完全监督时序动作定位Fully Supervised Temporal Action Localization 论文阅读
proposal + classification
目前fully supervised动作定位算法可以分为两类:top-down和bottom-up。top-down方法通过滑动不同尺度的窗口获取proposals,它的缺陷在于 生成的proposals通常在时间上不够精确或不够灵活,无法涵盖不同持续时间动作实例。bottom-up方法分为两个阶段 (1)定位时间边界并将边界合并为提案;(2)使用构造的提案特征评估每个提案的置信度。
时序动作提案生成文章链接:Temporal Action Proposal Generation
CVPR2022
Learning to Refactor Action and Co-occurrence Features for Temporal Action Localization
时序动作定位的主要挑战是如何从海量的伴随动作同时出现的共现信息中检索微妙的人类动作。
一方面指出时序边界的模糊性是共现信息主导了真实的动作内容,造成不准确的边界预测。
另一方面,完全监督设置下,边界标签包含的场景等信息使得模型过度依赖这些共现信息检索动作。过度依赖共现信息也会造成误分类。如下图所示。
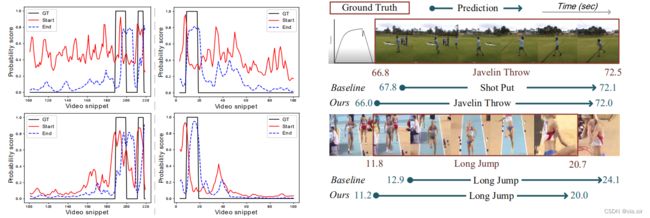
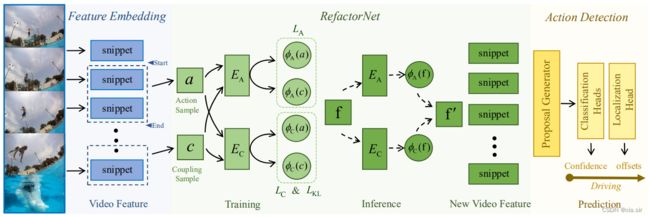
本文提出的方法 RefactorNet 是一个预处理过程。出发点是更好地平衡视频中的动作成分和共现成分。动作成分是指描述在一个视频片段中发生的动作的特征,包括一个或多个人的运动模式及其与对象的交互。共现成分指的是不描述任何动作,但经常在一个帧或一个视频片段中与它们同时出现的特征。这包括特定于类的背景,它只与某些动作频繁地同时出现,例如,田径场;和类别不可知的背景,它们的出现与动作类别不太相关,例如,天空。
RefactorNet旨在通过解耦加重构的方式获得一个更适合视频表征来进行动作定位。首先解耦的目的是显式地操控动作成分和共现成分,它利用动作片段和非动作片段的相似性和差异性进行特征解纠缠,然后利用KL散度损失函数使解耦出的共现成分服从标准的正态分布,降低其对动作检测器的负面影响。重组的目的是保留共现信息中的上下文信息,即对某些动作分类有益的信息。实验也证明了只保留动作成分是不足够的。
CVPR 2022
RCL : Recurrent Continuous Localization for Temporal Action Detection
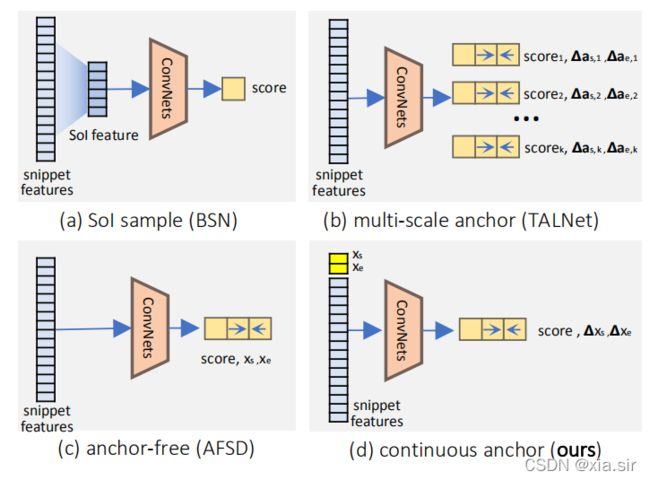
当前方法一直对short instance检测不佳,RCL提出连续anchor表征来有效地解决对short-term segments的漏检。
背景:受到2D object detection的影响,TAL通常采用离散的anchor机制。无论是anchor-based还是anchor-free的,都是分类回归离散的anchor或proposal。
ICCV 2021
Class Semantics-based Attention for Action Detection
