值的拷贝传递,传递的是值的拷贝,也就是说传递后就互不相关了。
- 引用传递:指的是在方法调用时,传递的参数是按引用进行传递,其实传递的是引用的地址,也就是变量所对应的内存空间的地址。传递的是值的引用,也就是说传递前和传递后都指向同一个引用(也就是同一个内存空间)。
基本类型作为参数被传递时肯定是值传递;引用类型作为参数被传递时也是值传递,只不过“值”为对应的引用地址。
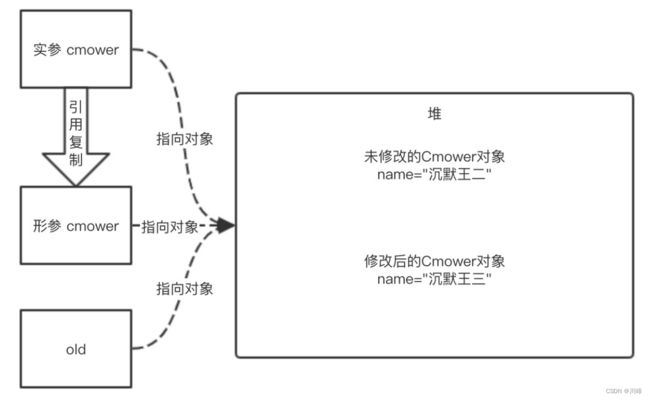
注意:Java中的对象类型作为形参传递时,传递的是一个指向该对象堆内存地址的引用变量的副本,可以通过该引用修改原始对象的成员属性调用成员方法等,但是如果在函数内修改形参的指向为新的对象时,不会影响原来实参变量的指向,参考下面代码:
User user = new User("张三");
function(user);
private void function(User u) {
u.age = 23; // 此时u操作的对象和外面的user是同一个对象
u = new User("李四"); // u指向新的对象后,u和外面的user就没有关系了,外面的user不变还是指向张三
u.age = 25; // 此时修改的是李四
}
而在C++中却可以通过引用和指针来实现函数内修改形参的指向同时也修改了实参的指向,注意二者的区别:
int b = 10;
int &a = b;
function(a);
void function(int & x) {
x = 100; // 函数内将形参改成100,则调用函数后,实参a也会变成100,a是b的别名,a和b是同一个对象,因此b会变成100
}
function(&b);
void function(int* x) {
*x = 200; // 函数内将形参改成200,则调用函数后,实参b也会变成200,因为指针指向的内容和b指向的内容相同
}
想要深入了解,可以参考这篇文章 :http://www.itwanger.com/java/2019/11/26/java-yinyong-value.html
https://www.cnblogs.com/ncl-960301-success/p/10574701.html
== 和 equals 区别是什么?
- 对于基本数据类型 == 比较的是值,对于引用数据类型,== 比较的是对象的内存地址
- 对象的equals方法默认从超类Object继承而来,内部实现默认与‘==’是完全等价的,比较的是对象的内存地址,但我们可以重写equals方法
- equals方法主要用于两个对象之间,检测一个对象是否等于另一个对象
判断两个对象是否相等,一般有两种使用情况:
- 情况1,类没有覆盖equals()方法。则通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象。
- 情况2,类覆盖了equals()方法。一般,我们都覆盖equals()方法来两个对象的内容相等;若它们的内容相等,则返回true(即,认为这两个对象相等)。
hashCode(),equals()两种方法是什么关系?
要弄清楚这两种方法的关系,就需要对哈希表有一个基本的认识。其基本的结构如下:

对于hashcode方法,会返回一个哈希值,哈希值对数组的长度取余后会确定一个存储的下标位置,如图中用数组括起来的第一列。
不同的哈希值取余之后的结果可能是相同的,用equals方法判断是否为相同的对象,不同则在链表中插入。
则有 hashCode() 与 equals() 的相关规定:
- 如果两个对象相等,则hashcode一定也是相同的;
- 两个对象相等,对两个对象分别调用equals方法都返回true;
- 两个对象有相同的hashcode值,它们也不一定是相等的;
为什么重写 equals 方法必须重写 hashcode 方法 ?
- 针对Map一类的操作接口,会使用到对象的哈希值进行存储定位,如果equals相等但hashCode不一样,会出现不可预期的结果
- equals相等的对象hasCode必须相等, equals不相等的对象hasCode也必须不同
- 重写父类的equals方法,必须同时重写hashCode方法,子类重新定义equals必须包含调用super.equals
- equals方法重写,除了比较对象地址是否相等,对象是否是同一个类 instanceof 或getClass是否相等外,对于基本类型成员使用==比较,对于引用类型成员使用equals比较
- 确保hashCode使用的字段与equals中使用的字段一致,任何在equals()方法中出现的field都应该纳入hashCode()的计算
在重写equals方法时,需要遵循哪些约定,具体介绍一下?
- 自反性:对于任何非null的引用值x,x.equals(x)应返回true。
- 对称性:对于任何非null的引用值x与y,当且仅当:y.equals(x)返回true时,x.equals(y)才返回true。
- 传递性:对于任何非null的引用值