当前的TAL方法都采用 feature encoder + localization netowork for regression and classification 的pipeline。这些方法没有采用任何注意力机制使得localization network关注重要的特征。
本文提出一个Class Semantics-based Attention(CSA), 它从输入视频中动作类的语义的时间分布中学习,以找到编码特征的重要性分数。具体来说作者提出一个类似于SENet的注意力机制,它能从编码特征的channel和temporal axes两方面为重要的语义特征提供注意力分数。实验证明本文提出的方法是model-agnostic。
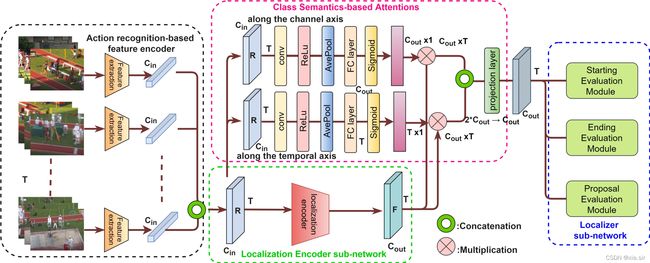
Architecture: 融合了CSA注意机制的通用TAL架构。常用的动作检测架构由三个主要组件组成:(1)一个基于动作识别的特征编码器,比如I3D,提取类语义丰富的特征,记为R,(2)一个映射R到F的定位编码器子网络,(3)最后一个基于特征F生成动作提案的定位子网络。本文提出的注意机制从R中学习注意权重,并沿着通道和时间轴将注意分数应用于F上,然后融合两个加权的输出。值得注意的是,I3D是在action recognition数据集上预训练的特征提取器,因此R本身具备一定的动作识别能力。
CSA与SENet的区别在于SENet是自注意力机制。
注意力机制的具体实现其实已经呈现在主图中,里面只有两层1D时序卷积层。通道级别的注意力模块和时序维度的注意力模块分别输出通道注意力分数以及时序上下文注意力分数,用于加权F。
本文的切入点是很不错的。显然可以很容易地融合进自己的baseline。个人觉得性能提升来自于参数量的增加,本文貌似没有针对这一点进行分析。技术贡献是有限的,且缺少定性实验,比如注意力权重可视化。其实之前有很多类似于上下文注意力和语义注意力的论文,如GTAD,PGCN,TCANet等。
CVPR2021 oral
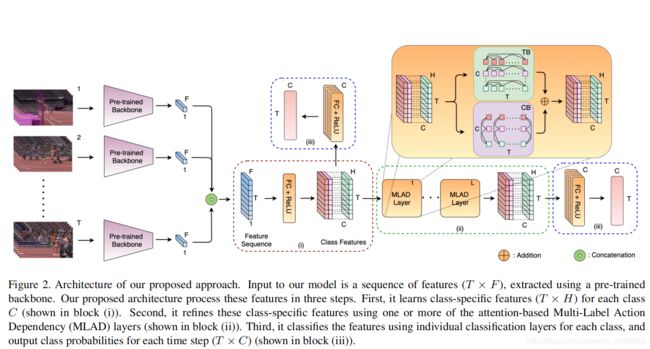
Modeling Multi-Label Action Dependencies for Temporal Action Localization
不同动作类别之间往往存在较强的依赖关系,作者将这种依赖关系定义为共发生依赖关系(co-occurrence dependency)和时序依赖关系(temporal dependency)。这两种依赖关系体现在某些动作往往在同一时刻发生(“run” and "basketball dribble"),或前后顺序发生("jump" and "fall")。实验数据集是MultiTHUMOS和Charades,都是多标签数据集。MultiTHUMOS每个视频包含多达25个动作标签,平均每个视频有10.5个动作实例,每帧有1.5个标签。Charades数据集平均每个视频包含6.8个动作实例,该数据集为室内活动数据集。
之前的工作没有深入讨论不同动作之间的依赖关系。
本文提出的方法建模两种依赖关系:共发生依赖关系是通过基于一个时间段内其他动作的存在与否来细化动作特征来建模的;时间依赖关系是通过基于输入视频序列的所有时间步来细化特征来建模的。

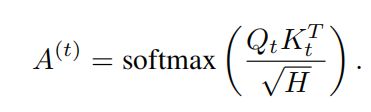
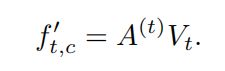
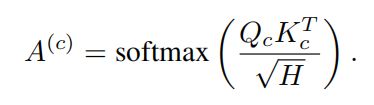

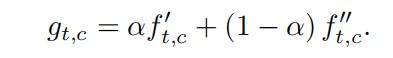
CVPR2020
ActionBytes: Learning from Trimmed Videos to Localize Actions
Zero-shot 文章。
现在的工作都使用标注的未剪辑的视频来训练一个动作定位模型,本文提出在训练过程中只利用短的剪辑的视频,即用于动作分类任务的视频数据。
解决思路:由于剪辑视频只包含类别信息,没有动作边界的概念,所以本文将动作序列分解成若干的子动作,称为ActionBytes,利用ActionBytes训练一个边界感知模型。
第一步生成Actionbytes。首先视频的高级语义信息是随时间平滑变化的,如果视频特征序列发生突然变化,也就意味着视频的像素空间出现了突变。本文利用这一特性来讲一个视频分解成若干子样本,即ActionBytes。接下来寻找ActionBytes的边界,即视频特征突变的时序位置,作者计算相邻位置的特征的距离,如果大于某个值,则在此截断,视为ActionBytes的边界。这里ActionBytes的边界是类无关的,不包含动作类别的语义信息。

由于此时的ActionBytes是类无关的,而定位视频中的动作需要类激活分数,所以需要赋予每个ActionBytes鉴别性的语义类别。作者想到为ActionBytes分配为标签。
首先通过ActionBytes生成伪标签。从训练视频中提取N个ActionBytes,每个ActionBytes以其边界特征表示。利用K-means算法对ActionBytes聚类,每个视频的伪标签向量由该视频内所有ActionBytes聚类id组成。
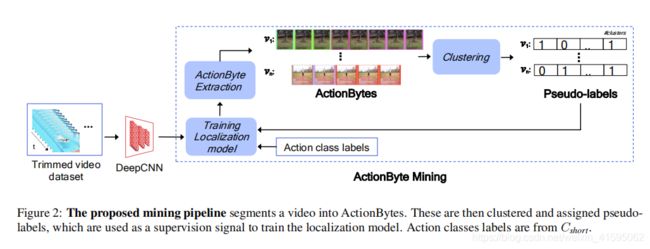
接下来利用伪标签训练定位模型,即分类和定位ActionBytes。由于现在有若干个训练视频,每个视频有其伪标签向量,好比弱监督的时序动作定位(已知每个视频包含的动作类别来定位动作)。因而相似于弱监督方法,利用一个线性分类器作用于视频特征,每个时序位置得到伪类别的激活分数。训练时分类使用MIL loss,label用的是ActionBytes的伪标签,是弱监督常见的损失函数。定位使用co-activity similarity loss,两个相同类别的视频应具有很高的相似度。此外,作者增加了一个全连接层,串联在线性分类器后,该层也使用MIL loss,只不过使用的是class label,这个分支就是仿照弱监督 训练,测试时用阈值生成action instances。
CVPR2016
Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs

Multi-scale segment generation
在未剪辑的视频上滑动窗口,窗口大小16,32,64,128,256,512帧,每个片段重叠75%,最后均匀下采样至16帧。对于剪辑后的视频,直接每16帧一个片段。
网络结构上还是比较容易理解的,对每个视频片段的信息利用3D卷积网络提取RGB和motion信息,上分支用来过滤背景,二分类网络。
中间分支多分类任务,下分支计算overlap损失用于定位。
上分支是proposal网络值得一提的是,训练过程:剪辑视频的片段为正样本,未剪辑视频的片段通过计算与GT的IoU>0.7即为正样本,小于0.3即为background负样本。
ICCV2019
Graph Convolutional Networks for Temporal Action Localization
top-down:目前算法大多单独处理每个proposal,而没有利用它们之间的关系。
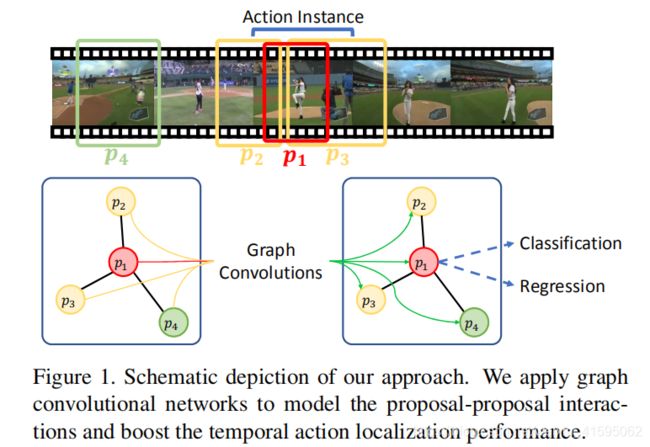
如图所示,传统方法仅用p1进行检测,而考虑上下文信息更有助于p1边界的回归,p2和p3分别描述了动作实例的开始阶段和结束阶段,p4是背景,有时场景对动作的分类也起到指导作用。
作者主要解释了两个问题:一个是如何构建一个图来表达proposal之间的关系;二是如何利用GCN学习proposal的表达的。
Proposal Graph Construction:
由于proposal较多,每个proposal之间建立关系这样会带来极大的计算量,况且有些无关的proposal没有必要连接。因此作者设计了两种边,Contextual Edge和Surrounding Edge。上下文proposals的选择基于两个proposal的IOU,重叠度大说明包含了丰富的上下文信息。
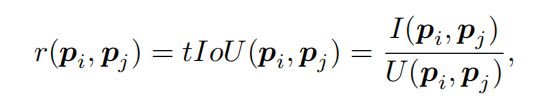
同时作者认为背景proposal对动作实例proposal的分类也会起到指导作用,所以引入Surrounding Edges。作者先计算proposal之间的IOU,排序IOU=0的proposal,再计算距离。距离小于某个阈值则添加这两个proposal的边。

Graph Convolution for Action Localization

图卷积就是在训练过程中利用节点的邻域信息来更新该节点的特征。
ECCV2020
Bottom-Up Temporal Action Localization with Mutual Regularization
Challenge:动作序列可分为开始,持续动作以及结束三个阶段。本文深入研究了这一机制,认为现有的方法通过将这些阶段建模为单个分类任务,忽略了它们之间潜在的时间约束。 当视频输入的某些帧缺乏足够的判别信息时,这可能导致不正确和/或不一致的预测。
分类任务目前每个时间位置的概率预测是独立的,而实际上动作序列无论是开始中间过程到结束都应该是平滑的,每个时间位置相互影响,忽略时间相关性会导致不一致的预测。其次开始持续和结束三个阶段是有时序关系的,忽略时序关系会导致矛盾的预测结果。
Methods: 作者提出两个正则项Intra-phase consistency和Inter-phase consistency。相位内一致性,它的目标是尽量减少每个阶段的正(负)区域内的差异,并最大限度地扩大正负区域之间的差异。 为了满足三相的有序约束,我们引入了相间一致性(InterC)正则化 通过在继续启动和继续结束之间运作,加强三个阶段的可能性之间的一致性。
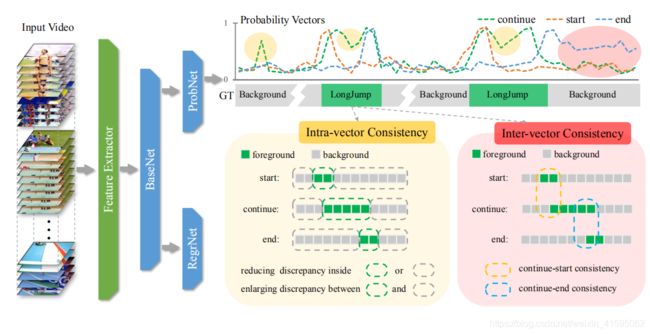
Intra-phase Consistency,图中黄色框内显示了continuing phase的处理细节。positive regions为动作序列持续的区域,那么negative regions 就是剩余时间区域,利用GT划分。这样的话预测的概率值也被分成两个集合,positive set 和negative set ,优化目标为min同一个集合的两个概率值的L1距离,max不同集合的两个概率值的L1距离。

Inter-phase Consistency,图中红色框表示。针对开始阶段,持续阶段以及结束阶段,提出相间一致性。作者假设 (一)如果持续阶段突然上升,起始阶段应给予很大的可能性,反之亦然;(二)如果持续阶段突然下降,则结束阶段 应该给出一个很高的概率,反之亦然。有点绕,我的理解是动作持续过程的概率值高说明动作开始了,所以开始阶段的概率值必须高,如果动作持续阶段的概率值突然变低说明动作即将结束,所以结束阶段的预测概率就应该很高,标志动作结束。作者定义一个标志计算持续阶段的突变,和分别表示持续阶段突然升高或突然降低的值。因此依据假设持续阶段概率的突然升高应与开始阶段的概率相关,持续阶段的概率降低应与结束概率相关。如下。
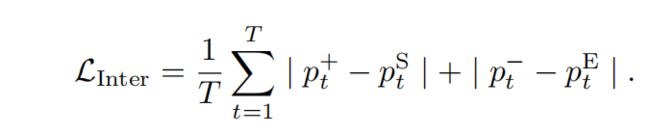
最终损失函数为,边界回归损失利用smoothL1,分类损失为交叉熵。
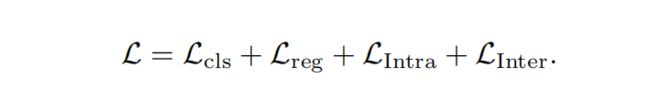
ICCV2019
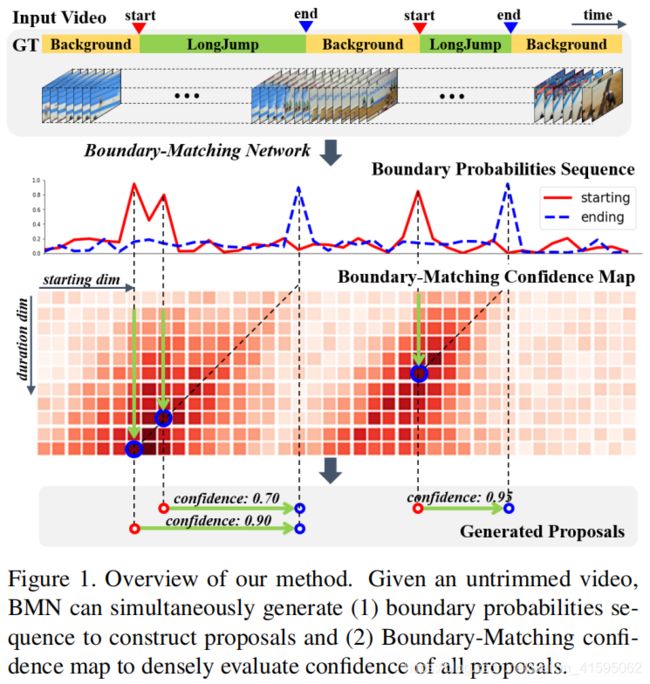
BMN: Boundary-Matching Network for Temporal Action Proposal Generation
【自下而上】目前自下而上的提案生成方法可以生成具有精确边界的提案,但不能有效地生成足够可靠的置信度分数来检索提案。 为了解决这些困难,我们引入了边界匹配(BM)机制来评估密集分布的提案的一致性分数,它将一个proposal表示为起始边界和结束边界构成的匹配对,并将所有密集分布的BM组合到BM置信度图中。
Contribution:1. 我们介绍了边界匹配机制,用于评估密集分布的提案的置信度,它可以很容易地嵌入到网络中。 2. 我们提出了一个高效、有效的端到端时间动作建议生成方法边界匹配网络(BMN)。 在BMN的两个分支中同时生成时间边界概率序列和BM置信度图作为一个统一的框架。 3. 广泛的实验表明,与其他最先进的方法相比,BMN可以获得明显更好的提案生成性能。在时间动作检测任务中,效率高,通用性强,性能好。
首先要声明的一点是该论文是针对proposal generation任务的,与action Localization区别在于不用分类。
ICCV2019(TAL Challenge 2019)
Learning Sparse 2D Temporal Adjacent Networks for Temporal Action Localization
Contribution:之前的方法没有考虑proposal之间的时间关系。
我们提出了稀疏的二维时间相邻网络来模拟候选方案之间的时间关系。 这种方法包括四个步骤:视频表示、提案生成、动作分类和分数融合。